cpu存取数据-【公粽号:堆栈future】
cpu存取数据大致可以认为是下图的流程(此处图比较简单)
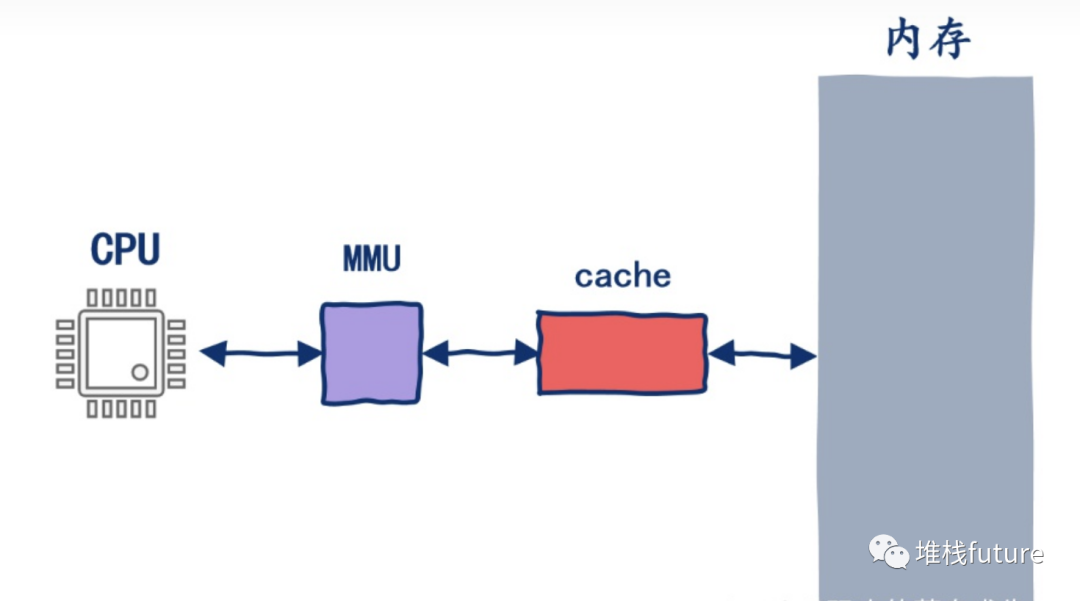
cpu拿到需要的内存地址,之后这个地址会被mmu转换成真正的物理地址,接下来会去查接下来查L1 cache,L1 cache不命中查L2 cache,L2 cache不命中查L3 cache,L3 cache不能命中查内存。
其实现在查到内存还算完,现在有了虚拟内存,
内存其实也是一层cache,是磁盘的cache,也就是说查内存也有可能不会命中
,因为内存中的数据可能被虚拟内存系统放到磁盘中了,
如果内存也不能命中就要查磁盘
。
为什么需要cache
程序局部性原理
如果我们访问内存中的一个数据A,那么很有可能接下来再次访问到,同时还很有可能访问与数据A相邻的数据B,这分别叫做
时间局部性
和
空间局部性
。
cpu cache 有多快
根据摩尔定律,CPU 的访问速度每 18 个月就会翻 倍,相当于每年增⻓ 60% 左右,内存的速度当然也会不断增⻓,但是增⻓的速度远小于 CPU,平均每年 只增⻓ 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
CPU Cache 通常分为大小不等的三级缓存,分别是
L1 Cache
、
L2 Cache
和
L3 Cache
。其中L3是多个核心共享的。
程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再加载到每个核心独有的 L2 Cache,最后 进入到最快的 L1 Cache,之后才会被 CPU 读取。它们之间的层级关系,如下图
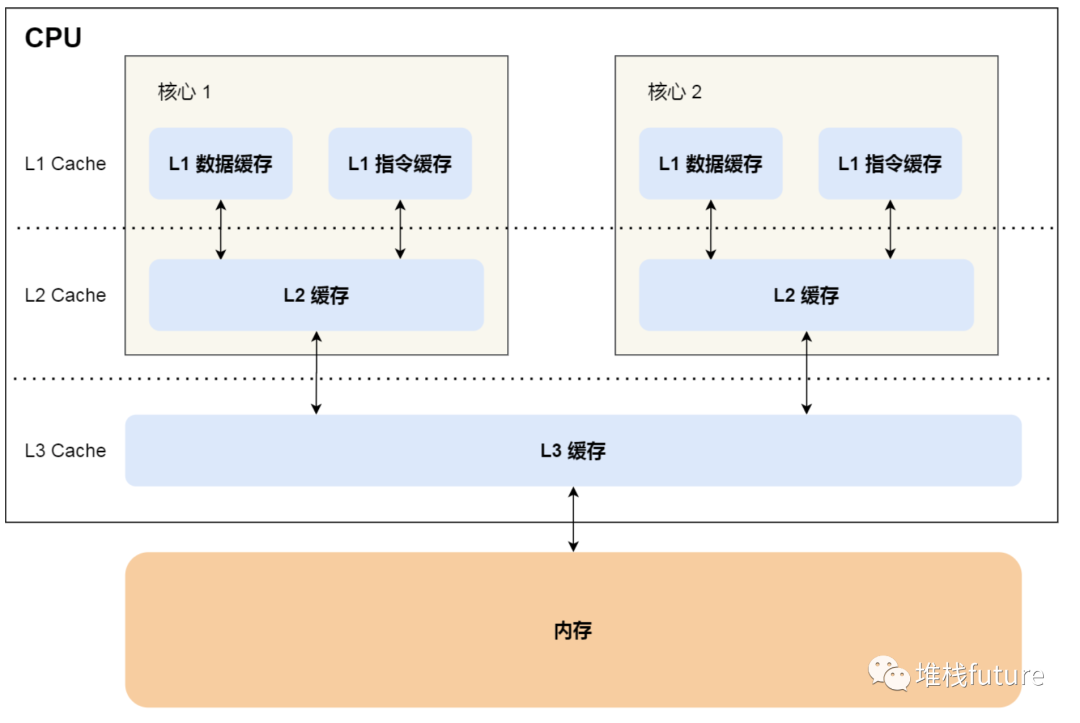
越靠近 CPU 核心的缓存其访问速度越快
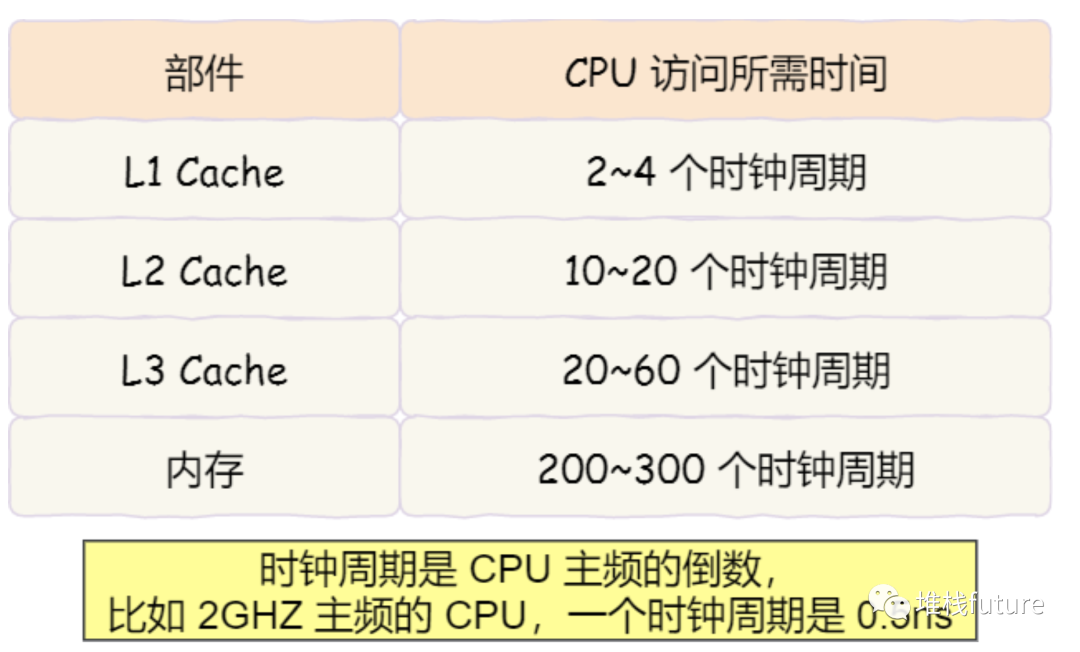
cpu cache 读取过程
CPU Cache 的数据是从内存中读取过来的,它是以一小块一小块读取数据的,而不是按照单个数组元素来
读取数据的,在 CPU Cache 中的,这样一小块一小块的数据,称为
Cache Line
(缓存块)。
可以在linux机器下执行一下命令查询L1cache的大小,单位是字节
#查看cache line 大小
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
#查看各级缓存大小 inde0-3分别是 L1数据缓存 L1指令缓存 L2数据缓存 L3数据缓存
cat /sys/devices/system/cpu/cpu0/cache/index0/size
比如,有一个 int array[100] 的数组,当载入 array[0] 时,由于这个数组元素的大小在内存只占 4 字 节,不足 64 字节,CPU 就会顺序加载数组元素到 array[15] ,意味着 array[0]~array[15] 数组元素都会 被缓存在 CPU Cache 中了,因此当下次访问这些数组元素时,会直接从 CPU Cache 读取,而不用再从内 存中读取,大大提高了 CPU 读取数据的性能。
如何写出让cpu跑的更快的代码
其实,这个问题定义为如何提高cpu缓存利用率更好
大家可以看下如下代码哪个执行效率更高
func main() {
n := 100
x := 0
arr := createArray(n)
//var arr [][]int
t := time.Now().UnixNano()
for i := 0; i < n; i++ {
for j := 0; j < n; j++ {
x = arr[i][j]
}
}
t1 := time.Now().UnixNano()
for i := 0; i < n; i++ {
for j := 0; j < n; j++ {
x = arr[j][i]
}
}
fmt.Println(x)
}
//创建二维数组
func createArray(n int) [][]int {
var arr [][]int
for i := 0; i < n; i++ {
var tmp []int
for j := 0; j < n; j++ {
tmp = append(tmp, i+j)
}
arr = append(arr, tmp)
}
return arr
}
/**
经过测试,形式一 array[i][j] 执行时间比形式二 array[j][i] 快好几倍。
之所以有这么大的差距,是因为二维数组 array 所占用的内存是连续的,比如⻓度 N 的指是 2 的 话,那么内存中的数组元素的布局顺序是这样的:
array[0][0] array[0][1] array[1][0] array[1][1]
形式一用 array[i][j] 访问数组元素的顺序,正是和内存中数组元素存放的顺序一致。当 CPU 访问 array[0][0] 时,由于该数据不在 Cache 中,
于是会「顺序」把跟随其后的 3 个元素从内存中加载到 CPU Cache,这样当 CPU 访问后面的 3 个数组元素时,就能在 CPU Cache 中成功地找到数据,
这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这便大大提高了代码的性能。
而如果用形式二的 array[j][i] 来访问,则访问的顺序就是:
array[0][0] array[1][0] array[0][1] array[1][1]
你可以看到,访问的方式跳跃式的,而不是顺序的,那么如果 N 的数值很大,那么操作 array[j][i] 时,是 没办法把 array[j+1][i] 也读入到
CPU Cache 中的,既然 array[j+1][i] 没有读取到 CPU Cache,那么就 需要从内存读取该数据元素了。很明显,这种不连续性、跳跃式访问数据元素
的方式,可能不能充分利用 到了 CPU Cache 的特性,从而代码的性能不高。那访问 array[0][0] 元素时,CPU 具体会一次从内存中加载多少元素到
CPU Cache 呢?这个问题,在前 面我们也提到过,这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过
coherency_line_size 配置查看 它的大小,通常是 64 个字节。
*/
cpu cache的结构
CPU Cache 是由很多个 Cache Line 组成的,CPU Line 是 CPU 从内存读取数据的基本单位,而 CPU Line 是由各种标志(Tag)+ 数据块(Data Block)组成
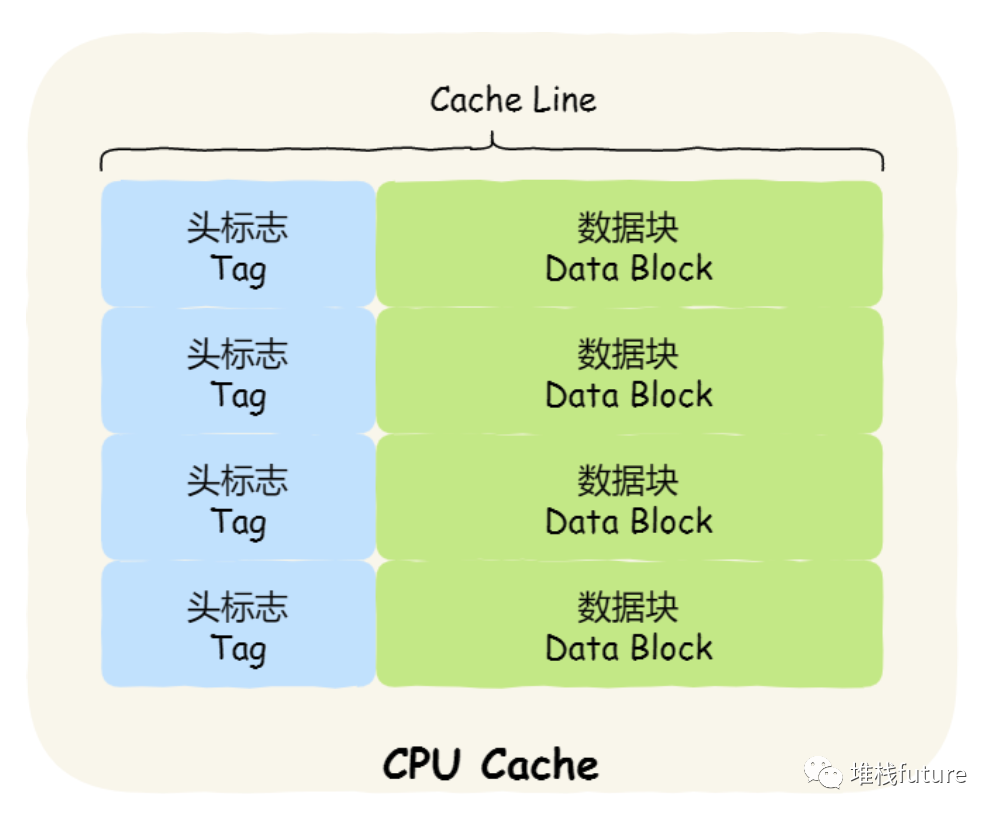
cpu cache数据的写入
事实上,数据不止有读取还有写入,如果数据写入cache之后,内存和cache的数据就不同了,我们需要把cache同步到内存中。
问题的关键就在于我们在什么时机去把数据写到内存?一般来讲有以下两种策略
写直达
保持内存与 Cache 一致性最简单的方式是,把数据同时写入内存和
Cache
中,这种方法称为写直达 (
Write Through
)。
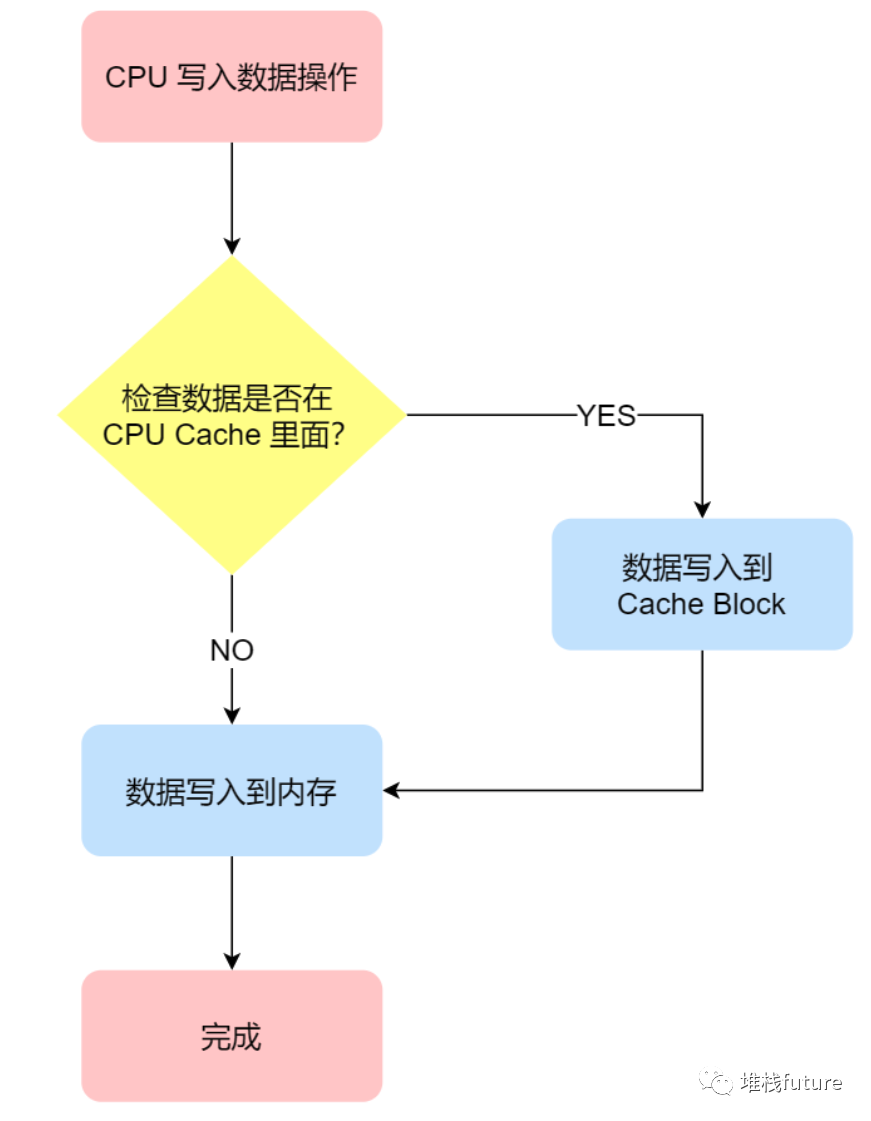
在这个方法里,写入前会先判断数据是否已经在 CPU Cache 里面了:
如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写入到内存里面; 如果数据没有在 Cache 里面,就直接把数据更新到内存里面。
写直达法很直观,也很简单,但是问题明显,无论数据在不在 Cache 里面,每次写操作都会写回到内存, 这样写操作将会花费大量的时间,无疑性能会受到很大的影响。
写回
由于写直达的机制会有性能问题,所以产生了写回(
Write Back
)的方法
在写回机制中,当发生写操作时,新的数据仅仅被写入
Cache Block
里,只有当修改过的
Cache Block
「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
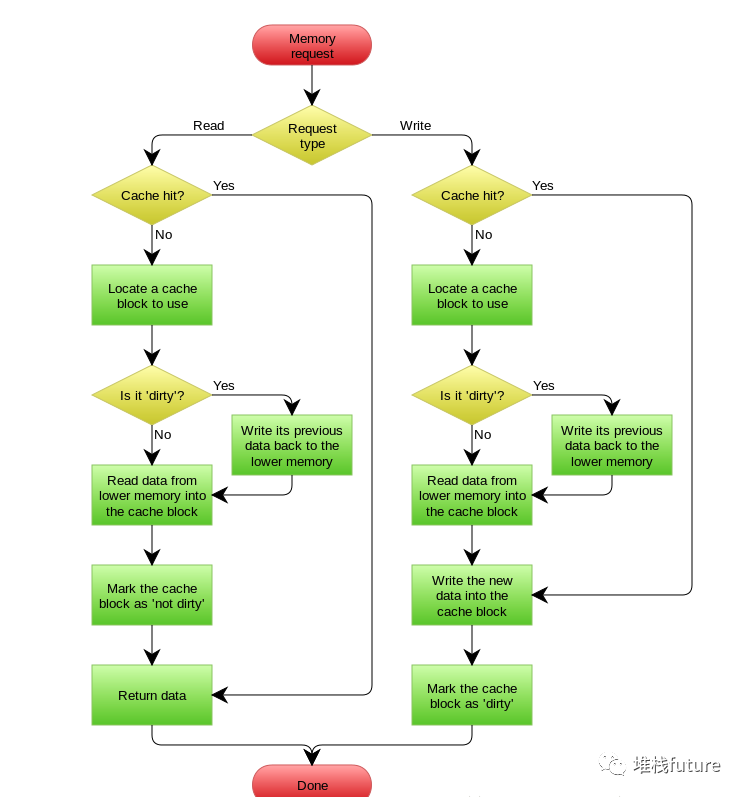
-
如果当发生写操作时,数据已经在 CPU Cache 里的话,则把数据更新到 CPU Cache 里,同时标记 CPU Cache 里的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache 里面的这个 Cache Block 的数据和内存是不一致的,这种情况是不用把数据写到内存里的;
-
如果当发生写操作时,数据所对应的 Cache Block 里存放的是「别的内存地址的数据」的话,就要检 查这个 Cache Block 里的数据有没有被标记为脏的,如果是脏的话,我们就要把这个 Cache Block 里的数据写回到内存,然后再把当前要写入的数据,写入到这个 Cache Block 里,同时也把它标记为 脏的;如果 Cache Block 里面的数据没有被标记为脏,则就直接将数据写入到这个 Cache Block 里,然后再把这个 Cache Block 标记为脏的就好了。
可以发现写回这个方法,在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中 的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。
这样的好处是,如果我们大量的操作都能够命中缓存,那么大部分时间里 CPU 都不需要读写内存,自然性 能相比写直达会高很多。
缓存一致性问题
现在的CPU都是多核的,由于L1/L2cache是各个核心独有的,那么会带来多核心的缓存一致性问题,如果不能保证缓存一致性问题就会造成错误的结果
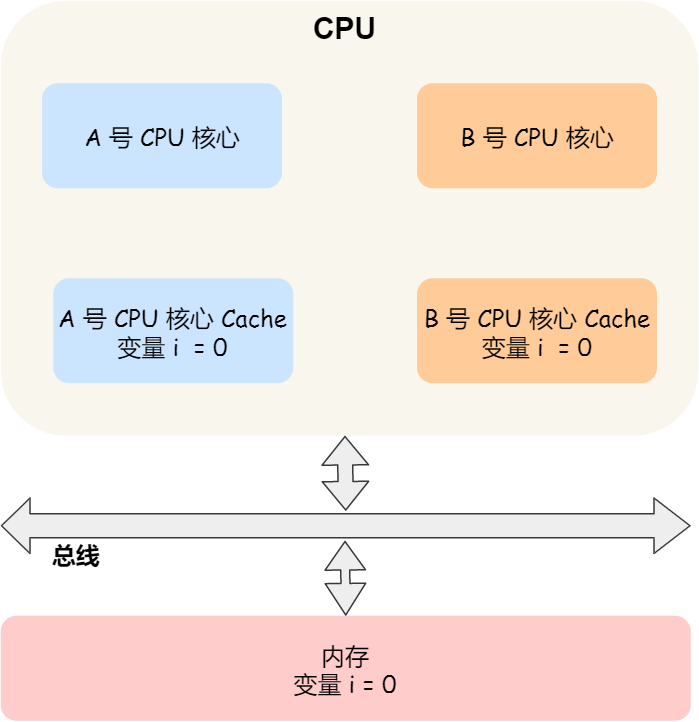
那缓存一致性的问题具体是怎么发生的呢?我们以一个含有两个核心的 CPU 作为例子看一看。
假设 A 号核心和 B 号核心同时运行两个线程,都操作共同的变量 i(初始值为 0 )。
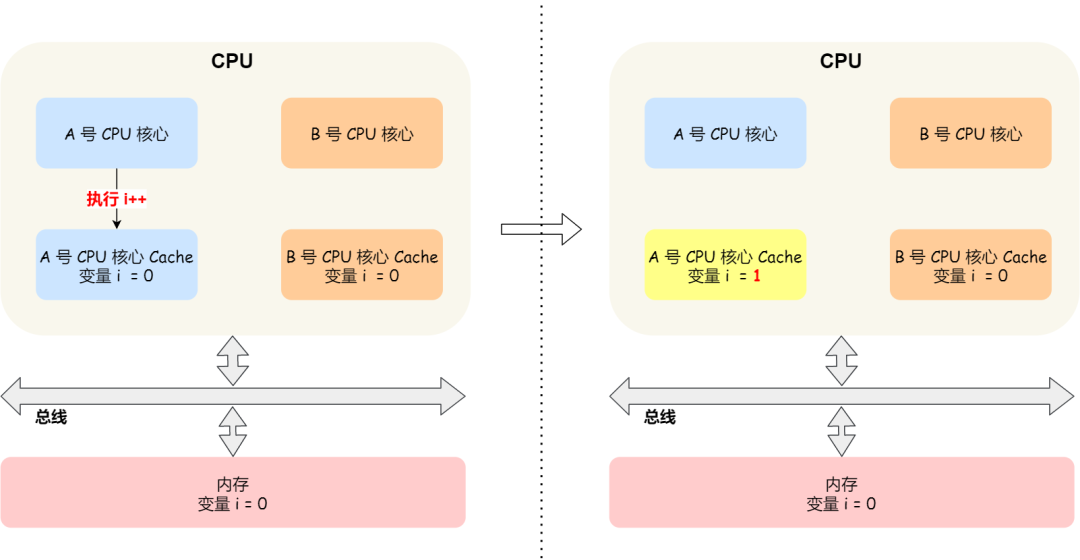
这时如果 A 号核心执行了
i++
语句的时候,为了考虑性能,使用了我们前面所说的写回策略,先把值为
1
的执行结果写入到 L1/L2 Cache 中,然后把 L1/L2 Cache 中对应的 Block 标记为脏的,这个时候数据其实没有被同步到内存中的,因为写回策略,只有在 A 号核心中的这个 Cache Block 要被替换的时候,数据才会写入到内存里。
如果这时旁边的 B 号核心尝试从内存读取 i 变量的值,则读到的将会是错误的值,因为刚才 A 号核心更新 i 值还没写入到内存中,内存中的值还依然是 0。
这个就是所谓的缓存一致性问题,A 号核心和 B 号核心的缓存,在这个时候是不一致,从而会导致执行结果的错误。
那么,要解决这一问题,就需要一种机制,来同步两个不同核心里面的缓存数据。要实现的这个机制的话,要保证做到下面这 2 点:
-
第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为
写传播(*Wreite Propagation*)
; -
第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为
事务的串形化(*Transaction Serialization*)
。
第一点写传播很容易就理解,当某个核心在 Cache 更新了数据,就需要同步到其他核心的 Cache 里。
而对于第二点事务的串形化,我们举个例子来理解它。
假设我们有一个含有 4 个核心的 CPU,这 4 个核心都操作共同的变量 i(初始值为 0 )。A 号核心先把 i 值变为 100,而此时同一时间,B 号核心先把 i 值变为 200,这里两个修改,都会「传播」到 C 和 D 号核心。
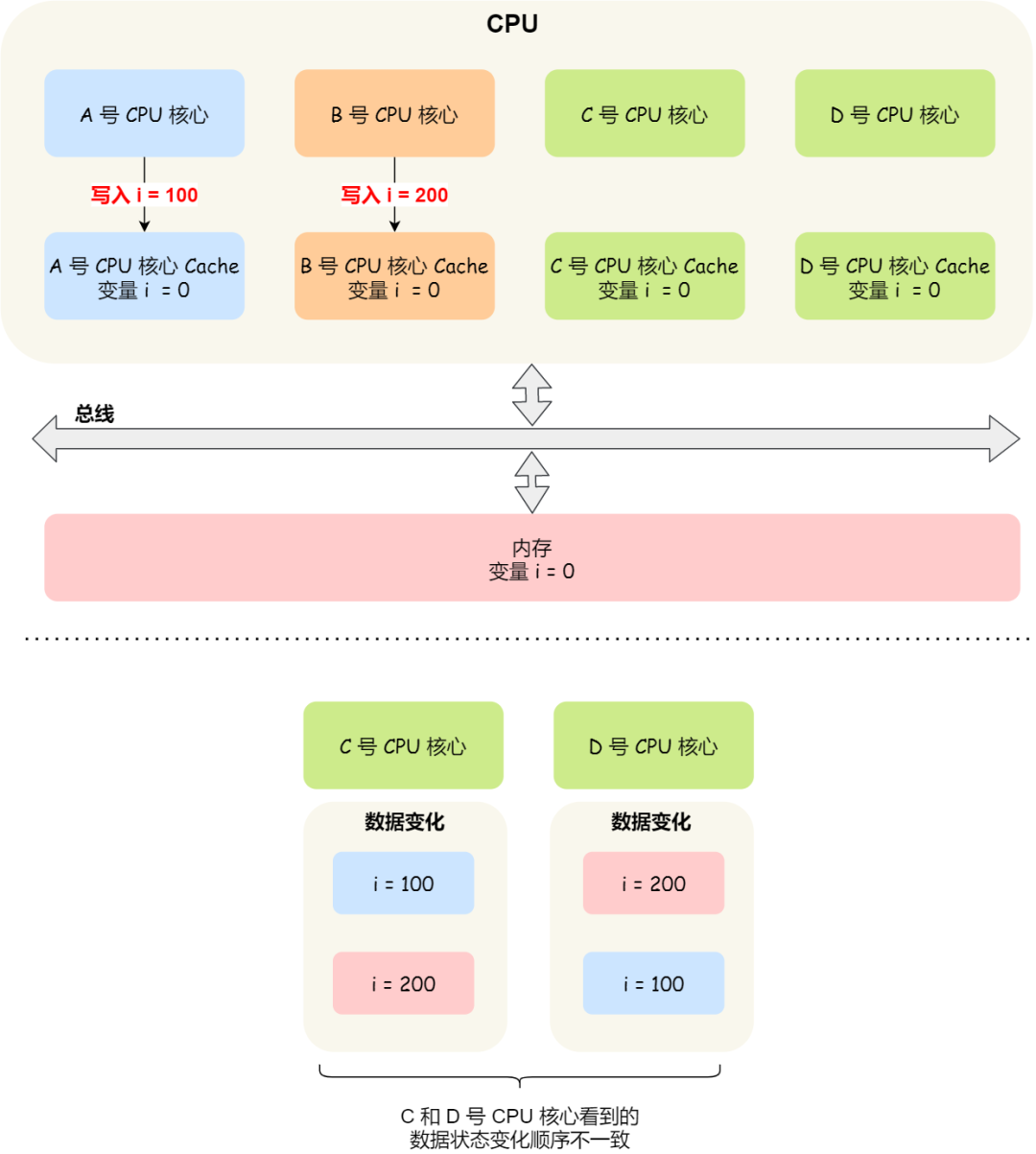
那么问题就来了,C 号核心先收到了 A 号核心更新数据的事件,再收到 B 号核心更新数据的事件,因此 C 号核心看到的变量 i 是先变成 100,后变成 200。
而如果 D 号核心收到的事件是反过来的,则 D 号核心看到的是变量 i 先变成 200,再变成 100,虽然是做到了写传播,但是各个 Cache 里面的数据还是不一致的。
所以,我们要保证 C 号核心和 D 号核心都能看到
相同顺序的数据变化
,比如变量 i 都是先变成 100,再变成 200,这样的过程就是事务的串形化。
要实现事务串形化,要做到 2 点:
-
CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
-
要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
那接下来我们看看,写传播和事务串形化具体是用什么技术实现的。
总线嗅探
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常⻅实 现的方式是总线嗅探(
Bus Snooping
)。
我还是以前面的 i 变量例子来说明总线嗅探的工作机制,当 A 号 CPU 核心修改了 L1 Cache 中 i 变量的 值,通过总线把这个事件广播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的广播事件,并 检查是否有相同的数据在自己的 L1 Cache 里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需 要把该数据更新到自己的 L1 Cache。
可以发现,总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
另外,总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并 不能保证事务串形化。
于是,有一个协议基于总线嗅探机制实现了事务串形化,也用状态机机制降低了总线带宽压力,这个协议 就是 MESI 协议,这个协议就做到了 CPU 缓存一致性。
MESI协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
-
Modified
,已修改 -
Exclusive
,独占 -
Shared
,共享 -
Invalidated
,已失效
这四个状态来标记 Cache Line 四个不同的状态。
「已修改」状态就是我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。而「已失效」状态,表示的是这个 Cache Block 里的数据已经失效了,不可以读取该状态的数据。
「独占」和「共享」状态都代表 Cache Block 里的数据是干净的,也就是说,这个时候 Cache Block 里的数据和内存里面的数据是一致性的。
「独占」和「共享」的差别在于,独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。
另外,在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
那么,「共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
举个例子
当 A 号 CPU 核心从内存读取变量 i 的值,数据被缓存在 A 号 CPU 核心自己的 Cache 里面,此时其他 CPU 核心的 Cache 没有缓存该数据,于是标记 Cache Line 状态为「独占」,此时其 Cache 中的数据与内存是一致的;
然后 B 号 CPU 核心也从内存读取了变量 i 的值,此时会发送消息给其他 CPU 核心,由于 A 号 CPU 核心已经缓存了该数据,所以会把数据返回给 B 号 CPU 核心。在这个时候, A 和 B 核心缓存了相同的数据,Cache Line 的状态就会变成「共享」,并且其 Cache 中的数据与内存也是一致的;
当 A 号 CPU 核心要修改 Cache 中 i 变量的值,发现数据对应的 Cache Line 的状态是共享状态,则要向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后 A 号 CPU 核心才更新 Cache 里面的数据,同时标记 Cache Line 为「已修改」状态,此时 Cache 中的数据就与内存不一致了。
如果 A 号 CPU 核心「继续」修改 Cache 中 i 变量的值,由于此时的 Cache Line 是「已修改」状态,因此不需要给其他 CPU 核心发送消息,直接更新数据即可。
如果 A 号 CPU 核心的 Cache 里的 i 变量对应的 Cache Line 要被「替换」,发现 Cache Line 状态是「已修改」状态,就会在替换前先把数据同步到内存。
所以,可以发现当 Cache Line 状态是「已修改」或者「独占」状态时,修改更新其数据不需要发送广播给其他 CPU 核心,这在一定程度上减少了总线带宽压力。
事实上,整个 MESI 的状态可以用一个有限状态机来表示它的状态流转。还有一点,对于不同状态触发的事件操作,可能是来自本地 CPU 核心发出的广播事件,也可以是来自其他 CPU 核心通过总线发出的广播事件。下图即是 MESI 协议的状态图:
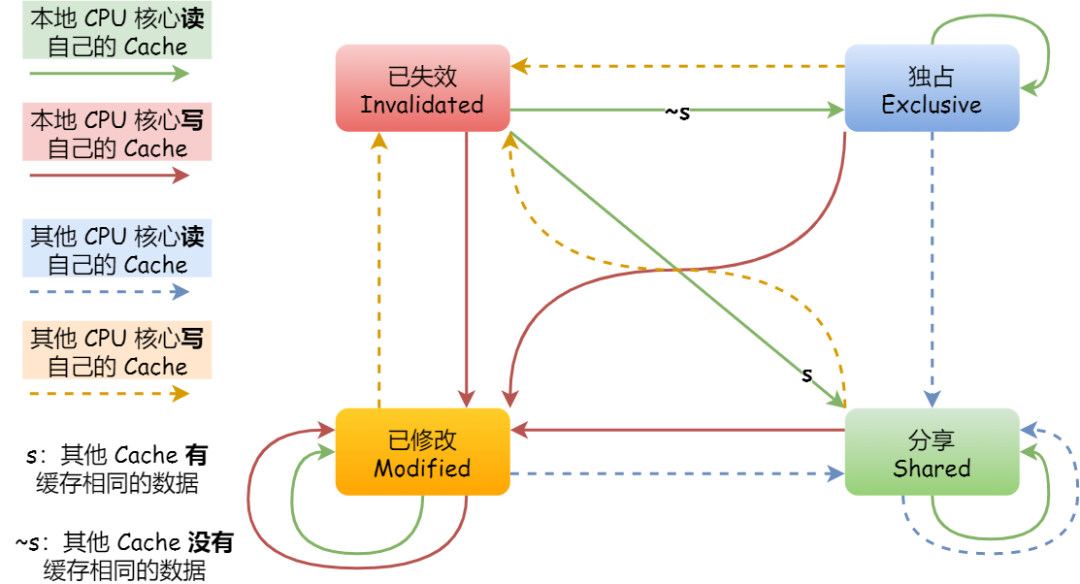
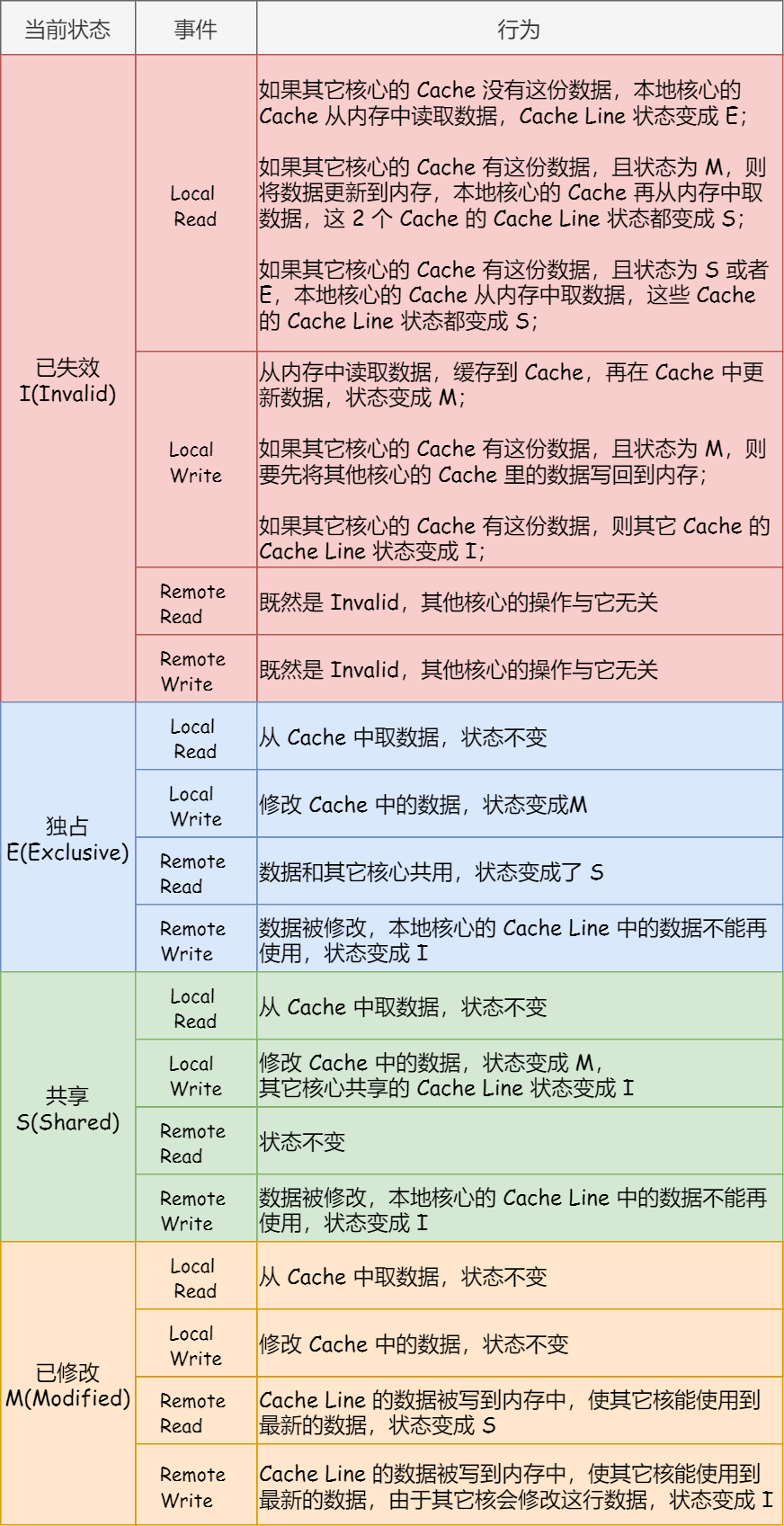
MESI 协议的四种状态之间的流转过程,我汇总成了下面的表格,你可以更详细的看到每个状态转换的原因:
mesi可视化
https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
MMU
百度百科:MMU是Memory Management Unit的缩写,中文名是内存管理单元,有时称作
分页内存管理单元
(英语:
paged memory management unit
,缩写为
PMMU
)。它是一种负责处理中央处理器(CPU)的内存访问请求的计算机硬件。
为什么需要mmu?
一
在单片机时代,是没有操作系统的,每次写完代码都需要借助工具把程序烧进去,这样程序才能跑起来,单片机的CPU是直接操作内存的物理地址
在这种情况下要想在内存中同时运行两个程序是不可能的。比如第一个程序在2000这个写入一个新的值,将会擦掉第二个程序存放在相同位置的内容。
所以操作系统引入虚拟地址,进程都有自己的,互不干涉。
操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入 的是不同的物理地址,这样就不会冲突了。
二
在现在的硬件情况下,虽然内存在一步步的变大,但是对应的程序使用的内存也在一步步变大,这个时候虚拟内存就可以提供远远超实际内存限制的空间,使计算机能够同时执行更多的程序。
这个edge浏览器占用的内存
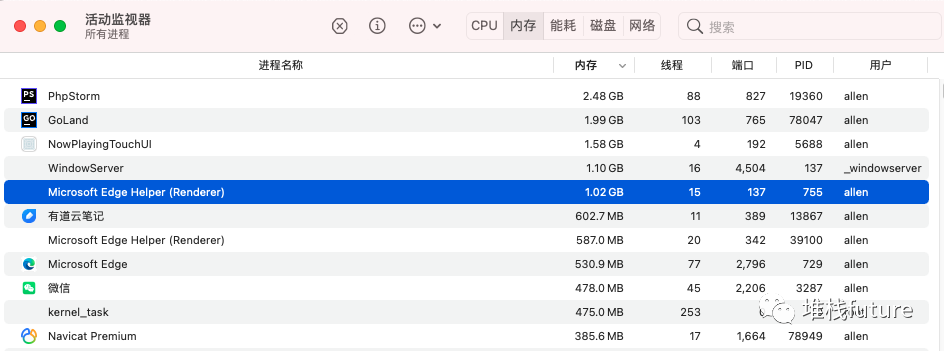
这个是详情
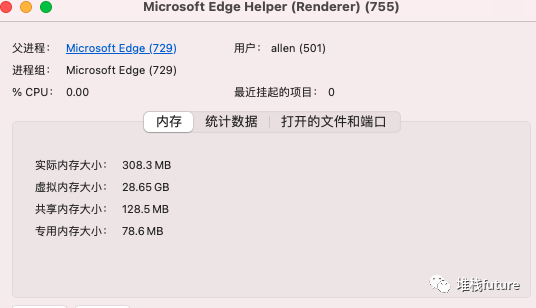
mmu的好处
-
为编程提供方便统一的内存空间抽象,在应用开发而言,好似都完全拥有各自独立的用户内存空间的访问权限,这样隐藏了底层实现细节,提供了统一可移植用户抽象。
-
以最小的开销换取性能最大化,利用MMU管理内存肯定不如直接对内存进行访问效率高,为什么需要用这样的机制进行内存管理,是因为并发进程每个进程都拥有完整且相互独立的内存空间。那么实际上内存是昂贵的,即使内存成本远比从前便宜,但是应用进程对内存的寻求仍然无法在实际硬件中,设计足够大的内存实现直接访问,即使能满足,CPU利用地址总线直接寻址空间也是有限的。
-
其实更重要的不是扩展了内存而是给每个程序提供了一个连续的内存空间,降低了我们操作内存的复杂性。
实际上虚拟内存可以实现的是 将内存看作一个存储在硬盘上的虚拟地址空间的高速缓存,并且只在内存中缓存活动区域(比如一个浏览器打开需要200mb内存 每个页面需要200内存 浏览器即使开十几个页面,内存占用也只是400mb,当然这是一个简单的例子)
分页
分⻚是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间, 我们叫⻚(
Page
)。在 Linux 下,每一⻚的大小为 4KB 。
CPU在获得虚拟地址之后,需要通过MMU将虚拟地址翻译为物理地址。而在翻译的过程中还需要借助页表,所谓
页表就是一个存放在物理内存中的数据结构,它记录了虚拟页与物理页的映射关系。
页表是一个元素为页表条目(Page Table Entry, PTE)的集合,每个虚拟页在页表中一个固定偏移量的位置上都有一个PTE
。下面是PTE仅含有一个有效位标记的页表结构,该有效位代表这个虚拟页是否被缓存在物理内存中。
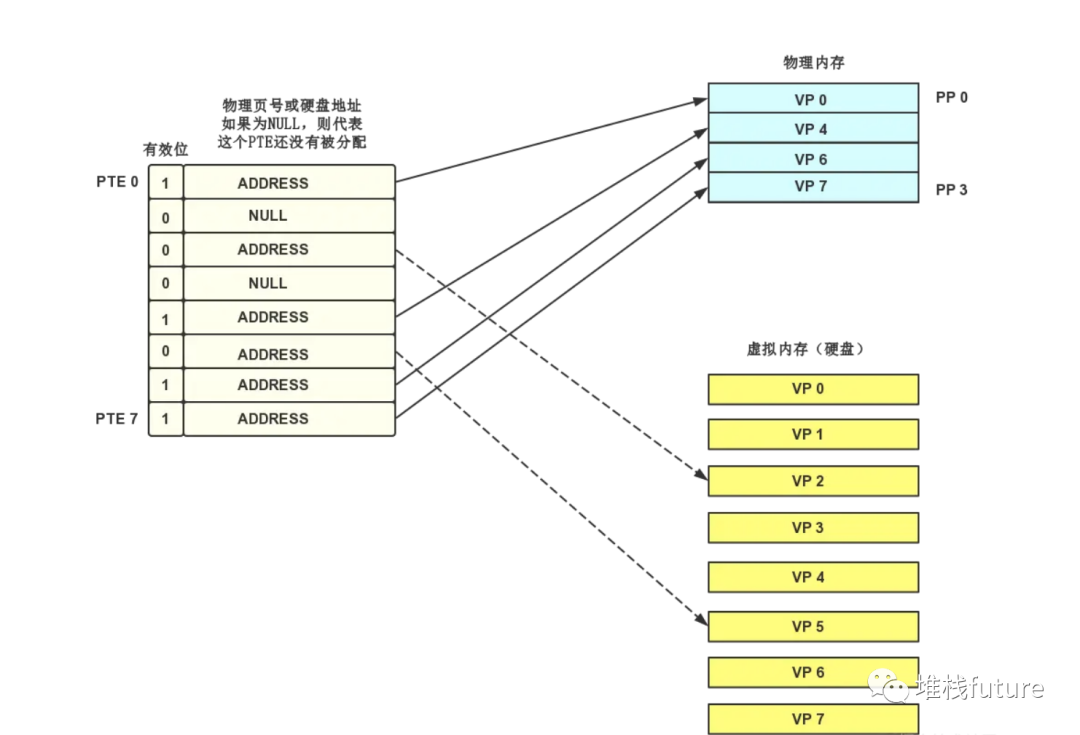
image-20211228160304209
虚拟页
VP 0
、
VP 4
、
VP 6
、
VP 7
被缓存在物理内存中,虚拟页
VP 2
和
VP 5
被分配在页表中,但并没有缓存在物理内存,虚拟页
VP 1
和
VP 3
还没有被分配。
在进行动态内存分配时,例如
malloc()
函数或者其他高级语言中的
new
关键字,操作系统会在硬盘中创建或申请一段虚拟内存空间,并更新到页表(分配一个PTE,使该PTE指向硬盘上这个新创建的虚拟页)。
由于CPU每次进行地址翻译的时候都需要经过PTE,所以如果想控制内存系统的访问,可以在PTE上添加一些额外的许可位(例如读写权限、内核权限等)
,这样只要有指令违反了这些许可条件,CPU就会触发一个一般保护故障,将控制权传递给内核中的异常处理程序。一般这种异常被称为“段错误(Segmentation Fault)”。
页命中
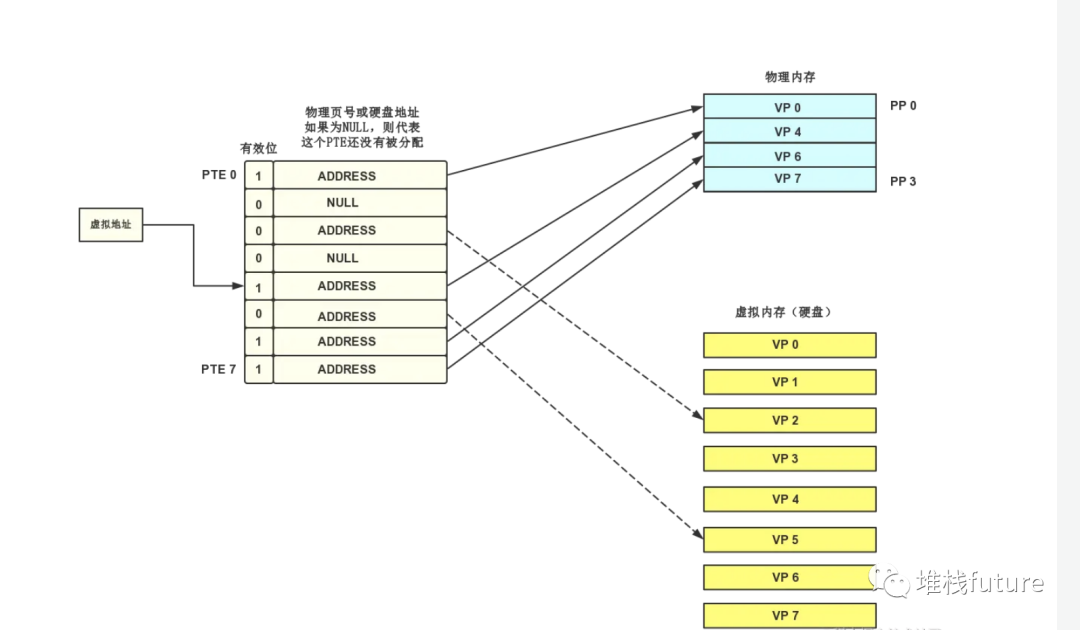
image-20211228160408348
如上图所示,MMU根据虚拟地址在页表中寻址到了
PTE 4
,该PTE的有效位为1,代表该虚拟页已经被缓存在物理内存中了,最终MMU得到了PTE中的物理内存地址(指向
PP 1
)。
缺页
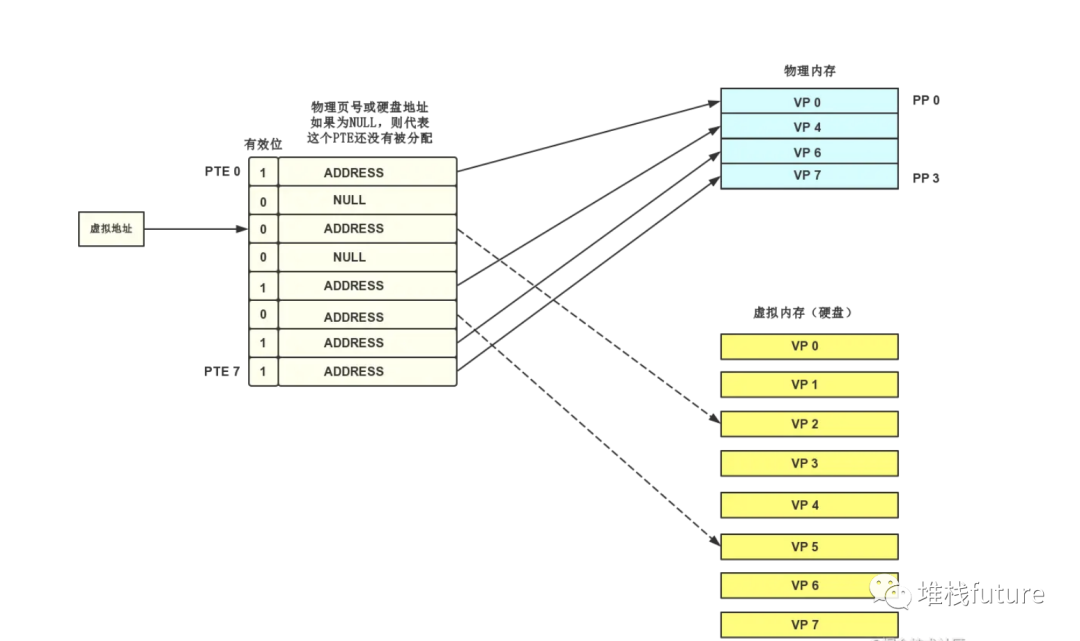
image-20211228160442595
如上图所示,MMU根据虚拟地址在页表中寻址到了
PTE 2
,该PTE的有效位为0,代表该虚拟页并没有被缓存在物理内存中。
虚拟页没有被缓存在物理内存中(缓存未命中)被称为缺页。
当CPU遇见缺页时会触发一个缺页异常,缺页异常将控制权转向操作系统内核,然后调用内核中的缺页异常处理程序,该程序会选择一个牺牲页,如果牺牲页已被修改过,内核会先将它复制回硬盘(采用写回机制而不是直写也是为了尽量减少对硬盘的访问次数),然后再把该虚拟页覆盖到牺牲页的位置,并且更新PTE。
当缺页异常处理程序返回时,它会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址重新发送给MMU
。由于现在已经成功处理了缺页异常,所以最终结果是页命中,并得到物理地址。
这种在硬盘和内存之间传送页的行为称为页面调度(paging):页从硬盘换入内存和从内存换出到硬盘。当缺页异常发生时,才将页面换入到内存的策略称为按需页面调度(demand paging),所有现代操作系统基本都使用的是按需页面调度的策略。
虚拟内存跟CPU高速缓存(或其他使用缓存的技术)一样依赖于局部性原则
。虽然处理缺页消耗的性能很多(毕竟还是要从硬盘中读取),而且程序在运行过程中引用的不同虚拟页的总数可能会超出物理内存的大小,但是
局部性原则保证了在任意时刻,程序将趋向于在一个较小的活动页面(active page)集合上工作,这个集合被称为工作集(working set)
。根据空间局部性原则(一个被访问过的内存地址以及其周边的内存地址都会有很大几率被再次访问)与时间局部性原则(一个被访问过的内存地址在之后会有很大几率被再次访问),只要将工作集缓存在物理内存中,接下来的地址翻译请求很大几率都在其中,从而减少了额外的硬盘流量。
如果一个程序没有良好的局部性,将会使工作集的大小不断膨胀,直至超过物理内存的大小,这时程序会产生一种叫做抖动(thrashing)的状态,页面会不断地换入换出,如此多次的读写硬盘开销,性能自然会十分“恐怖”。
所以,想要编写出性能高效的程序,首先要保证程序的时间局部性与空间局部性。
多级页表
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个⻚的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个⻚,每个「⻚表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储⻚表。
这 4MB 大小的⻚表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有 自己的⻚表。
那么, 100 个进程的话,就需要 400MB 的内存来存储⻚表,这是非常大的内存了,更别说 64 位的环 境了。
要解决上面的问题,就需要采用一种叫作多级⻚表(
Multi-Level Page Table
)的解决方案。
我们把这个 100 多万个「⻚表项」的单级⻚表再分⻚,将⻚表(一级⻚表)分为 1024 个⻚表(二级⻚ 表),每个表(二级⻚表)中包含 1024 个「⻚表项」,形成二级分⻚。
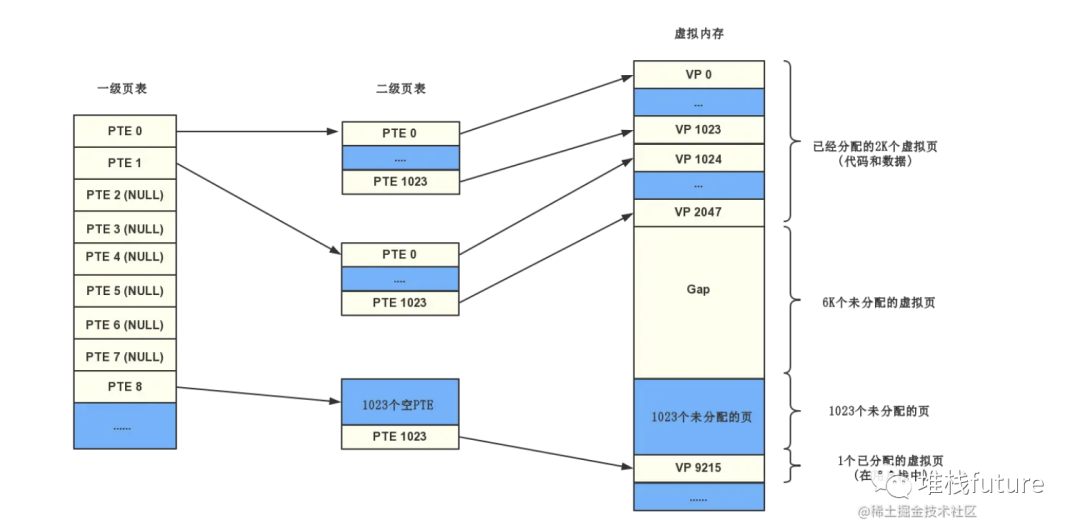
image-20211228160859548
虽然分了二级表,映射 4GB 地址空间就需要 4KB(一级⻚表)+ 4MB(二级⻚表)的内存,这样 占用空间不是更大了吗?
当然如果 4GB 的虚拟地址全部都映射到了物理内存上的话,二级分⻚占用空间确实是更大了,但是,我们 往往不会为一个进程分配那么多内存。
如果使用了二级分⻚,一级⻚表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级⻚表的⻚表项没有被 用到,也就不需要创建这个⻚表项对应的二级⻚表了,即可以在需要时才创建二级⻚表。做个简单的计 算,假设只有 20% 的一级⻚表项被用到了,那么⻚表占用的内存空间就只有 4KB(一级⻚表) + 20% * 4MB(二级⻚表)= 0.804MB ,这对比单级⻚表的 4MB 是巨大的节约
这个结构看起来很像是一个
B-Tree
,这种层次结构有效的减缓了内存要求:
-
如果一个一级页表的一个PTE是空的,那么相应的二级页表也不会存在。这代表一种巨大的潜在节约(对于一个普通的程序来说,虚拟地址空间的大部分都会是未分配的)。
-
只有一级页表才总是需要缓存在内存中的,这样虚拟内存系统就可以在需要时创建、页面调入或调出二级页表(只有经常使用的二级页表才会被缓存在内存中),这就减少了内存的压力。
对于 64 位的系统,两级分⻚肯定不够了,就变成了四级目录,分别是:
全局⻚目录项 PGD(
Page Global Directory
); 上层⻚目录项 PUD(
Page Upper Directory
); 中间⻚目录项 PMD(
Page Middle Directory
); ⻚表项 PTE(
Page Table Entry
);
TLB
多级⻚表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了几道转换的工序,这显然就降 低了这俩地址转换的速度,也就是带来了时间上的开销。
又是无处不在的局部性原理
我们就可以利用这一原理,把最常访问的几个⻚表项存储到访问速度更快的硬件,于是计算机科学家们, 就在 CPU 芯片中,加入了一个专⻔存放程序最常访问的⻚表项的 Cache,这个 Cache 就是 TLB (
Translation Lookaside Buffer
) ,通常称为⻚表缓存、转址旁路缓存、快表等。
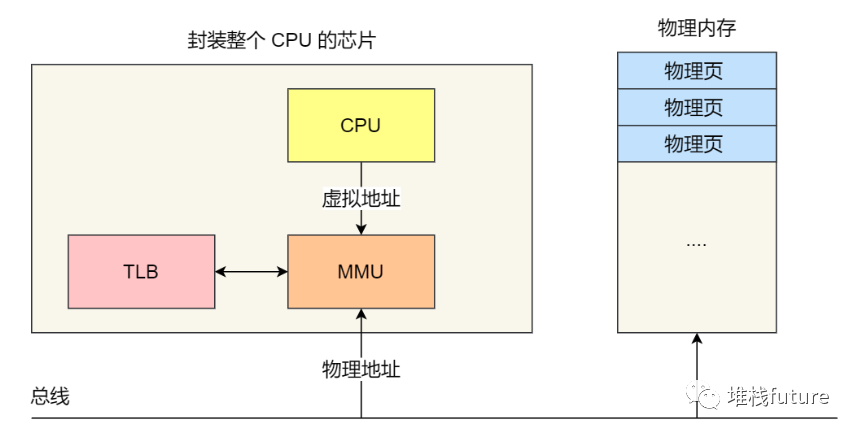
image-20211228161346517
在 CPU 芯片里面,封装了内存管理单元(
Memory Management Unit
)芯片,它用来完成地址转换和 TLB 的访问与交互。
有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的⻚表。TLB 的命中率其实是很高的,因为程序最常访问的⻚就那么几个。
参考
-
https://juejin.cn/post/6844903507594575886
-
https://cloud.tencent.com/developer/article/1921341#:~:text=MMU
-
https://gitlib.com/page/pc-mmu.html

宫粽号:【堆栈future】
使很多处于迷茫阶段的coder能从这里找到光明,堆栈创世,功在当代,利在千秋
124篇原创内容
