说起Redis的诞生,它跟关系数据库MySQL还是挺有渊源的。

随着互联网的高速发展,MySQL容纳的数据也越来越多,用户请求也随之暴涨。而每一个用户请求都变成了对它的一个又一个读写操作,MySQL真是苦不堪言。尤其是到类似双11 这种全民购物狂欢的日子,都是MySQL受苦受难的日子。
后来有人就琢磨,是不是可以学学CPU,给数据库也加一个缓存呢?于是基于缓存的Redis数据库就诞生了!
Redis的使用流程
应用程序先从MySQL那查询到的数据,在Redis这里登记一下,后面再需要用到的时候,就先找Redis要,这里就不用再麻烦MySQL了。
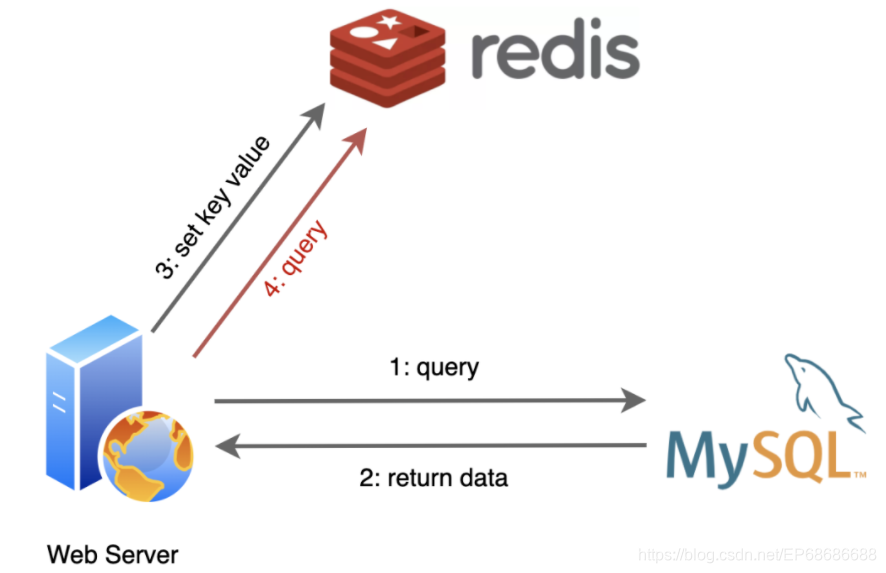
因为Redis会把登记的数据都记录在内存中,所以就不用去执行慢如蜗牛的I/O操作了。所以找Redis要数据 比找MySQL要数据省去不少的时间!
Redis支持的5中种对象
1.String (字符串类型)
2.Hash (哈希)
3.List (链表)
4.Set(集合)
5.zset(有序集合)
缓存过期 && 缓存淘汰
Redis缓存的数据都是在内存中,可是就算是在服务器上,内存的空间资源还是很有限的,总之不能无节制的存下去。
所以Redis想到了一个办法:给缓存内容设置一个超时时间,具体设置多长交给应用的程序们去设置,Redis要做的就是把过期的内容从Redis数据库里面删除,及时腾出空间就OK了。
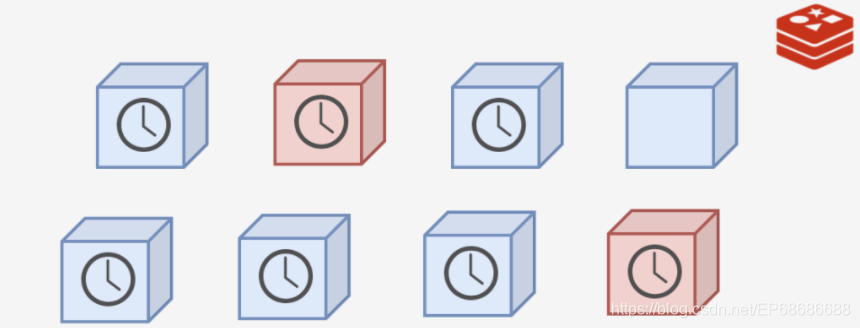
超时时间有了,那么Redis该在什么时候去干这个清理的活呢?
最简单的就是定期删除,比如100ms就做一次,一秒钟就是10次!
当然清理的时候也不能一下把所有过期的资源都给删除掉。因为Redis里面存了大量的数据,如果全面扫一遍,那不知道要花多长时间,会严重影响Redis接收新的请求!
所以Redis只好随机选择一部分来清理,能缓解内存压力就行了!
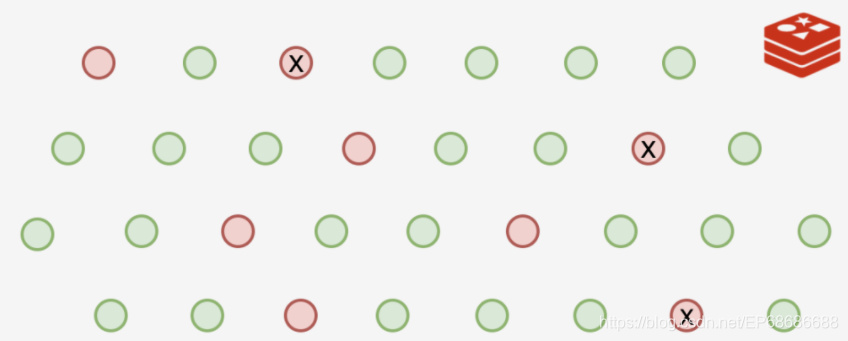
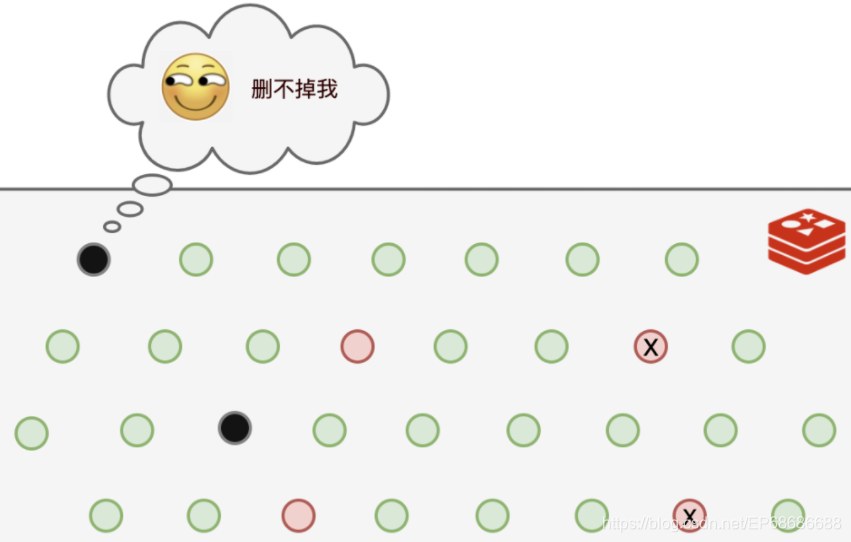
这样的话,那如果是某些键值的运气比较好,每次都没有被Redis的随机算法选中,每次都能幸免于难。那么这些长时间过期的数据就一直会占着内存空间!
于是Redis在原来定期删除的基础上,又加了一招:
把那些原来逃脱随机选择算法的键值,一旦遇到查询请求,被发现已经过期了,那就立即删除。
这种方式因为是被动式触发的,不查询就不会发生,所以也叫惰性删除!
可是,还是有部分键值,既逃脱了Redis的随机选择算法,又一直没有被查询,导致它们一直占着内存!而于此同时,可以使用的内存空间却越来越少。
而且就算退一步讲,Redis能够把过期的数据都删除掉,那万一过期时间设置的过长,还没等到Redis去清理,内存就已经吃满了,那就······
所以就有了
内存淘汰策略
,这一次Redis就能彻底解决问题啦!
Redis提供了8种策略供应用程序选择,用于Redis遇到内存不足时该如何决策:
– noeviction:返回错误,不会删除任何键值
– allkeys-lru:使用LRU算法删除最近最少使用的键值
– volatile-lru:使用LRU算法 从设置了过期时间的键集合中删除最近最少使用的键值
– allkeys-random:从所有key中随机删除
– volatile-random:从设置了过期时间的键的集合中随机删除
– volatile-ttl:从设置了过期时间的键中删除剩余时间最短的键
– volatile-lfu:从配置了过期时间的键中删除使用频率最少的键
– allkeys-lfu:从所有键中删除使用频率最少的键
有了上面几套组合拳,Redis就再也不用担心过期数据多了把空间撑满的问题了~
缓存穿透 && 布隆过滤器
不过MySQL有时会遇到查询的数据不存在的请求,每当这时MySQL就要白忙活一场!不仅如此,因为不存在,Redis也没法缓存,导致同样的请求来了每次都要让MySQL白忙活一场。Redis作为缓存的价值就没得到体现啦!这就是人们常说的
缓存穿透
。
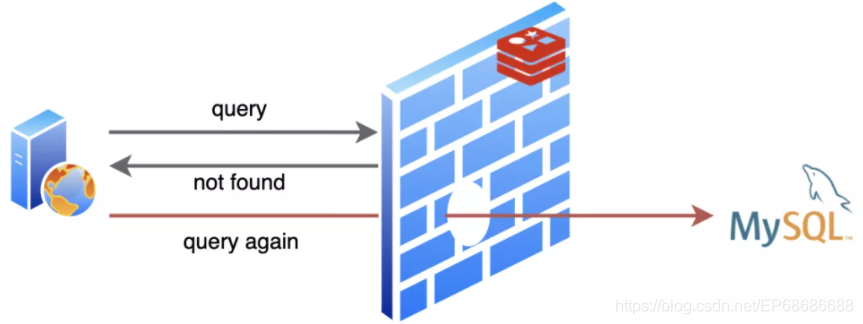
要把那些明知道不会有结果的查询请求挡住,缓解MySQL的压力,那这时就要用
布隆过滤器
了。
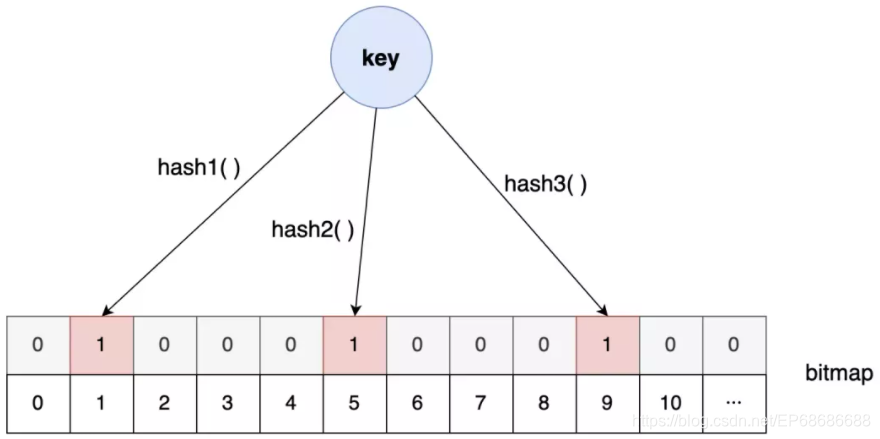
布隆过滤器别的本事没有,就擅长从超大的数据集中快速告诉你查找的数据存不存在!
(
PS:布隆过滤器有一点不靠谱,它告诉你存在的话不能全信,其实有可能是不存在的,不过它他如果告诉你不存在的话,那就一定不存在
)
将布隆过滤器介绍给了应用程序,不存在的数据就不会去打扰MySQL了,轻松帮忙解决了缓存穿透的问题。
缓存击穿 && 缓存雪崩
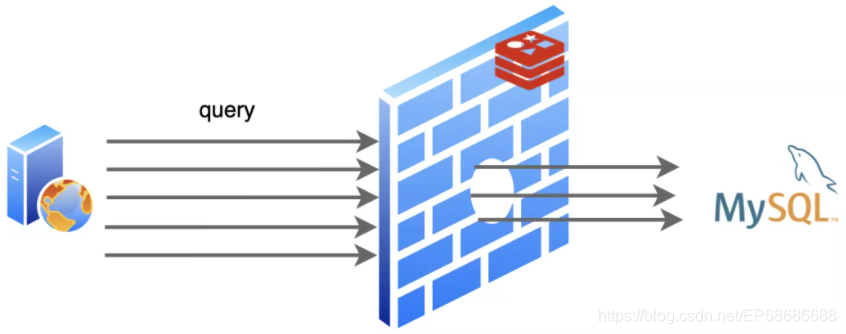
缓存击穿
:当一个热点数据到了过期时间,被Redis删掉了,不巧的是随后就有对这个数据的大量查询请求过来,Redis这里已经删了,所以请求都会发到MySQL那里。
缓存雪崩
:当一大批数据几乎同时过了有效期,然后又发生了很多对这些数据的请求。
要解决缓存击穿及缓存雪崩的问题,那么就要在程序上调整键值的过期时间,可以让其随机一下。对于热点数据,可以设置热点数据永不过期!