python-sklearn数据拆分与决策树的实现
前言
hello大家好这里是小L?,上一篇笔记简单复习了sklearn三板斧,学习sklearn数据预处理部分?
这次笔记内容:学习sklearn对数据拆分的实现,以及实现决策树模型并绘制决策树。数据集用sklearn内置数据及进行举例?。
小L希望可以在这里与大家一起进步!?
一、数据拆分的sklearn实现
1.拆分为训练集与测试集
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分别为
训练集(training set)
、验证集(validation set)和
测试集(testset)
.
训练集用来训练模型
,验证集用于模型的选择,
而测试集用于最终对学习方法的评估
.在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型.由于验证集有足够多的数据,用它对模型进行选择也是有效的.
首先讲解随机种子seed,方便对sklearn.model_selection.train_teat_split()中参数random_state的理解,random可以随机生成数字,但在前面输入设置好的代码则最后生成的随机数将不会改变。
#忽略警告信息(不显示警告信息)
import warnings
warnings.filterwarnings("ignore")
#导入需要的库
import sklearn
import random as r
r.seed(666)#种子,相当于设置/输入密码,使下行代码保持不变
r.random()
?sklearn可对数据进行处理但是不能进行可视化
训练集:用于生成模型的
测试集:最终对模型方法进行评估
sklearn.model.selection.train_test_split(
arrays,
test_size=0.25:用于验证模型的样本比例,若为None所有样本参与训练,
train_size=None:用于训练模型的样本比例,None时自动基于test_size计算,
random_state=None:随机种子,
shuffle=True:是否在拆分前对样本进行随机排列(默认洗牌),
stratify=None:array-like or None是否按指定类别标签对数据做分层拆分(分层)
)
一般用参数arrays,test_size,random_stste

#导入波斯顿数据集
from sklearn.datasets import load_boston
boston_df = load_boston()
#导入训练集与测试集拆分模块
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(boston.data,boston.target,test_size=0.3,random_state=666)
#按3:7拆,用4个变量进行接收数据,以免数据分割后被直接释放
len(x_train),len(x_test),len(y_train),len(y_test)
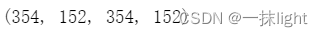
boston数据集一共有506条数据,按3:7拆分数据集的输入与输出。
2.交叉验证法
但是,在许多实际应用中数据是不充足的,为了选择好的模型,可以采用交叉验证方法.交叉验证的基本想法是
重复地使用数据
:把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上
反复地进行训练、测试以及模型选择
.

(1)留一交叉验证
保留一个数据点进行验证(每个数据点都会验证一次),其余数据训练模型。若有n个数据点,需重复交叉验证n次。
利用所有数据点,适用于数据量特别小时,受离群值影响,一般不用。
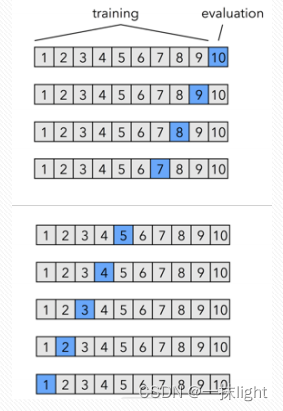
(2)验证集验证
保留一个样本数量集(设置比例),其余数据训练模型。只验证一次。结果具有偶然性。
(3)k折交叉验证
随机将数据集分成k份,每一份进行验证,其余数据进行训练,最终结果为k次记录的平均值。k越小越接近验证集法,k越大越接近留一法。
(4)s折交叉验证(s-fold)
超参数,提前设置好。
数据划分为s个互不相交大小相同子集,其中一份测试,其余数据训练。重复进行,忠厚选择s次测试中平均误差最小的模型。

3.sklearn交叉验证常用的命令
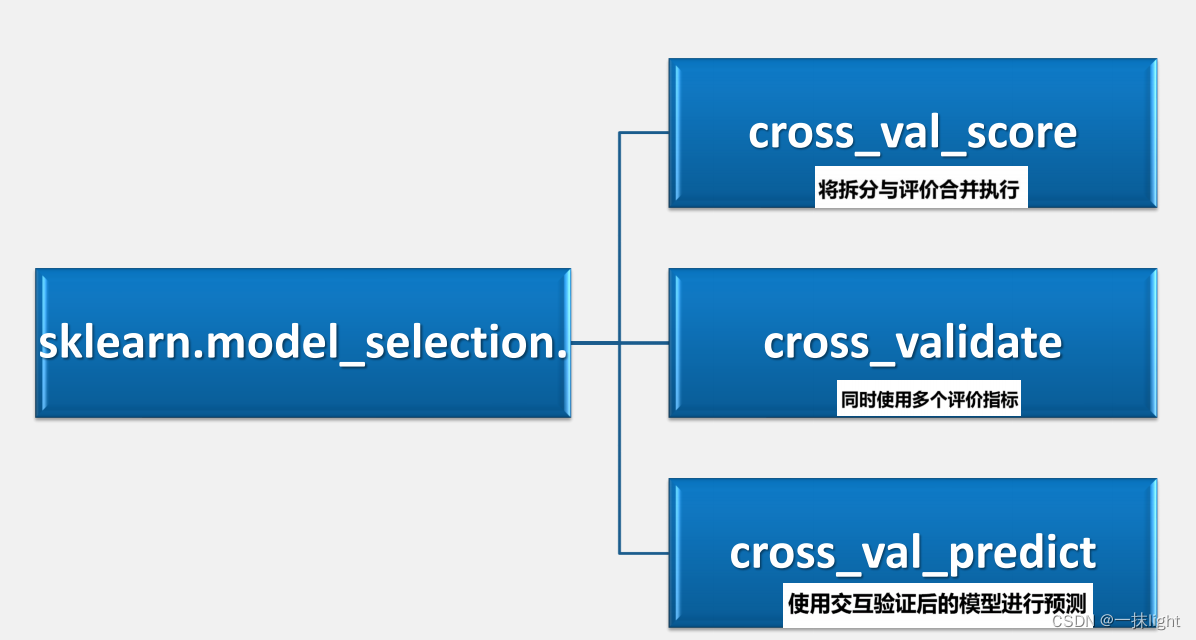
(1)将拆分与评价合并执行
拆分与评估合并执行 前三,cv,需要自己先把数据随机打乱
sklearn.model_selection.cross_val_score(
)
返回:每轮模型最后评分的数组

#导入线性回归模型
from sklearn.linear_model import LinearRegression
reg=LinearRegression()
#不用实例化,直接就是函数
#导入cross_val_score模块
from sklearn.model_selection import cross_val_score#cross_val_score不会默认洗牌
scores=cross_val_score(reg,boston.data,boston.target,cv=10)
scores#模型效果很差

scores.mean(),scores.std()
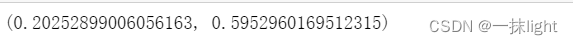
scores = cross_val_score(reg,boston.data,boston.target,scoring='explained_variance',cv=10)
scores#使用scoring后模型依旧很糟糕

#对数据进行随机重排,保证拆分的均匀性
import numpy as np#先把序号打乱,再进行赋值
X,y = boston.data,boston.target
indices = np.arange(y.shape[0])#提取行数
np.random.shuffle(indices)#打乱顺序
X,y = X[indices],y[indices]#重新赋值
reg=LinearRegression()
scores=cross_val_score(reg,X,y,cv=10)
scores

scores.mean(),scores.std()
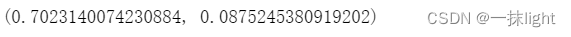
(2)同时使用多个评价指标
同时输出多个指标,精度等,需要自己先把数据随机打乱
sklearn.model_selection.cross_validate(
)
返回:每轮模型对应评分的字典,shape=(n_splits,)


from sklearn.model_selection import cross_validate
scoring = ['r2','explained_variance']
scores = cross_validate(reg,X,y,cv=10,scoring=scoring,return_train_score = False)#字典,拟合需要时间,评分时间
scores

scores['test_r2'].mean()

(3)使用交互验证后的模型进行预测
交叉验证和预测同时执行
sklearn.model_selection.cross_val_predict
(
)
返回ndarray,模型对应的各案例预测值

from sklearn.model_selection import cross_val_predict
pred = cross_val_predict(reg,X,y,cv=10)
pred[:10]#预测因变量的值(y)

from sklearn.metrics import r2_score
r2_score(y,pred)#预测准确率

二、sklearn实现决策树
1.代码实现
class sklearn.tree.DecisionTreeClassifier
(
)

- 驼峰原则命名,分类模型
- criterion标准,默认gini
- c4.5熵率

#导入iris数据集
from sklearn.datasets import load_iris
iris = load_iris()
#导入决策树分类模块
from sklearn.tree import DecisionTreeClassifier
#决策树实例化
ct = DecisionTreeClassifier()
#模型训练
ct.fit(iris.data,iris.target)

ct.max_features_

ct.feature_importances_ #特征重要性
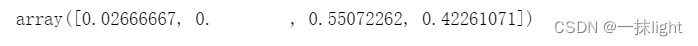
ct.predict(iris.data)

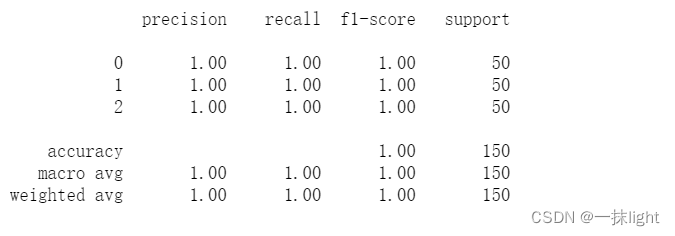
from sklearn.metrics import classification_report
print(classification_report(iris.target,ct.predict(iris.data)))
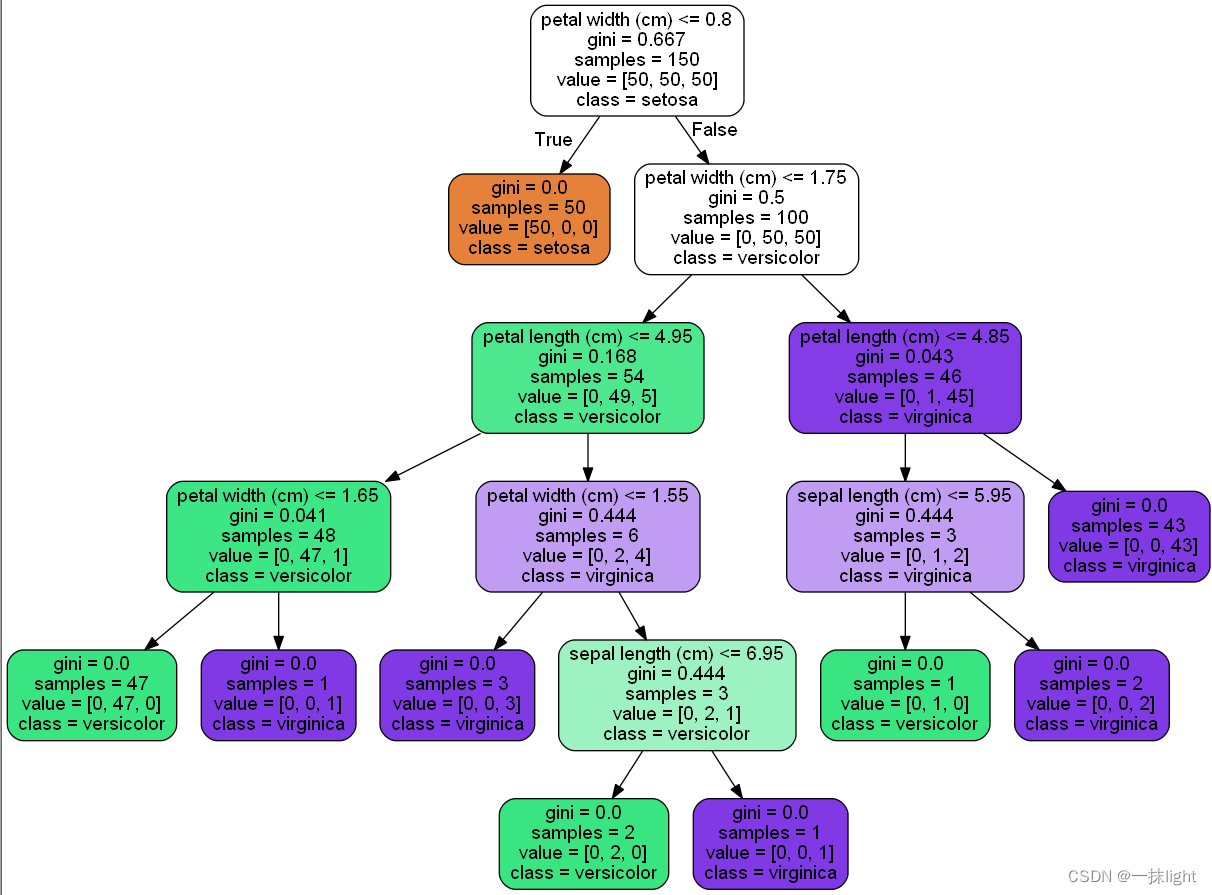
2.绘制决策树
sklearn.tree.export_graphviz
(
)可通过改变参数自定义图案, 在graphviz中打开tree.dot文件查看生成的决策树

from sklearn.tree import export_graphviz
export_graphviz(ct,out_file = ' tree.dot',
feature_names=iris.feature_names,
class_names=iris.target_names,filled=True)
#filled=True表示决策树成不同颜色
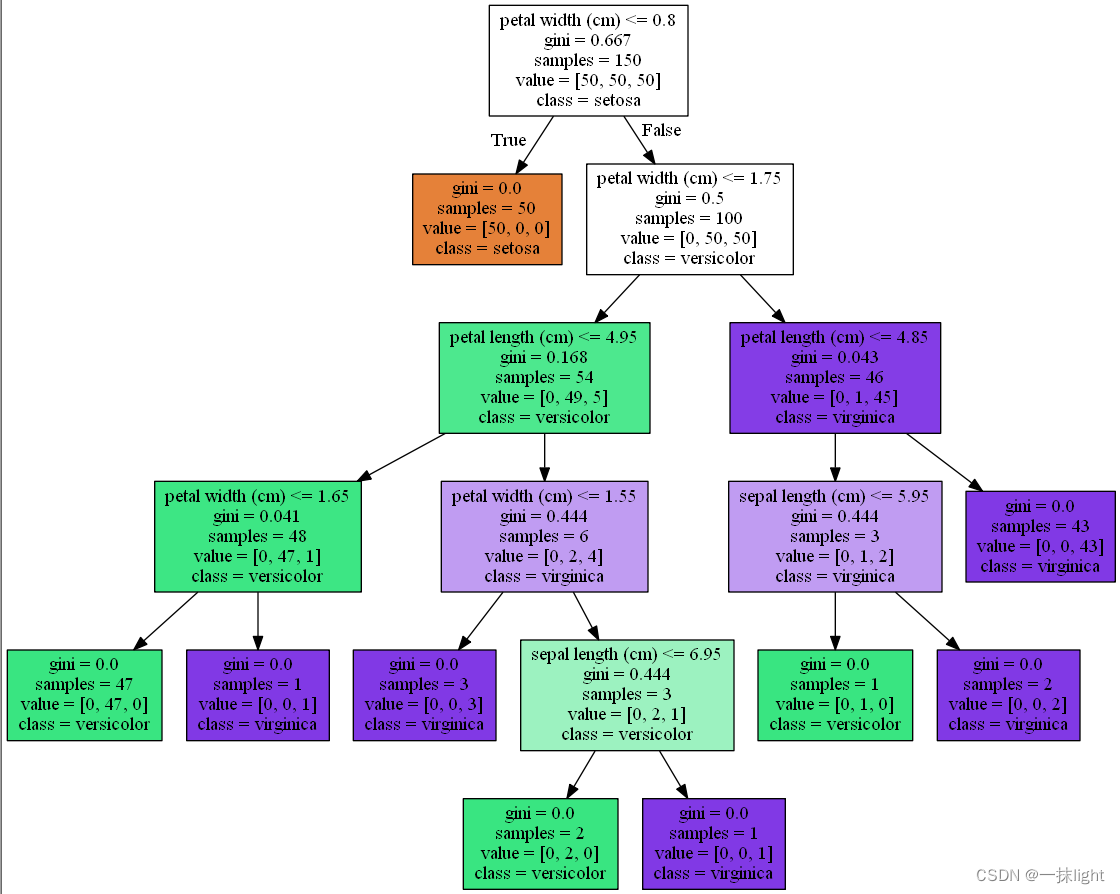

from sklearn.tree import export_graphviz
export_graphviz(ct,out_file = ' tree01.dot',
feature_names=iris.feature_names,
class_names=iris.target_names,filled=False)
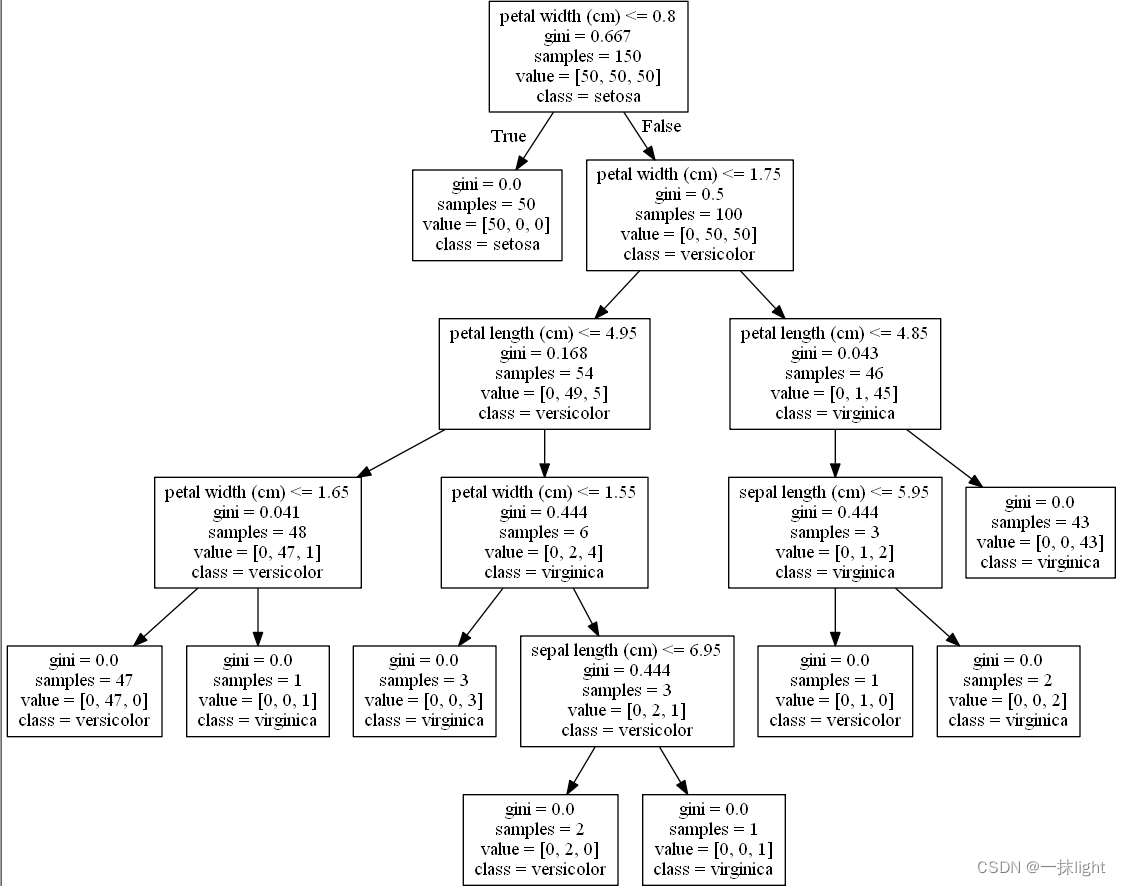
from sklearn.tree import export_graphviz
export_graphviz(ct,out_file = ' tree01.dot',
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True,rounded = True)