在项目当中遇到一种情况:我需要根据不同字段的值综合判断该数据属于我划分的哪种类型。
如果是单个字段我们可以根据kettle提供的switch / case 组件进行判断并赋值,但是如果通过多个字段或者是添加某种限定条件对数据整体进行处理,该组件的功能不足以支持。这种时候我开始怀念以前用java进行数据清洗,内存崩了的时候。java为我们数据清洗提供了更加广泛的维度,恰巧kettle提供的多种脚本工具当中就有java脚本
本次转换实现的功能:根据班级编码、班级名称、上课地点、授课教室四个字段综合判断是否排课、是否该排课
本次转换的主要流程:
1、从excel当中获取数据;
2、获取数据处理当天的时间;
3、从excel当中选取需要字段;
4、java脚本对选取字段处理;
5、将处理完的数据插入本地数据库;
接下来,配置详细图进行流程的演示
0、各种安装、配置环境请看鄙人文章(
kettle安装
)
1、从excel当中获取数据
该步骤主要是通过转换—>输入—>Excel输入 完成
Excel输入需要注意的几点
(1)、选择相对应的表格类型(引擎),一般情况下选择Excel 2007 XLSX (Apache POI Streaming)或者Excel 2007 XLSX (Apache POI )即可。
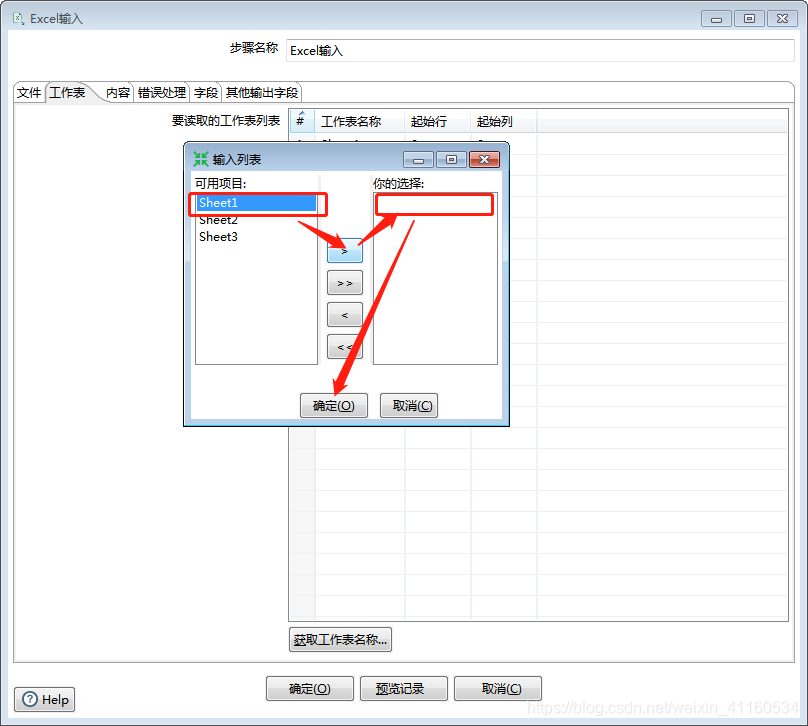
(2)、文件或目录。浏览找到之后,需要点击添加按钮。(此目录可以通过正则表达式对目录下的文件进行筛选)
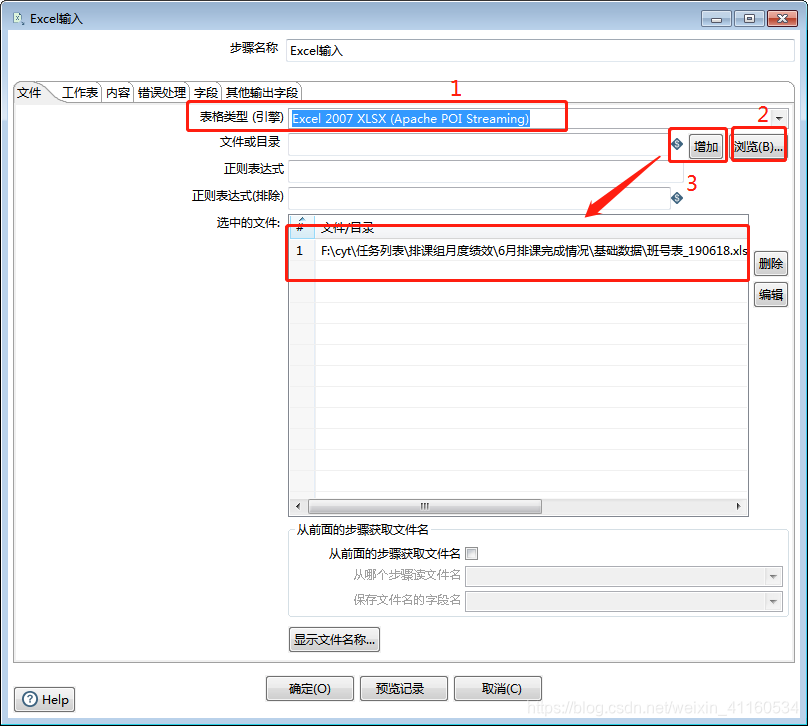
(3)、工作表需要选取读取的sheet。
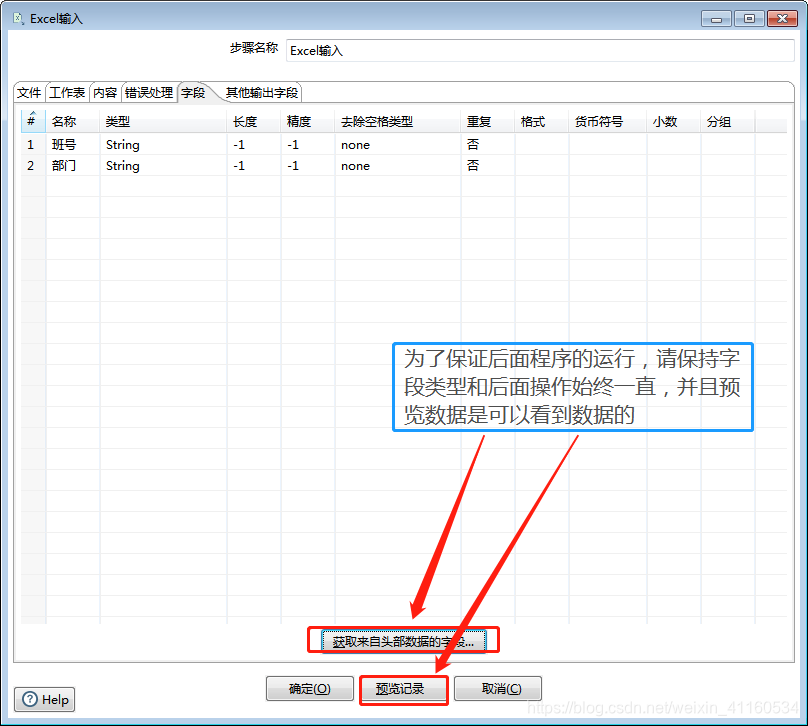
(4)、获取字段,并对字段进行相关操作(类型修改、去除空格、格式化、长度、精度)。(此处截图非实际项目截图,参考而已)
2、获取数据处理当天的时间
部分数据在处理时需要根据具体的时间获取部分数据进行处理,此处我的时间精度为天,因此我采用的组件为:获取系统信息
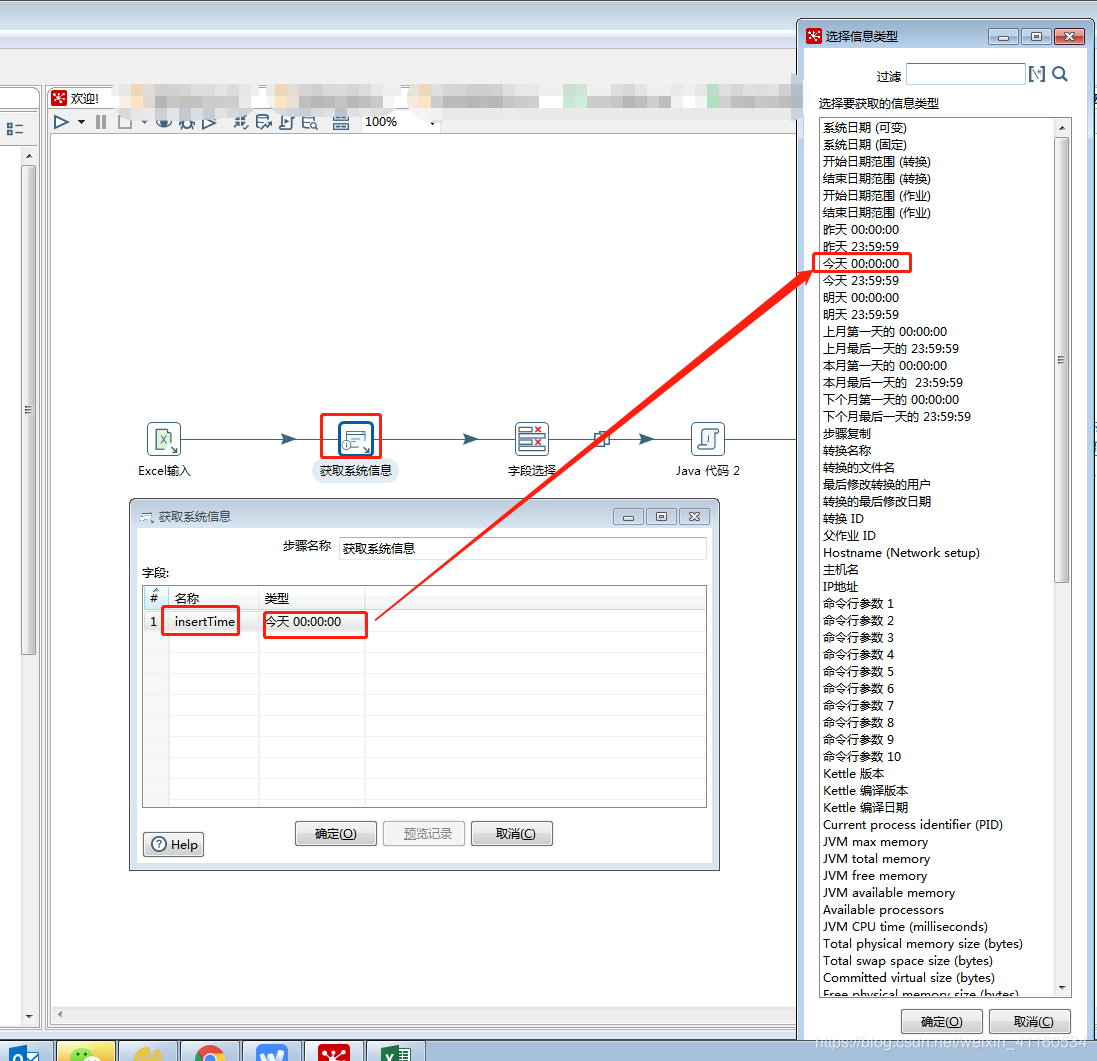
3、从excel当中选取需要字段
该步骤需要对excel当中的字段进行筛选,只需要筛选出我们需要的字段就可以。选择字段选择(转换—>字段选择)组件即可。该组件可以对字段的长度、类型、名称、格式等进行规范化。具体操作可以在元数据当中自己摸索。本步骤只需要进行选择和删除。
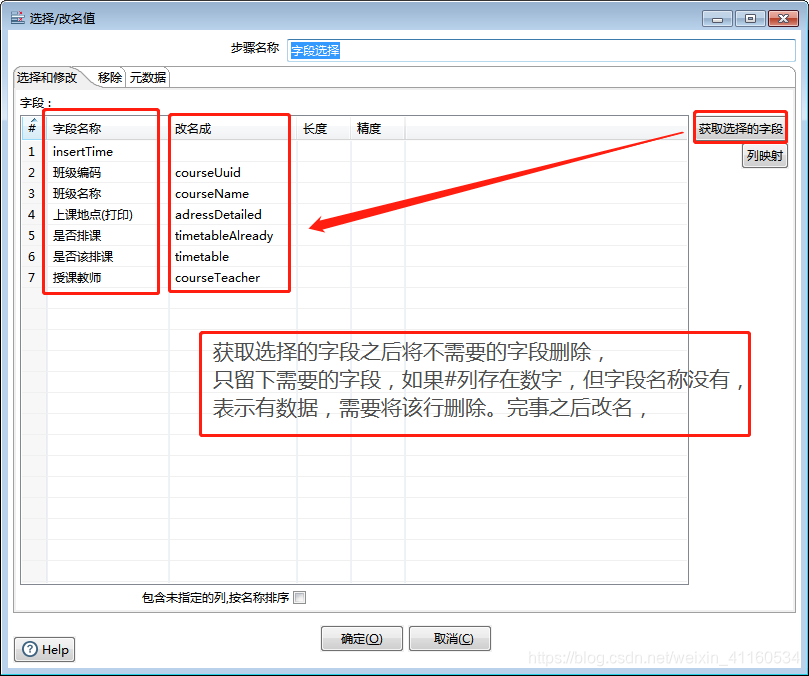
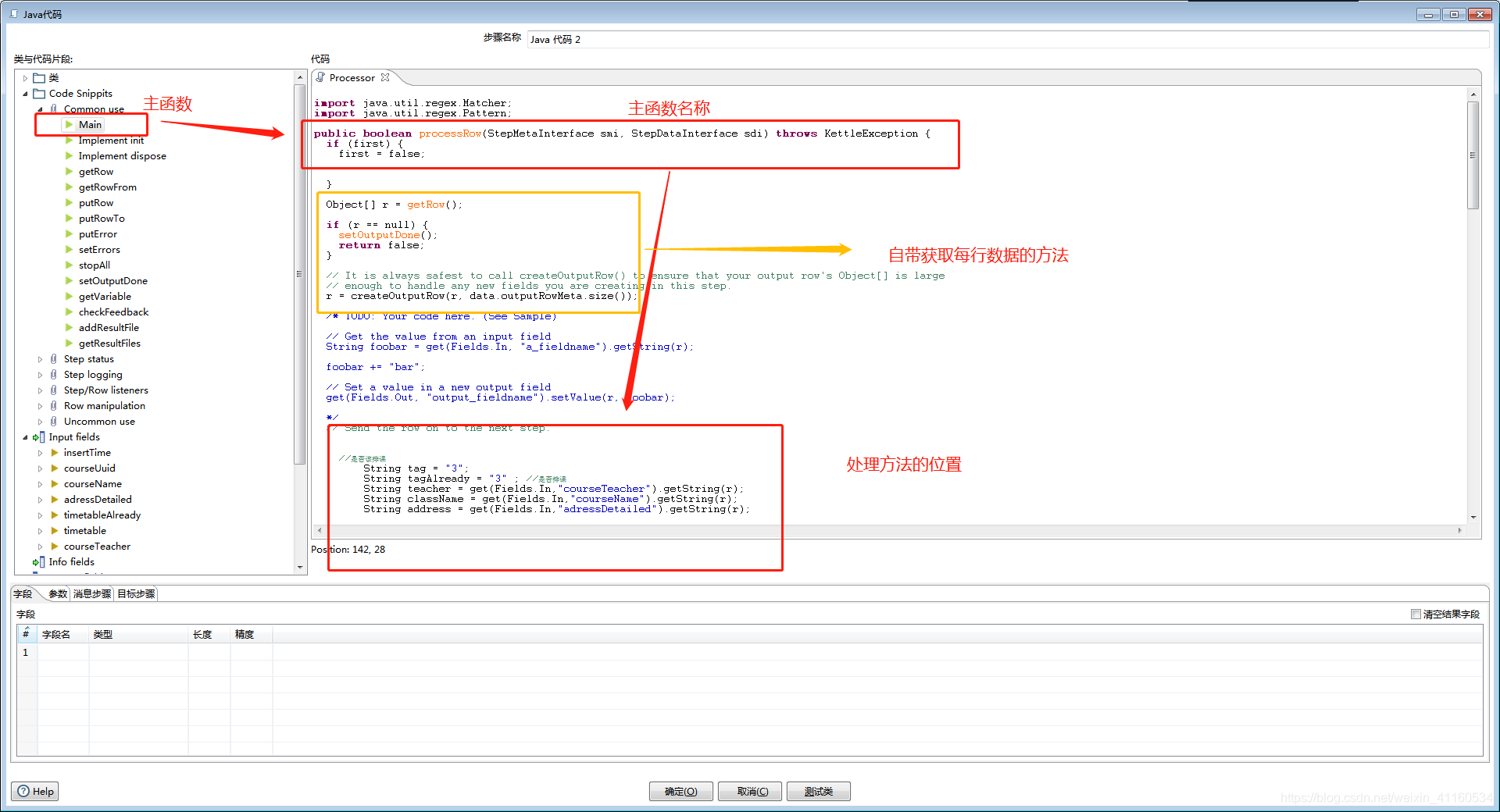
4、java脚本对选取字段处理
该脚本当中对数据是按照行处理的,很类似easyexcel的处理方式。
在获取数据时我们主要通过的方法为:get(Fields.In,”列名”).getString(r);
处理完之后对数据进行保存、更新操作的方法为:get(Fields.Out,”列名”).setValue(r,处理完之后的字段名);
在处理过程如果需要引用类,该类属于jdk自带的直接 import 即可。
如果引用的类为其他jar内,我们将相关jar放到D:\kettle\data-integration\lib路径下即可使用。
所有的处理内容需要放在 processRow 方法中。
获取变量和处理之后保存变量的方法如下
//获取变量名
String str = get(Fields.In,"班级名称").getString(r);
String str2 = str ;
//处理完成之后输出结果
get(Fields.Out,"新年级").setValue(r,str2);
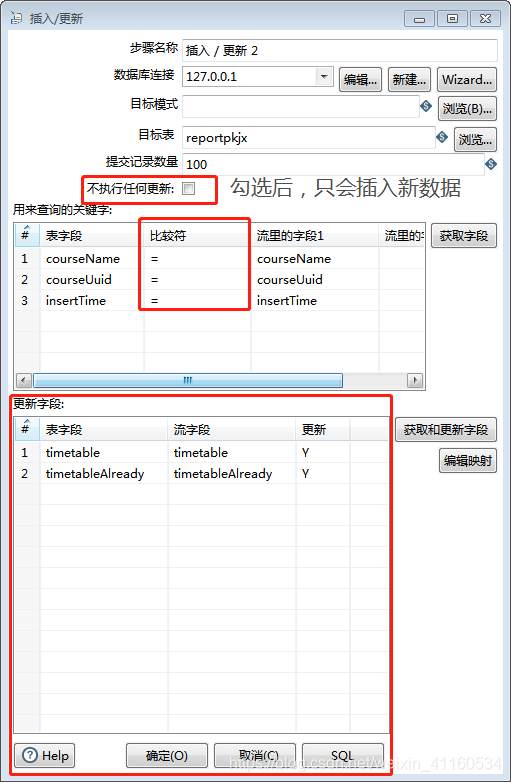
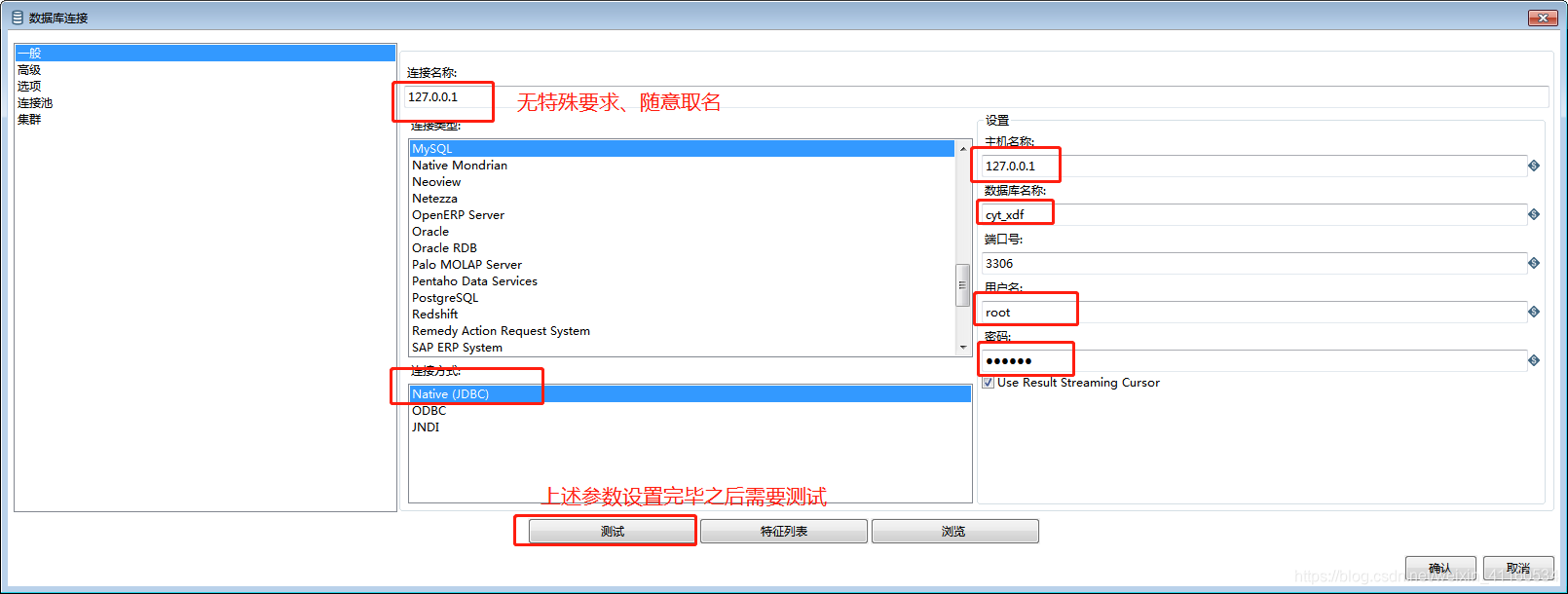
5、将处理完的数据插入本地数据库
放入数据库的方法很多,如果不需要查重可以使用组件表输出(输出——>表输出),如果需要查重可以使用组件插入/更新。
使用时注意事项:
(1)、需要链接数据库,需要将制定数据库的驱动文件(jar)放入到D:\kettle\data-integration\lib当中,不然会报错。
(2)、部分表需要增加一些选项,增加读写速度、插入速度、编码格式等。
1. 增加批量写的速度:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
cachePrepStmts = true
rewriteBatchedStatements = true
2. 增加读的速度:
useServerPrepStmts=true
cachePrepStmts
=true
参数说明:
1)useCompression=true,压缩数据传输,优化客户端和MySQL服务器之间的通信性能。
2)rewriteBatchedStatements=true ,开启批量写功能
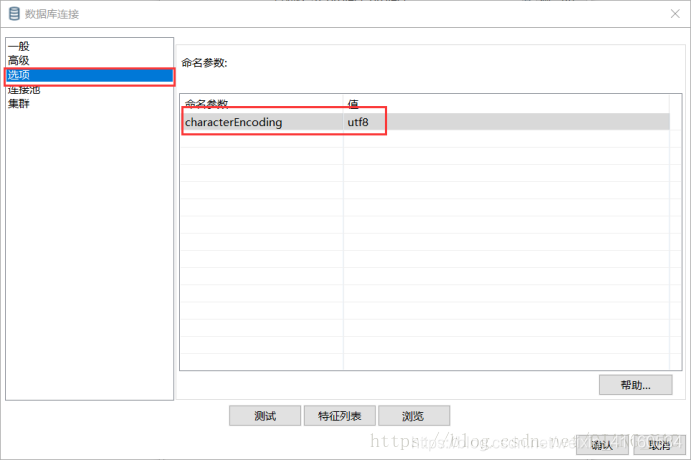

这样测试就成功了
(3)、根据表内字段和流内字段的关系设置查重标准。当该数据查重并未查到,则会插入一条新的数据,该数据取决于流入的数据。如果查询到重复数据将会执行(4)当中的更新操作。
(4)、设置更新字段。