笔记参考小王同学,
代码参考
我用的pycharm需要对代码做微小修改。
代码:
import matplotlib # 注意这个也要import一次
import matplotlib.pyplot as plt
import torch
from torch import nn
from d2l import torch as d2l
T = 1000
time = torch.arange(1, T + 1, dtype = torch.float32) # 1到1000为时间
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
d2l.plot(time, [x], 'time', 'x', xlim=[1,1000], figsize=(6,3))
plt.show()
我参考的代码没有画出图来,
经查阅需要加一行
plt.show()
我的编译器是pycharm所以需要加,jupter则不需要
补充知识点:

-
复习python切片
-
详细的逗号分割的切片复习
-
所以reshape(-1,1)表示(任意行,1列)
-
trainer.step() 是更新参数的函数
-
torch.optim.SGD 优化器
-
x.detach().numpy()的含义
-
nn.Sequential()的用法:
调用forward()方法进行前向传播时,for循环按照顺序遍历nn.Sequential()中存储的网络模块,并以此计算输出结果,并返回最终的计算结果。
lr = 0.03
epoches = 10
net = my_net()
train(net, lr, epoches)
# 检查模型预测下⼀个时间步的能⼒,也就是单步预测
onestep_preds = net(features)
所以说这一步经过net传入features以后已经返回给了 onestep_preds一个预测的列表。
其实可以打印一下onestep_preds的type,这里略。
那这样整个代码流程就梳理的很清楚了。
Tensor.numpy()将Tensor转化为ndarray,这里的Tensor可以是标量或者向量(与item()不同)转换前后的dtype不会改变
detach()就是返回一个新的tensor,并且这个tensor是从当前的计算图中分离出来的。但是返回的tensor和原来的tensor是共享内存空间的。
举个例子来说明一下detach有什么用。 如果A网络的输出被喂给B网络作为输入, 如果我们希望在梯度反传的时候只更新B中参数的值,而不更新A中的参数值,这时候就可以使用detach()
detach之后 就可以,单步预测了,这样梯度就不会回传。

-
代码里的问题
-
再补充讲解一个细节
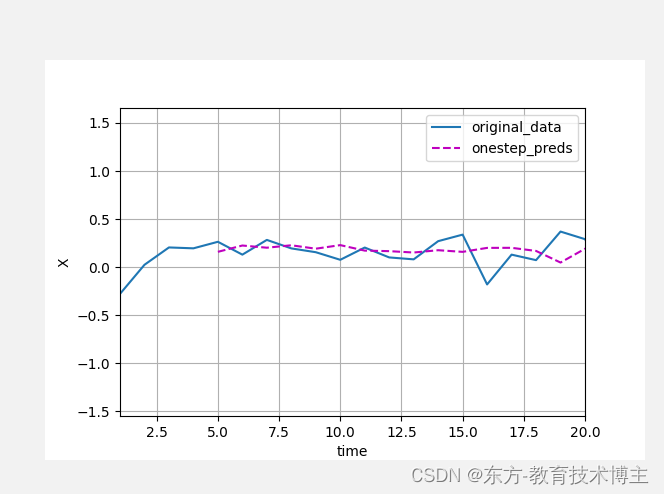
我把这里改成了1,20.
然后这个图是从5开始有数据的,
说明plot这个函数如果画多个线的话。

这里的方括号里面的第一个就是x,y以及对应的legend。
画多条的话就按照顺序一一对应。
# 检查模型预测下⼀个时间步的能⼒,也就是单步预测
onestep_preds = net(features)
d2l.plot([time, time[tau:]], [x.detach().numpy(), onestep_preds.detach().numpy()], 'time', 'X',
['original_data', 'onestep_preds'], [1, 20], figsize=(6, 3))
plt.show()
-
(重要!)代码逻辑多步预测和单步预测区别,是这样的:比如我用前4个预测后4个,那操作就是,先用前4个,预测第5个,然后把预测的5加入(不用真实的5,不然就成单步预测了),用2-5这四个,预测第6个,依次类推。。
pycharm可运行的完整代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
"""
@Project :深度学习入门
@File :序列模型.py
@Author :little_spice
@Date :2022/5/10 20:00
"""
import torch
from torch import nn
from d2l import torch as d2l
import pylab
import matplotlib # 注意这个也要import一次
import matplotlib.pyplot as plt
# 生成序列数据
T = 1000
# 生成1~T个时间步
time = torch.arange(1, T + 1, dtype=torch.float32)
# 加入随机噪声
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
# 调用d2l封装好的画图功能
d2l.plot(time, x, xlabel='time', xlim=[1, 1000], figsize=(6, 4))
"""
将这个序列转换为模型的“特征-标签”(feature-label)对
将数据映射为数据对yt = xt 和xt = [xt−τ , ... , xt−1]。
个人认为这里的转换太妙了!
"""
# tau是马尔科夫模型规定的长度
tau = 4
# 特征的行数为T-tau,因为前tau个数据都不够tau个时间步,特征列数为tau个
features = torch.zeros((T - tau, tau))
print(features)
# 这里的代码很妙,应该是转换的模版,不仅要理解,而且要记住
#遍历tau,这里i循环四次
for i in range(tau):
print(i)
features[:, i] = x[i:T - tau + i]
print(features)
print('x vlaue')
print(x)
print('x[tau:]')
print(x[tau:])
labels = x[tau:].reshape((-1, 1))
print(labels)
# 只用前n_train个数据进行训练
batch_size, n_train = 16, 600
train_iter = d2l.load_array((features[:n_train], labels[:n_train]), batch_size, is_train=True)
# 初始化⽹络权重的函数
def init_wight(m):
if type(m) == nn.Module:
nn.init.xavier_normal_(m.weight)
# ⼀个简单的多层感知机
# 本质上序列模型在做的就是一个简单的回归问题,用前tau个时间步数据预测第tau+1个时间步的数据
def my_net():
net = nn.Sequential(
nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1)
)
net.apply(init_wight)
return net
# 平⽅损失。注意:MSELoss计算平⽅误差时不带系数1/2
# reduction默认为mean,返回的是平均loss,是标量。这里用了None,则返回的是向量。
loss = nn.MSELoss(reduction='none')
# 训练过程
def train(net, lr, epoches):
trainer = torch.optim.SGD(net.parameters(), lr)
for epoch in range(epoches):
for X, y in train_iter:
# 先把梯度清零
trainer.zero_grad()
# 返回向量
l = loss(net(X), y)
# 反向传播
l.sum().backward()
# 梯度下降更新参数
trainer.step()
print(f'epoch:{epoch},loss:{d2l.evaluate_loss(net, train_iter, loss):f}')
lr = 0.03
epoches = 10
net = my_net()
train(net, lr, epoches)
# 检查模型预测下⼀个时间步的能⼒,也就是单步预测
onestep_preds = net(features)
d2l.plot([time, time[tau:]], [x.detach().numpy(), onestep_preds.detach().numpy()], 'time', 'X',
['original_data', 'onestep_preds'], [1, 1000], figsize=(6, 3))
plt.show()
# 检查多步预测能力
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):
multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1, -1)))
d2l.plot([time, time[tau:], time[n_train + tau:]], [x.detach().numpy(),
onestep_preds.detach().numpy(),
multistep_preds[n_train + tau:].detach().numpy()],
'time', 'x', legend=['data', '1-step preds', 'multistep preds'], xlim=[1, 1000], figsize=(8, 6))
"""
可以看到多步预测效果很差,这是因为误差会累计,每预测下一个时间步数据都用上次预测的结果作为输入,误差叠加会非常快。
基于k = 1, 4, 16, 64,通过对整个序列预测的计算,让我们更仔细地看⼀下k步预测的困难。
"""
plt.show()
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来⾃x的观测,其时间步从(i+1)到(i+T-tau-max_steps+1)
for i in range(tau):
features[:, i] = x[i:i + T - tau - max_steps + 1]
# 列i(i>=tau)是来⾃(i-tau+1)步的预测,其时间步从(i+1)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):
features[:, i] = net(features[:, i - tau:i]).reshape(-1)
steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],
[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',
legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000], figsize=(6, 3))
plt.show()
运行结果:
由于1000的运行结果太长了不好复制
# 生成序列数据
T = 100
改成了100.
然后看下运行结果:(这样少了很多 可以对比代码来看)
太长了,不复制了
因为一百次还是有点多,我又换成了20次。
简短清晰的可以看效果。
更明显。这里复制改成20次的运行结果:
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
0
tensor([[-0.0601, 0.0000, 0.0000, 0.0000],
[-0.1454, 0.0000, 0.0000, 0.0000],
[ 0.1080, 0.0000, 0.0000, 0.0000],
[-0.0168, 0.0000, 0.0000, 0.0000],
[-0.0961, 0.0000, 0.0000, 0.0000],
[ 0.0370, 0.0000, 0.0000, 0.0000],
[-0.0463, 0.0000, 0.0000, 0.0000],
[ 0.2162, 0.0000, 0.0000, 0.0000],
[-0.1409, 0.0000, 0.0000, 0.0000],
[ 0.1747, 0.0000, 0.0000, 0.0000],
[ 0.1533, 0.0000, 0.0000, 0.0000],
[ 0.3141, 0.0000, 0.0000, 0.0000],
[-0.0853, 0.0000, 0.0000, 0.0000],
[-0.0016, 0.0000, 0.0000, 0.0000],
[-0.0715, 0.0000, 0.0000, 0.0000],
[ 0.2855, 0.0000, 0.0000, 0.0000]])
1
tensor([[-0.0601, -0.1454, 0.0000, 0.0000],
[-0.1454, 0.1080, 0.0000, 0.0000],
[ 0.1080, -0.0168, 0.0000, 0.0000],
[-0.0168, -0.0961, 0.0000, 0.0000],
[-0.0961, 0.0370, 0.0000, 0.0000],
[ 0.0370, -0.0463, 0.0000, 0.0000],
[-0.0463, 0.2162, 0.0000, 0.0000],
[ 0.2162, -0.1409, 0.0000, 0.0000],
[-0.1409, 0.1747, 0.0000, 0.0000],
[ 0.1747, 0.1533, 0.0000, 0.0000],
[ 0.1533, 0.3141, 0.0000, 0.0000],
[ 0.3141, -0.0853, 0.0000, 0.0000],
[-0.0853, -0.0016, 0.0000, 0.0000],
[-0.0016, -0.0715, 0.0000, 0.0000],
[-0.0715, 0.2855, 0.0000, 0.0000],
[ 0.2855, 0.4048, 0.0000, 0.0000]])
2
tensor([[-0.0601, -0.1454, 0.1080, 0.0000],
[-0.1454, 0.1080, -0.0168, 0.0000],
[ 0.1080, -0.0168, -0.0961, 0.0000],
[-0.0168, -0.0961, 0.0370, 0.0000],
[-0.0961, 0.0370, -0.0463, 0.0000],
[ 0.0370, -0.0463, 0.2162, 0.0000],
[-0.0463, 0.2162, -0.1409, 0.0000],
[ 0.2162, -0.1409, 0.1747, 0.0000],
[-0.1409, 0.1747, 0.1533, 0.0000],
[ 0.1747, 0.1533, 0.3141, 0.0000],
[ 0.1533, 0.3141, -0.0853, 0.0000],
[ 0.3141, -0.0853, -0.0016, 0.0000],
[-0.0853, -0.0016, -0.0715, 0.0000],
[-0.0016, -0.0715, 0.2855, 0.0000],
[-0.0715, 0.2855, 0.4048, 0.0000],
[ 0.2855, 0.4048, -0.0703, 0.0000]])
3
tensor([[-0.0601, -0.1454, 0.1080, -0.0168],
[-0.1454, 0.1080, -0.0168, -0.0961],
[ 0.1080, -0.0168, -0.0961, 0.0370],
[-0.0168, -0.0961, 0.0370, -0.0463],
[-0.0961, 0.0370, -0.0463, 0.2162],
[ 0.0370, -0.0463, 0.2162, -0.1409],
[-0.0463, 0.2162, -0.1409, 0.1747],
[ 0.2162, -0.1409, 0.1747, 0.1533],
[-0.1409, 0.1747, 0.1533, 0.3141],
[ 0.1747, 0.1533, 0.3141, -0.0853],
[ 0.1533, 0.3141, -0.0853, -0.0016],
[ 0.3141, -0.0853, -0.0016, -0.0715],
[-0.0853, -0.0016, -0.0715, 0.2855],
[-0.0016, -0.0715, 0.2855, 0.4048],
[-0.0715, 0.2855, 0.4048, -0.0703],
[ 0.2855, 0.4048, -0.0703, 0.1139]])
x vlaue
tensor([-0.0601, -0.1454, 0.1080, -0.0168, -0.0961, 0.0370, -0.0463, 0.2162,
-0.1409, 0.1747, 0.1533, 0.3141, -0.0853, -0.0016, -0.0715, 0.2855,
0.4048, -0.0703, 0.1139, 0.2026])
x[tau:]
tensor([-0.0961, 0.0370, -0.0463, 0.2162, -0.1409, 0.1747, 0.1533, 0.3141,
-0.0853, -0.0016, -0.0715, 0.2855, 0.4048, -0.0703, 0.1139, 0.2026])
tensor([[-0.0961],
[ 0.0370],
[-0.0463],
[ 0.2162],
[-0.1409],
[ 0.1747],
[ 0.1533],
[ 0.3141],
[-0.0853],
[-0.0016],
[-0.0715],
[ 0.2855],
[ 0.4048],
[-0.0703],
[ 0.1139],
[ 0.2026]])
epoch:0,loss:0.029287
epoch:1,loss:0.029200
epoch:2,loss:0.029124
epoch:3,loss:0.029051
epoch:4,loss:0.028981
epoch:5,loss:0.028913
epoch:6,loss:0.028848
epoch:7,loss:0.028783
epoch:8,loss:0.028708
epoch:9,loss:0.028635
沐神答疑环节