Java-8-流(2)
map
如果有一个函数可以将一种类型的值转换成另外一种类型, map 操作就可以使用该函数,将一个流中的值转换成一个新的流
使用 for 循环将字符串转换为大写
public static void main(String[] args) {
List<String> collected = new ArrayList<>();
for (String string : asList("a", "b", "hello")) {
String uppercaseString = string.toUpperCase();
collected.add(uppercaseString);
}
System.out.println(collected);
}
使用 map 操作将字符串转换为大写形式
List<String> strings = Stream.of("a", "b", "hello")
.map(s -> s.toUpperCase())
.collect(Collectors.toList());
System.out.println(strings);
对象列表 – >其他对象列表
public class OldUser {
private String name;
private int age;
private String note;
public OldUser() {
}
public OldUser(String name, int age, String note) {
this.name = name;
this.age = age;
this.note = note;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getNote() {
return note;
}
public void setNote(String note) {
this.note = note;
}
@Override
public String toString() {
return "OldUser{" +
"name='" + name + '\'' +
", age=" + age +
", note='" + note + '\'' +
'}';
}
}
public static void main(String[] args) {
List<User> users = User_Data.create();
List<OldUser> oldUsers = users.stream()
.map(
user ->
{
OldUser oldUser = new OldUser();
oldUser.setName(user.getName());
oldUser.setAge(user.getAge());
if (user.getAge() > 60){
oldUser.setNote("老人");
}
return oldUser;
}
).collect(Collectors.toList());
System.out.println(oldUsers);
//[OldUser{name='张0', age=79, note='老人'},
// OldUser{name='许1', age=89, note='老人'},
// OldUser{name='陈2', age=65, note='老人'},
// OldUser{name='王3', age=40, note='null'},
// OldUser{name='许4', age=74, note='老人'},
// OldUser{name='刘5', age=90, note='老人'},
// OldUser{name='张6', age=1, note='null'},
// OldUser{name='刘7', age=38, note='null'},
// OldUser{name='刘8', age=46, note='null'},
// OldUser{name='陈9', age=41, note='null'},
// OldUser{name='陈10', age=0, note='null'},
// OldUser{name='张11', age=30, note='null'},
// OldUser{name='刘12', age=26, note='null'},
// OldUser{name='陈13', age=70, note='老人'},
// OldUser{name='许14', age=34, note='null'},
// OldUser{name='许15', age=25, note='null'},
// OldUser{name='王16', age=36, note='null'},
// OldUser{name='许17', age=94, note='老人'},
// OldUser{name='王18', age=97, note='老人'}, OldUser{name='张19', age=76, note='老人'},
// OldUser{name='刘20', age=96, note='老人'}, OldUser{name='许21', age=33, note='null'},
// OldUser{name='刘22', age=12, note='null'}, OldUser{name='张23', age=11, note='null'}, OldUser{name='张24', age=52, note='null'},
// OldUser{name='刘25', age=83, note='老人'}, OldUser{name='陈26', age=1, note='null'}, OldUser{name='许27', age=13, note='null'},
// OldUser{name='刘28', age=98, note='老人'}, OldUser{name='陈29', age=99, note='老人'}]
}
map 和 flatMap
假设有一个包含多个列表的流,现在希望得到所有数字的序列:
List<Integer> list1 = Arrays.asList(
1,2,3,4,56
);
List<Integer> list2 = Arrays.asList(
256,455,45,65665,565
);
List<Integer> list3 = Arrays.asList(
0,59,1454,5656,6554,21546
);
想把上面三个列表合并成一个,里面存放所有集合中的数字:
希望得到:
[1, 2, 3, 4, 56, 256, 455, 45, 65665, 565, 0, 59, 1454, 5656, 6554, 21546]
使用map
Stream.of(
list1,list2,list3
).map(Function.identity()).collect(Collectors.toList());
使用这个操作后得到的是:
List<List<Integer>>
map方法是将指定的Stream中元素进行“平级”处理,每个元素转化为各自所对应的一个Stream集合,输入与输出是一对一的关系,若进一步获取各个子Stream中的元素,还需要逐个遍历子集合
使用flatMap
Stream.of(list1,list2,list3)
.flatMap(list -> list.stream())
.map(Function.identity()).collect(Collectors.toList());
得到的就是我们想要的:
List<Integer>
flatMap将原有Stream中的元素进行转化为新的子Stream集合,同时对子Stream中的元素进行“跨级”处理,原有的Stream通过一次flatMap之后得到的不是各个子Stream的集合,而是各个子Steam集合中的元素的总集合,也就是对各个子Stream结合进行二次遍历取出中的元素,融合到一个总集合中
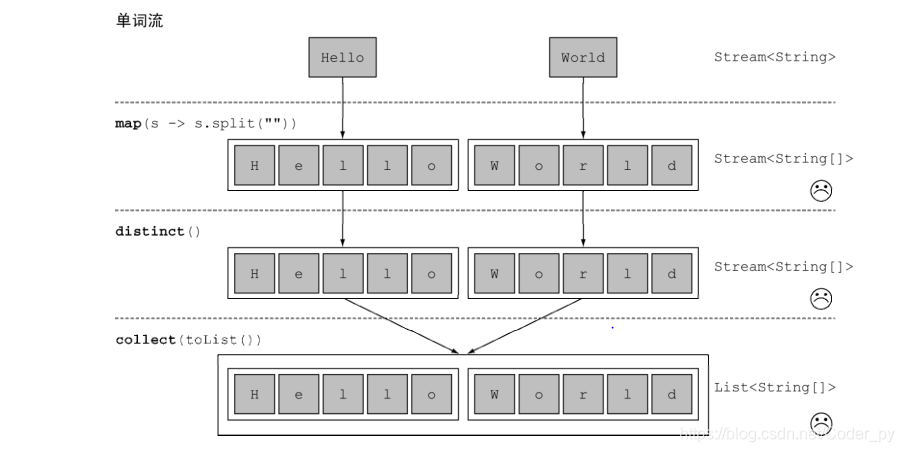
再比如:
对于一张单词 表 , 如 何 返 回 一 张 列 表 , 列 出 里 面 各 不 相 同 的 字 符 呢
String[] words = new String[]{"Hello","World"};
List<String[]> a = Arrays.stream(words)
.map(word -> word.split(""))
.distinct()
.collect(Collectors.toList());
//[H, e, l, l, o]
//[W, o, r, l, d]
for (String[] s : a){
System.out.println(Arrays.toString(s));
}
过程:
List<String> dis = Arrays.stream(words)
.map(word -> word.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
System.out.println(dis);
过程:

flatMap升维
给定列表[1, 2, 3]和列表[3, 4],应该返回[(1, 3), (1, 4), (2, 3), (2, 4), (3, 3), (3, 4)]
public static void main(String[] args) {
List<Integer> numbers1 = Arrays.asList(1, 2, 3);
List<Integer> numbers2 = Arrays.asList(3, 4);
// flatMap升维度
List<int[]> pairs = numbers1.stream().flatMap(x -> numbers2.stream().map(y -> new int[] { x, y }))
.collect(Collectors.toList());
for (int[] pair : pairs) {
System.out.println(Arrays.toString(pair));
}
System.out.println("---------------");
List<String> first= Arrays.asList("one", "two", "three", "four");
List<String> second= Arrays.asList("A", "B", "C", "D");
Stream.of(first,second).flatMap(Collection::stream).forEach(System.out::print);
}
public static void main(String[] args) {
List<String> first= Arrays.asList("one", "two", "three", "four");
List<String> second= Arrays.asList("A", "B", "C", "D");
//不使用lambda表达式
first.stream()
.flatMap(new Function<String, Stream<String>>() {
//f是first发出的元素
public Stream<String> apply(String f) {
return second.stream().map(new Function<String, String>() {
//s是second发出的元素
public String apply(String s) {
return String.format("%s,%s \n", f, s);
}
});
}
})
.forEach(System.out::println);
//使用lambda表达式
System.out.println("-------------------");
first.stream()
.flatMap(f -> second.stream().map(s -> String.format("%s,%s ", f, s)))
.forEach(System.out::println);
}
filter
遍历数据并检查其中的元素时,可尝试使用 Stream 中提供的新方法 filter
public class Person {
private String name;
private int age;
private String sex;
public Person() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
'}';
}
}
public class Person_Data {
static Random random = new Random();
static String[] sexs = new String[]
{
"male",
"female"
};
public static List<Person> people(){
List<Person> people = new ArrayList<>();
for (int i = 0; i < 15; i++) {
Person person = new Person();
person.setAge(random.nextInt(60));
person.setSex(sexs[random.nextInt(sexs.length)]);
person.setName(i + "号");
people.add(person);
}
return people;
}
public static void main(String[] args) {
for (Person person : people()){
System.out.println(person);
}
}
}
public class M1 {
// 只选取男性
public static List<Person> getMale(List<Person> people){
return people.stream()
.filter(person -> person.getSex().equals("male"))
.collect(Collectors.toList());
}
//选取年龄大于40岁的人
public static List<Person> getOld(List<Person> people){
return people.stream()
.filter(person -> person.getAge() > 40)
.collect(Collectors.toList());
}
public static void main(String[] args) {
List<Person> people = Person_Data.people();
for (Person person:getMale(people)){
System.out.println(person);
}
System.out.println("--------------------------");
for (Person person:getOld(people)){
System.out.println(person);
}
}
}
reduce
reduce方法用于对stream中元素进行聚合求值,最常见的用法就是将stream中一连串的值合成为单个值,比如为一个包含一系列数值的数组求和
//reduce方法有三个重载的方法,方法签名如下
Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
第一个方法的应用:
public static void main(String[] args) {
//代码实现了对numList中的元素累加。lambada表达式的a参数是表达式的执行结果的缓存,也就是表达式这一次的执行结果会被作为下一次执行的参数,而第二个参数b则是依次为stream中每个元素。如果表达式是第一次被执行,a则是stream中的第一个元素
List<Integer> numList = Arrays.asList(1,2,3,4,5);
int res = numList.stream().reduce((a,b) -> a + b).get();
System.out.println(res);
System.out.println("----------------------------");
//查看整个过程
int res_2 = numList.stream()
.reduce((x,y) ->
{
System.out.println("x = "+
x +
", y = " + y);
return x+y;
}).get();
//表达式被调用了4次, 第一次a和b分别为stream的第一和第二个元素,因为第一次没有中间结果可以传递, 所以 reduce方法实现为直接将第一个元素作为中间结果传递。
System.out.println(res_2);
}
第二个方法的应用:
public static void main(String[] args) {
List<Integer> numList = Arrays.asList(1,2,3,4,5);
int res = numList.stream()
.reduce(0,(x,y) -> x+y);
//第一种比第一种仅仅多了一个字定义初始值罢了。 此外,因为存在stream为空的情况,所以第一种实现并不直接方法计算的结果,而是将计算结果用Optional来包装,我们可以通过它的get方法获得一个Integer类型的结果,而Integer允许null。第二种实现因为允许指定初始值,因此即使stream为空,也不会出现返回结果为null的情况,当stream为空,reduce为直接把初始值返回。
System.out.println(res);
int res_2 = numList.stream()
.reduce(10,(x,y) -> x+y);
System.out.println(res_2);
}
第三个方法的应用:
public static void main(String[] args) {
List<Integer> numList = Arrays.asList(Integer.MAX_VALUE,Integer.MAX_VALUE);
long res = numList.stream()
.reduce(0L,(x,y) -> x+y,(x,y) -> 0L);
//第三种签名的用法相较前两种稍显复杂,犹豫前两种实现有一个缺陷,它们的计算结果必须和stream中的元素类型相同,如上面的代码示例,stream中的类型为int,那么计算结果也必须为int,这导致了灵活性的不足,甚至无法完成某些任务, 比入我们咬对一个一系列int值求和,但是求和的结果用一个int类型已经放不下,必须升级为long类型,此实第三签名就能发挥价值了,它不将执行结果与stream中元素的类型绑死。
System.out.println(res);
List<Integer> numList_1 = Arrays.asList(1, 2, 3, 4, 5, 6);
ArrayList<String> result = numList_1.stream().reduce(new ArrayList<String>(), (a, b) -> {
a.add("element-" + Integer.toString(b));
return a;
}, (a, b) -> null);
System.out.println(result);
}
public static void main(String[] args) {
List<Integer> list = Arrays.asList(
1554,565,5658,55
);
//找出最大值
System.out.println(
list.stream()
.reduce(Integer::max).get()
);
//统计集合里面多少个元素
System.out.println(
list.stream()
.collect(Collectors.counting())
);
统计集合里面多少个元素
System.out.println(
list.stream()
.map(integer -> integer = 1)
.reduce(0,(x,y) -> x+y)
);
}
public static void main(String[] args) {
System.out.println(
Stream.of(
"a","b","c","d"
).reduce(String::concat).get()
);
System.out.println(
Stream.of(
"a","b","c","d"
).reduce("F---",String::concat)
);
}
Stream.distinct()
distinct()返回由该流的不同元素组成的流。distinct()是Stream接口的方法。distinct()使用hashCode()和equals()方法来获取不同的元素。因此,我们的类必须实现hashCode()和equals()方法。如果distinct()正在处理有序流,那么对于重复元素,将保留以遭遇顺序首先出现的元素,并且以这种方式选择不同元素是稳定的。在无序流的情况下,不同元素的选择不一定是稳定的,是可以改变的。distinct()执行有状态的中间操作。在有序流的并行流的情况下,保持distinct()的稳定性是需要很高的代价的,因为它需要大量的缓冲开销。如果我们不需要保持遭遇顺序的一致性,那么我们应该可以使用通过BaseStream.unordered()方法实现的无序流
例子:
public static void main(String[] args) {
List<String> list = Arrays.asList("AA", "BB", "CC", "BB", "CC", "AA", "AA");
long i = list.stream().distinct().count();
System.out.println(i);
String output = list.stream().distinct().collect(Collectors.joining(","));
System.out.println(output);
}
public class Book {
private String name;
private int price;
public Book(String name, int price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public int getPrice() {
return price;
}
@Override
public boolean equals(final Object obj) {
if (obj == null) {
return false;
}
final Book book = (Book) obj;
if (this == book) {
return true;
} else {
return (this.name.equals(book.name) && this.price == book.price);
}
}
@Override
public int hashCode() {
int hashno = 7;
hashno = 13 * hashno + (name == null ? 0 : name.hashCode());
return hashno;
}
}
public static void main(String[] args) {
List<Book> list = new ArrayList<>();
{
list.add(new Book("Core Java", 200));
list.add(new Book("Core Java", 200));
list.add(new Book("Learning Freemarker", 150));
list.add(new Book("Spring MVC", 300));
list.add(new Book("Spring MVC", 300));
}
long l = list.stream().distinct().count();
System.out.println("No. of distinct books:"+l);
System.out.println("-----------------");
list.stream().distinct().forEach(b -> System.out.println(b.getName()+ "," + b.getPrice()));
}
如果不方便去重写equals和hashCode方法,有没有方法去实现去重功能呢,答案是肯定的
public static void main(String[] args) {
List<Book> list = new ArrayList<>();
{
list.add(new Book("Core Java", 200));
list.add(new Book("Core Java", 300));
list.add(new Book("Learning Freemarker", 150));
list.add(new Book("Spring MVC", 200));
list.add(new Book("Hibernate", 300));
}
list.stream().filter(distinctByKey(b -> b.getName()))
.forEach(b -> System.out.println(b.getName() + "," + b.getPrice()));
}
//distinctByKey()方法返回一个使用ConcurrentHashMap 来维护先前所见状态的 Predicate 实例
private static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) {
Map<Object, Boolean> seen = new ConcurrentHashMap<>();
return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null;
}
limit方法
流支持 limit(n) 方法,该方法会返回一个不超过给定长度的流。所需的长度作为参数传递给 limit
public static void main(String[] args) {
Random random = new Random();
List<Integer> list= new ArrayList<>();
for (int i = 0; i < 30; i++) {
list.add(random.nextInt(598));
}
list.stream()
.filter( integer -> integer % 3 == 0)
.limit(10)
.forEach(System.out::println);
}
只要limit()达到最大项数,它就不再消耗任何项,只返回结果流。因此,我们说limit()是一种短路操作
skip()方法
skip方法是一个中间操作,跳过stream中的前n个元素,n不能为负值。如果n大于stream的大小,则返回空stream。
public static void main(String[] args) {
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
.filter(integer -> integer % 2 == 0)
.skip(3)
.forEach(System.out::println);
//上面的代码中,获取流中的偶数,并跳过前3个
}
上面的stream在执行的时候,forEach处理每个元素的时候,当到skip()的时候,skip知道前两项必须被丢弃,因此它们不会将添加到结果流中。之后,它会创建并返回包含其余项目的流。为了做到这一点,skip()操作必须保持元素的状态。出于这个原因,我们说skip()是一个有状态操作
结合skip()和limit()
private static List<Integer> getEvenNumbers(int offset, int limit) {
return Stream.iterate(0, i -> i + 1)
.filter(i -> i % 2 == 0)
.skip(offset)
.limit(limit)
.collect(Collectors.toList());
}
public static void main(String[] args) {
System.out.println(getEvenNumbers(1,10));
System.out.println(getEvenNumbers(2,10));
}
allMatch 、 anyMatch 、 noneMatch 、 findFirst、findAny
-
anyMatch表示,判断的条件里,任意一个元素成功,返回true
-
allMatch表示,判断条件里的元素,所有的都是,返回true
-
noneMatch跟allMatch相反,判断条件里的元素,所有的都不是,返回true
public static void main(String[] args) {
List<String> strs = Arrays.asList("a", "a", "a", "a", "b");
boolean aa = strs.stream().anyMatch(str -> str.equals("a"));
boolean bb = strs.stream().allMatch(str -> str.equals("a"));
boolean cc = strs.stream().noneMatch(str -> str.equals("a"));
long count = strs.stream().filter(str -> str.equals("a")).count();
System.out.println(aa);// TRUE
System.out.println(bb);// FALSE
System.out.println(cc);// FALSE
System.out.println(count);
}
findFirst和findAny,通过名字,就可以看到,对这个集合的流,做一系列的中间操作后,可以调用findFirst,返回集合的第一个对象,findAny返回这个集合中,取到的任何一个对象;通过这样的描述,我们也可以知道,在串行的流中,findAny和findFirst返回的,都是第一个对象;而在并行的流中,findAny返回的是最快处理完的那个线程的数据,所以说,在并行操作中,对数据没有顺序上的要求,那么findAny的效率会比findFirst要快的
public static void main(String[] args) {
List<String> strs = Arrays.asList("d", "b", "a", "c", "a");
Optional<String> aa = strs.stream()
.filter(s -> !s.equals("a")).findFirst();
System.out.println(aa.get());
System.out.println("------------------");
Optional<String> bb = strs.stream()
.filter(s -> !s.equals("a")).findAny();
System.out.println(bb.get());
System.out.println("------------------");
}
stream.sorted()
-
sorted() 默认使用自然序排序, 其中的元素必须实现Comparable 接口
-
sorted(Comparator<? super T> comparator) :我们可以使用lambada 来创建一个Comparator 实例。可以按照升序或着降序来排序元素
public class Student implements Comparable<Student>{
private int id;
private String name;
private int age;
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student ob) {
return name.compareTo(ob.getName());
}
@Override
public boolean equals(final Object obj) {
if (obj == null) {
return false;
}
final Student std = (Student) obj;
if (this == std) {
return true;
} else {
return (this.name.equals(std.name) && (this.age == std.age));
}
}
@Override
public int hashCode() {
int hashno = 7;
hashno = 13 * hashno + (name == null ? 0 : name.hashCode());
return hashno;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class N1 {
public static void main(String[] args) {
List<Student> list = new ArrayList<Student>();
list.add(new Student(1, "Mahesh", 12));
list.add(new Student(2, "Suresh", 15));
list.add(new Student(3, "Nilesh", 10));
//Natural Sorting by Name
List<Student> students = list.stream()
.sorted()
.collect(Collectors.toList());
students.forEach(System.out::println);
System.out.println("-------------------------------------");
//Natural Sorting by Name in reverse order
List<Student> students_1 = list.stream()
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
students_1.forEach(System.out::println);
System.out.println("-------------------------------------");
//Sorting using Comparator by Age
List<Student> students_2 = list.stream()
.sorted(Comparator.comparingInt(Student::getAge))
.collect(Collectors.toList());
students_2.forEach(System.out::println);
System.out.println("-------------------------------------");
//Sorting using Comparator by Age with reverse order
List<Student> students_3 = list.stream()
.sorted(Comparator.comparing(Student::getAge).reversed())
.collect(Collectors.toList());
students_3.forEach(System.out::println);
}
}
原始类型流特化
Java 8引入了三个原始类型特化流接口来解决这个问题: IntStream 、 DoubleStream 和LongStream ,分别将流中的元素特化为 int 、 long 和 double ,从而避免了暗含的装箱成本
java.util.stream.IntStream
方法
//返回子序列 [a,b),左闭又开。意味着包括 b 元素,增长步值为 1
rangeClosed(a,b)
//返回子序列 [a,b),左闭右开,意味着不包括 b
range(a,b)
//计算所有元素的总和
sum
//排序元素
sorted
public static void main(String[] args) {
IntStream.rangeClosed(1,10)
.map(i -> i*i)
.forEach(System.out::println);
System.out.println("---------------------------");
IntStream.range(1,10)
.map(x->x*x)
.forEach(System.out::println);
System.out.println("---------------------------");
System.out.println(IntStream.rangeClosed(1,50).sum());
System.out.println("---------------------------");
IntStream.of(
1,2,30,8,44,4
).sorted()
.forEach(System.out::println);
}
LongStream
public static void main(String[] args) {
System.out.println("--Using LongStream.rangeClosed--");
LongStream.rangeClosed(13, 15).map(n->n*n).forEach(s->System.out.print(s +" "));
System.out.println("\n--Using LongStream.range--");
LongStream.range(13,15).map(n->n*n).forEach(s->System.out.print(s +" "));
System.out.println("\n--Sum of range 1 to 10--");
System.out.print(LongStream.rangeClosed(1,10).sum());
System.out.println("\n--Sorted number--");
LongStream.of(13,4,15,2,8).sorted().forEach(s->System.out.print(s +" "));
}
DoubleStream
java.util.stream.LongStream 是一个原始双精度浮点型序列 ( sequence ) 。该流提供了许多方法可以对该流中的元素顺序执行或并行执行一些聚合操作。它的使用方式和 IntStream 一样,提供的方法也一样,除此之外,还额外提供了几个聚合方法
public static void main(String[] args) {
System.out.println("--Using DoubleStream.of--");
DoubleStream.of(5.33,2.34,5.32,2.31,3.51).map(d->d*1.5).forEach(s->System.out.print(s +" "));
System.out.println("\n--Using DoubleStream.average--");
double val = DoubleStream.of(12.1,11.2,13.3).average().getAsDouble();
System.out.println(val);
System.out.println("--Using DoubleStream.max--");
val = DoubleStream.of(12.1,11.2,13.3).max().getAsDouble();
System.out.println(val);
System.out.println("--Using DoubleStream.filter--");
DoublePredicate range = d -> d > 12.11 && d < 12.99;
DoubleStream.of(12.1,11.2,12.3).filter(range).forEach(d->System.out.print(d));
//--Using DoubleStream.of--
//7.995 3.51 7.98 3.465 5.265
//--Using DoubleStream.average--
//12.200000000000001
//--Using DoubleStream.max--
//13.3
//--Using DoubleStream.filter--
//12.3
}
映射到数值流:将流转换为特化版本的常用方法是mapToInt、mapToDouble和mapToLong。这些方法和前 面说的map方法的工作方式一样,只是它们返回的是一个特化流,而不是Stream
List<User> users = User.supplier();
//统计所有人的年龄
int ages = users.stream()
.mapToInt(User::getAge)返回IntStream
.sum();
System.out.println(ages);
通过 box 方法可以将数值流转化为 Stream 非特化流。
public static void main(String[] args) {
List<User> users = User.supplier();
//统计所有人的年龄
int ages = users.stream()
.mapToInt(User::getAge)返回IntStream
.sum();
System.out.println(ages);
System.out.println("------------------");
IntStream intStream = users.stream().mapToInt(User::getAge); //将Strean转化为数值流
Stream<Integer> stream = intStream.boxed(); //将数值流转化为Stream
}