前言
在介绍zookeeper(下文用zk代替)实现分布式锁的机制之前,先粗略介绍一下zk是什么东西:
Zookeeper是一种提供配置管理、分布式协同以及命名的中心化服务。
zk的模型是这样的:zk包含一系列的节点,叫做znode,就好像文件系统一样每个znode表示一个目录,然后znode有一些特性:
- 有序节点:
假如当前有一个父节点为/lock,我们可以在这个父节点下面创建子节点;
zookeeper提供了一个可选的有序特性,例如我们可以创建子节点“/lock/node-”并且指明有序,那么zookeeper在生成子节点时会根据当前的子节点数量自动添加整数序号
也就是说,如果是第一个创建的子节点,那么生成的子节点为/lock/node-0000000000,下一个节点则为/lock/node-0000000001,依次类推。
- 临时节点:
客户端可以建立一个临时节点,在会话结束或者会话超时后,zookeeper会自动删除该节点。
- 事件监听:
在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:
- 节点创建
- 节点删除
- 节点数据修改
- 子节点变更
基于以上的一些zk的特性,我们很容易得出使用zk实现分布式锁的落地方案:
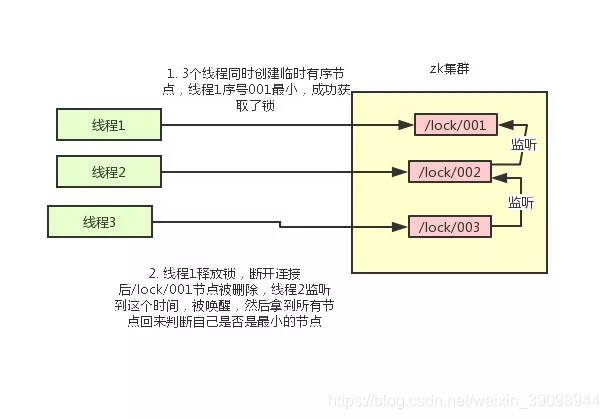
- 使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
- 创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
- 如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
- 如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
比如当前线程获取到的节点序号为/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:
具体的实现思路就是这样,至于代码怎么写,这里比较复杂就不贴出来了。
Curator介绍
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。
他的使用方式也比较简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock");
interProcessMutex.acquire();
interProcessMutex.release()<