MongoDB在大数据场景下的应用
MongoDB概述
-
MongoDB是一个开源的NoSQL数据库
- 使用C++编写的具有动态模式的面向文档的数据库
- 动态模式支持流畅的多态性
- 将数据存储在类似JSON的文档中(BSON)
- 使用文档(对象) 更趋近于许多编程语言
-
MongoDB特点
- 高性能
- 易部署
- 易使用
- 存储数据非常方便

MongoDB数据模型与RDBMS对比
| RDBMS | MongoDB |
|---|---|
| DataBase | DataBase |
| Table | Collection |
| Index | Index |
| Row | Document |
| Column | Field |
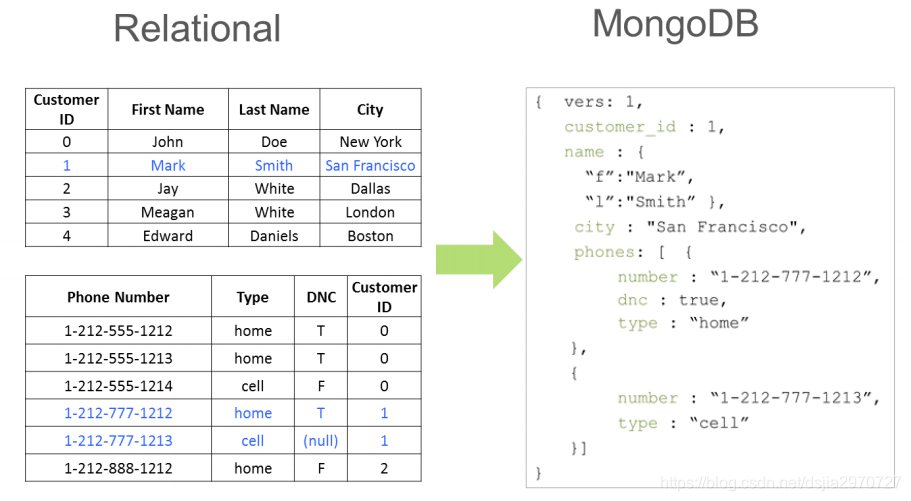
MongoDB数据模型
-
当个集合中的文档不必具有相同的字段,集合的不同文档的字段的数据类型可能有所不同
- 最佳实践:一般情况下,集合中的文档具有相似的结构
-
模式验证
- 创建集合或更改集合时指定JSON模式,模式验证发生在插入和更新期间,已经存在的文档不接受验证检查,回到被修改
-
上限集合
- 固定大小的集合,集合填满分配的空间后,通过覆盖集合中最旧的文档来存放新文档
MongoDB的安装
步骤
- 配置yum源
vi /etc/yum.repos.d/mongodb.repo
[MongoDB]
name=MongoDB Repository
baseurl=http://mirrors.aliyun.com/mongodb/yum/redhat/7Server/mongodb-org/4.0/x86_64/
gpgcheck=0
enabled=1
- 下载
yum install mongodb-org
- 启动
sudo systemctl start mongod.service
MongoDB client Shell
- 启动client shell命令
// 启动client
$ mongo
// 查看版本
$ mongod --version
- shell基本操作
// 显示所有数据库
show dbs
//查看当前的数据库名字
db
//切换数据库
use events
//显示所有集合
show collections
DataBase操作
-
DataBase
-
创建
- use命令后跟的数据库名,如果存在就进入此数据库,如果不存在就创建
- 使用命令use命令创建数据库后,并没有真正生成对应的数据文件,如果此时退出,此数据库将被删除,只有在此数据库中创建集合后,才会真正生成数据文件
-
删除当前数据库
- db.dropDatabase()
-
查看所有数据库
- show dbs
-
创建
Collection操作
-
创建
-
显示创建
- db.createCollection(“集合名称”)
-
隐式创建
- 创建集合并同时向集合中插入数据
- db.集合名称.insert({})
-
显示创建
-
查询
-
查看当前数据库中所有的集合
- show collections
- show tables
-
查看当前数据库中所有的集合
Document插入操作
- 单个插入
#将一条记录插入到collection表中,会自动添加_id字段,并分配_id字段的值
db.events.insert({"name":"demo record"}) #不推荐db.events.insertOne({"name":"demo record"})
- 批量插入
db.inventory.insertMany([
{ item: "journal", qty: 25, status: "A", size: { h: 14, w: 21, uom: "cm" }, tags: [ "blank", "red" ] },
{ item: "notebook", qty: 50, status: "A", size: { h: 8.5, w: 11, uom: "in" }, tags: [ "red", "blank" ] },
{ item: "paper", qty: 100, status: "D", size: { h: 8.5, w: 11, uom: "in" }, tags: [ "blank", "plain" ] },
{ item: "planner", qty: 75, status: "D", size: { h: 22.85, w: 30, uom: "cm" }, tags: [ "blank" ] },
{ item: "postcard", qty: 45, status: "A", size: { h: 10, w: 15.25, uom: "cm" }, tags: [ "blue" ] }
]);
Document查询操作(一)
- 查询所有文档
db.events.find()
db.events.find({})
-
条件查询
-
db.集合名称.find({条件})
- 属性值:db.inventory.find({ status: “D” })
- 过滤查询:db.inventory.find( { status: { $in: [ “A”, “D” ] } } )
-
db.集合名称.find({条件})
Document查询操作(二)
-
投影查询
- MongoDB支持返回某些特定的字段值
-
语法
- db.集合名称.find({条件名称},{字段:1})
- 其中1表示显示该字段,0表示不显示
# 查询文档中status=D的文档,只返回文档中status和size两个字段的值
db.inventory.find({ status: "D" },{status:1,size:1})
# 查询文档中status=D的文档,返回除了size字段的所有字段
db.inventory.find({ status: "D" },{size:0})
Document更新操作
- update
db.collection.update( <query>, <update>,
{upsert: <boolean>,multi: <boolean>,writeConcern: <document>})
# 这个操作将更改集合中与name: "apple"匹配的第一个文档,使用$set将其中的字段name设为"apple5s",使用$inc将字段price增加4000,其他字段保持不变。
db.goods.update({name: "apple"},{$set: {name: "appleSs"},$inc: {price:4000}})
# updateOne和updateMany操作
# 1.按条件更新数据,只更新查询排在第一位的数据
db.inventory.updateOne({ "status" : "D" },{ $set: { "item" : "journal"} },{ upsert: true });
# 2.更新满足条件的全部数据
db.inventory.updateMany({ "qty" : { $gt: 75 } },{ $set: { status: "A" } });
Document删除操作
-
remove操作和delete操作
- remove已经过时
#使用remove删除
db.col.remove({'title':'MongoDB 教程'})
# remove已经过时,官方推荐使用下面的方式:
# 删除集合下全部文档:
db.inventory.deleteMany({})
# 删除满足条件的全部文档:
db.inventory.deleteMany({ status : "A" })
# 删除一个文档:
db.inventory.deleteOne( { status: "D" } )
Document操作——Bulk-Write
- 需要批量操作时候,可以使用bulk_write,节省网络连接交互次数
db.characters.bulkWrite([
{ insertOne : { "document" : { "_id" : 4, "char" : "Dithras", "class" : "barbarian", "lvl" : 4 } } },
{ insertOne : { "document" : { "_id" : 5, "char" : "Taeln", "class" : "fighter", "lvl" : 3 } } },
{ updateOne : {
"filter" : { "char" : "Eldon" },
"update" : { $set : { "status" : "Critical Injury" } }
}
},
{ deleteOne : { "filter" : { "char" : "Brisbane"} } }
],{ ordered : false } );
索引
-
MongoDB的索引是Collection级别的
- MongoDB索引的数据结构是B+树
- MongoDB默认为所有集合都创建了一个_id字段的单字段索引,而且这个索引是唯一的,不能被删除
- 多键索引-索引存储在数组中的内容
- 文本索引-为文本搜索索引字符串的内容
- 哈希索引-索引字段的哈希值
db.collection.createIndex(keys, options)
# 语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为 -1即可
#实例
db.myColl.createIndex( { “score”: 1, “price”: 1, “category”: -1 })
副本集(复制)
-
MongoDB复制时将数据同步在多个服务器的过程
- 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,并可以保证数据的安全性
- 如果当前的主实例失败,会在副本集中选出一个新的主实例
-
MongoDB的复制至少需要两个节点
- 其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据
- 各个节点常见的搭配方式为:一主一从、一主多从
聚集分析
-
MongoDB主要提供了三种对数据进行分析计算的方式
- 管道模式聚集分析
- MapReduce聚集分析
- 简单函数和命令的聚集分析
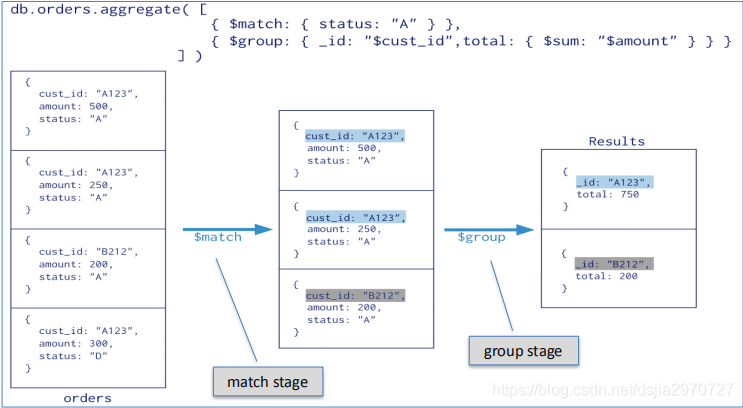
管道模式聚集分析
- 管道类似于UNIX上的管道命令。数据通过一个多步骤的管道,每个步骤都会对数据进行处理,最后返回需要的结果集
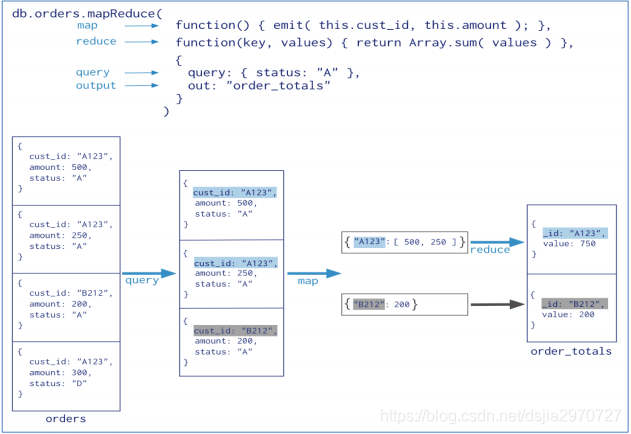
MapReduce聚集分析
-
MongoDB也提供了当前流行的MapReduce的并行编程模型,为海量数据的查询分析提供了一种更加高效的方法
- map阶段:处理每个文档并为每个文档发出一个或多个对象输入文件
- reduce阶段:聚合map阶段的输出
简单聚集函数
-
管道模式和MapReduce模式基本上可以解决数据分析中的所有问题,但有时在数据量不是很大的情况下,直接调用基于集合的函数会更简单
- distinct
- count
写关注(Write Concern)
- Write Concern,简称MongoDB写入安全机制
- 是一种客户端设置,用于控制写入安全的级别
- 描述了MongoDB写入到mongod单实例,副本集,以及分片集群时何时应答给客户端
- 写关注
参数:{ w: <value>, j: <boolean>, wtimeout: <number> }
//示例
db.blogs.insert({name:"kgc"},{writeConcern:{w:0}})
读关注(Read Concern)
- 读关注允许控制从副本集和副本集分片读取数据的一致性和隔离性的属性
- 读关注级别
- local/available:查询返回实例的数据,没有确保数据已写入大多数副本集成员(即可能会回滚)
- majority:只要是在发起读操作之前,已经大部分节点ACK的数据,都可以被读取
- linearizable:该查询能返回的数据是在读操作开始之前完成的所有成功的多数已确认的写操作
- snapshot:仅适用于多文档的事务操作
Java操作MongoDB
import com.mongodb.client.*;
import com.mongodb.*;
import java.util.Map;
public class mug1 {
public static void main(String[] args) {
try {
MongoClient mongoClient = new MongoClient();
MongoDatabase db = mongoClient.getDatabase("mug”);
MongoCollection coll = db.getCollection("foo");
MongoCursor c = coll.find().iterator();
while(c.hasNext()) {
Map doc = (Map) c.next();
System.out.println(doc);
}
} catch(Exception e) {// ... }
}
}
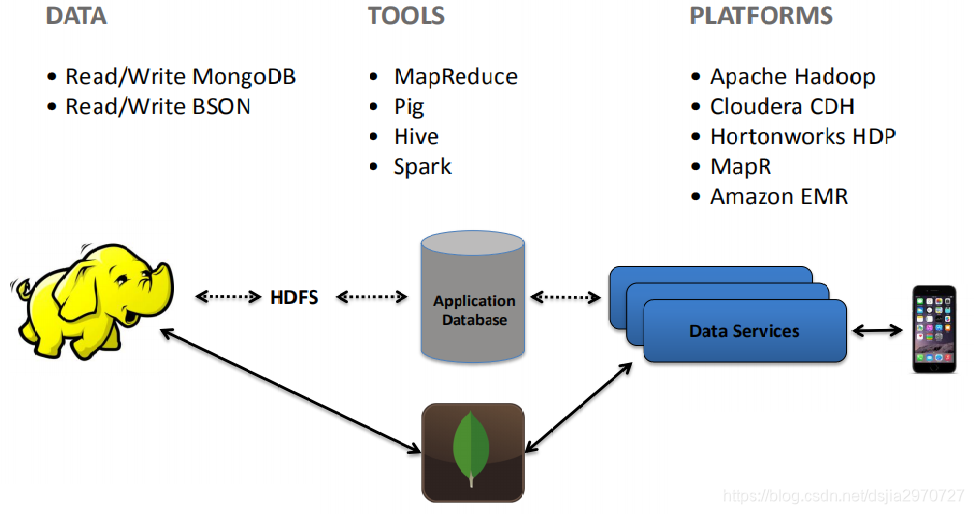
MongoDB与Hadoop平台整合
加载CSV文件到MongoDB
- 下载mongoimport
sudo yum install mongodb-org-tools-4.0.1
- 导入
MongoDB与Hive整合
- 使用MongoStorageHandler操作基于MongoDB的Hive表,需要提前拷贝相应Jar包
mongoimport --headerline --type=csv --file=./events.csv -d events_db -c events
CREATE TABLE individuals (
id INT,
name STRING,
age INT,
work STRUCT<title:STRING, hours:INT>
) STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler'
WITH SERDEPROPERTIES
('mongo.columns.mapping'='{"id":"_id","work.title":"job.position"}') TBLPROPERTIES
('mongo.uri'='mongodb://localhost:27017/test.persons');
MongoDB与Spark整合
- Spark操作MongoDB中的Collection
import com.mongodb.spark._
val spark = SparkSession.builder().master("local")
.config("spark.mongodb.input.uri", "mongodb://127.0.0.1/")
.config("spark.mongodb.input.collection", "restaurants")
.config("spark.mongodb.output.uri", "mongodb://127.0.0.1/")
.config("spark.mongodb.output.collection", "restaurants")
.getOrCreate()
//读
val df = MongoSpark.load(spark)
//写
MongoSpark.save(df.write.mode("overwrite"))
MongoDB认证
- 步骤
1、启动mongo client创建用户,设置密码
语法: db.createUser
2、关闭MongoDB服务
3、将/etc/mongod.conf中authorization设置为enable
security:
authorization: enabled
4、重启服务,并使用用户密码登录
mongo --port 27017 -u "kgc" -p "password" --authenticationDatabase "admin"
版权声明:本文为dsjia2970727原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。