Epoll性能特点
对
Select
、
Poll
、
Epoll
、
Kqueue
几种I/O多路复用做测试(限制100个活动连接,并且每一个连接会有1000次写入)
Select
Poll
Epoll
Kqueue
下图是 libevent(一个知名的异步事件处理软件库)对这几个 I/O 多路复用技术做的性能测试。
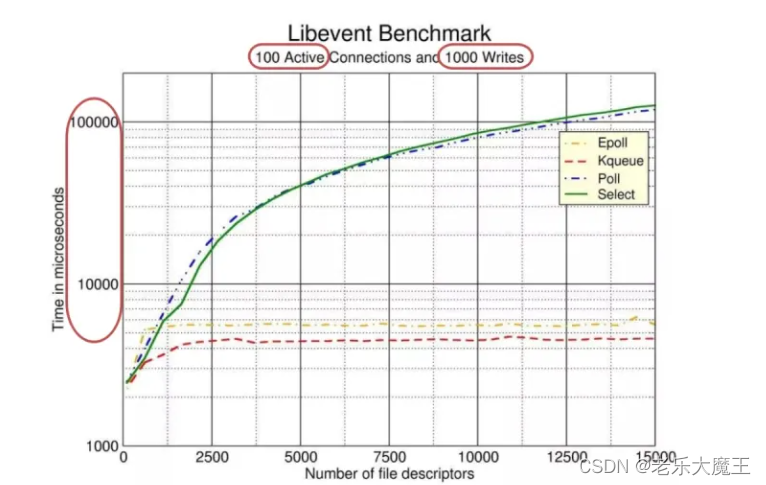
实验结果
在
fd
数量<1000时,这几种
I/O复用
的性能相互接近,当随着
fd
的数量越来越多,
EPOLL
和
Kqueue
的相应时间相接近,并且远小
Select
和
Poll
的响应时间
fd
I/O复用
fd
EPOLL
Kqueue
Select
Poll
实验分析
通过实验结果,可以看出
Epoll
在面对大量连接时性能表现优异。
Epoll
但是,不是任何时候,
Epoll
面对大量连接时都能够有如此表现,上述实验有个很重要的限制条件,
100 Active Connections
,也就是说,假设
Epoll
应对大量fd(15000个),此时其中只有100个活跃连接,
Epoll
才会明显优于其他I/O复用。
Epoll
Epoll
Epoll
如果当活跃连接也为15000个时,
Epoll
将会和Select以及
Poll
性能相近。
Epoll
Poll
在谈Epoll原理之前,先看几个问题(无需知道为什么),并且通过下面的原理解读来理解这些问题
Q: 为什么会出现
I/O多路复用
?
I/O多路复用
A: 为了减少进程上下文切换带来的开销。
Q: 是Linux已发行就有
Epoll
了吗?
Epoll
A:
I/O多路复用是一种技术,而
Select
、
Poll
、
Epoll
是实现了该技术的框架。
Select
Poll
Epoll
框架的api发布的时间线:
- 1983,socket 发布在 Unix(4.2 BSD)
- 1983,select 发布在 Unix(4.2 BSD)
- 1994,Linux的1.0,已经支持socket和select
- 1997,poll 发布在 Linux 2.1.23
- 2002,epoll发布在 Linux 2.5.44
这些框架的出现是以不断改进的方式向前推进的:
Select
->
Poll
->
Epoll
,
Poll
是在
Select
的基础上改进,
Epoll
在
Poll
的基础上改进,可以这么说,
Epoll
是在
I/O多路复用框架
不断发展的结果。
Select
Poll
Epoll
Poll
Select
Epoll
Poll
Epoll
I/O多路复用框架
Q:
Epoll
解决了什么问题?
Epoll
A:
Epoll
优化了
内核
和
监视进程
(
监视fd的进程
)的
交互
。
Epoll
监视fd的进程
1
Epoll
原理
Epoll
1.1 阻塞
Epoll
为什么是阻塞的,这是因为内核收发网络数据的底层机制导致的,并且,阻塞才是高效的方式。
Epoll
接收网络数据的过程:
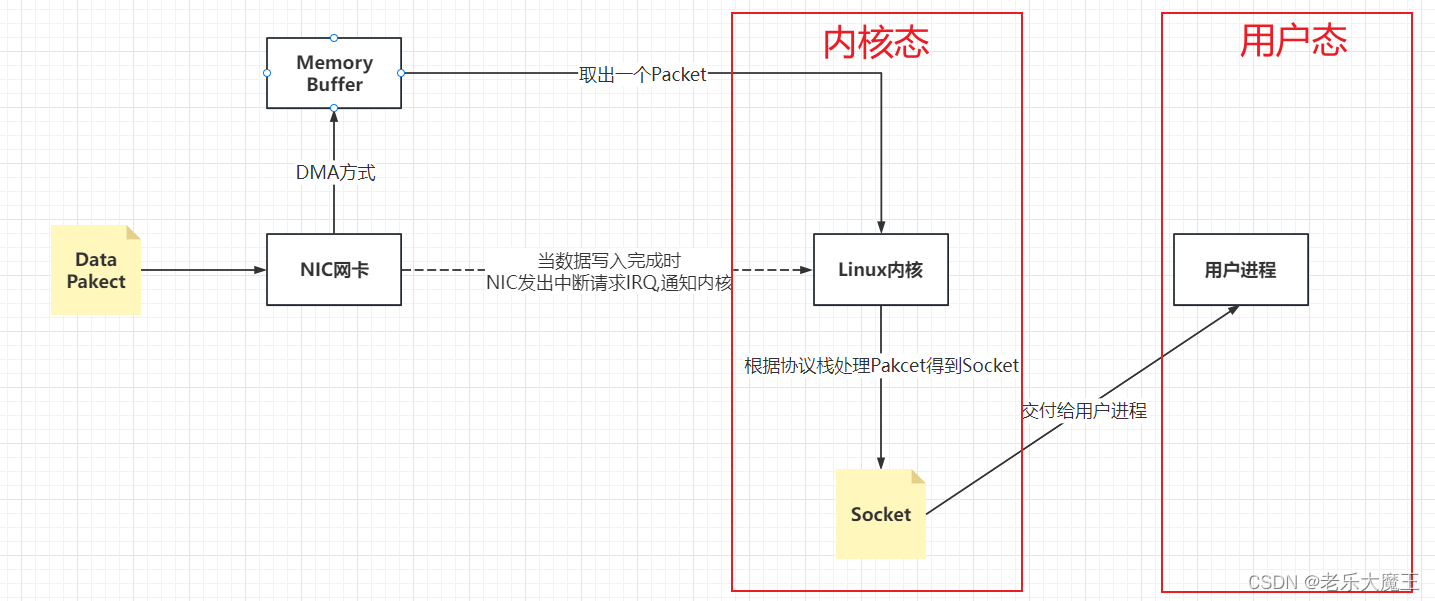
网卡接收数据依赖发送方和传输路径,延迟是毫秒(ms)级别的,相对于用户进程处理数据的纳秒级来说相对很慢,所以用户态的用户进程在等待数据的过程中CPU空闲,此时通过阻塞该进程来让出CPU资源(阻塞不占用CPU资源),提高CPU的利用率。
1.2 阻塞恢复
问题来了,当用户进程阻塞等待数据,数据接受完毕后怎么办
Sokcet结构体包含两个数据:
进程ID
(调用send,read,connect的进程)and
端口号
进程ID
端口号
当数据从网卡到内核时,内核通过
端口号
来确定对应的Sokcet
端口号
当数据从内核到用户进程时,内核通过
进程ID
来确定目标进程,然后修改目标进程的状态,从
阻塞状态
变为
可执行状态
,最后通过OS的进程调度,该进程得以从
可执行状态
变为
运行状态
,最终用户的数据得以处理完毕
进程ID
阻塞状态
可执行状态
可执行状态
运行状态
1.3 过程优化
进程
接收数据的过程存在两处可能造成频繁上下文切换产生大量不必要开销
进程
1.如果频繁接收到
Packet
,那么网卡会频繁发出IRQ,此时,CPU不一定在内核态,有可能在用户态,因此可能会造成大量的内核态与用户态之间频繁的切换
Packet
2.
one socket - one proccess
,当一个
Sokcet
处理完,就一定伴随着进程间调度,存在进程间的上下文切换
one socket - one proccess
Sokcet
解决办法:缓冲区的思想
解决问题1:通过网卡驱动中的一种机制
NAPI
机制,这里有兴趣的小伙伴可以自己去了解了解,这里不展开赘述,我直接总结一下:就是
批量收发数据
减少内核态与用户态的切换次数
NAPI
批量收发数据
解决问题2:你肯定已经想到了,解决进程间调度的办法也是
批量收发数据
呗,问题就在于怎样去操作。网卡可以通过
NAPI
机制,内核可以通过大名鼎鼎的
I/O多路复用技术
来优化。就是
n Socket - one proccess
,说白了就是
多
个
Socket
复用
到
一个进程
中。
批量收发数据
NAPI
I/O多路复用技术
n Socket - one proccess
多
Socket
复用
一个进程
1.4 EPOLL存储fd数据结构
1.由两个结构体组成,
总集
和
就绪队列
总集
就绪队列
2.数据结构:1.
红黑树
存储总集
fd
,2
链表
存储就绪
fd
红黑树
fd
链表
fd
1.5 Epoll与Select、Poll之间的比较
1.提高了总集大小:
fd
数量上限是系统最大可以打开的文件数目(主机内存限制)
fd
2.采用通知机制:每个
fd
上有
callback
函数,只有活跃的
Socket
才会调用
callback
函数
fd
callback
Socket
callback
3. 提高了活跃Socket的查找效率:由于通过
epoll_wait
直接获取到的就是活跃Socket,所以用户进程查找时间复杂度为
O(活跃连接数量*logn)
,而
Poll和Select
需要线性查找时间复杂度
O(活跃连接数量*n)
epoll_wait
O(活跃连接数量*logn)
Poll和Select
O(活跃连接数量*n)
若当活跃连接数量远小于总量n时,Epoll时间复杂度可看作
O(logn)
,
Poll和Select
时间复杂度可看作
O(n)
,此时Epoll性能优!
O(logn)
Poll和Select
O(n)
若当活跃连接与n相近时,则
Epoll
时间复杂度为
O(nlogn)
,
Poll和Select
时间复杂度可看作
O(n^2)
,性能相差不大,甚至在某些
业务场景
中
Epoll
性能还不如
Poll和Select
,所以
Epoll
并不是所谓的万金油,要具体问题具体分析
Epoll
O(nlogn)
Poll和Select
O(n^2)
Epoll
Poll和Select
Epoll
3.数据处理问题:内核和用户通过
mmap
共享内存,避免内存拷贝(据说不同的linux版本,
Epoll
不用
mmap
,这个以后通过实践考证)
mmap
Epoll
mmap
版权声明:本文为qq_27277041原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。