在上一篇文章中,我们详细介绍了链式存储结构,并结合LinkedList源码进行了分析,相关文章大家可以点击这里回看我的博客:线性表数据结构解读(二)链式存储结构LinkedList
栈的定义
栈是一种特殊的线性表,其全部操作都被限制在表的固定一端进行,而且构成栈的元素必须是同一数据类型。
栈的特点
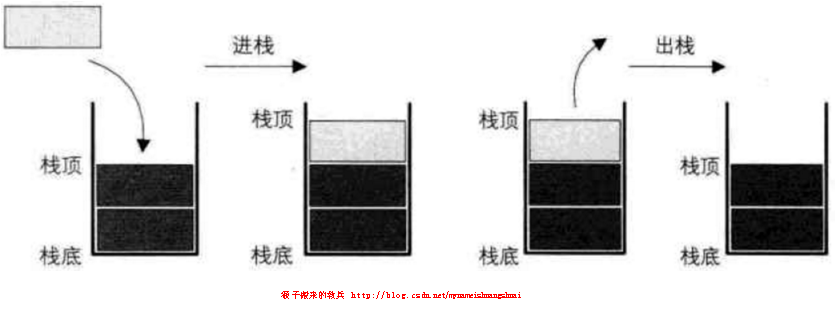
允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom),不含任何数据元素的栈称为空栈。栈又称为后进先出的线性表
栈的操作
栈的常用操作包括建立栈、元素入栈、元素出栈、取栈顶元素等。
空栈
当建立一个栈时,不包括任何元素,此时称其为空栈。栈为空时top和bottom共同指向栈底。向栈中插入元素成为入栈,使top指向的元素退出栈,称为出栈,出栈和入栈操作全部是针对栈顶元素进行操作的。
栈的存储结构
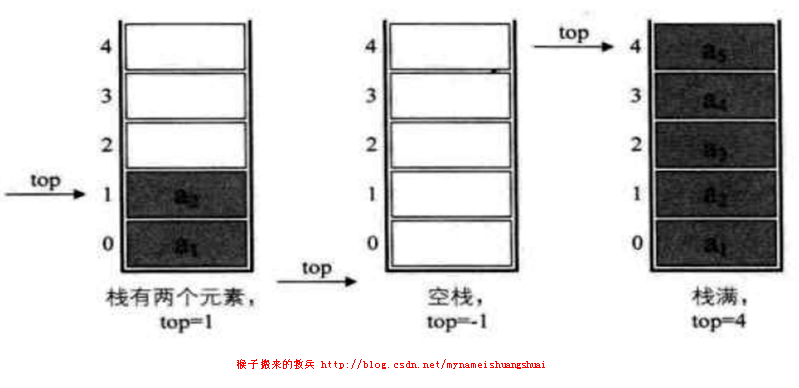
● 顺序栈
将栈在顺序存储结构下所得到的结构成为顺序栈。顺序栈类类似于数组,因此可以使用数组实现顺序栈的相关运算,通常栈底是下标为0的一端。
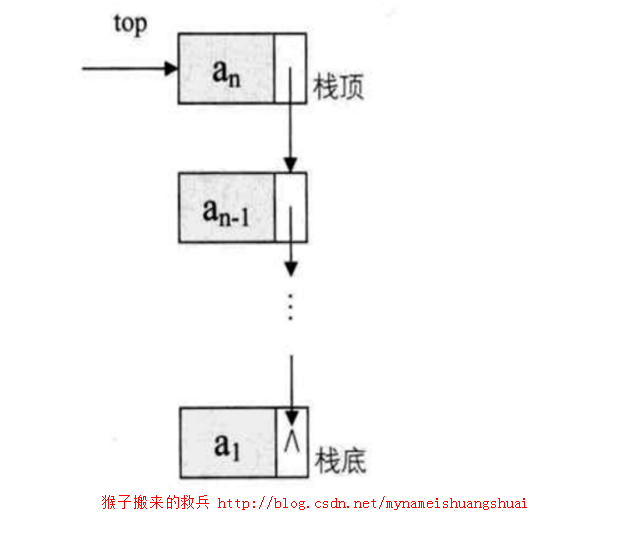
● 链式栈
将栈在链式存储结构下所得到的结构,称为链式栈。链式栈类似于指针,在java中可以通过类的对象引用实现指针运算。
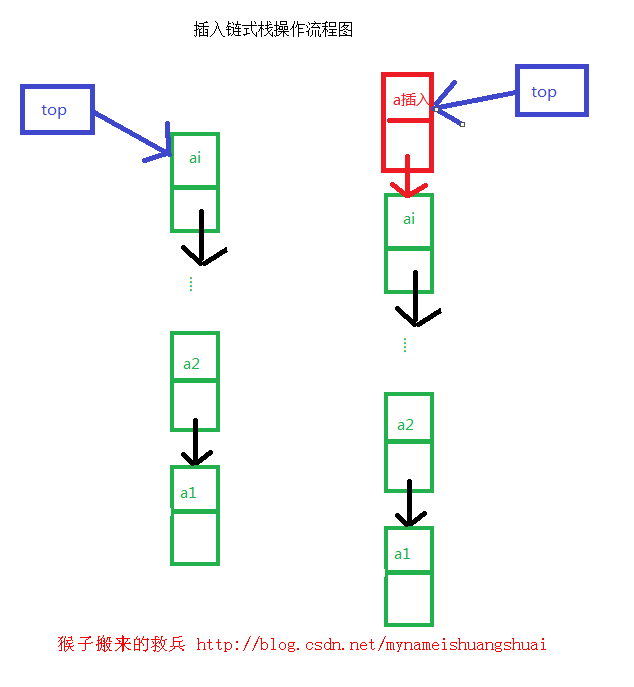
链式栈的入栈操作
把top的引用指向新的结点,新结点的下一个引用指向原来的top结点
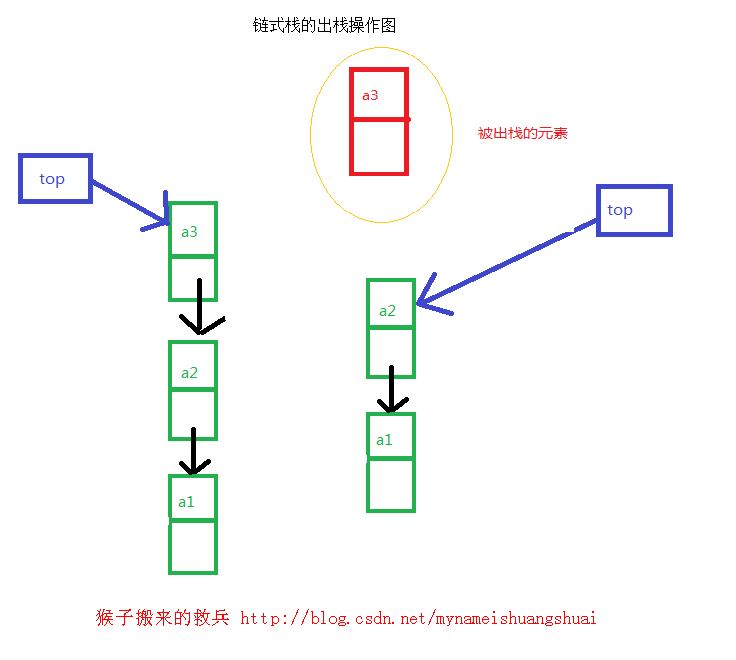
链式栈的出栈操作
把top的引用指向原栈顶元素的下一个元素,并释放原栈顶元素的引用
栈结构在Android中的应用
在Android中,我们常见具有代表性的栈结构为Stack,下面我们进行分析,看看它内部是如何实现入栈和出栈操作的。
public class Stack extends Vector {
private static final long serialVersionUID = 1224463164541339165L;
/** * 无参构造方法 */
public Stack() {
}
/** * 判断是否为空 * Returns whether the stack is empty or not. * @return {@code true} if the stack is empty, {@code false} otherwise. */
public boolean empty() {
return isEmpty();
}
/** * 返回栈顶的元素 * Returns the element at the top of the stack without removing it. * @return the element at the top of the stack. * @throws EmptyStackException if the stack is empty. * @see #pop */
@SuppressWarnings(“unchecked”)
public synchronized E peek() {
try {
return (E) elementData[elementCount – 1];
} catch (IndexOutOfBoundsException e) {
throw new EmptyStackException();
}
}
/** * 弹出栈 * Returns the element at the top of the stack and removes it. * @return the element at the top of the stack. * @throws EmptyStackException if the stack is empty. * @see #peek * @see #push */
@SuppressWarnings(“unchecked”)
public synchronized E pop() {
if (elementCount == 0) {// 如果为0则为空栈
throw new EmptyStackException();// 抛出空栈异常
}
// index是被弹出栈元素的下标(先减再赋值)
final int index = –elementCount;
final E obj = (E) elementData[index];
elementData[index] = null;// 把弹出栈的元素值设为空
modCount++;
return obj;
}
/** * 推入栈操作 * Pushes the specified object onto the top of the stack. * @param object The object to be added on top of the stack. * @return the object argument. * @see #peek * @see #pop */
public E push(E object) {
// 添加一个元素
addElement(object);
return object;
}
/** * 查询操作,该方法一定要是线程安全的,不能一边遍历一边增删 * Returns the index of the first occurrence of the object, starting from * the top of the stack. * @return the index of the first occurrence of the object, assuming that * the topmost object on the stack has a distance of one. * @param o the object to be searched. */
public synchronized int search(Object o) {
final Object[] dumpArray = elementData;
// 非空栈元素的数量
final int size = elementCount;
if (o != null) {// 如果传进来的元素不等于空
for (int i = size – 1; i >= 0; i–) {// 从栈顶遍历下去
if (o.equals(dumpArray[i])) {//如果传进来的元素等于dumpArray[i]
return size – i;
}
}
} else {
for (int i = size – 1; i >= 0; i–) {
if (dumpArray[i] == null) {// 如果dumpArray[i]等于null
return size – i;
}
}
}
return -1;
}
}
我们注意到源码中push方法中用到了父类的addElement(),这里我们去Stack的父类Vector中一探究竟。
addElement方法
/** * 添加元素方法 * Adds the specified object at the end of this vector. *@param object the object to add to the vector. */
public synchronized void addElement(E object) {
// 容量长度和非空元素数量相同
if (elementCount == elementData.length) {
growByOne();
}
elementData[elementCount++] = object;
modCount++;
}
growByOne方法
/** * JIT optimization */
private void growByOne() {
int adding = 0;
if (capacityIncrement <= 0) {
// 判断是否是空栈,如果为空增加1
if ((adding = elementData.length) == 0) {
adding = 1;
}
} else {// 否则扩容capacityIncrement
adding = capacityIncrement;
}
// 新创建一个数组,把数组长度扩容,然后数组复制
E[] newData = newElementArray(elementData.length + adding);
System.arraycopy(elementData, 0, newData, 0, elementCount);
elementData = newData;
}
参考来源:动脑学院Danny老师数据结构课程