文章目录
本文是针对VoteNet:Deep Hough Voting for 3D Object Detection in Point Clouds论文的源码的理解。VoteNet的解读可以参考我的
另外一篇博客
。具体的源码,
可在github上下载
。
总的来说,代码写的非常优雅,我觉得光从代码的结构来看,也有很多可以借鉴的地方。所以本文先看一下代码的结构,然后再跟进去详解。
代码结构
train.py
# train.py
# 具体的内容可以看源码,这里只是记录一些代码要干的事情,很有借鉴意义的代码。
通过parser定义trian过程需要的参数
定义Log_dir和Dump_dir,并打开Log_dir,写入本次训练的parser中有关config的参数
定义一个写入log的函数,只是在trian.py中调用
加载dataset的config,加载dataset,在定义dataset时,使用train和eval两种模式,甚至还可以加入test模式,从而可以共用dataset的接口
定义worker_init_fn,加载dataloader
加载model,并将其放到nn.DataParallel中
加载criterion,由于loss计算越来越复杂,定义一个函数或者类
定义optimizer
def train_one_epoch():
stat_dict = {} # 定义一个储存中间过程变量的dict
adjust_learning_rate(optimizer, EPOCH_CNT) # 调整lr
bnm_scheduler.step() # decay BN momentum
for batch_idx, batch_data_label in enumerate(TRAIN_DATALOADER):
前向计算
计算loss
反向传播
统计中间结果
展示中间结果
def eval_one_epoch():
相比于train_one_epoch,增加计算最终统计量的部分例如AP,其他相同
def trian():
for epoch in range(start_epoch, MAX_EPOCH):
log记录epoch的属性
np.random.seed()
train_one_epoch()
if EPOCH_CNT == 0 or EPOCH_CNT % 10 == 9: # Eval every 10 epochs
loss = evaluate_one_epoch()
# Save checkpoint
save_dict = {'epoch': epoch+1, # after training one epoch, the start_epoch should be epoch+1
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}
try: # with nn.DataParallel() the net is added as a submodule of DataParallel
save_dict['model_state_dict'] = net.module.state_dict()
except:
save_dict['model_state_dict'] = net.state_dict()
torch.save(save_dict, os.path.join(LOG_DIR, 'checkpoint.tar'))
if __name__=='__main__':
train(start_epoch)
值得学习的点:
- log文件的写入写成一个函数,只在train.py中写入,写入的地方有了限制,好查找
- 使用stat_dict作为储存中间变量的字典,贯穿整个过程,使得在trian.py中可以找到需要的所有中间过程,而且留出了中间过程与train.py之间交互的接口,不需要修改太多就可以加入新功能
训练数据处理
Sunrgbd的data是以matlab形式储存的,作者提供了从matlab中读出数据和label的函数:
- extract_split.m:将数据集分割成训练集和验证集
- extract_rgbd_data_v2.m:将v2版的label以txt形式储存,并且复制每个数据的depth,img和calib文件
- extract_rgbd_data_v1.m:讲v1版的label以txt形式储存
在储存好上述数据之后,使用python sunrgbd_data.py –gen_v1_data进一步处理数据,将depth数据降采样,并构造votes的数据。
sunrgbd_data.py
def extract_sunrgbd_data(idx_filename, split, output_folder, num_point=20000,
type_whitelist=DEFAULT_TYPE_WHITELIST,
save_votes=False, use_v1=False, skip_empty_scene=True):
""" Extract scene point clouds and
bounding boxes (centroids, box sizes, heading angles, semantic classes).
Dumped point clouds and boxes are in upright depth coord.
Args:
idx_filename: a TXT file where each line is an int number (index)
split: training or testing
save_votes: whether to compute and save Ground truth votes.
use_v1: use the SUN RGB-D V1 data
skip_empty_scene: if True, skip scenes that contain no object (no objet in whitelist)
Dumps:
<id>_pc.npz of (N,6) where N is for number of subsampled points and 6 is
for XYZ and RGB (in 0~1) in upright depth coord
<id>_bbox.npy of (K,8) where K is the number of objects, 8 is for
centroids (cx,cy,cz), dimension (l,w,h), heanding_angle and semantic_class
<id>_votes.npz of (N,10) with 0/1 indicating whether the point belongs to an object,
then three sets of GT votes for up to three objects. If the point is only in one
object's OBB, then the three GT votes are the same.
"""
dataset = sunrgbd_object('./sunrgbd_trainval', split, use_v1=use_v1)
data_idx_list = [int(line.rstrip()) for line in open(idx_filename)]
if not os.path.exists(output_folder):
os.mkdir(output_folder)
for data_idx in data_idx_list:
print('------------- ', data_idx)
objects = dataset.get_label_objects(data_idx)
# Skip scenes with 0 object
if skip_empty_scene and (len(objects)==0 or \
len([obj for obj in objects if obj.classname in type_whitelist])==0):
continue
object_list = []
for obj in objects:
if obj.classname not in type_whitelist: continue
obb = np.zeros((8))
obb[0:3] = obj.centroid
# Note that compared with that in data_viz, we do not time 2 to l,w.h
# neither do we flip the heading angle
obb[3:6] = np.array([obj.l,obj.w,obj.h])
obb[6] = obj.heading_angle
obb[7] = sunrgbd_utils.type2class[obj.classname]
object_list.append(obb)
if len(object_list)==0:
obbs = np.zeros((0,8))
else:
obbs = np.vstack(object_list) # (K,8)
pc_upright_depth = dataset.get_depth(data_idx)
pc_upright_depth_subsampled = pc_util.random_sampling(pc_upright_depth, num_point)
# 将降采样到50000个点写入_pc.npz,并将label写入bbox.npy
np.savez_compressed(os.path.join(output_folder,'%06d_pc.npz'%(data_idx)),
pc=pc_upright_depth_subsampled)
np.save(os.path.join(output_folder, '%06d_bbox.npy'%(data_idx)), obbs)
if save_votes:
N = pc_upright_depth_subsampled.shape[0]
point_votes = np.zeros((N,10)) # 3 votes and 1 vote mask
point_vote_idx = np.zeros((N)).astype(np.int32) # in the range of [0,2]
indices = np.arange(N)
# 对每个obj计算相对应的votes
for obj in objects:
if obj.classname not in type_whitelist: continue
try:
# Find all points in this object's OBB
box3d_pts_3d = sunrgbd_utils.my_compute_box_3d(obj.centroid,
np.array([obj.l,obj.w,obj.h]), obj.heading_angle)
pc_in_box3d,inds = sunrgbd_utils.extract_pc_in_box3d(\
pc_upright_depth_subsampled, box3d_pts_3d)
# Assign first dimension to indicate it is in an object box
point_votes[inds,0] = 1
# Add the votes (all 0 if the point is not in any object's OBB)
votes = np.expand_dims(obj.centroid,0) - pc_in_box3d[:,0:3]
sparse_inds = indices[inds] # turn dense True,False inds to sparse number-wise inds
for i in range(len(sparse_inds)):
j = sparse_inds[i]
point_votes[j, int(point_vote_idx[j]*3+1):int((point_vote_idx[j]+1)*3+1)] = votes[i,:]
# Populate votes with the fisrt vote
if point_vote_idx[j] == 0:
point_votes[j,4:7] = votes[i,:]
point_votes[j,7:10] = votes[i,:]
point_vote_idx[inds] = np.minimum(2, point_vote_idx[inds]+1)
except:
print('ERROR ----', data_idx, obj.classname)
np.savez_compressed(os.path.join(output_folder, '%06d_votes.npz'%(data_idx)),
point_votes = point_votes)
Sunrgbd_detection_dataset.py
# Sunrgbd_detection_dataset.py
class SunrgbdDetectionVotesDataset(Dataset):
def __init__(self, split_set='train', num_points=20000,
use_color=False, use_height=False, use_v1=False,
augment=False, scan_idx_list=None)
def __len__(self):
return len(self.scan_names)
def __getitem__(self, idx):
#先从文件中加载输入
point_cloud = np.load(os.path.join(self.data_path, scan_name)+'_pc.npz')['pc'] # Nx6,(x, y, z, r, g, b)
bboxes = np.load(os.path.join(self.data_path, scan_name)+'_bbox.npy') # K,8, (x, y, z, w, h, l, angle-z, class)
point_votes = np.load(os.path.join(self.data_path, scan_name)+'_votes.npz')['point_votes'] # Nx10, (1, vote-x1, vote-y1, vote-z1, vote-x1, vote-y1, vote-z1, vote-x1, vote-y1, vote-z1)
# ------------------------------- DATA AUGMENTATION ------------------------------
进行Data Augmentation,包括旋转和尺度变换
# ------------------------------- LABELS ------------------------------
box3d_centers = np.zeros((MAX_NUM_OBJ, 3))
box3d_sizes = np.zeros((MAX_NUM_OBJ, 3))
angle_classes = np.zeros((MAX_NUM_OBJ,))
angle_residuals = np.zeros((MAX_NUM_OBJ,))
size_classes = np.zeros((MAX_NUM_OBJ,))
size_residuals = np.zeros((MAX_NUM_OBJ, 3))
label_mask = np.zeros((MAX_NUM_OBJ))
label_mask[0:bboxes.shape[0]] = 1
max_bboxes = np.zeros((MAX_NUM_OBJ, 8))
max_bboxes[0:bboxes.shape[0],:] = bboxes
for i in range(bboxes.shape[0]):
bbox = bboxes[i]
semantic_class = bbox[7]
box3d_center = bbox[0:3]
angle_class, angle_residual = DC.angle2class(bbox[6])
# NOTE: The mean size stored in size2class is of full length of box edges,
# while in sunrgbd_data.py data dumping we dumped *half* length l,w,h.. so have to time it by 2 here
box3d_size = bbox[3:6]*2
size_class, size_residual = DC.size2class(box3d_size, DC.class2type[semantic_class])
box3d_centers[i,:] = box3d_center
angle_classes[i] = angle_class
angle_residuals[i] = angle_residual
size_classes[i] = size_class
size_residuals[i] = size_residual
box3d_sizes[i,:] = box3d_size
target_bboxes_mask = label_mask
target_bboxes = np.zeros((MAX_NUM_OBJ, 6))
for i in range(bboxes.shape[0]):
bbox = bboxes[i]
corners_3d = sunrgbd_utils.my_compute_box_3d(bbox[0:3], bbox[3:6], bbox[6])
# compute axis aligned box
xmin = np.min(corners_3d[:,0])
ymin = np.min(corners_3d[:,1])
zmin = np.min(corners_3d[:,2])
xmax = np.max(corners_3d[:,0])
ymax = np.max(corners_3d[:,1])
zmax = np.max(corners_3d[:,2])
target_bbox = np.array([(xmin+xmax)/2, (ymin+ymax)/2, (zmin+zmax)/2, xmax-xmin, ymax-ymin, zmax-zmin])
target_bboxes[i,:] = target_bbox
point_cloud, choices = pc_util.random_sampling(point_cloud, self.num_points, return_choices=True)
point_votes_mask = point_votes[choices,0]
point_votes = point_votes[choices,1:]
ret_dict = {}
ret_dict['point_clouds'] = point_cloud.astype(np.float32)
ret_dict['center_label'] = target_bboxes.astype(np.float32)[:,0:3]
ret_dict['heading_class_label'] = angle_classes.astype(np.int64)
ret_dict['heading_residual_label'] = angle_residuals.astype(np.float32)
ret_dict['size_class_label'] = size_classes.astype(np.int64)
ret_dict['size_residual_label'] = size_residuals.astype(np.float32)
target_bboxes_semcls = np.zeros((MAX_NUM_OBJ))
target_bboxes_semcls[0:bboxes.shape[0]] = bboxes[:,-1] # from 0 to 9
ret_dict['sem_cls_label'] = target_bboxes_semcls.astype(np.int64)
ret_dict['box_label_mask'] = target_bboxes_mask.astype(np.float32)
ret_dict['vote_label'] = point_votes.astype(np.float32)
ret_dict['vote_label_mask'] = point_votes_mask.astype(np.int64)
ret_dict['scan_idx'] = np.array(idx).astype(np.int64)
ret_dict['max_gt_bboxes'] = max_bboxes
return ret_dict
令我疑惑的是,target_bboxes的存在。在最终的ret_dict中,target_bboxes只是将[:, 0:3]放入,也就是只放入了(x, y, z),与box3d_centers是一样的。不一样之处在于,由于经过了旋转,target_bboxes的size是在全局坐标系下,不考虑旋转的size,但这个并没有使用。不知道为什么要计算target_bboxes。
另外一个是需要注意的是point_votes的产生是在sunrgbd_data.py中产生的,这相当于一个前处理的过程,其描述如下:
<id>_votes.npz of (N,10) with 0/1 indicating whether the point belongs to an object,
then three sets of GT votes for up to three objects. If the point is only in one
object's OBB, then the three GT votes are the same.
也就是vote[0]表示该点在不在一个物体的内部,vote[1:4]、vote[4:7]、vote[7:10]表示该激光点与所属物体的中心的位置偏差。
接下来,我们解释一下ret_dict包含的变量所代表的含义,基本这些含义是从构建label的地方就能看懂:
- pointclouds:点云,20000*4,最后一列代表减去地面高度的高度
- center_label:box中心的位置
- heading_class_label:box朝向的class的label
- heading_residual_label:box朝向residual的label
- size_class_label:box的whl的class的label
- size_residual_label:box的whl的residual的label
- sem_cls_label:box的semantic class的label
- box_label_mask:是指示在box_label中,哪些box是真正的,哪些是用零补的
- vote_label_mask:指示某个点参不参与vote的计算
- scan_idx
- max_gt_bboxes:指示box_label中真实的box的数量,也就是box_label_mask相加
train过程详解
前向计算过程
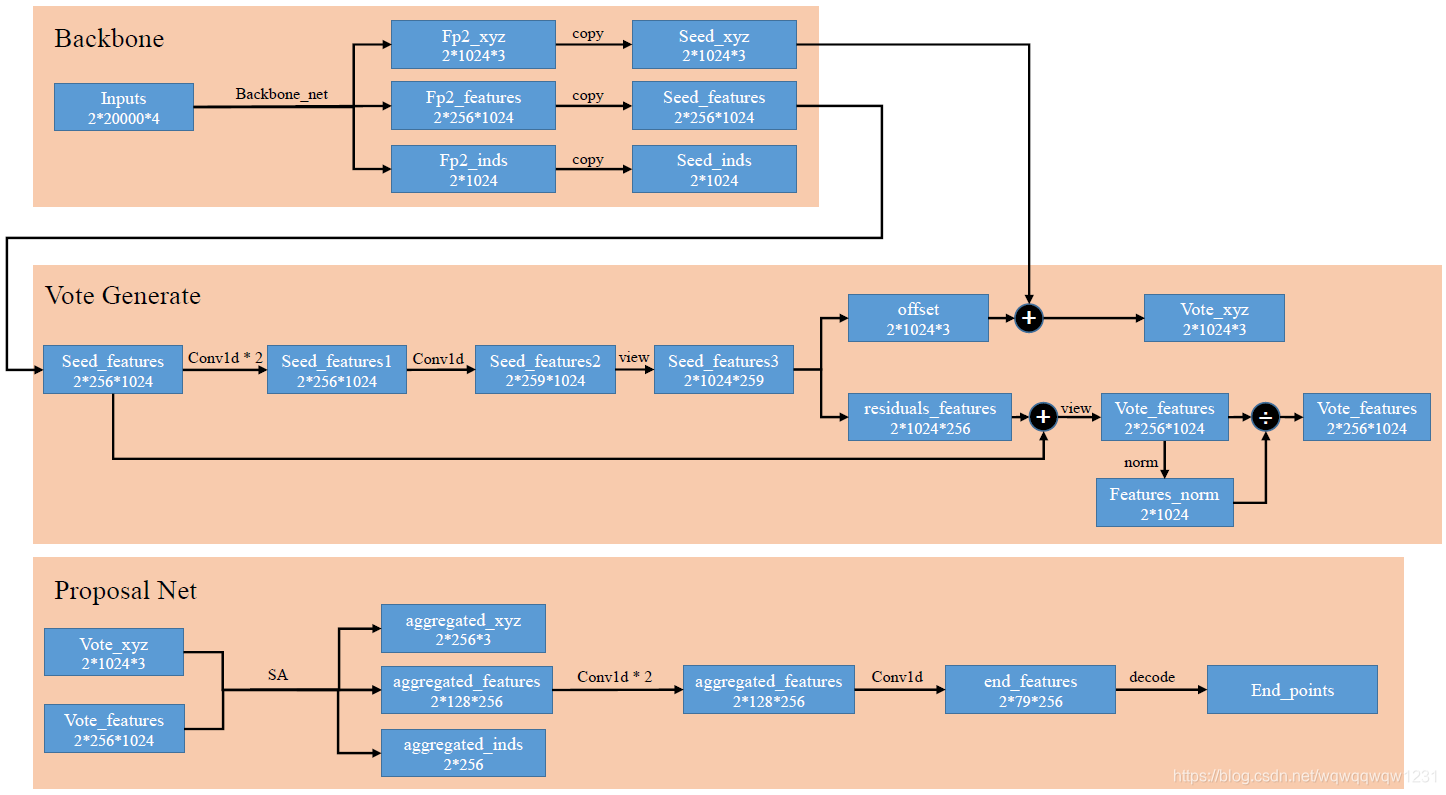
具体的前向计算过程如上图:
- Backbone:BackBone由Pointnet++构成,包括4层SA层,2层FP层,最终输出的Seed_inds是指示Seed_xyz在Inputs中的位置。
-
Vote Generate:对Seed_features使用Conv1d得到vote的offsets和residuals_features,然后与seed的xyz和feature相加,得到vote_xzy和vote_features,最后对vote_features进行归一化。(
这个归一化在文中并没有提到啊?
) - Porposal Net:对Vote_xyz和Vote_feature再过一层SA,然后对feature使用Conv1d得到最终结果,通过decode构建计算loss的变量。
Decode
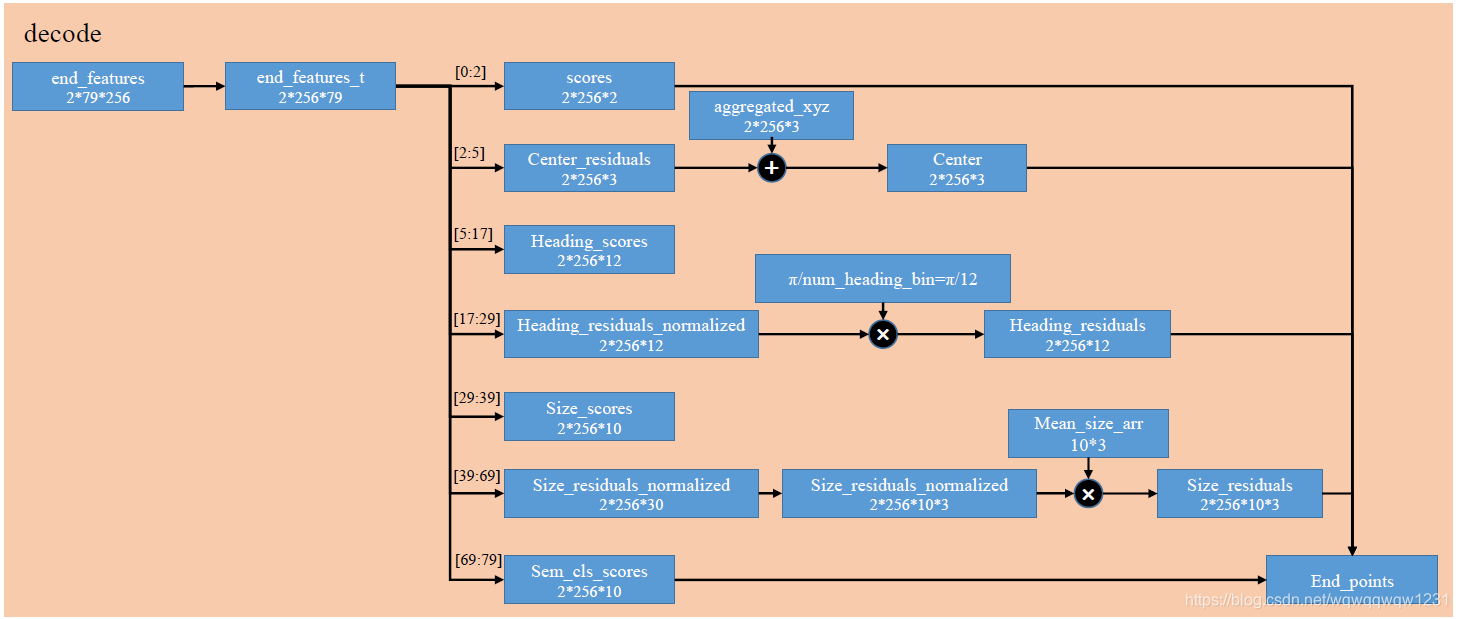
Decode过程不产生梯度,没有卷积层,只是把最终的结果解析成计算loss的变量,具体操作,上图已经很清楚了,不再赘述,这块内容对应文章中的:
The max-pooled features are further processed by MLP2 with output sizes of 128, 128, 5+2NH+4NS+NC where the output consists of 2 objectness scores, 3 center regression values, 2NH numbers for heading regression (NH heading bins) and 4NS numbers for box size regression (NS box anchors) and NC numbers for semantic classification
计算Loss
Loss的构成分为好几部分,比较复杂。
Vote Loss
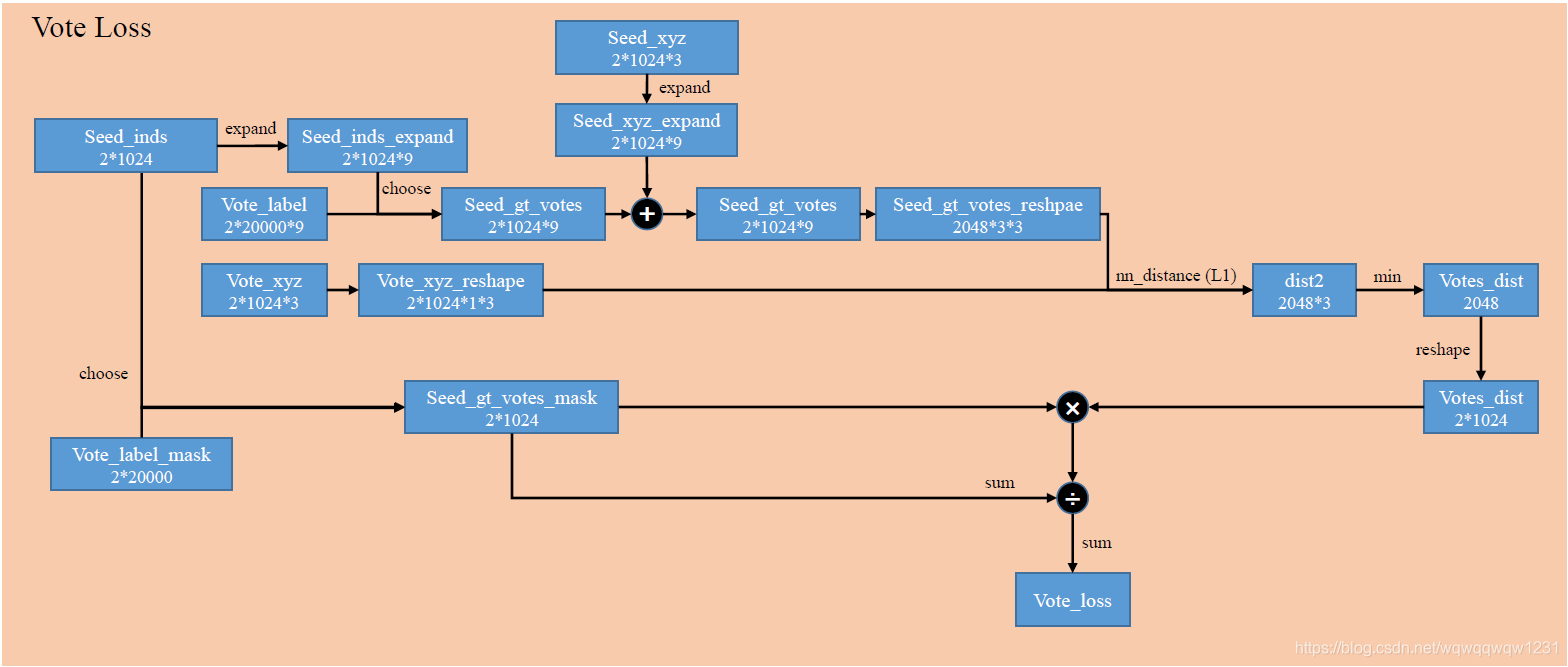
计算Vote与真值的差别,步骤如下:
- 根据Seed_inds从初始数据中的Vote_label中找到降采样后的Vote_label,然后加在Seed_xyz上得到Vote_xyz的真值,也就是Seed_gt_votes_reshape
- 通过nn_distance计算预测值与真值的差距。nn_distance的作用是计算两个储存位置信息的tensor之间的距离差,tensor A的维度为(batch,参与计算距离的点的数目,3)。所以该nn_distance是计算Vote_xyz_reshape中的一个点与Seed_gt_votes_reshape中的3个点计算距离,输出距离最小值,这样操作重复2048个点。L1表示是使用L1距离。所以dist2则是Seed_gt_votes_reshape中的3个点距离Vote_xyz_reshape中对应点的距离,然后去最小值得到Votes_dist。
- 通过Seed_inds选取mask,当seed点在物体内时,Vote_label_mask为1,其余为0,然后相乘则是使用mask使得不是物体内的点不参与loss的计算,相除是为了归一化。
Objectness Loss
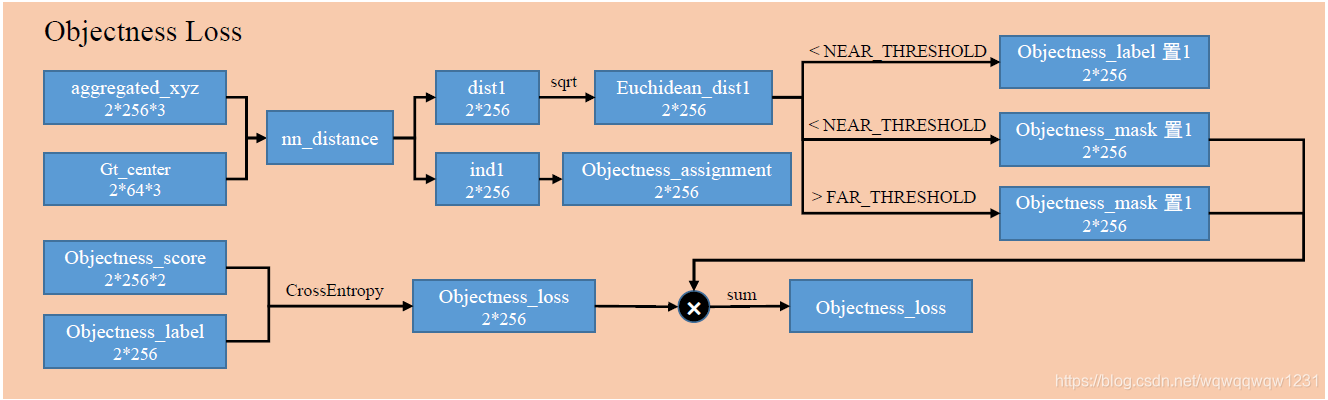
本loss主要是与判断一个aggregated_vote是否是物体有关,并产生了计算box loss的mask。步骤如下:
- 计算aggregated_xyz与物体中心gt_center的距离,当距离小于NEAR_THRESHOLD时,objectness_label置1,然后当距离小于NEAR_THRESHOLD大于FAR_THRESHOLD,mask置1,mask为0的部分(既不远也不近)的部分不参与Objectness_loss计算
- 选取aggregated_xyz距离最近的gt_center,构建objectness_assignment
Box Loss
Center Loss
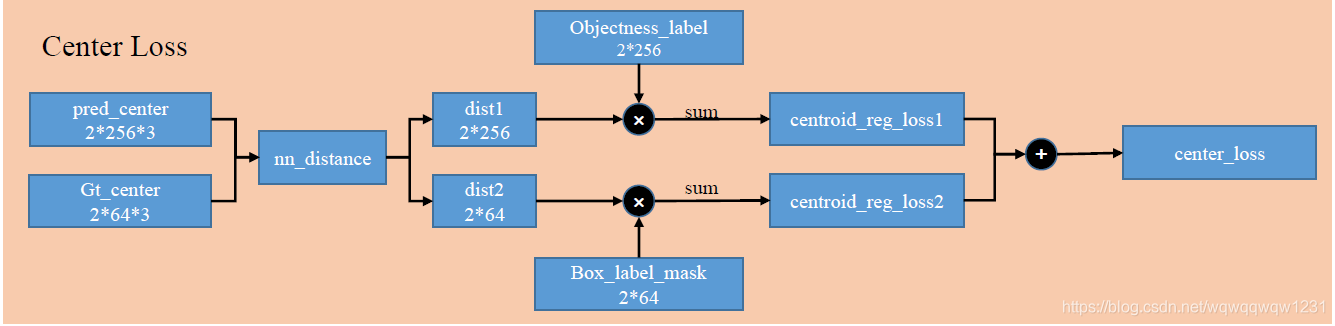
计算预测的box的center的位置偏差有关的loss。这个loss由两部分组成,下面一支代表,每个box的center都需要有一个center去预测。
Heading Loss
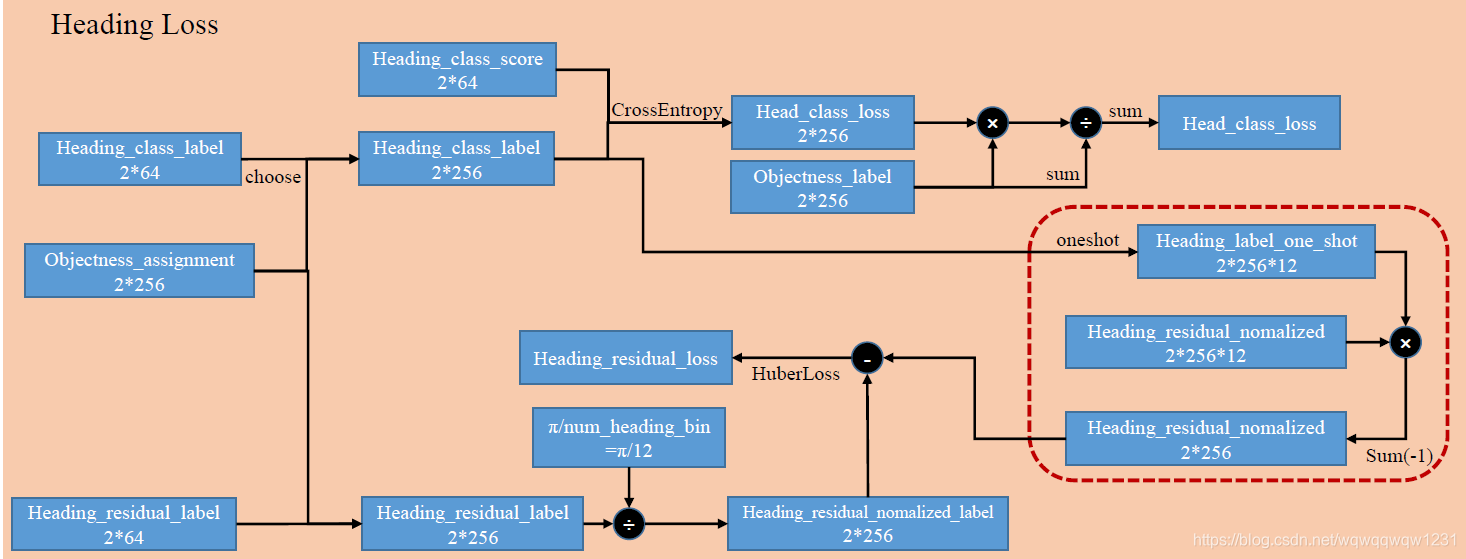
计算与box heading有关的loss,包括Classification和regression的部分,步骤如下:
- 根据Objectness_assignment从heading_class_label中选取对应的,构建label,然后与预测的heading_class_score求loss,使用objectness_label做mask,只有是objectness的部分参与计算heading_class_loss
- 根据Objectness_assignment从heading_residual_label中选取对应的,构建label,然后用角度归一化。接下来着重解释一下,由heading_class_label变成one_hot,只有正确的那个heading_class为1,其余为0,与heading_residual_nomalized相乘,使得正确的heading_class对应的那个residual不为0,其余residual为0,再相加,只不过相当于减少这个维度。
- 然后与构建Heading_residual_normalized_label去HuberLoss
Size Loss

Semantice Classification Loss

计算sem_cls_loss的过程,同样首先是根据objectness_assignment和sem_cls_label构建新的label,然后送入CrossEntropy计算loss。
Loss打印详解
在训练过程中,会打印各个loss,如下:
mean box_loss: 0.453468
mean center_loss: 0.414120
mean heading_cls_loss: 0.181052
mean heading_reg_loss: 0.016689
mean loss: 9.394492
mean neg_ratio: 0.972461
mean obj_acc: 0.993152
mean objectness_loss: 0.006167
mean pos_ratio: 0.011475
mean sem_cls_loss: 0.022770
mean size_cls_loss: 0.022605
mean size_reg_loss: 0.002293
mean vote_loss: 0.480620
这里总结一下:
- mean vote_loss:vote的真是坐标点(其实就是真实的物体中心)与pred_vote的L1距离差距的均值
- mean objectness_loss:aggregated_vote是否预测box的loss,当aggregated_vote与实际物体中心点离的比较近的时候,才是预测object
-
mean center_loss:预测的最终box的center与真实center的差距,
其中很重要的一点是,当出现某一个真实的物体上没有aggregated_vote时,会使得第二项loss变得很大
- mean heading_reg_loss:真实值在[-1,1]之间,使用huber loss计算,huber loss的delta是1.0
- mean size_cls_loss:当预置的size很接近时,这个loss会比较大
- mean size_reg_loss:因为是在预置的size上做reg,所以loss会收敛到比较小。
Eval
在train的过程中有evaluate_one_epoch(),也有eval.py也有evaluate_one_epoch(),这两者的区别仅在于eval.py中的evaluate_one_epoch()要对多个IoU进行计算AP,而trian过程中,只对单一的IoU计算,这里就以train过程中的举例
# train.py
def evaluate_one_epoch():
stat_dict = {} # collect statistics
ap_calculator = APCalculator(ap_iou_thresh=FLAGS.ap_iou_thresh,
class2type_map=DATASET_CONFIG.class2type)
net.eval() # set model to eval mode (for bn and dp)
for batch_idx, batch_data_label in enumerate(TEST_DATALOADER):
if batch_idx % 10 == 0:
print('Eval batch: %d'%(batch_idx))
for key in batch_data_label:
batch_data_label[key] = batch_data_label[key].to(device)
# Forward pass
inputs = {'point_clouds': batch_data_label['point_clouds']}
with torch.no_grad():
end_points = net(inputs)
# Compute loss
for key in batch_data_label:
assert(key not in end_points)
end_points[key] = batch_data_label[key]
loss, end_points = criterion(end_points, DATASET_CONFIG)
# Accumulate statistics and print out
for key in end_points:
if 'loss' in key or 'acc' in key or 'ratio' in key:
if key not in stat_dict: stat_dict[key] = 0
stat_dict[key] += end_points[key].item()
batch_pred_map_cls = parse_predictions(end_points, CONFIG_DICT)
batch_gt_map_cls = parse_groundtruths(end_points, CONFIG_DICT)
# 储存每一个batch的结果,这个重点还是要理解上面两行在干什么。
ap_calculator.step(batch_pred_map_cls, batch_gt_map_cls)
# Dump evaluation results for visualization
if FLAGS.dump_results and batch_idx == 0 and EPOCH_CNT %10 == 0:
MODEL.dump_results(end_points, DUMP_DIR, DATASET_CONFIG)
# Log statistics
# TEST_VISUALIZER.log_scalars({key:stat_dict[key]/float(batch_idx+1) for key in stat_dict},
# (EPOCH_CNT+1)*len(TRAIN_DATALOADER)*BATCH_SIZE)
for key in sorted(stat_dict.keys()):
log_string('eval mean %s: %f'%(key, stat_dict[key]/(float(batch_idx+1))))
# Evaluate average precision
metrics_dict = ap_calculator.compute_metrics()
for key in metrics_dict:
log_string('eval %s: %f'%(key, metrics_dict[key]))
mean_loss = stat_dict['loss']/float(batch_idx+1)
return mean_loss
这段程序不难懂,使用ap_calculator保存每一个batch的pred和gt信息,然后最后进行计算。重点在保存了哪些信息,这就需要看一下parse_predictions和parse_groundtruths函数
# models/ap_helper.py
def parse_predictions(end_points, config_dict):
""" Parse predictions to OBB parameters and suppress overlapping boxes
Args:
end_points: dict
{point_clouds, center, heading_scores, heading_residuals,
size_scores, size_residuals, sem_cls_scores}
config_dict: dict
{dataset_config, remove_empty_box, use_3d_nms, nms_iou,
use_old_type_nms, conf_thresh, per_class_proposal}
Returns:
batch_pred_map_cls: a list of len == batch size (BS)
[pred_list_i], i = 0, 1, ..., BS-1
where pred_list_i = [(pred_sem_cls, box_params, box_score)_j]
where j = 0, ..., num of valid detections - 1 from sample input i
"""
pred_center = end_points['center'] # B,num_proposal,3
pred_heading_class = torch.argmax(end_points['heading_scores'], -1) # B,num_proposal
pred_heading_residual = torch.gather(end_points['heading_residuals'], 2,
pred_heading_class.unsqueeze(-1)) # B,num_proposal,1
pred_heading_residual.squeeze_(2)
pred_size_class = torch.argmax(end_points['size_scores'], -1) # B,num_proposal
pred_size_residual = torch.gather(end_points['size_residuals'], 2,
pred_size_class.unsqueeze(-1).unsqueeze(-1).repeat(1,1,1,3)) # B,num_proposal,1,3
pred_size_residual.squeeze_(2)
pred_sem_cls = torch.argmax(end_points['sem_cls_scores'], -1) # B,num_proposal
sem_cls_probs = softmax(end_points['sem_cls_scores'].detach().cpu().numpy()) # B,num_proposal,10
pred_sem_cls_prob = np.max(sem_cls_probs,-1) # B,num_proposal
num_proposal = pred_center.shape[1]
# Since we operate in upright_depth coord for points, while util functions
# assume upright_camera coord.
bsize = pred_center.shape[0]
pred_corners_3d_upright_camera = np.zeros((bsize, num_proposal, 8, 3))
pred_center_upright_camera = flip_axis_to_camera(pred_center.detach().cpu().numpy())
for i in range(bsize):
for j in range(num_proposal):
heading_angle = config_dict['dataset_config'].class2angle(\
pred_heading_class[i,j].detach().cpu().numpy(), pred_heading_residual[i,j].detach().cpu().numpy())
box_size = config_dict['dataset_config'].class2size(\
int(pred_size_class[i,j].detach().cpu().numpy()), pred_size_residual[i,j].detach().cpu().numpy())
corners_3d_upright_camera = get_3d_box(box_size, heading_angle, pred_center_upright_camera[i,j,:])
pred_corners_3d_upright_camera[i,j] = corners_3d_upright_camera
K = pred_center.shape[1] # K==num_proposal
nonempty_box_mask = np.ones((bsize, K))
if config_dict['remove_empty_box']:
# -------------------------------------
# Remove predicted boxes without any point within them..
batch_pc = end_points['point_clouds'].cpu().numpy()[:,:,0:3] # B,N,3
for i in range(bsize):
pc = batch_pc[i,:,:] # (N,3)
for j in range(K):
box3d = pred_corners_3d_upright_camera[i,j,:,:] # (8,3)
box3d = flip_axis_to_depth(box3d)
pc_in_box,inds = extract_pc_in_box3d(pc, box3d)
if len(pc_in_box) < 5:
nonempty_box_mask[i,j] = 0
# -------------------------------------
obj_logits = end_points['objectness_scores'].detach().cpu().numpy()
obj_prob = softmax(obj_logits)[:,:,1] # (B,K)
if not config_dict['use_3d_nms']:
# ---------- NMS input: pred_with_prob in (B,K,7) -----------
pred_mask = np.zeros((bsize, K))
for i in range(bsize):
boxes_2d_with_prob = np.zeros((K,5))
for j in range(K):
boxes_2d_with_prob[j,0] = np.min(pred_corners_3d_upright_camera[i,j,:,0])
boxes_2d_with_prob[j,2] = np.max(pred_corners_3d_upright_camera[i,j,:,0])
boxes_2d_with_prob[j,1] = np.min(pred_corners_3d_upright_camera[i,j,:,2])
boxes_2d_with_prob[j,3] = np.max(pred_corners_3d_upright_camera[i,j,:,2])
boxes_2d_with_prob[j,4] = obj_prob[i,j]
nonempty_box_inds = np.where(nonempty_box_mask[i,:]==1)[0]
pick = nms_2d_faster(boxes_2d_with_prob[nonempty_box_mask[i,:]==1,:],
config_dict['nms_iou'], config_dict['use_old_type_nms'])
assert(len(pick)>0)
pred_mask[i, nonempty_box_inds[pick]] = 1
end_points['pred_mask'] = pred_mask
# ---------- NMS output: pred_mask in (B,K) -----------
elif config_dict['use_3d_nms'] and (not config_dict['cls_nms']):
# ---------- NMS input: pred_with_prob in (B,K,7) -----------
pred_mask = np.zeros((bsize, K))
for i in range(bsize):
boxes_3d_with_prob = np.zeros((K,7))
for j in range(K):
boxes_3d_with_prob[j,0] = np.min(pred_corners_3d_upright_camera[i,j,:,0])
boxes_3d_with_prob[j,1] = np.min(pred_corners_3d_upright_camera[i,j,:,1])
boxes_3d_with_prob[j,2] = np.min(pred_corners_3d_upright_camera[i,j,:,2])
boxes_3d_with_prob[j,3] = np.max(pred_corners_3d_upright_camera[i,j,:,0])
boxes_3d_with_prob[j,4] = np.max(pred_corners_3d_upright_camera[i,j,:,1])
boxes_3d_with_prob[j,5] = np.max(pred_corners_3d_upright_camera[i,j,:,2])
boxes_3d_with_prob[j,6] = obj_prob[i,j]
nonempty_box_inds = np.where(nonempty_box_mask[i,:]==1)[0]
pick = nms_3d_faster(boxes_3d_with_prob[nonempty_box_mask[i,:]==1,:],
config_dict['nms_iou'], config_dict['use_old_type_nms'])
assert(len(pick)>0)
pred_mask[i, nonempty_box_inds[pick]] = 1
end_points['pred_mask'] = pred_mask
# ---------- NMS output: pred_mask in (B,K) -----------
elif config_dict['use_3d_nms'] and config_dict['cls_nms']:
# ---------- NMS input: pred_with_prob in (B,K,8) -----------
pred_mask = np.zeros((bsize, K))
for i in range(bsize):
boxes_3d_with_prob = np.zeros((K,8))
for j in range(K):
boxes_3d_with_prob[j,0] = np.min(pred_corners_3d_upright_camera[i,j,:,0])
boxes_3d_with_prob[j,1] = np.min(pred_corners_3d_upright_camera[i,j,:,1])
boxes_3d_with_prob[j,2] = np.min(pred_corners_3d_upright_camera[i,j,:,2])
boxes_3d_with_prob[j,3] = np.max(pred_corners_3d_upright_camera[i,j,:,0])
boxes_3d_with_prob[j,4] = np.max(pred_corners_3d_upright_camera[i,j,:,1])
boxes_3d_with_prob[j,5] = np.max(pred_corners_3d_upright_camera[i,j,:,2])
boxes_3d_with_prob[j,6] = obj_prob[i,j]
boxes_3d_with_prob[j,7] = pred_sem_cls[i,j] # only suppress if the two boxes are of the same class!!
nonempty_box_inds = np.where(nonempty_box_mask[i,:]==1)[0]
pick = nms_3d_faster_samecls(boxes_3d_with_prob[nonempty_box_mask[i,:]==1,:],
config_dict['nms_iou'], config_dict['use_old_type_nms'])
assert(len(pick)>0)
pred_mask[i, nonempty_box_inds[pick]] = 1
end_points['pred_mask'] = pred_mask
# ---------- NMS output: pred_mask in (B,K) -----------
batch_pred_map_cls = [] # a list (len: batch_size) of list (len: num of predictions per sample) of tuples of pred_cls, pred_box and conf (0-1)
for i in range(bsize):
if config_dict['per_class_proposal']:
cur_list = []
for ii in range(config_dict['dataset_config'].num_class):
cur_list += [(ii, pred_corners_3d_upright_camera[i,j], sem_cls_probs[i,j,ii]*obj_prob[i,j]) \
for j in range(pred_center.shape[1]) if pred_mask[i,j]==1 and obj_prob[i,j]>config_dict['conf_thresh']]
batch_pred_map_cls.append(cur_list)
else:
batch_pred_map_cls.append([(pred_sem_cls[i,j].item(), pred_corners_3d_upright_camera[i,j], obj_prob[i,j]) \
for j in range(pred_center.shape[1]) if pred_mask[i,j]==1 and obj_prob[i,j]>config_dict['conf_thresh']])
end_points['batch_pred_map_cls'] = batch_pred_map_cls
return batch_pred_map_cls
def parse_groundtruths(end_points, config_dict):
""" Parse groundtruth labels to OBB parameters.
Args:
end_points: dict
{center_label, heading_class_label, heading_residual_label,
size_class_label, size_residual_label, sem_cls_label,
box_label_mask}
config_dict: dict
{dataset_config}
Returns:
batch_gt_map_cls: a list of len == batch_size (BS)
[gt_list_i], i = 0, 1, ..., BS-1
where gt_list_i = [(gt_sem_cls, gt_box_params)_j]
where j = 0, ..., num of objects - 1 at sample input i
"""
center_label = end_points['center_label']
heading_class_label = end_points['heading_class_label']
heading_residual_label = end_points['heading_residual_label']
size_class_label = end_points['size_class_label']
size_residual_label = end_points['size_residual_label']
box_label_mask = end_points['box_label_mask']
sem_cls_label = end_points['sem_cls_label']
bsize = center_label.shape[0]
K2 = center_label.shape[1] # K2==MAX_NUM_OBJ
gt_corners_3d_upright_camera = np.zeros((bsize, K2, 8, 3))
gt_center_upright_camera = flip_axis_to_camera(center_label[:,:,0:3].detach().cpu().numpy())
for i in range(bsize):
for j in range(K2):
if box_label_mask[i,j] == 0: continue
heading_angle = config_dict['dataset_config'].class2angle(heading_class_label[i,j].detach().cpu().numpy(), heading_residual_label[i,j].detach().cpu().numpy())
box_size = config_dict['dataset_config'].class2size(int(size_class_label[i,j].detach().cpu().numpy()), size_residual_label[i,j].detach().cpu().numpy())
corners_3d_upright_camera = get_3d_box(box_size, heading_angle, gt_center_upright_camera[i,j,:])
gt_corners_3d_upright_camera[i,j] = corners_3d_upright_camera
batch_gt_map_cls = []
for i in range(bsize):
batch_gt_map_cls.append([(sem_cls_label[i,j].item(), gt_corners_3d_upright_camera[i,j]) for j in range(gt_corners_3d_upright_camera.shape[1]) if box_label_mask[i,j]==1])
end_points['batch_gt_map_cls'] = batch_gt_map_cls
return batch_gt_map_cls
parse_predictions:
- 通过end_points中的变量恢复出center,pred_size,pred_heading_angle
- 通过center,pred_size,pred_heading_angle,恢复出pred_box的8个顶点
- 做nms
- 将最终nms过后的box存成ap_calculator的格式
parse_groundtruths:
- 通过label中的变量恢复出center,box_size,heading_angle
- 通过center,box_size,heading_angle,恢复出box的8个顶点
- 将box的顶点存成ap_calculator的格式
其中要注意的是:
注释中有下面这一句话,然后就将center的坐标变了一下
# Since we operate in upright_depth coord for points, while util functions assume upright_camera coord.
pred_center_upright_camera = flip_axis_to_camera(pred_center.detach().cpu().numpy())
这个变换在parse_predictions和parse_groundtruths都出现了,这是为什么呢?根据注释的提示,说的是util funciton用的是camera coord,所以找到使用这个center的代码:
corners_3d_upright_camera = get_3d_box(box_size, heading_angle, pred_center_upright_camera[i,j,:])
那么get_3d_box为什么一定要center是camera coord呢?
# utils/box_util.py
def get_3d_box(box_size, heading_angle, center):
''' box_size is array(l,w,h), heading_angle is radius clockwise from pos x axis, center is xyz of box center
output (8,3) array for 3D box cornders
Similar to utils/compute_orientation_3d
'''
R = roty(heading_angle)
l,w,h = box_size
x_corners = [l/2,l/2,-l/2,-l/2,l/2,l/2,-l/2,-l/2];
y_corners = [h/2,h/2,h/2,h/2,-h/2,-h/2,-h/2,-h/2];
z_corners = [w/2,-w/2,-w/2,w/2,w/2,-w/2,-w/2,w/2];
corners_3d = np.dot(R, np.vstack([x_corners,y_corners,z_corners]))
corners_3d[0,:] = corners_3d[0,:] + center[0];
corners_3d[1,:] = corners_3d[1,:] + center[1];
corners_3d[2,:] = corners_3d[2,:] + center[2];
corners_3d = np.transpose(corners_3d)
return corners_3d
代码显示,要以y轴做旋转。这就不难理解为什么要换一下center的坐标了。而且y是竖直向下的,对应了box_size中的h。但这样子又会出现一个问题,原来的坐标系X-right,Y-forward,Z-up中,以z轴做rotation和camera coord(X-right,Y-down,Z-forward)中,以y轴做rotation的方向正好是相反的。所以按照这里理解计算出来的pred_heading_angle是按照camera coord的方向的,这个在sunrgbd的可视化中也有体现:
# sunrgbd/sunrgbd_data.py
# Dump OBJ files for 3D bounding boxes
# l,w,h correspond to dx,dy,dz
# heading angle is from +X rotating towards -Y
# (+X is degree, -Y is 90 degrees)
oriented_boxes = []
for obj in objects:
obb = np.zeros((7))
obb[0:3] = obj.centroid
# Some conversion to map with default setting of w,l,h
# and angle in box dumping
obb[3:6] = np.array([obj.l,obj.w,obj.h])*2
obb[6] = -1 * obj.heading_angle
print('Object cls, heading, l, w, h:',\
obj.classname, obj.heading_angle, obj.l, obj.w, obj.h)
oriented_boxes.append(obb)
可以看到,在储存3D box时,heading_angle乘以了-1,这就说明转角方向取相反。也就印证了上面说的,pred_heading_angle是在camara coord下的。
NMS
特别好的NMS的一个范例:
# utils/nsm.py
def nms_3d_faster_samecls(boxes, overlap_threshold, old_type=False):
x1 = boxes[:,0]
y1 = boxes[:,1]
z1 = boxes[:,2]
x2 = boxes[:,3]
y2 = boxes[:,4]
z2 = boxes[:,5]
score = boxes[:,6]
cls = boxes[:,7]
area = (x2-x1)*(y2-y1)*(z2-z1)
I = np.argsort(score)
pick = []
while (I.size!=0):
last = I.size
i = I[-1]
pick.append(i)
xx1 = np.maximum(x1[i], x1[I[:last-1]])
yy1 = np.maximum(y1[i], y1[I[:last-1]])
zz1 = np.maximum(z1[i], z1[I[:last-1]])
xx2 = np.minimum(x2[i], x2[I[:last-1]])
yy2 = np.minimum(y2[i], y2[I[:last-1]])
zz2 = np.minimum(z2[i], z2[I[:last-1]])
cls1 = cls[i]
cls2 = cls[I[:last-1]]
l = np.maximum(0, xx2-xx1)
w = np.maximum(0, yy2-yy1)
h = np.maximum(0, zz2-zz1)
if old_type:
o = (l*w*h)/area[I[:last-1]]
else:
inter = l*w*h
o = inter / (area[i] + area[I[:last-1]] - inter)
o = o * (cls1==cls2)
I = np.delete(I, np.concatenate(([last-1], np.where(o>overlap_threshold)[0])))
return pick
使用meshlab可视化
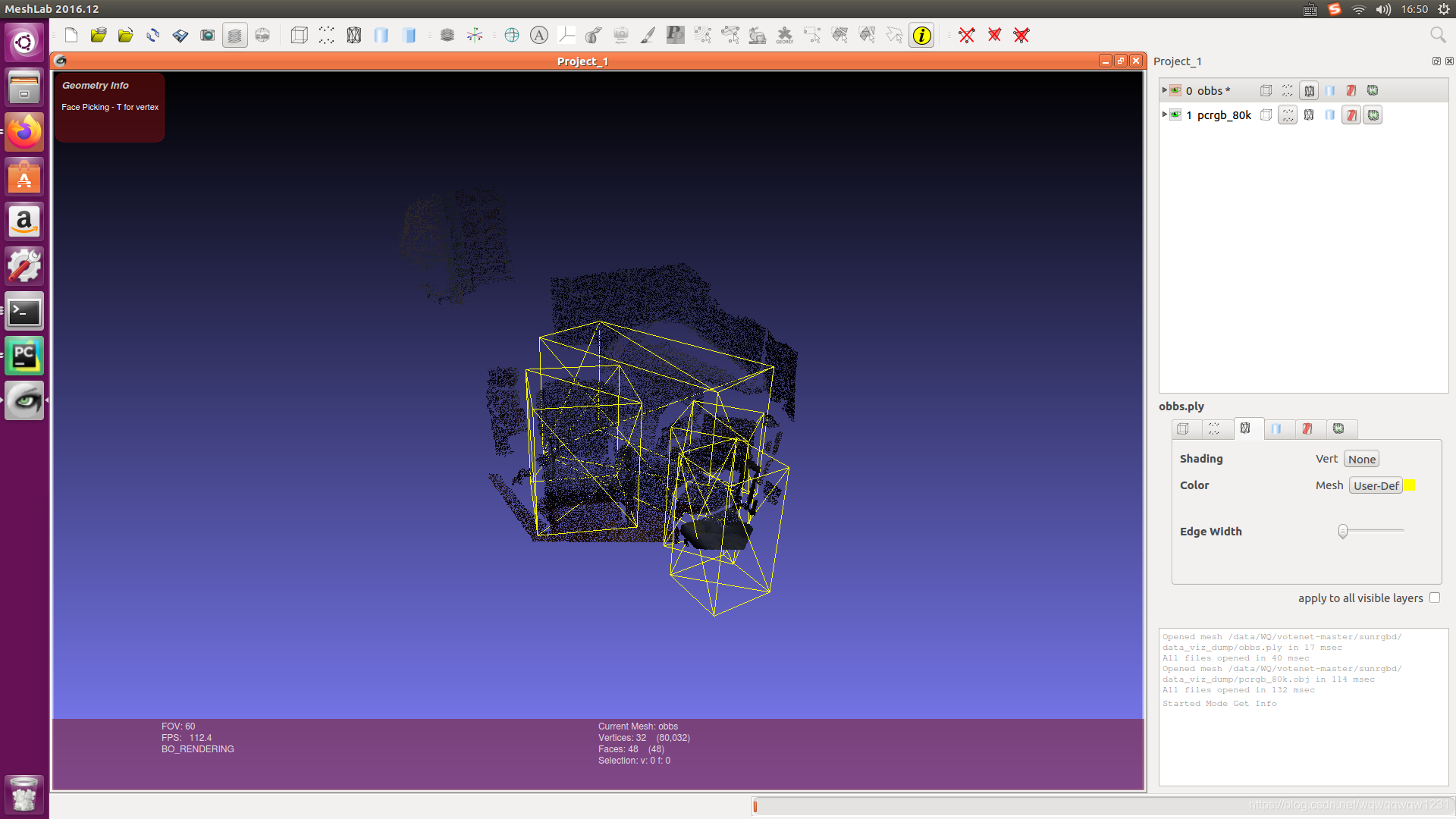
本代码不再以来mayavi和qt,这个我也安装过,使用复杂。具体可以参考我的另外几篇博客:
本文使用的meshlab可视化,具体的可以参考sunrgbd/sunrgbd_data.py的data_viz函数。下面放一张效果图: