项目流程
(1)分析职位页面的请求方式与请求数据
1.随便搜索一个职位进入职位界面,然后点击下一页,发现浏览器顶部的网址并未发生变化,因此分析请求方式应该是ajax的发起的post请求
2.点击右键打开浏览器的检查元素,选择network,再点击下面的XHR,此时再次点击下一页,发现出现一个ajax请求,点击进去会出现请求头,响应数据,查询字符串参数与请求数据,根据这些数据可知确实是ajax的post请求
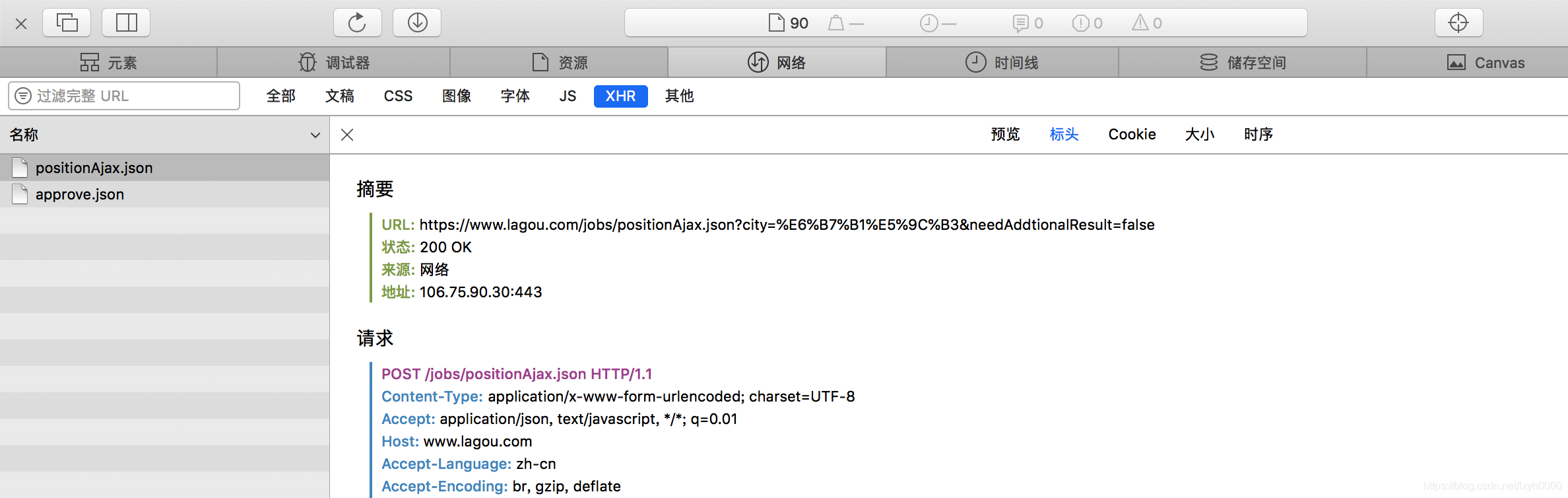
3.再次点击一个界面,然后对比两次请求数据的差异,分析出哪些数据是不变的,哪些是该改变的,以及改变的规律是什么,对比之后你会发现改变的数据只有页数,其他并未改变,而且可以根据字段的意思分析出每个字段携带的数据是什么。
(2)找出需要数据的位置
1.点击预览可以看到返回的响应信息,然后去分析这些响应信息,我们可以看出我们需要的信息在result中(这里可以百度第三方工具json在线编辑器去转换一下,更有助于我们去分析这些json数据)
2.找到位置后就需要我们研究如何去取出我们需要的数据,这里选择使用jsonpath来进行取数据,jsonpath的使用非常简单,根据数据的形式我们可以得出匹配格式为jsonpath(python_obj, “$…result”)[0],其中python_obj为响应的json数据转换后的python数据类型
3.分析完之后就可以使用代码来实现了,如果代码完成过程中发现有什么缺失的地方没有注意到,就回头继续完善分析
(3)代码实现
1.先建立一个代码框架,写出需要实现的函数,这样有利于思路的清晰,写出一个主函数,一个请求函数,一个处理函数,一个保存函数
2.主函数中写整个项目的流程,所有的调用都在主函数中
3.请求函数只负责向服务器发送请求,并接收返回数据(这里使用requests发送请求)
4.处理函数根据自己的需求去取出我们需要的数据(前面已经分析出如何取出数据,可以直接写入代码)
5.保存函数根据自己方便查看的文件格式进行保存(这里选择csv格式保存数据)
具体代码流程与步骤详解源码中都有注释
(如果想看源码或更多小项目请点击
码云
)
注意事项:
(1)此流程适用于大部分爬虫项目
(2)此项目我设置的爬取前5页,可以自行修改
(3)保存的csv文件如果直接使用wps打开可能出现乱码,可以在wps设置编码为utf-8就可以了