首先理解范数的概念
L1、L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数。
范数(norm)是数学中的一种基本概念。在
泛函分析
中,它定义在赋范线性空间中,并满足一定的条件,即①非负性;②齐次性;③三角不等式。它常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。
L1就是曼哈顿距离
L2就是欧式距离
再理解什么是稀疏矩阵
在
矩阵
中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。定义非零元素的总数比上矩阵所有元素的总数为矩阵的稠密度。
监督学习的过程可以概括为:最小化误差的同时规则化参数。最小化误差是为了让模型拟合训练数据,规则化参数是为了防止过拟合。参数过多会导致模型复杂度上升,产生过拟合,即训练误差很小,但测试误差很大,这和监督学习的目标是相违背的。所以需要采取措施,保证模型尽量简单的基础上,最小化训练误差,使模型具有更好的泛化能力(即测试误差也很小)。
范数规则化有两个作用:
1)保证模型尽可能的简单,避免过拟合。
2)约束模型特性,加入一些先验知识,例如稀疏、低秩等。
一般来说,监督学习中最小化的目标函数结构如下:
规则化函数Ω有多重选择,不同的选择效果也不同,不过
一般是模型复杂度的单调递增函数——模型越复杂,规则化值越大。
例如,可以是模型中参数向量的范数。常见的选择包括零范数,一范数,二范数等。下面挑选部分范数简单说明。
1 L0范数和L1范数
L0范数是指向量中非零元素的个数。如果用L0规则化一个参数矩阵W,就是希望W中大部分元素是零,实现稀疏。
L1范数是指向量中各个元素的绝对值之和,也叫”系数规则算子(Lasso regularization)“。L1范数也可以实现稀疏,通过将无用特征对应的参数W置为零实现。
L0和L1都可以实现稀疏化,不过一般选用L1而不用L0,原因包括:1)L0范数很难优化求解(NP难);2)L1是L0的最优凸近似,比L0更容易优化求解。(这一段解释过于数学化,姑且当做结论记住)
稀疏化的好处是是什么?
1)特征选择
实现特征的自动选择,去除无用特征。稀疏化可以去掉这些无用特征,将特征对应的权重置为零。
2)可解释性(interpretability)
例如判断某种病的患病率时,最初有1000个特征,建模后参数经过稀疏化,最终只有5个特征的参数是非零的,那么就可以说影响患病率的主要就是这5个特征。
2 L2范数
L2范数
是指向量各元素的平方和然后开方,用在回归模型中也称为岭回归(Ridge regression)。
L2避免过拟合的原理是:让L2范数的规则项||W||
2
尽可能小,可以使得W每个元素都很小,接近于零,但是与L1不同的是,不会等于0;这样得到的模型抗干扰能力强,参数很小时,即使样本数据x发生很大的变化,模型预测值y的变化也会很有限。
************************************************************************************************
Lasso Regresssion使用的就是L1正则化, 下面就是Lasso Regression 的Loss Function的样子,是不是很美丽:
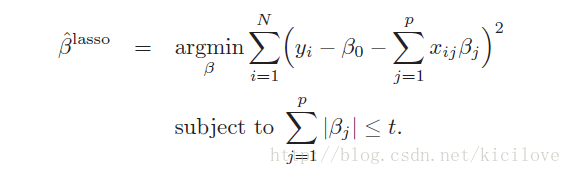
简单说一下,第一个SUM(∑)里面可以看出来是一个线性回归求损失平方,第二个SUM(∑)是线性回归中系数的服从条件,用来约束解的区域,凸优化中的约束求解一般都长这个样子。
此外,Lasso Regression的整体损失求极小的样子改成拉格朗日形式就是下面这个式子的模样:
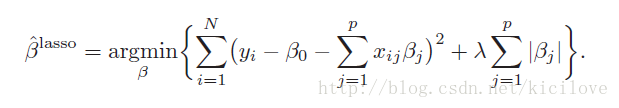
是不是找到了数学分析或者高等数学的感觉啦! 从式子里可以看到回归系数使用的是L1正则化,λ是惩罚参数或者叫做调节参数。L1范数的好处是当惩罚参数充分大时可以把某些待估的回归系数精确地收缩到0。
趁热打铁,我们再来看看Ridge Regression,也是线性回归的一个,看看简介:
RidgeRegression是一种专用于共线性的回归方法,对病态数据的拟合要强于最小二乘法(有想了解共线性问题,最小二乘的同学可以自己查资料了,如果对矩阵运算和矩阵性质熟悉的话会容易理解)。
岭回归使用的是L2正则化,下面的式子就是Ridge Regression的Loss Function 的美丽容颜:
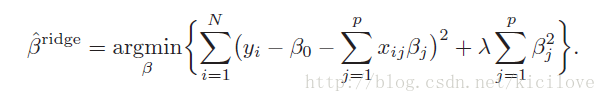
细心的同学眼睛已然盯上了式子的最后面,是不是传说中的L2正则项,系数的平方和。
上式的等价问题如下:
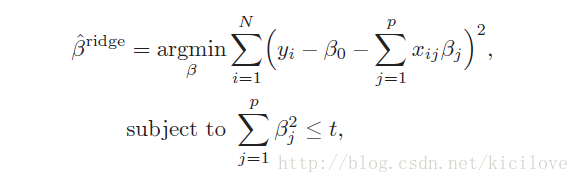
不管是Lasso Regression还是Ridge Regression 都有一个共同的参数,那就是惩罚参数λ,那么λ怎么来确定呢?
通常使用交叉验证法(CV)或者广义交叉验证(GCV),当然也可以使用AIC、BIC等指标。
我们学习Lasso Regression 或者Ridge Regression的时候,一定见过下面这张图:

下面从自己理解的角度和大家分享一下。
上面的图中实心的黑点也就是
β
^
β^
是真实的损失函数(不带有正则项的部分)我们暂叫做原问题的最优解,然后红色的圈圈就是系数
β
1
β1
、
β
2
β2
在原问题下可能的解的范围,接着是蓝色的实心圈是正则项约束的可能的解的范围。我们都知道如果两个函数要是有共同的解,那么在几何意义下或者说从几何图形上来看,这两个函数的图像所在范围是要有共同交点或者要有交集。所以,由于Lasso Regression或者Ridge Regression的整个Loss Function也就是我们的目标函数是由原问题和正则项两部分构成的,那么如果这个目标函数要有解并且是最小解的话,原问题和正则项就要有一个切点,这个切点就是原问题和正则项都满足各自解所在范围下的共同的解,红圈圈从图中的实心黑点也就是原问题最优解出发不断往外变化与蓝色实心圈相切的时候,L1范数意义下可能得到有的维度上的系数为零(就是切点所在的坐标处,
β
1
β1
坐标为0),这也就是为什么说L1可以导致稀疏解,同理L2范数意义下,相切的点就不在坐标轴上,
β
1
β1
和
β
2
β2
都取0。
也许你已经发现,其实说L1范数下可以导致稀疏并不是说L1范数下一定导致稀疏,这还得看原问题的最优解到底在哪个地方取值。
二.
L
q
Lq
下的目标函数
其实看到这里你可能会问,既然有L1、L2会不会有Lq呢?答案是肯定的,有!
直接上图

上图中,可以明显看到一个趋势,即q越小,曲线越贴近坐标轴,q越大,曲线越远离坐标轴,并且棱角越明显。那么 q=0 和 q=oo 时极限情况如何呢?猜猜看。
聪明的你猜对了吧,答案就是十字架和正方形。
也许你又开始有问题了,既然L0是十字架,为什么不用L0作为正则项?
从理论来说,L0确实是求稀疏解的最好的正则项,但是机器学习中特征的维度往往很大,你也可以理解为系数很多很多,然后解L0又是个NP-hard问题,因此在实际工程应用中极有限制,不可行。
也许你又有问题了,为啥我们非得得到稀疏解呢?
其实这个问题并不绝对。从统计上来说,稀疏解可以舒缓模型的过拟合问题,毕竟可以使模型复杂度降低了嘛,然后你从一些应用场景上来说,比如医生看病,你一下让他看几百几千。。。个指标得出正确答案简单,还是就几个关键指标就可以正确断诊来的好。毕竟解决问题还是要先抓住主要矛盾的,对不。
在统计学中,相比较于L1、L2这种特殊意义下的Lasso Regression 、Ridge Regression,更普遍意义Lq范数下的关于求系数的目标Loss Function为如下形式:

从上式可以看到最后面关于系数的约束就变成了Lq范数。