目录
一:什么是链表?
我们先看下面这个结构体。
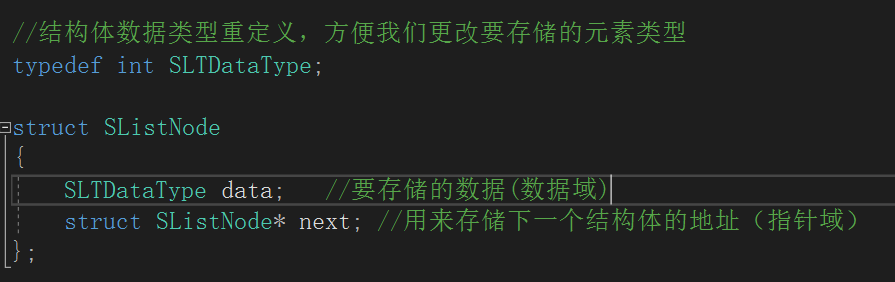
这个结构体存储数据的同时保存了一个结构体指针。
链表其实就是一个个结构体(后文把这样的一个结构体称为结点)
通过保存地址的方式找到下一个结构体,最后一个结构体保存的地址为空。
链表的两种实现方式
(1)带头结点
(2)不带头结点
区别:带头结点
有一个哨兵结点
,这个节点作为第一个节点,它的数据域不存储数据。两者各有利弊:我们进行结点删除时
需要用到待删除结点的前一个结点
。对于
没有哨兵的单链表
,当链表中只存在一个节点,
需要进行单独处理
。从而代码的复杂性增加。但如果设计了哨兵结点,则第一个结点的处理与其他结点一致。但处理链表数据时这个哨兵结点属于无效数据,
我们需要规避这个数据,也需要进行处理
。
本文选择的是无哨兵链表。
二:创建源文件和头文件
(1)头文件
头文件
SingleLinkedList.h
用来包含一些必要的头文件,声明函数以及定义结构体。
(2)源文件
源文件
SingleLinkedList.c
用来
实现链表的具体功能
。
源文件
text.c
用来对各个功能进行
测试
。
三:实参和形参
在实现链表之前,我们需要先深入的认识一下实参和形参的关系。
我们看下面这个代码:
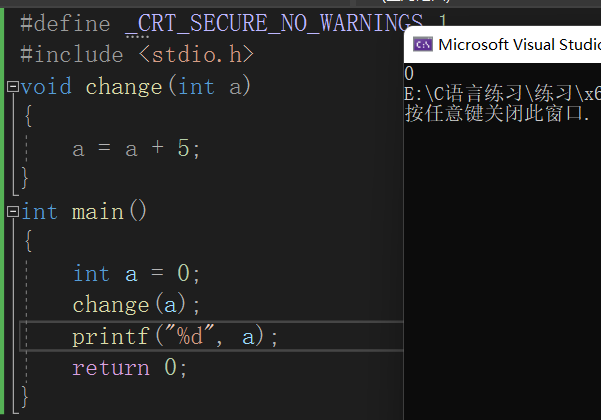
我们可以看到a的值并没有发生变化,那我们如果传入a的地址进行解引用呢?我们看下面这个代码。
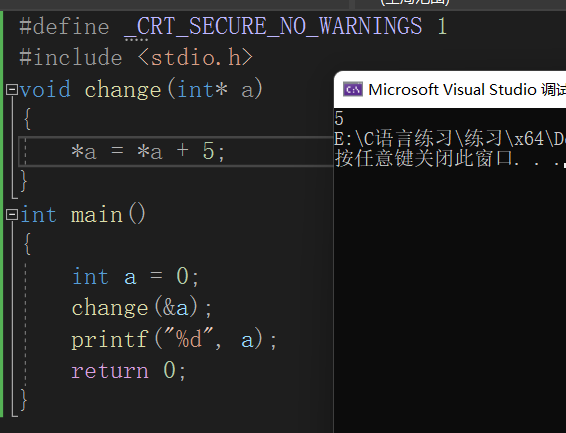
我们可以看到a成功被修改为了5,但这是为什么呢?
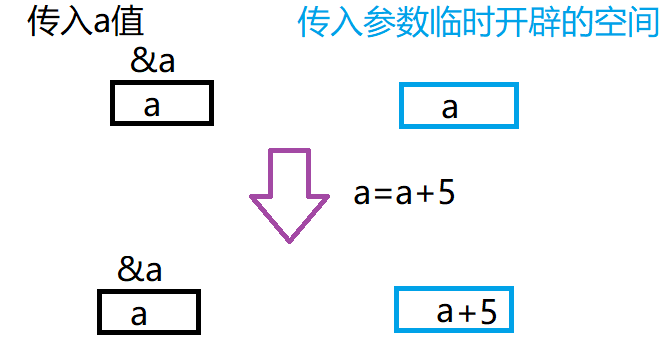
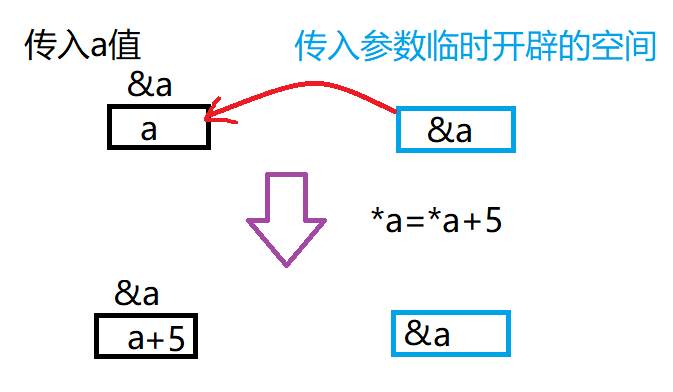
答:其实在传入参数的时候系统
临时开辟了一块空间用来接收数据
,函数调用结束时
这一块空间就会被释放
,这意味着如果我们直接传入a的值,我们只是
在对这一块临时开辟的空间内的数据进行修改
,无论如何都不会影响到a,但如果我们传入的是a的地址,
对a进行解引用就能直接找到并修改a
。
图解:
这是否意味着只要我们传入的是地址就一定能改变实参的值呢?我们看下面这个代码。
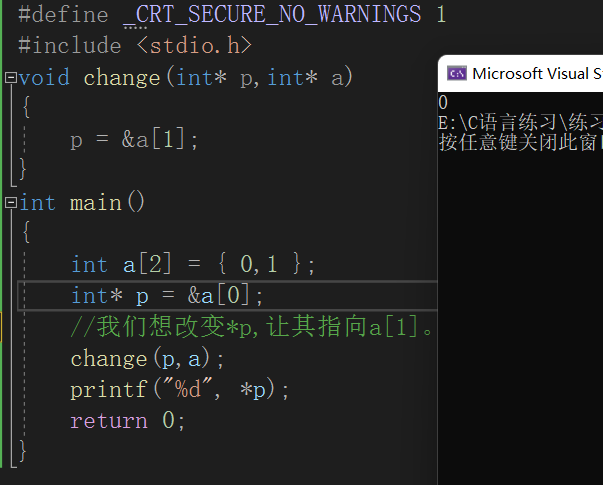
我们发现虽然传入的是地址,但p依旧指向a[0],并没有改变。这是为什么呢?
答:与前面的原理一致,我们传入p的时候也
临时开辟了一片空间来保存p的值
,无论我们怎么改变p值,
在函数调用结束后这片空间会被释放
,所以p实际上还是指向a[0]的。
图解:
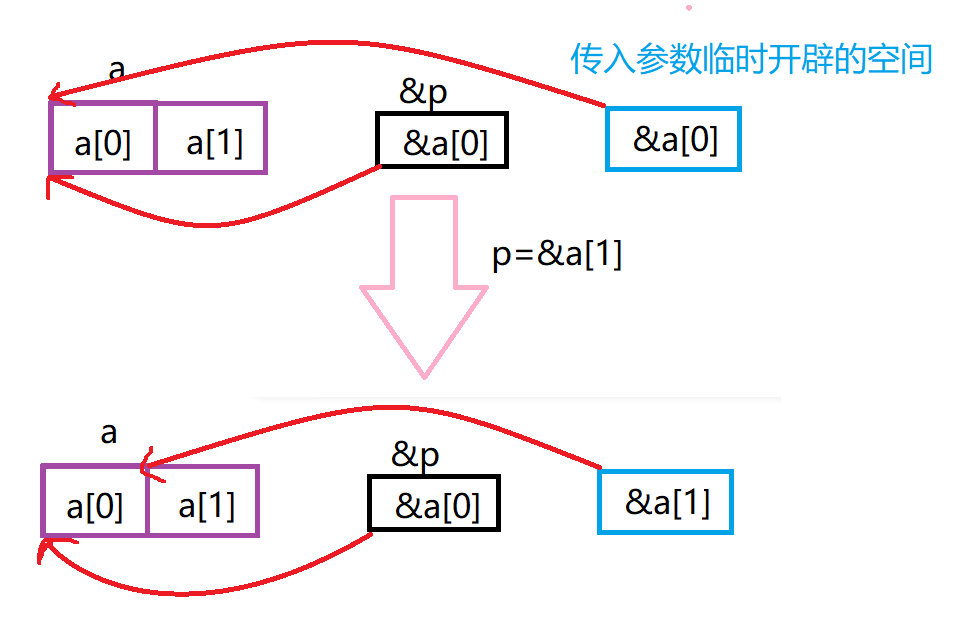
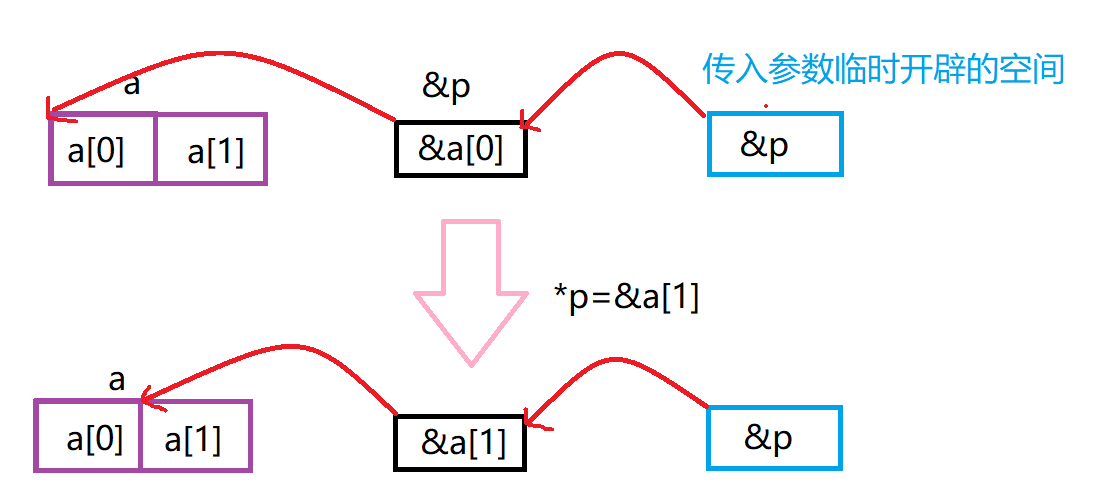
那如果我们传入p的地址,是不是就能改变p了呢?我们看代码。
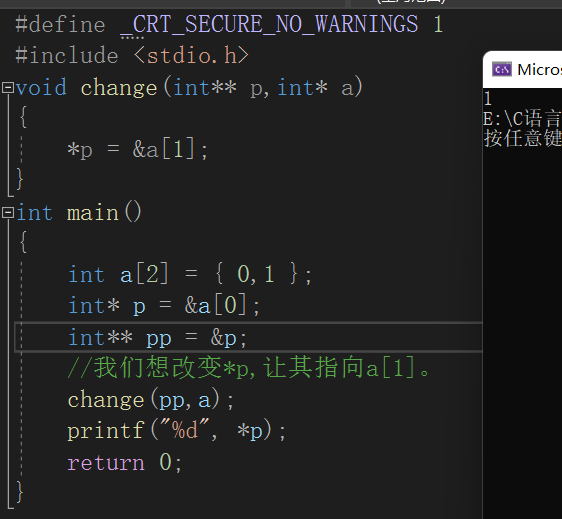
图解:
四:一步步实现单向链表
(1)建立一个头指针并置空
struct SListNode* head = NULL;
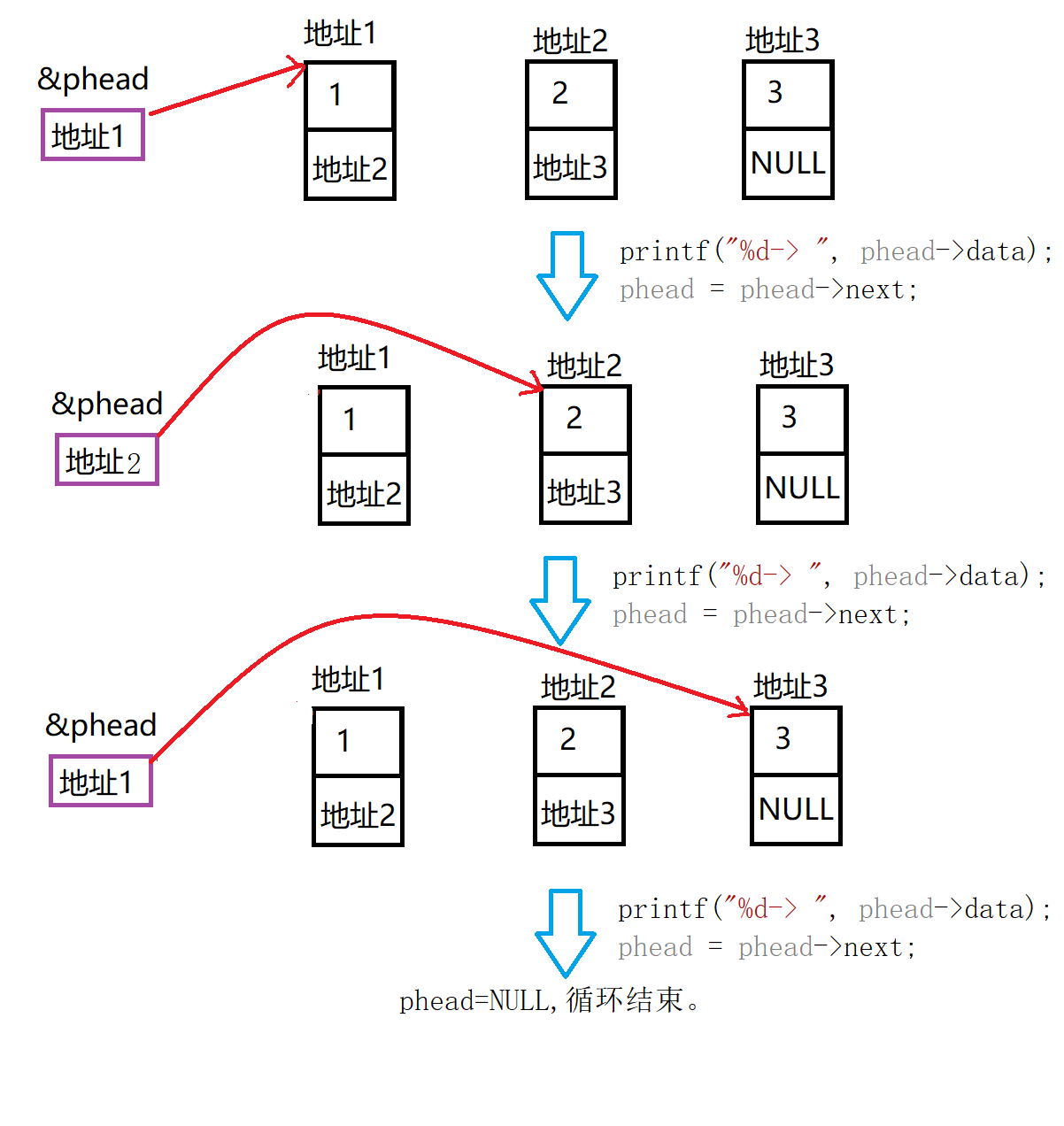
(2)打印链表,便于观察测试
我们用
头指针的地址是否为空为循环条件
。
我们可以分成两种情况讨论,如果链表为空,我们不进行遍历,直接打印NULL。
如果链表中有元素,从头指针(第一个结点)开始,我们打印结点数据,并让头指针指向下一个结点,一直到NULL。代码:

图解(以有三个结点为例子):
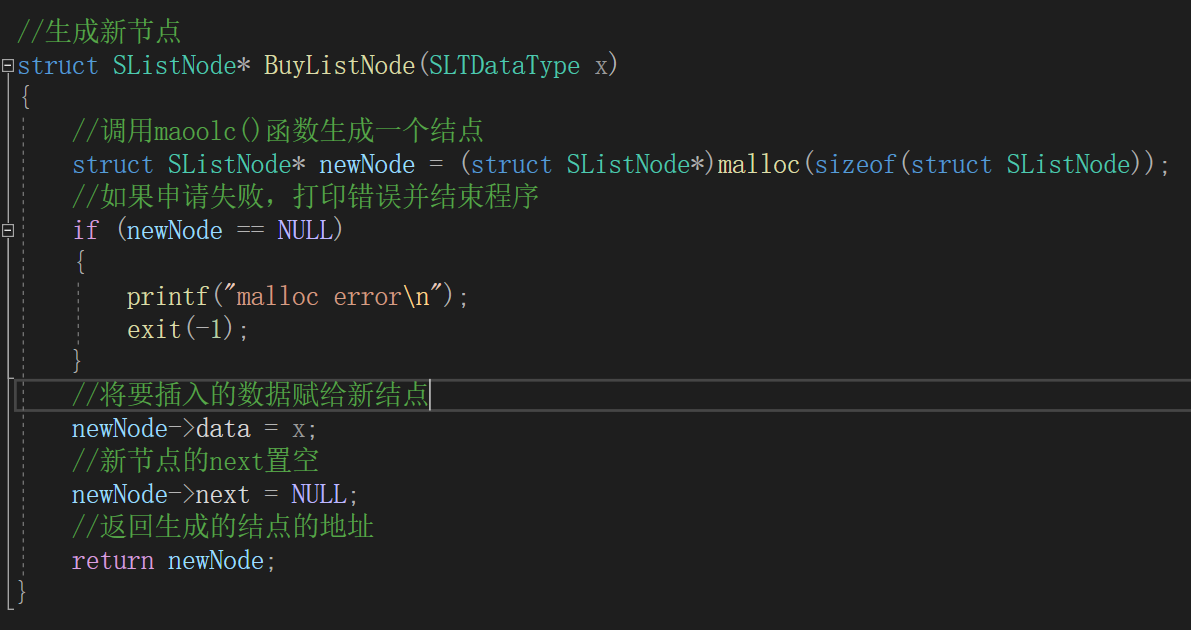
(3)创建一个新的结点
只要插入新结点,我们就一定要生成新的结点,我们可以把生成新结点的功能单独封装成函数
BuyListNode()
。代码:
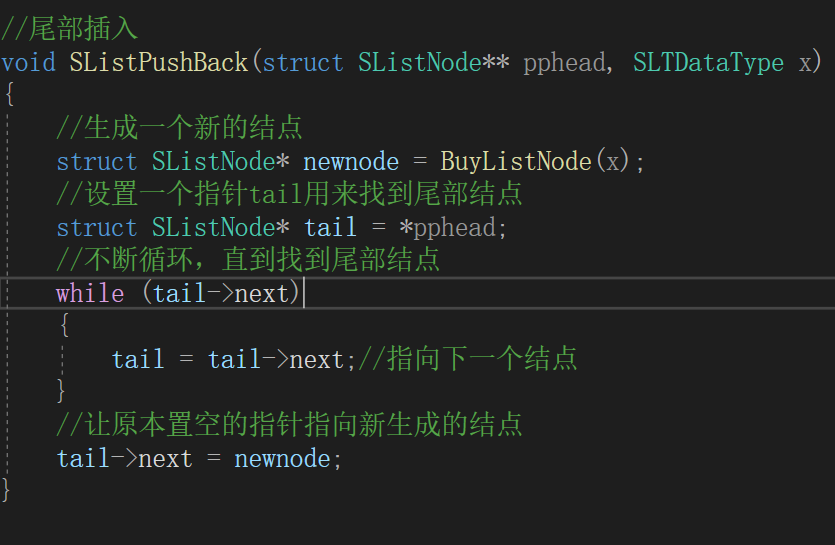
(4)尾部插入数据
进行数据插入,我们
要改变实参的值
(即改变指针的指向),
必须传入头指针的地址
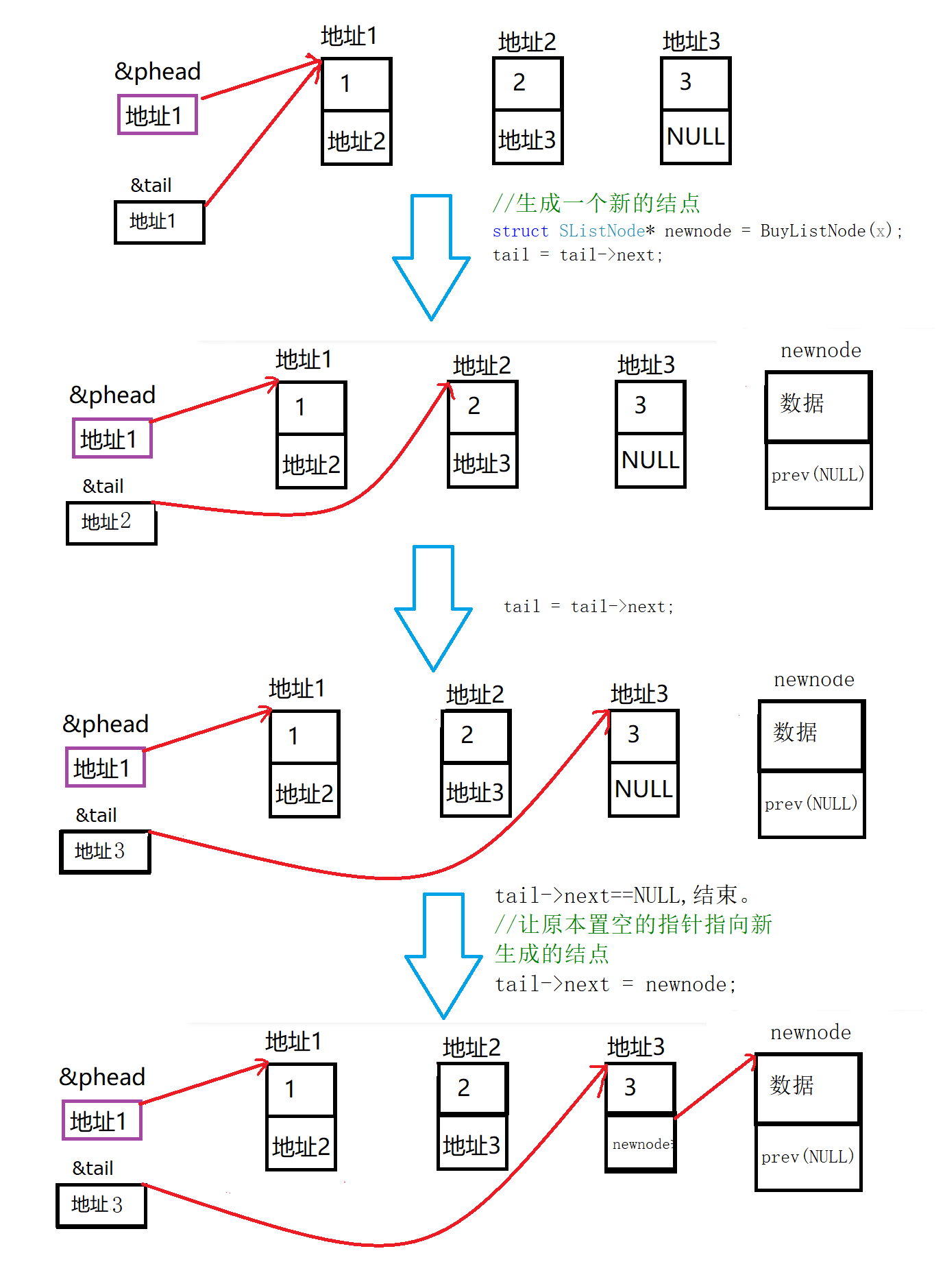
(二级指针)。基础思路:【1】在进行数据插入之前,我们要先
生成一个新的结点
。【2】要进行尾部插入,我们需要
找到链表的最后一个结点,并将它存储的指针指向新生成的结构体
。【3】我们设计一个指针
tail
来找尾部结点,如果
tail->next为NULL
,我们就找到了尾部结点,结束循环。图解:
现阶段代码:
我们对代码进行测试:
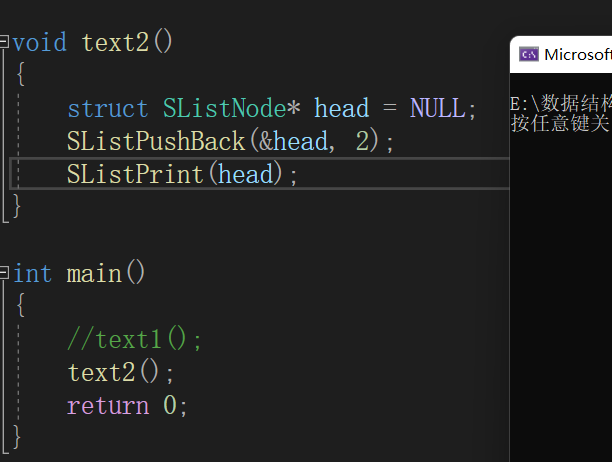
可以发现程序崩溃了,这是为什么呢?
答:这是因为我们没有考虑
链表为空
的情况,如果链表为空,我们会直接
对空指针进行解引用
,导致程序崩溃。
为了解决这个问题,我们可以对这种情况进行单独处理。
代码:
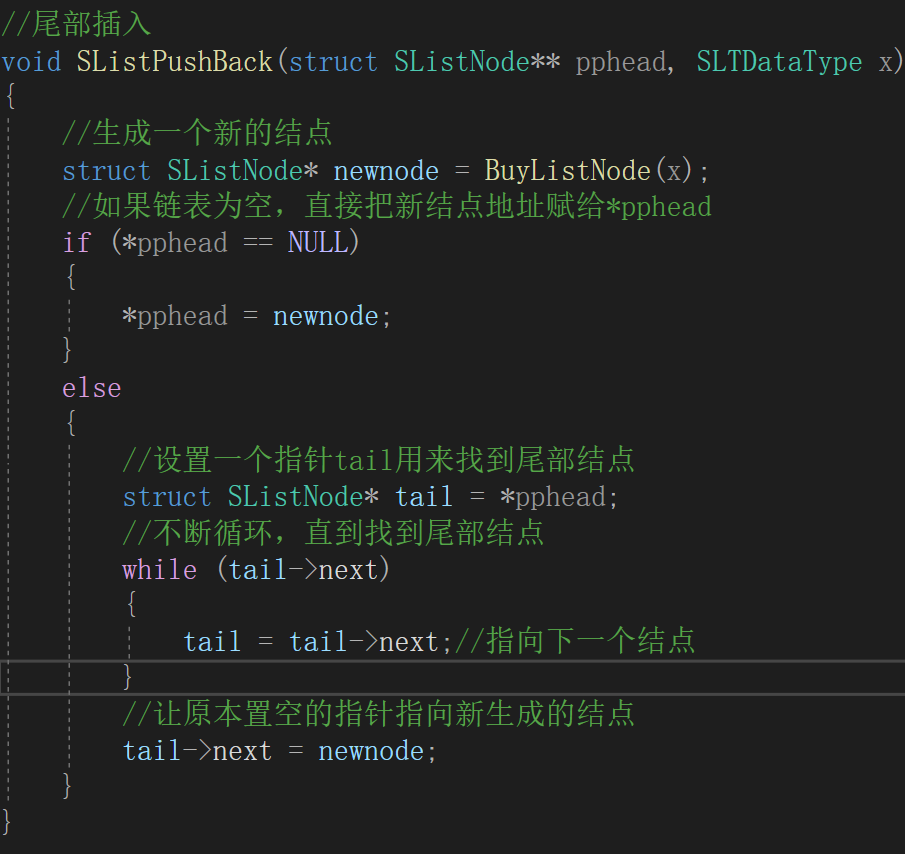
再次测试,观察结果。
我们发现数据成功插入了。
(5)头部插入
进行数据插入,我们
要改变实参的值
(即改变指针的指向),
必须传入头指针的地址
(二级指针)。思路:头部插入我们只需要
让头指针指向新结点
,让
新结点的指针域指向原来的头结点
。代码:

前面进行尾部插入的时候需要考虑链表为空的情况,那头部插入需不需要单独进行这个临界条件的处理呢?
图解:
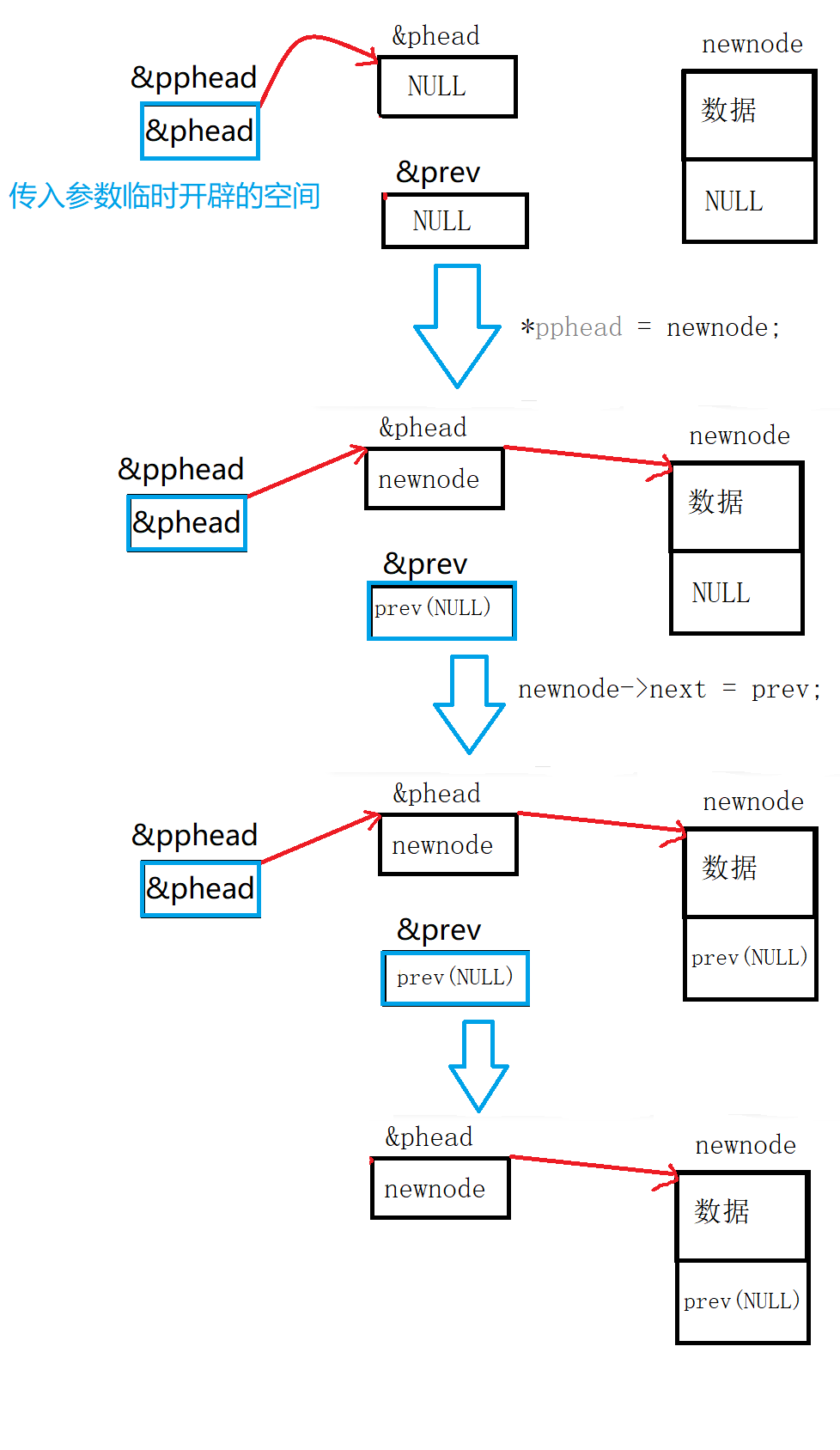
我们可以发现最后结点的指针域会指向空,所以不需要考虑这个临界情况。
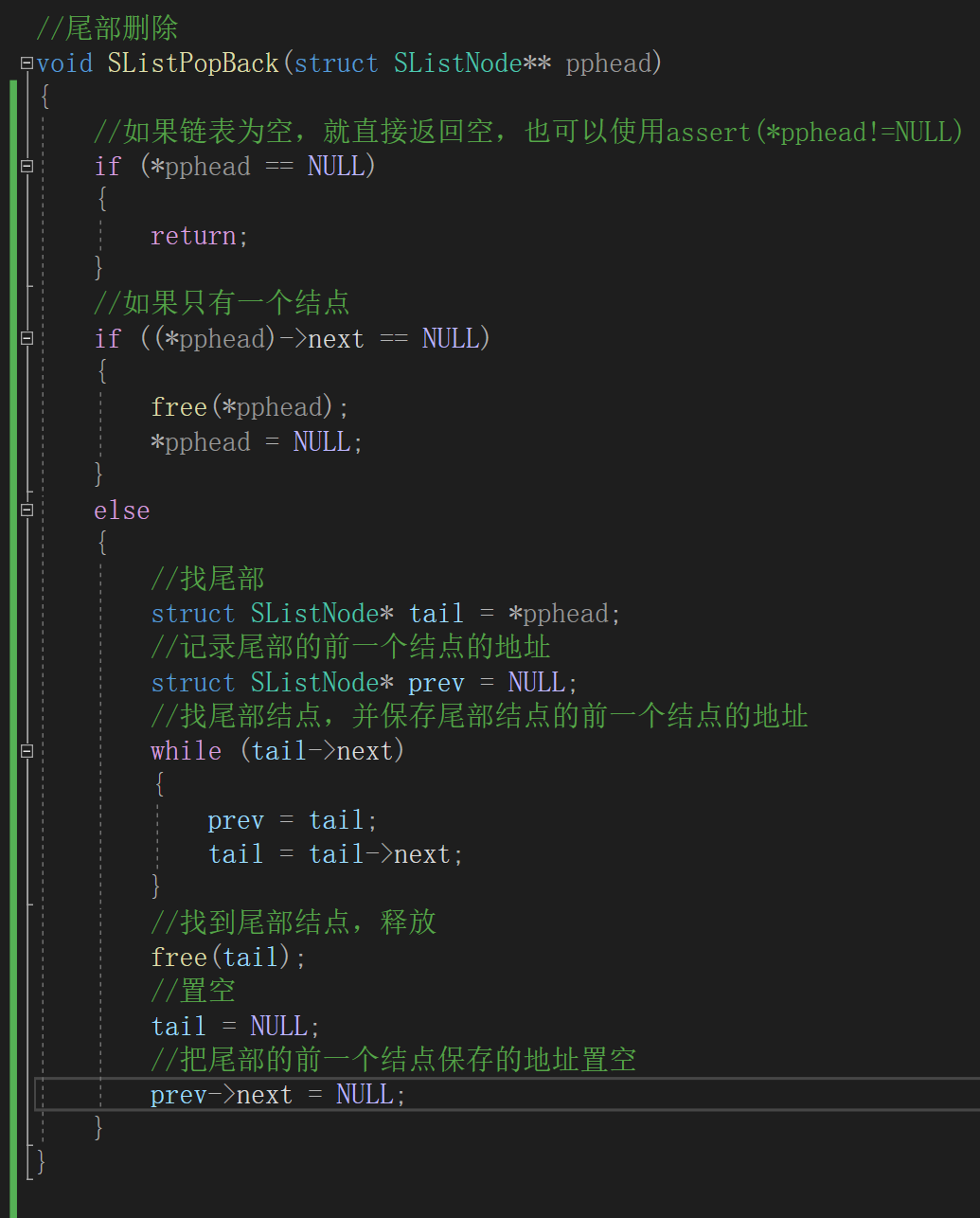
(6)尾部删除
进行数据插入,我们
要改变实参的值
(即改变指针的指向),
必须传入头指针的地址
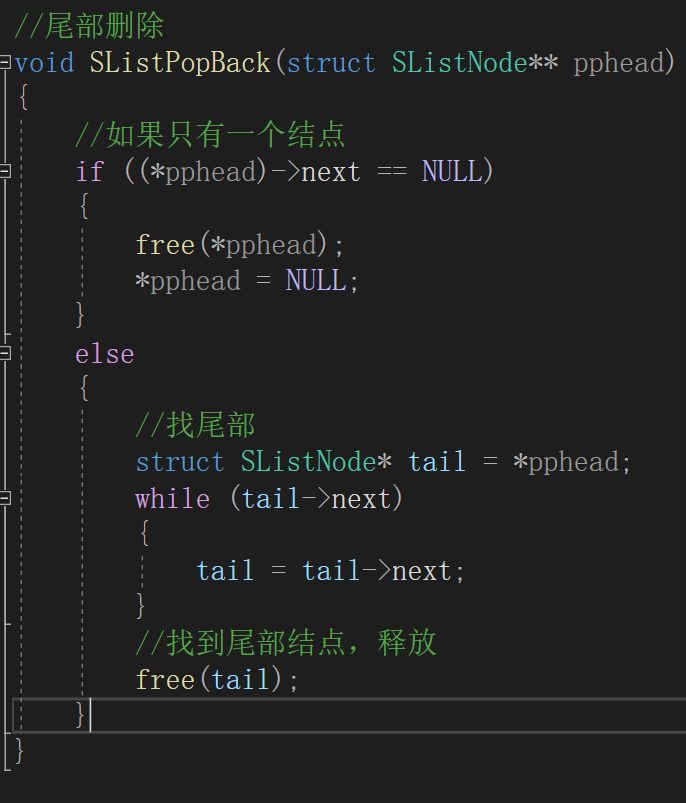
(二级指针)。思路:和尾部插入一样我们需要
使用一个tail指针找到尾部结点
(方法与前面一致),然后
释放这个结点
。我们看代码和运行结果:
我们发现程序打印的是随机数,这是为什么呢?
答:因为我们释放最后一个结点的时候
上一个结点的指针域没有指空
,但
空间已经被系统回收了
,此时我们进行指针的引用是非法的,也就是我们常说的
野指针
。
解决方案:我们可以设计一个
指针prev来记录倒数第二个结点
,在释放尾结点后
让倒数第二个结点的指针域指向空
。
但此时程序依然存在不足。
如果链表为空,我们就会对
空指针进行解引用
,所以我们需要单独处理这种情况,这里提供两种解决方案
第一,我们可以直接
返回空
。
第二,我们可以
使用断言让程序直接报错
。
这里使用第一种方法。
代码和测试结果:
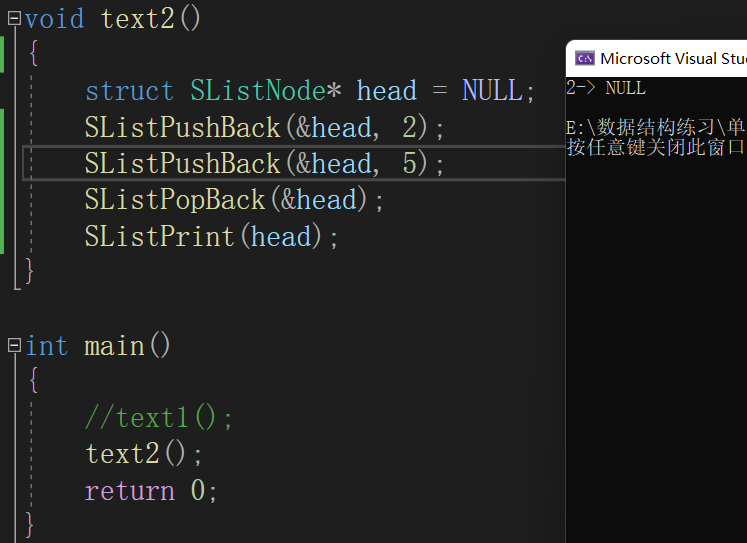
(7)头部删除
进行数据插入,我们
要改变实参的值
(即改变指针的指向),
必须传入头指针的地址
(二级指针)。思路:进行头部删除,可以
将第一个结点释放
,然后让
头指针指向第二个结点
。代码和运行结果:

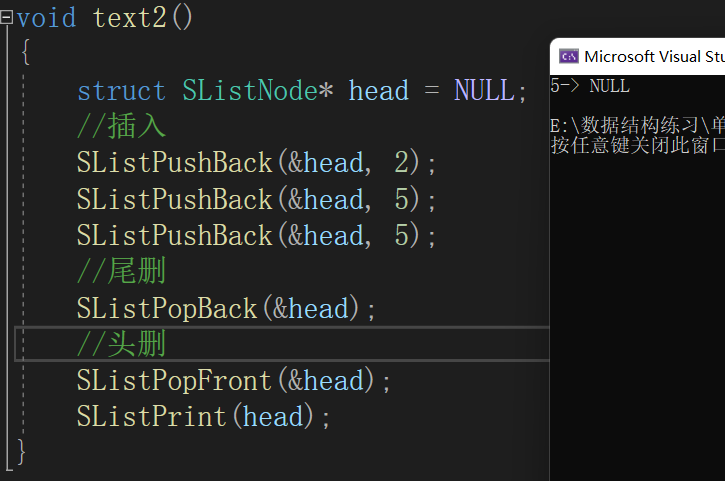
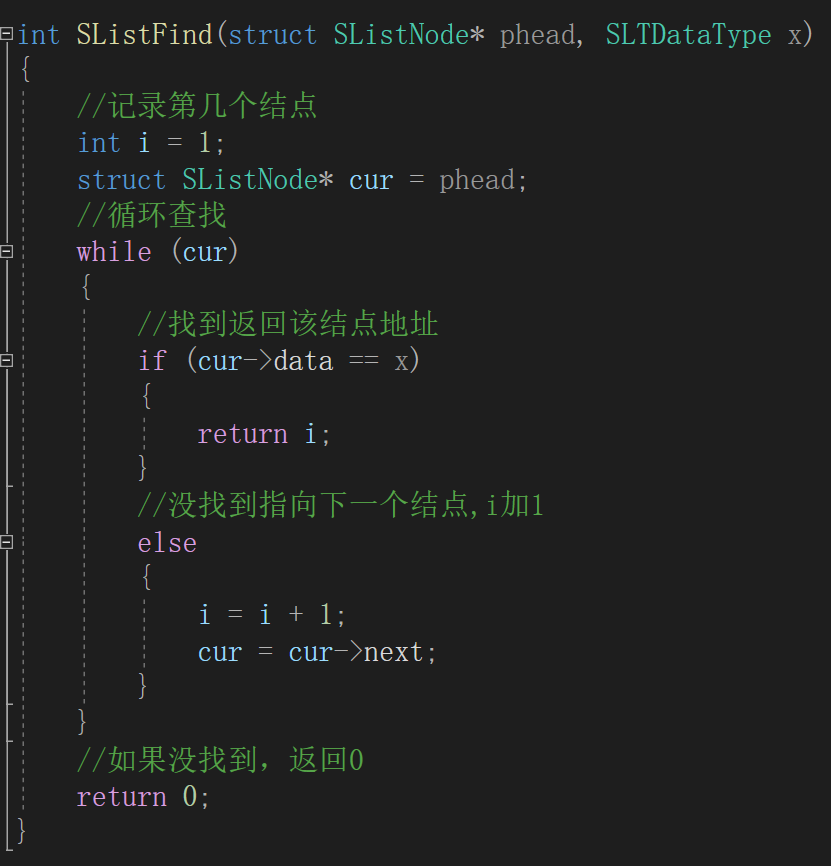
(8)查找
查找有两种实现方式,一种
返回结点地址
,一种返回
数据在第几个结点
。思路:
遍历
整个链表,一直到找到要查找的数据或最后一个结点为止。
如果
没有查找到数据,返回NULL或者0。
第一种(我用的):
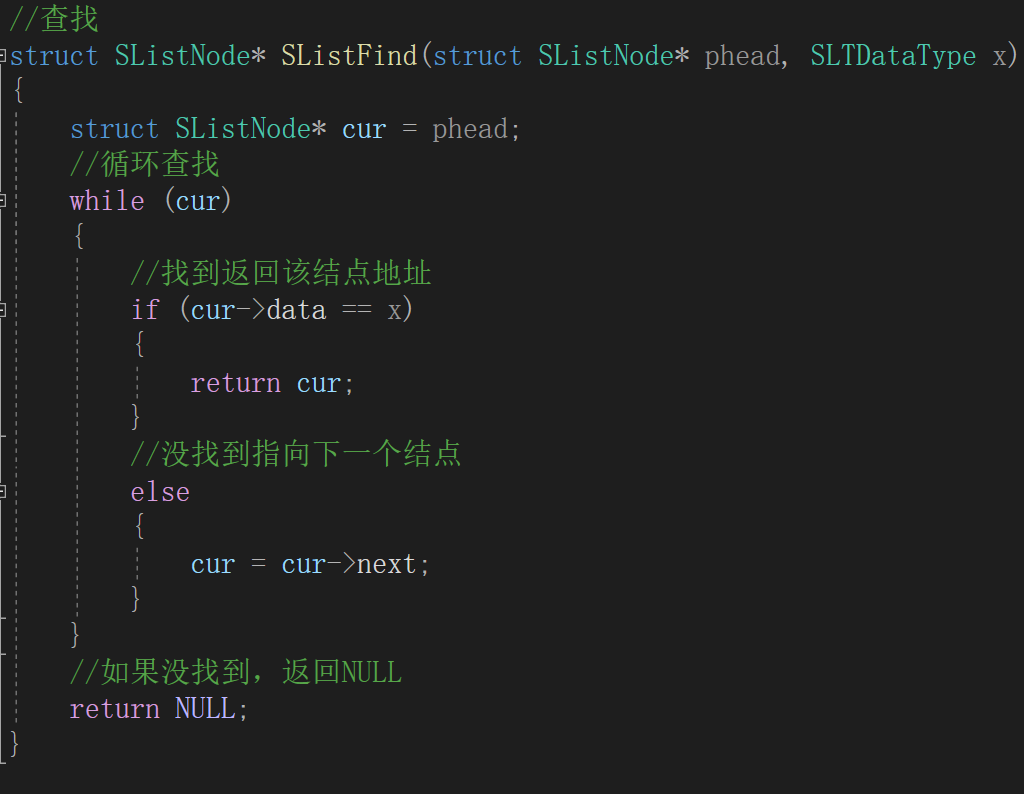
第二种:
上述函数我们只能找到第一个数,
后面相同的找不到
,如果我们需要查找链表中所有该数的位置 ,我们可以
设计一个pos指针并进行循环,循环结束条件为pos为空
,这样就可以实现多次查找,我们看代码。(这个方法只适用于第一种)

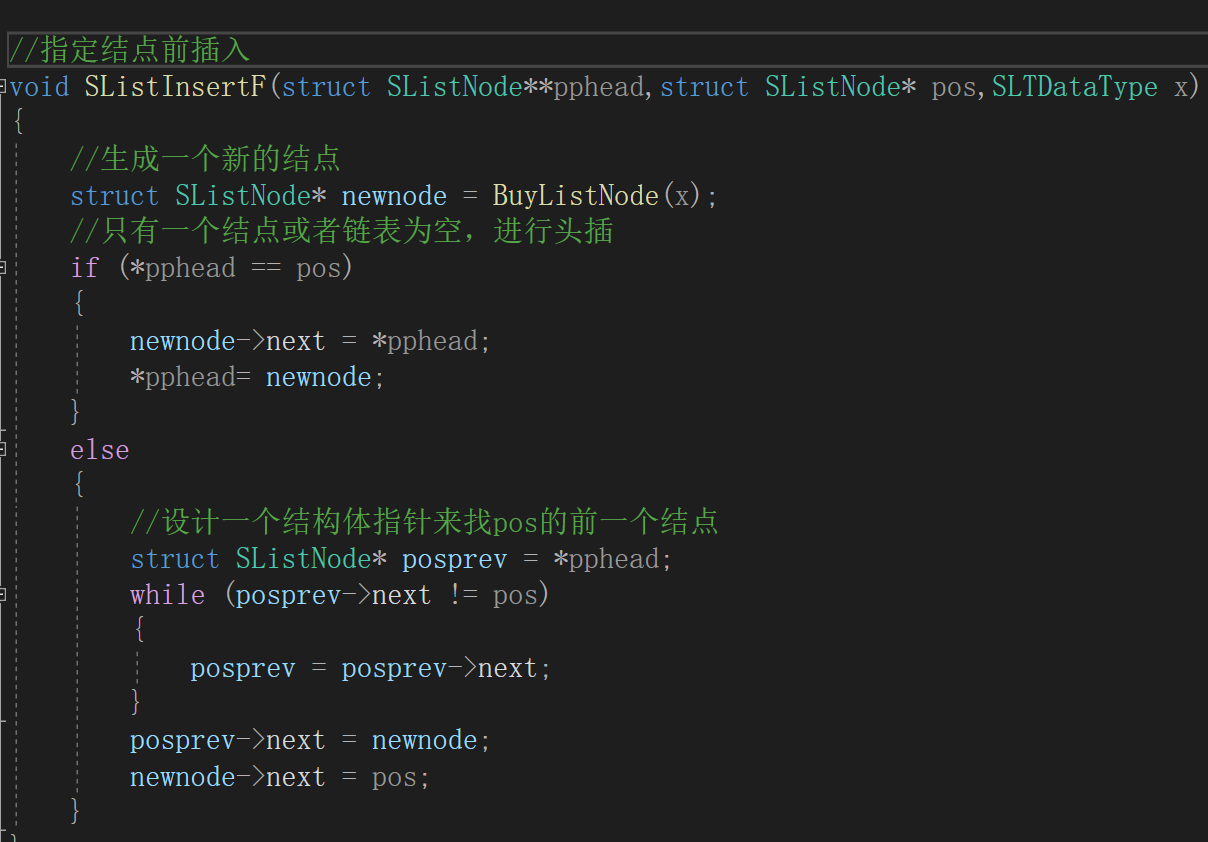
(9)指定位置插入
这里给出两种插入方式,一种是指定在那个结点前插入,一种是指定在那个结点后插入
第一种前插入:
第一种后插入:
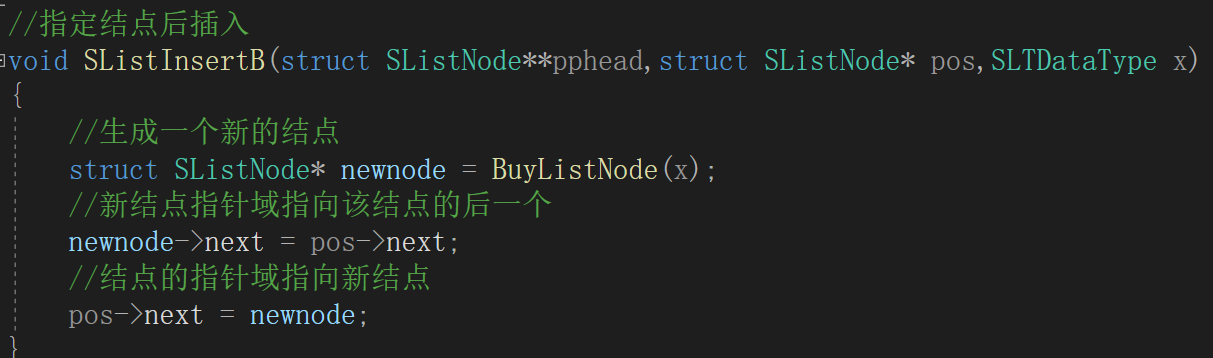
在进行插入前我们需要
找到要插入的那个结点的前面(后面)
,可以先使用查找函数找到位置,在进行插入。
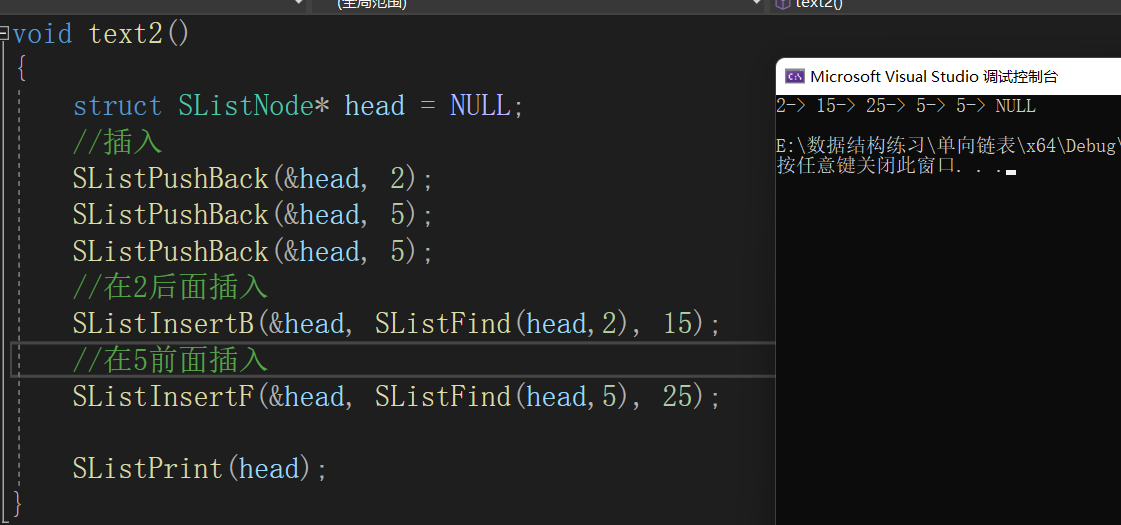
测试结果:
(10)指定删除
思路:删除的思路
同尾删类似
,我们需要找到待删除的结点并保存待删除的结点的指针域。代码:
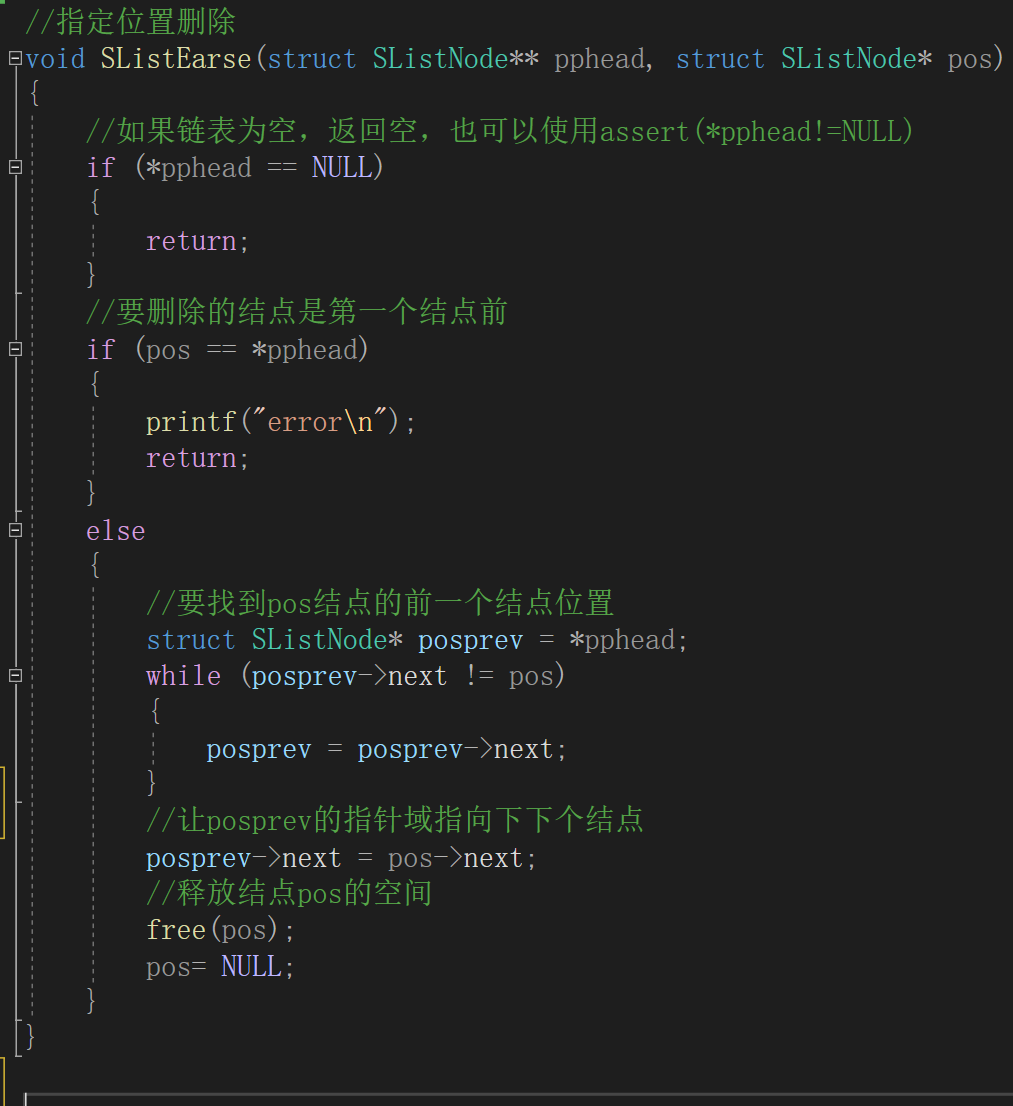
在进行删除前我们需要
找到要删除的那个结点的前一个结点(目的是让前面的结点指针域指向下下个结点)
,可以先使用查找函数找到位置,再进行删除。
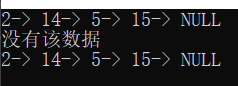
测试:
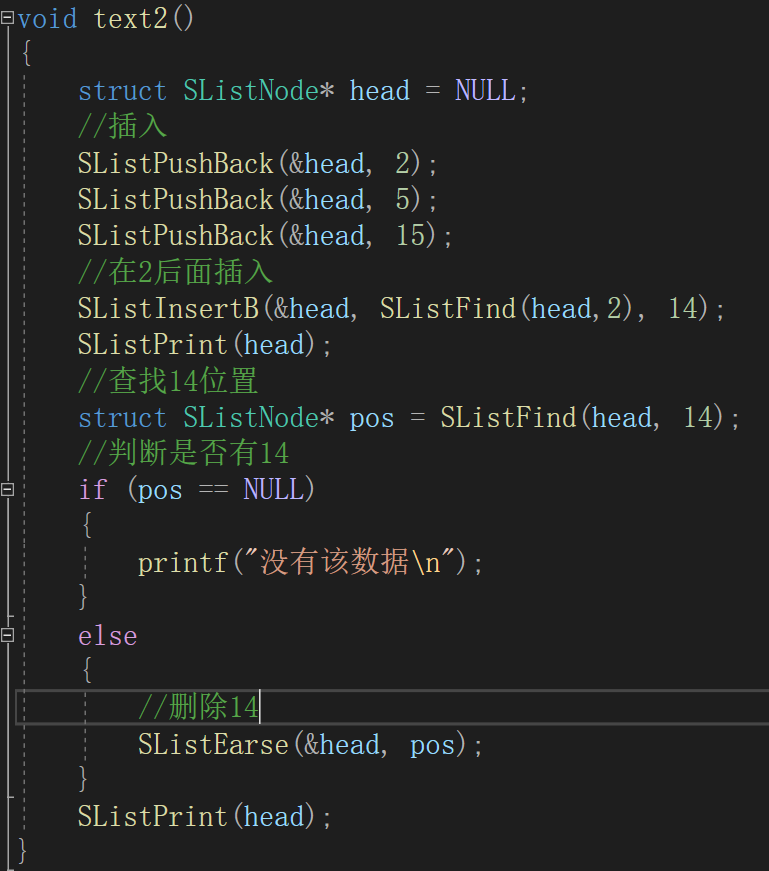
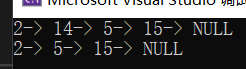
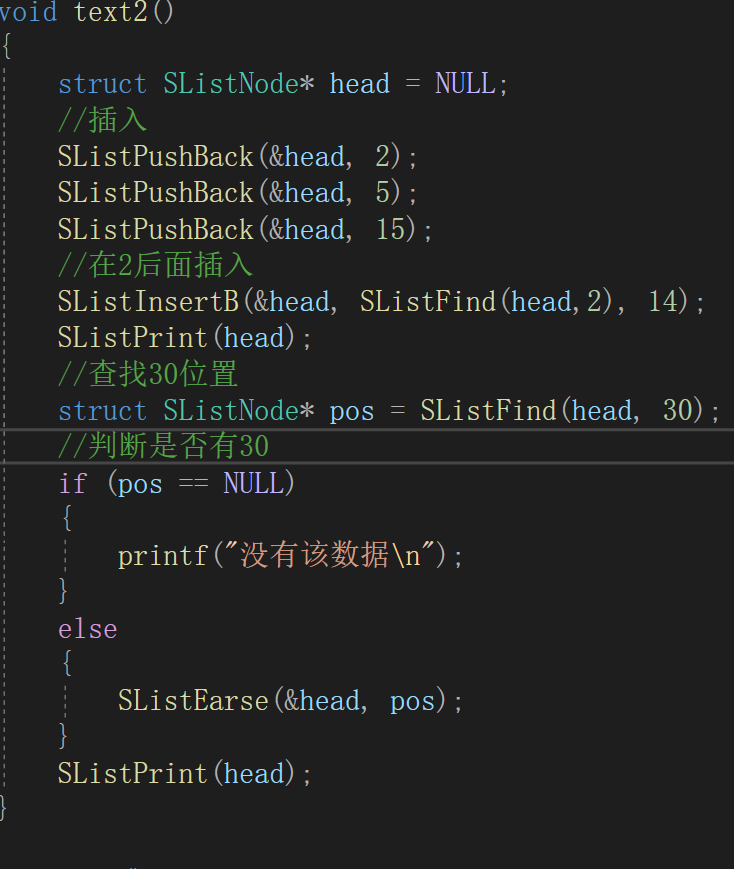
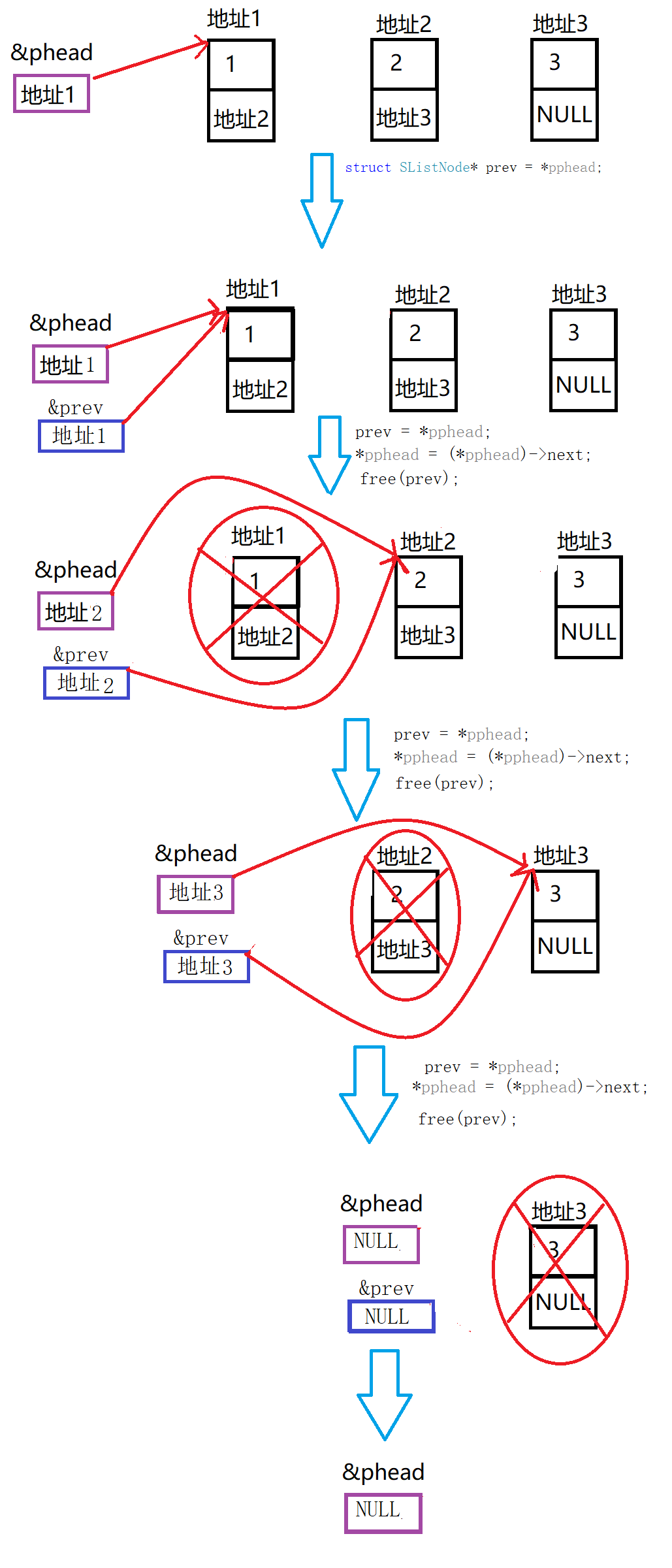
(11)清空链表
思路:从第一个结点开始,设计一个pos指针,每次循环把头指针指向的结点地址赋给pos,让头指针指向下一个结点地址,调用free()释放pos指向的结点。
图解(以三个结点为例子):
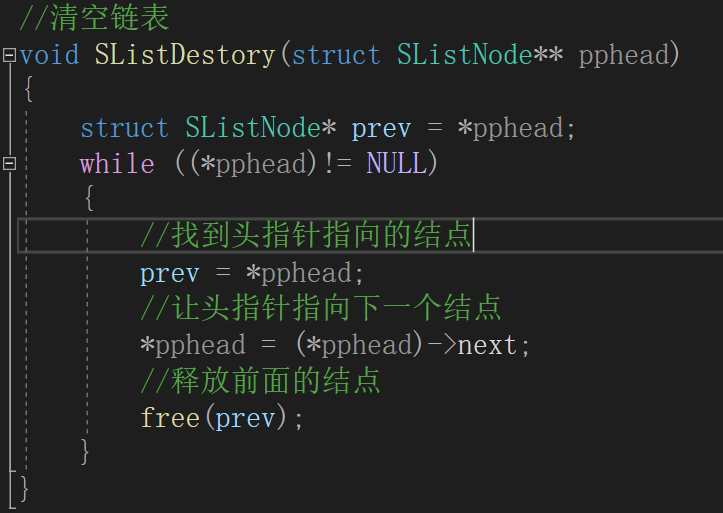
代码和测试结果:
(12)最终代码
SingleLinkedList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
//#include <assert.h> 要使用断言的话注意包含头文件
//结构体数据类型重定义,方便我们更改要存储的元素类型
typedef int SLTDataType;
struct SListNode
{
SLTDataType data; //要存储的数据(数据域)
struct SListNode* next; //用来存储下一个结构体的地址(指针域)
};
//打印
void SListPrint(struct SListNode* phead);
//创建一个新节点
struct SListNode* BuyListNode(SLTDataType x);
//尾部插入
void SListPushBack(struct SListNode** pphead, SLTDataType x);
//头部插入
void SListPushFront(struct SListNode** pphead, SLTDataType x);
//尾部删除
void SListPopBack(struct SListNode** pphead);
//头部删除
void SListPopFront(struct SListNode** pphead);
//查找,返回对应结点地址
//int SListFind(struct SListNode* phead, SLTDataType x);
struct SListNode* SListFind(struct SListNode* phead, SLTDataType x);
//指定插入(还有一种按输入位置来插入)(在前面插入)
void SListInsertF(struct SListNode** pphead, struct SListNode* pos, SLTDataType x);
void SListInsertB(struct SListNode** pphead, struct SListNode* pos, SLTDataType x);
//指定删除
void SListEarse(struct SListNode** pphead, struct SListNode* pos);
//销毁链表
void SListDestory(struct SListNode** pphead);
SingleLinkedList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "SingleLinkedList.h"
//打印链表
void SListPrint(struct SListNode* phead)
{
//一直循环,直到找到最后一个结点
while (phead)
{
printf("%d-> ", phead->data); //依次打印结点存储的数据
phead = phead->next; //让phead指向下一个结点
}
printf("NULL\n");
}
//生成新节点
struct SListNode* BuyListNode(SLTDataType x)
{
//调用maoolc()函数生成一个结点
struct SListNode* newNode = (struct SListNode*)malloc(sizeof(struct SListNode));
//如果申请失败,打印错误并结束程序
if (newNode == NULL)
{
printf("malloc error\n");
exit(-1);
}
//将要插入的数据赋给新结点
newNode->data = x;
//新节点的next置空
newNode->next = NULL;
//返回生成的结点的地址
return newNode;
}
//尾部插入
void SListPushBack(struct SListNode** pphead, SLTDataType x)
{
//生成一个新的结点
struct SListNode* newnode = BuyListNode(x);
//如果链表为空,直接把新结点地址赋给*pphead
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//设置一个指针tail用来找到尾部结点
struct SListNode* tail = *pphead;
//不断循环,直到找到尾部结点
while (tail->next)
{
tail = tail->next;//指向下一个结点
}
//让原本置空的指针指向新生成的结点
tail->next = newnode;
}
}
//头部插入
void SListPushFront(struct SListNode** pphead, SLTDataType x)
{
//生成新结点
struct SListNode* newnode = BuyListNode(x);
//保存原来第一个结点的地址
struct SListNode* prev = *pphead;
//让头指向新结点
*pphead = newnode;
newnode->next = prev;
}
//尾部删除
void SListPopBack(struct SListNode** pphead)
{
//如果链表为空,就直接返回空,也可以使用assert(*pphead!=NULL)
if (*pphead == NULL)
{
return;
}
//如果只有一个结点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
//找尾部
struct SListNode* tail = *pphead;
//记录尾部的前一个结点的地址
struct SListNode* prev = NULL;
//找尾部结点,并保存尾部结点的前一个结点的地址
while (tail->next)
{
prev = tail;
tail = tail->next;
}
//找到尾部结点,释放
free(tail);
//置空
tail = NULL;
//把尾部的前一个结点保存的地址置空
prev->next = NULL;
}
}
//头部删除
void SListPopFront(struct SListNode** pphead)
{
//如果链表为空,返回空,也可以使用assert(*pphead!=NULL)
if (*pphead == NULL)
{
return;
}
else
{
//找到下一个结点的地址
struct SListNode* prev = (*pphead)->next;
//释放第一个结点
free(*pphead);
//头指针指向第二个结点
*pphead = prev;
}
}
//查找
struct SListNode* SListFind(struct SListNode* phead, SLTDataType x)
{
struct SListNode* cur = phead;
//循环查找
while (cur)
{
//找到返回该结点地址
if (cur->data == x)
{
return cur;
}
//没找到指向下一个结点
else
{
cur = cur->next;
}
}
//如果没找到,返回NULL
return NULL;
}
//第二种
//int SListFind(struct SListNode* phead, SLTDataType x)
//{
// //记录第几个结点
// int i = 1;
// struct SListNode* cur = phead;
// //循环查找
// while (cur)
// {
// //找到返回该结点地址
// if (cur->data == x)
// {
// return i;
// }
// //没找到指向下一个结点,i加1
// else
// {
// i = i + 1;
// cur = cur->next;
// }
// }
// //如果没找到,返回0
// return 0;
//}
//指定结点前插入
void SListInsertF(struct SListNode**pphead,struct SListNode* pos,SLTDataType x)
{
//生成一个新的结点
struct SListNode* newnode = BuyListNode(x);
//只有一个结点或者链表为空,进行头插
if (*pphead == pos)
{
newnode->next = *pphead;
*pphead= newnode;
}
else
{
//设计一个结构体指针来找pos的前一个结点
struct SListNode* posprev = *pphead;
while (posprev->next != pos)
{
posprev = posprev->next;
}
posprev->next = newnode;
newnode->next = pos;
}
}
//指定结点后插入
void SListInsertB(struct SListNode**pphead,struct SListNode* pos,SLTDataType x)
{
//生成一个新的结点
struct SListNode* newnode = BuyListNode(x);
//新结点指针域指向该结点的后一个
newnode->next = pos->next;
//结点的指针域指向新结点
pos->next = newnode;
}
//指定位置删除
void SListEarse(struct SListNode** pphead, struct SListNode* pos)
{
//如果链表为空,返回空,也可以使用assert(*pphead!=NULL)
if (*pphead == NULL)
{
return;
}
//要删除的结点是第一个结点
if (pos == *pphead)
{
//找到下一个结点的地址
struct SListNode* prev = (*pphead)->next;
//释放第一个结点
free(*pphead);
//头指针指向第二个结点
*pphead= prev;
}
else
{
//要找到pos结点的前一个结点位置
struct SListNode* posprev = *pphead;
while (posprev->next != pos)
{
posprev = posprev->next;
}
//让posprev的指针域指向下下个结点
posprev->next = pos->next;
//释放结点pos的空间
free(pos);
pos= NULL;
}
}
//清空链表
void SListDestory(struct SListNode** pphead)
{
struct SListNode* prev = *pphead;
while ((*pphead)!= NULL)
{
//找到头指针指向的结点
prev = *pphead;
//让头指针指向下一个结点
*pphead = (*pphead)->next;
//释放前面的结点
free(prev);
}
}text.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "SingleLinkedList.h"
void text1()
{
struct SListNode* head = NULL;
SListPushFront(&head, 5);
SListPushFront(&head, 50);
SListPushFront(&head, 50);
SListPushFront(&head, 5);
struct SListNode* pos = SListFind(head, 50);
int i = 1;
//查找多个相同的值
while (pos)
{
printf("第%d个pos节点:%p->%d\n", i++, pos, pos->data);
//pos指向目标结点的下一个结点
pos = SListFind(pos->next, 50);
}
SListPrint(head);
//修改
pos = SListFind(head, 50);
if (pos)
{
pos->data = 30;
}
SListPrint(head);
}
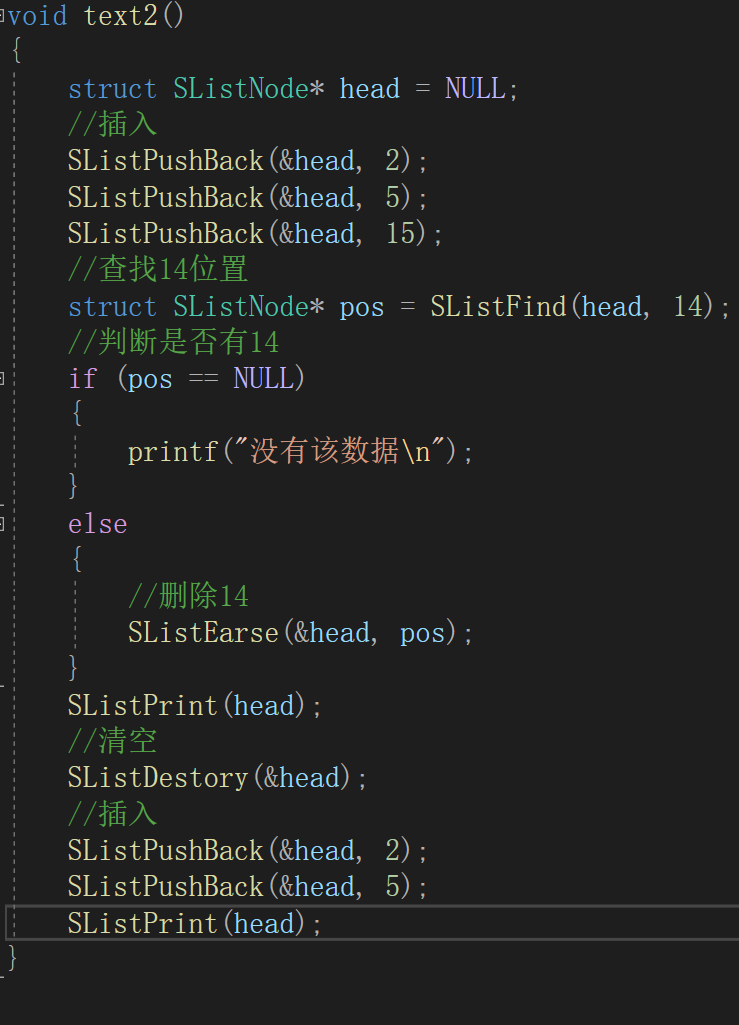
void text2()
{
struct SListNode* head = NULL;
//插入
SListPushBack(&head, 2);
SListPushBack(&head, 5);
SListPushBack(&head, 15);
//查找14位置
struct SListNode* pos = SListFind(head, 14);
//判断是否有14
if (pos == NULL)
{
printf("没有该数据\n");
}
else
{
//删除14
SListEarse(&head, pos);
}
SListPrint(head);
//清空
SListDestory(&head);
//插入
SListPushBack(&head, 2);
SListPushBack(&head, 5);
SListPrint(head);
}
int main()
{
/*text1();*/
text2();
return 0;
}
五:小结
相较于顺序表,
链表能够更好的利用零散的空间
,并且插入数据不需要大量移动数据,但是单链表在
物理层上不是连续存储的,我们只能前找后却无法后找前
,而且一旦
指针域的数据丢失我们就没法找到后续结点
,后续的双向链表可以很好的解决这个问题。
顺序表讲解链接:
http://t.csdn.cn/V96aI