HDFS概述
1.HDFS是什么
-
Hadoop Distributed File System
:
分步式文件系统
-
源自于
Google的GFS论文
,发表于2003年10月,HDFS是GFS克隆版 -
HDFS是Hadoop体系中
数据存储管理的基础
-
通过
流式数据访问
,提供
高吞吐量
应用程序数据访问功能,适合带有大型数据集的应用程序 -
提供一次写入多次读取的机制,数据以
块
的形式,同时分布在集群不同物理机器上 -
高度容错性的系统
,能
检测和应对
硬件故障,用于在
低成本的通用硬件上运行
2.Hadoop 2重要的新功能
-
高可用性HA
消除Hadoop 1中存在的单点故障**,其中NameNode故障将导致整个集群中断
HDFS的高可用性提供自动故障转移功能**,备用节点自动从失败的主NameNode接管工作
-
Federation
允许集群中出现多个NameNode,各个NN间相互独立且不需要互相协调,各自分工,管理自己的区域;
DataNode 被用作通用的数据块存储设备;每个DataNode要向集群中所有NameNode注册,并发送心跳报告
3.HDFS客户端
- Web client(http://node1:50070)
- Java API->Idea插件(big data tool)
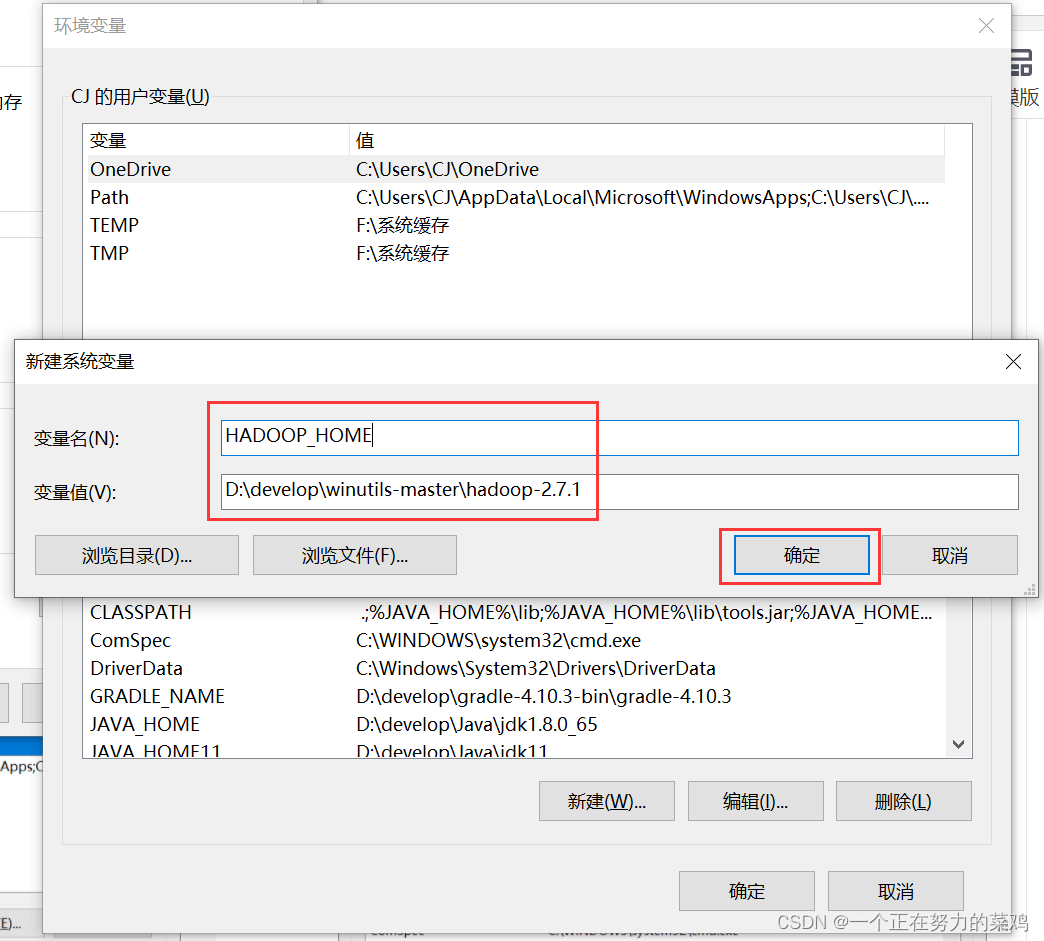
4.HDFS安装
-
官网学安装
- 单机安装
- 伪分布式安装
-
完全分步式安装
时间同步->安装JDK->上传解压->免密钥设置->修改配置文件->同步到其他节点->格式化NN->启动
HDFS组成
1.主从架构图解
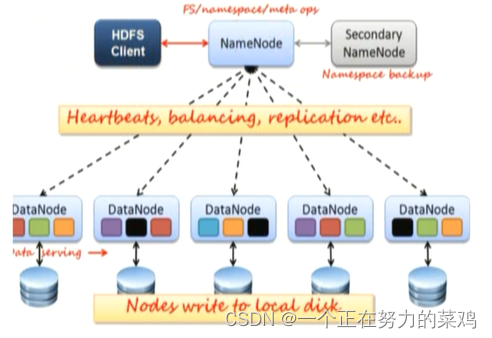
2.NameNode
-
作用是
接收客户端读写,存元数据信息
- 元数据信息包括文件谁所有,权限,用户对文件的操作信息(edit logs),文件被分成几块(Block ID),块存在哪些DataNode
- NameNode如何将数据保存到磁盘?元数据主要保存在fsimage和edit logs
首先了解两个文件
fsimage:NameNode启动时对整个文件系统的快照
edit logs:NameNode启动后对整个文件系统的操作日志
接下来讲讲两个文件如何配合工作
fsimage保存的是最开始时的快照,而edit logs记录的是启动后的每一步操作命令,所以fsimage+edit logs就是最终操作结果
只有NameNodde重启时,edit logs才会合并到fsimage中,从而得到一个最新快照
但是在产品集群中NameNode很少重启,这意味着随着NameNode运行时间的加长,edit logs文件越来越大
因此我们需要一个管理机制来减小edit logs文件大小和得到一个新的fsimage文件,这与windows的恢复机制相似
此时引入SecondNameNode
-
NameNode
启动后将元数据加载到内存
,磁盘文件名为fsimage,块的位置信息不会保存到fsimage,而由DataNode启动时主动上报给NameNode,edit记录操作日志 -
一个集群中有且只有一台NameNode处于active状态
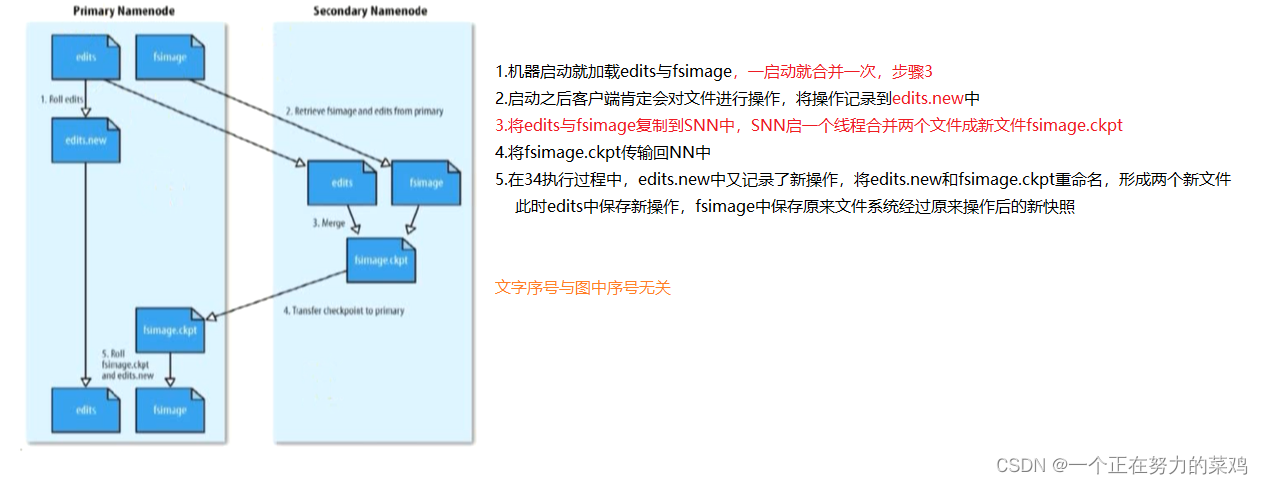
3.SecondNameNode
-
SecondNameNode是NameNode的备份,但
主要任务是合并NameNode的fsimage和edit logs,减少NameNode启动时间
-
SNN的合并时机可以通过
配置文件设置的时间间隔
(fs.checkpoint.period.period,默认1h)或
配置文件设置edit大小
(fs.checkpoint.size),edit超过该大小则需合并 -
合并流程
4.DataNode
-
DataNode用来
真正存数据,数据按块存
,当DN启动会向NN汇报块信息 -
DataNode之间还保存数据的副本,实现数据节点的互相拷贝
-
DN与NN间需要
维护心跳
,3s一次,当10min没收到心跳,则NN认为DN掉线,会复制该DN上的块到其他DN上 -
NN对DN还有
重平衡机制
,因为随着时间推移,DN上存储的数据总数不同,磁盘空间大小不同,可以调用命令整理磁盘,若不重平衡会导致系统由响应最慢的节点决定
HDFS组成详解
1.块Block(数据存储单元)
-
文件被切分成固定大小的数据块
-
查找数据块比较方便
,因为在磁盘上找文件时由指针移动来寻找,所以移动块比字节要快 - 数据块大小默认为128MB(可配置)
-
若文件大小不到128MB可以单独存一个块,但过多小文件每次都单独存一个块,而块存于NN,NN存于内存,内存有限,从而集群中的存储量有限,所以存数据是需要将小文件合并成大文件,尽量填满一个数据快再存
;文件大小大于128MB,则会切分 -
将切分后的数据块存储到不同节点上
,默认情况每个Block都有
三个备份
,
副本采用负载均衡,随机存放策略
,
防止数据倾斜
,即数据都存放在一个节点上,发生数据倾斜,可以使用
重平衡策略
-
当DN挂掉后自动生成该节点的副本,以保证备份数为3,当该节点恢复后不会删除多余副本
,多余副本就会导致节点数据量不同,所以需要上面提到的
重平衡
-
块大小和副本数通过客户端上传文件时设定,
文件上传成功后副本数可以变更,但块大小不行
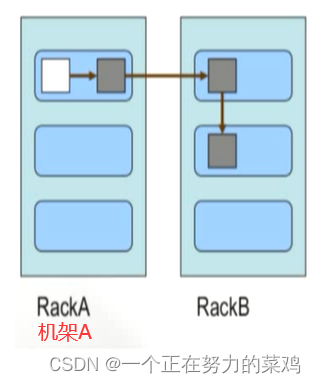
2.块副本存放策略
-
第一个副本放在
上传文件的DN
,若是集群外提交则随机挑选一台磁盘不太满的,CPU不太忙的节点 -
第二个副本放在
不同于第一个副本的机架节点
-
第三个副本放在与
第二个副本相同机架节点
-
更多副本则
随机节点
HDFS权限安全
1.HDFS文件权限
-
与Linux文件权限类似有
读写执行(rwx)权限
,但x对于文件忽略,对于文件夹表示是否允许访问其内容 - 若Linux用户cj使用Hadoop命令创建文件,那么该文件在HDFS拥有者就是cj
-
HDFS文件的目的是
阻止好人做错事,而不是阻止坏人做坏事
,A上传的文件B也看得到,与Linux不同
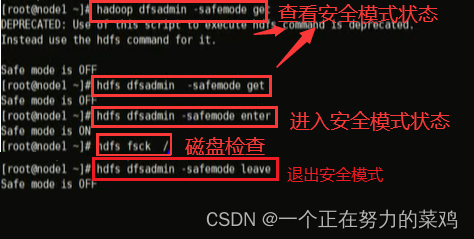
2.安全模式
- NN启动时,将fsimage加载到内存,并执行edit中的各项操作(NN启动时合并两个文件)
- 内存中成功建立文件系统元数据映射后,则创建一个新fsimage和空edit
-
此时NN运行在安全模式,即NN对于客户端来说是只读的
,写删重命名等操作都会失败 - 此阶段NN收集各个DN的报告
- 当数据块副本数量超过最小副本数,会被认为是安全的,在一定比例(可配置)数据块被认为安全后,再经过若干时间,安全模式结束
- 当数据块副本数量未达到最小副本数,会继续复制直到达到
-
系统中数据块的位置不是由NN维护,而是以块列表形式存储在DN
HDFS读写流程
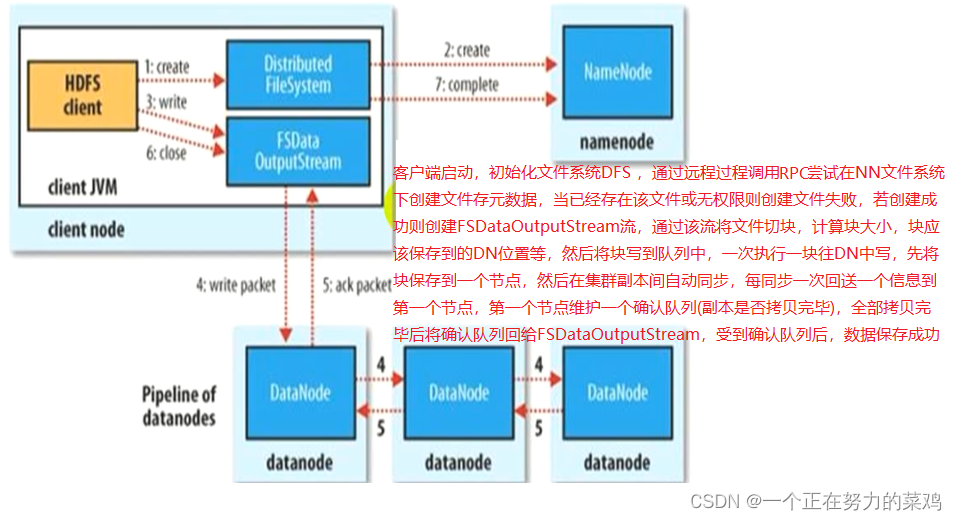
1.HDFS写流程
-
客户端传数据是先传到NN再由NN传到DN,还是直接传到DN?答案都不对,看图
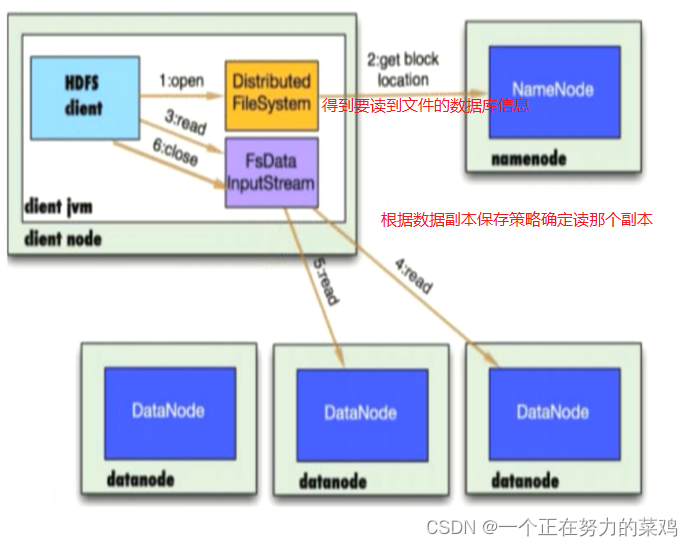
2.HDFS读流程
HDFS操作
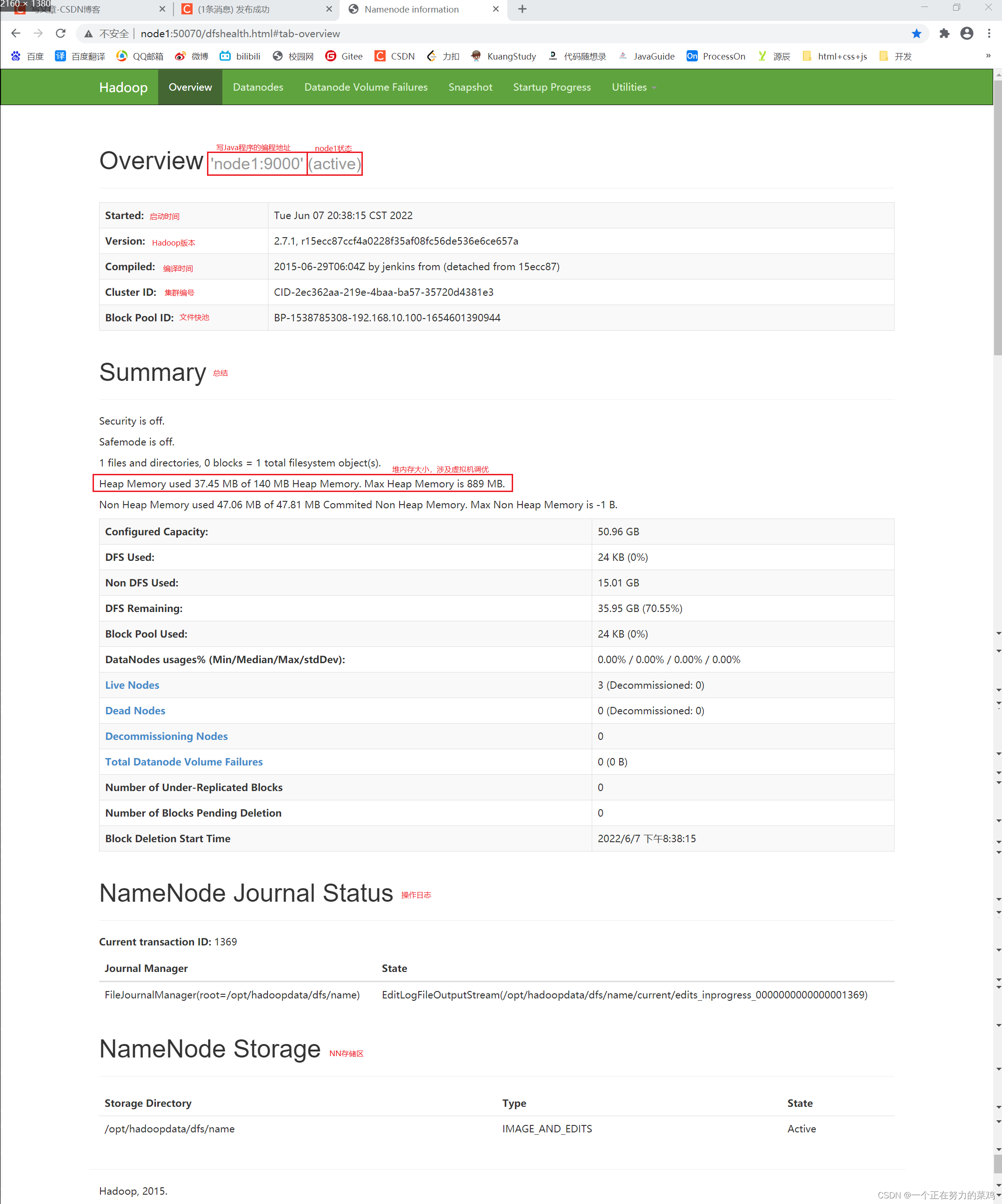
1.利用Web访问
- 访问地址:http://node1:50070
-
Overview
-
Datanodes
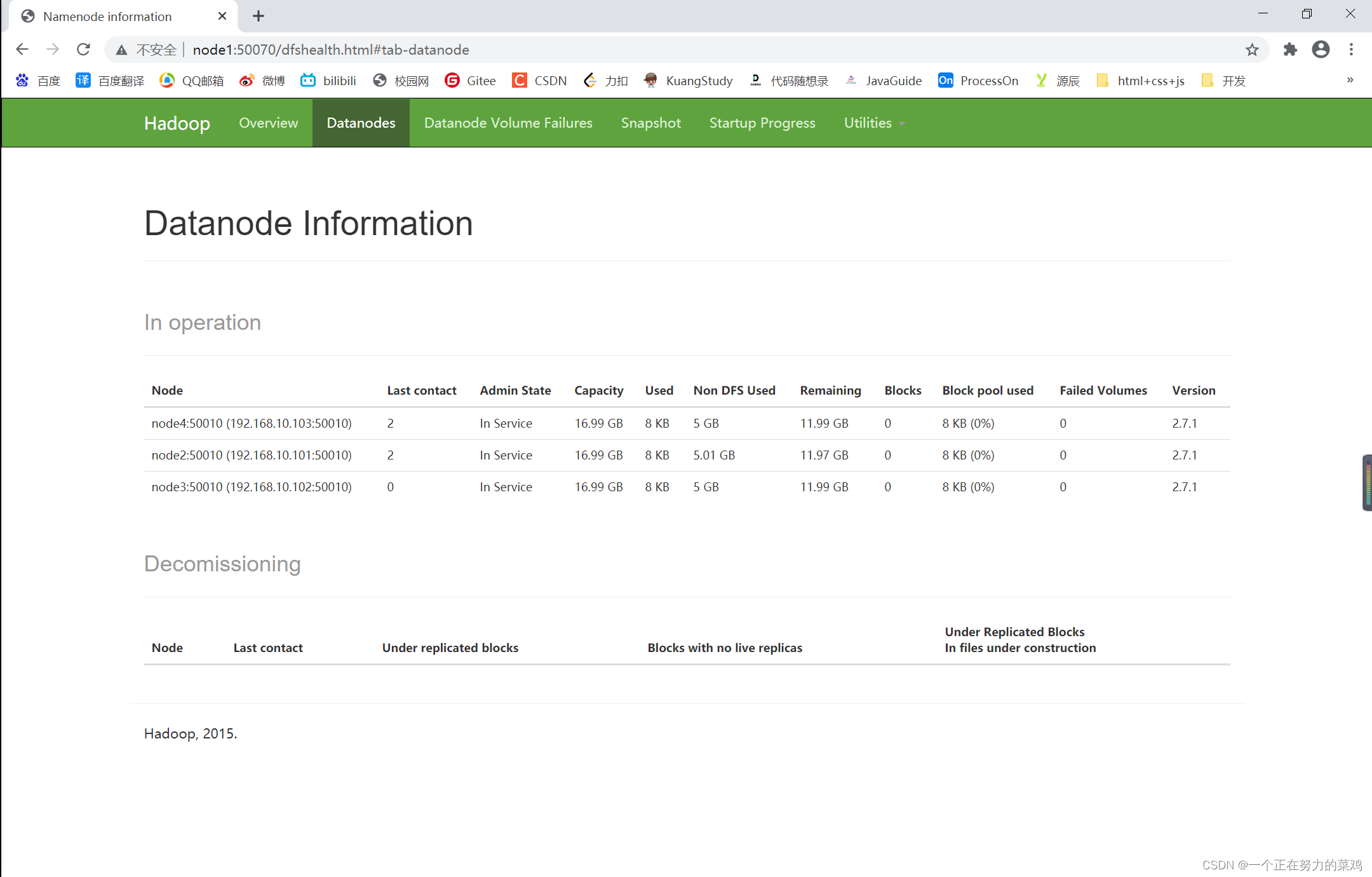
- 相信你可以自己看懂!
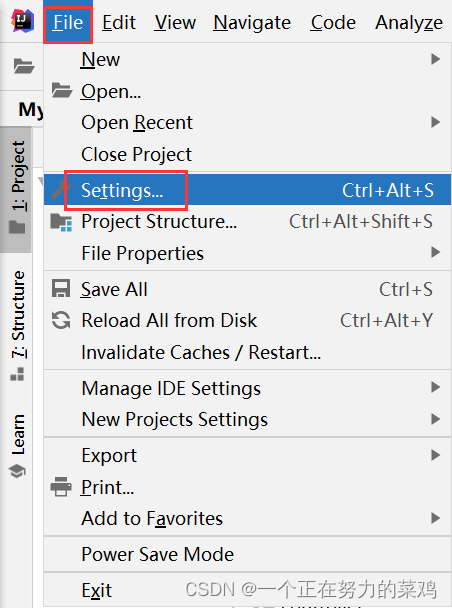
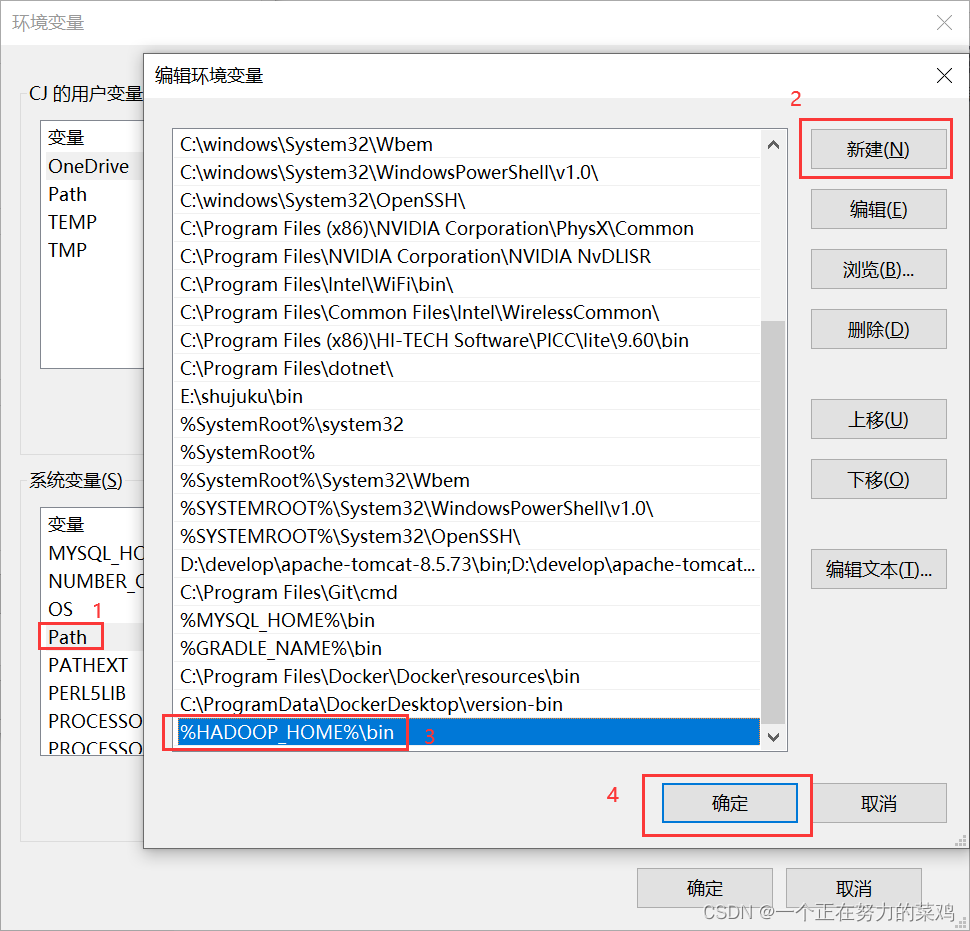
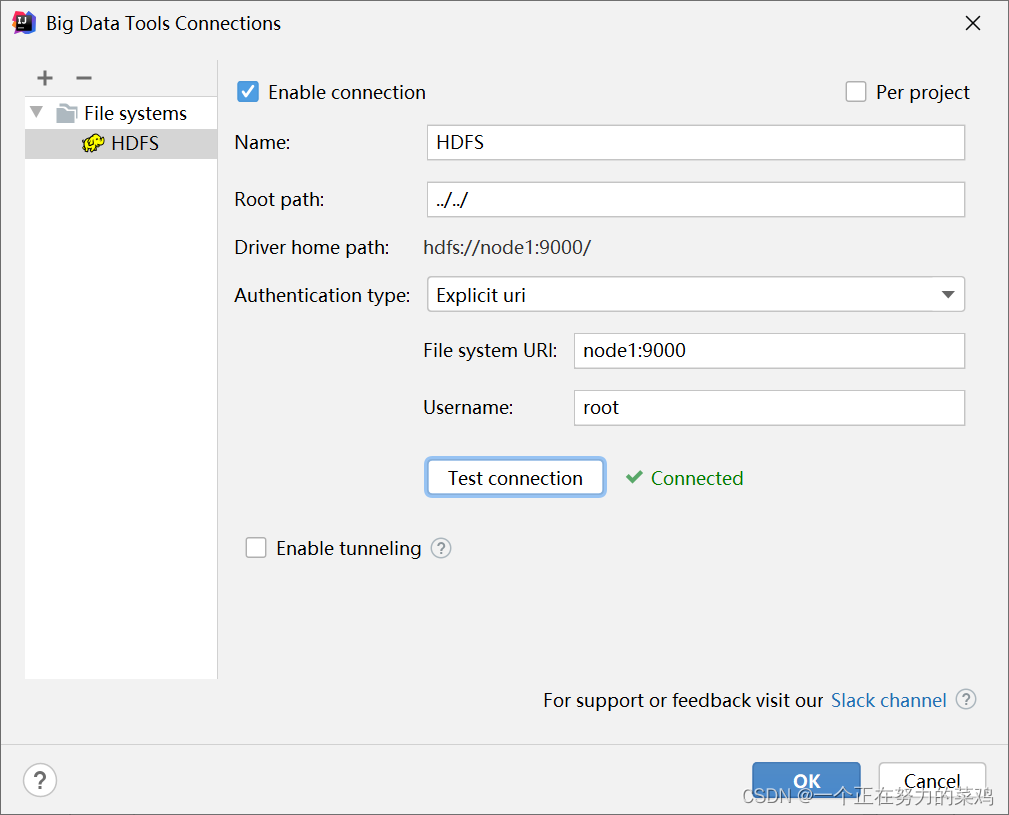
2.IDEA插件Big Data Tools
-
下载插件
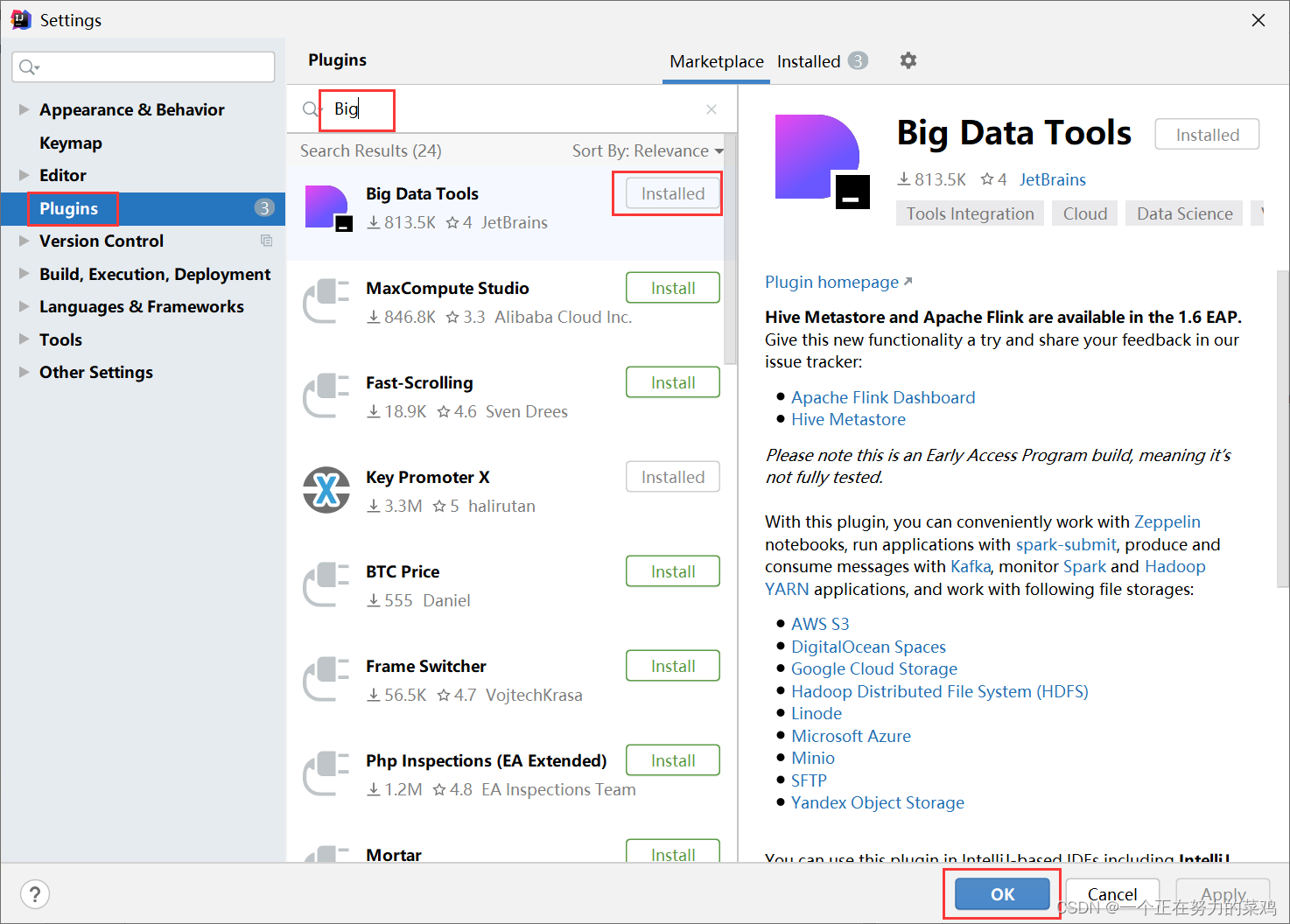
-
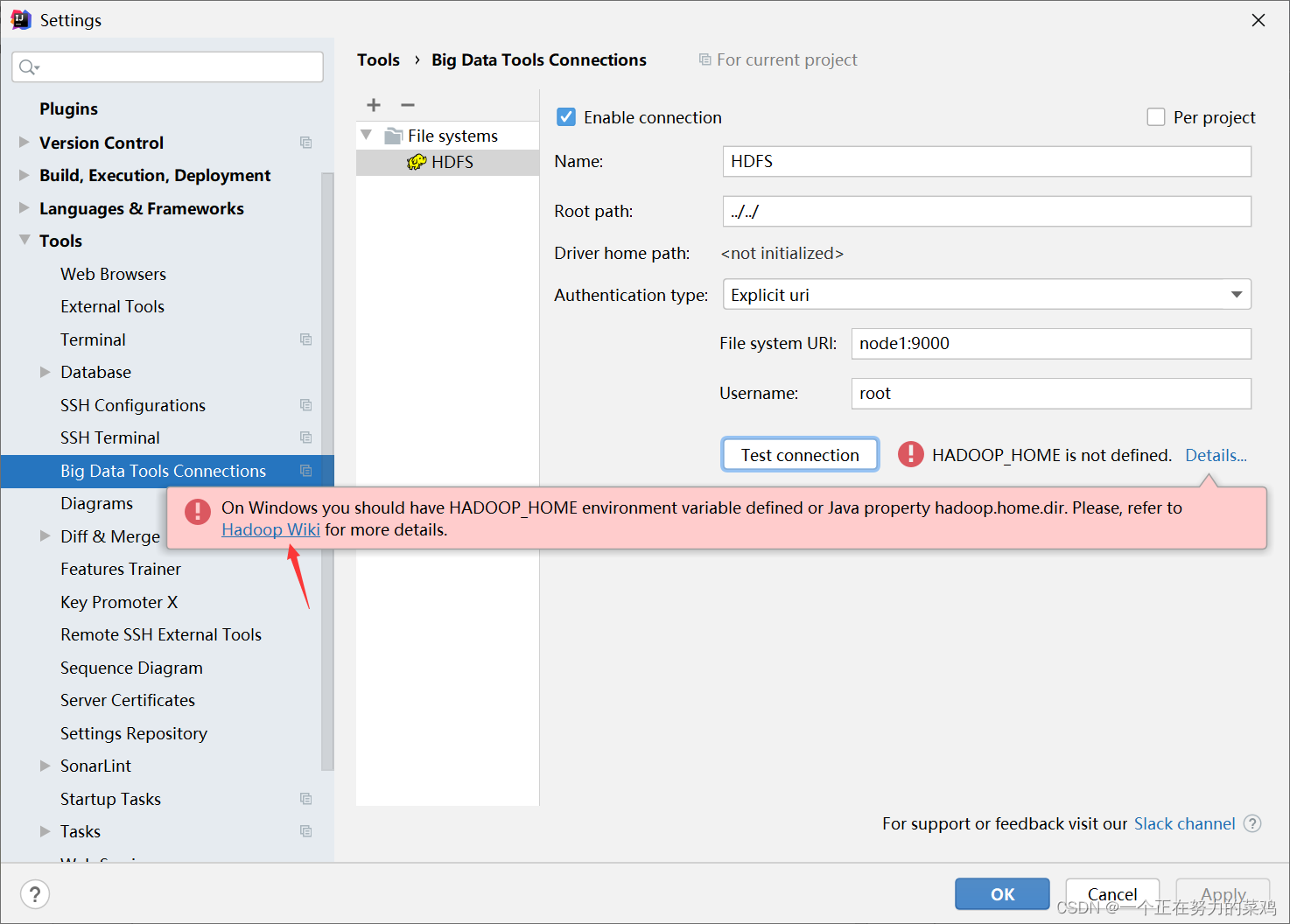
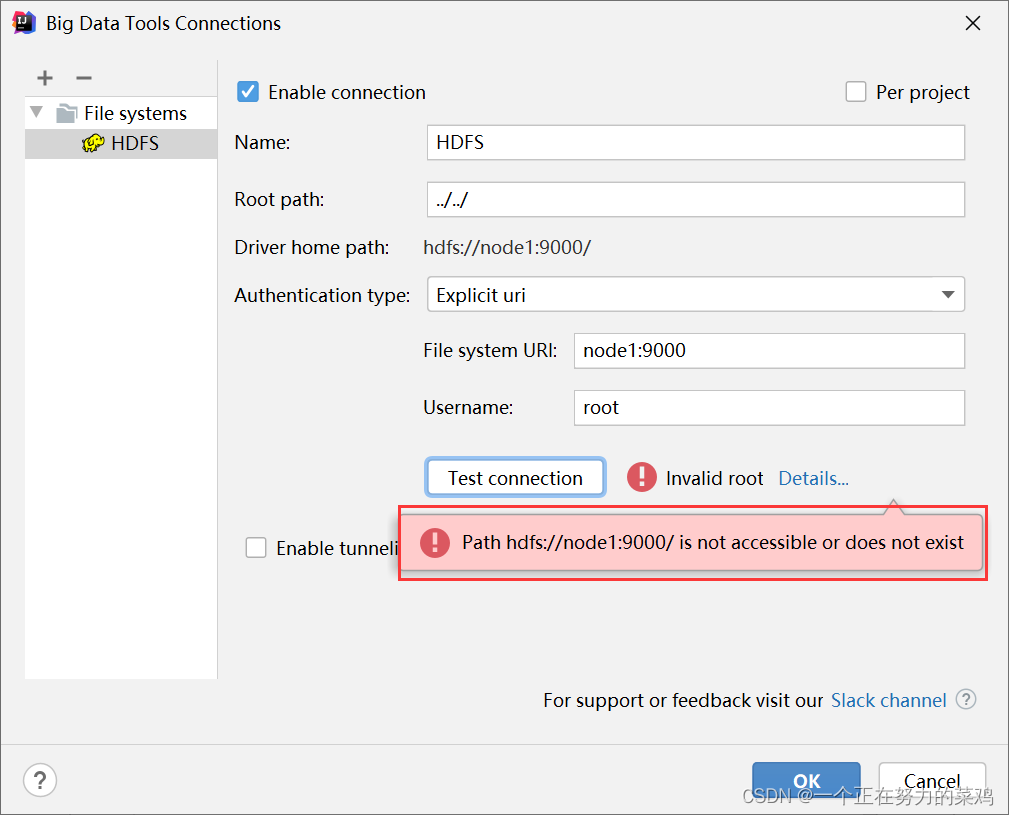
测试连接
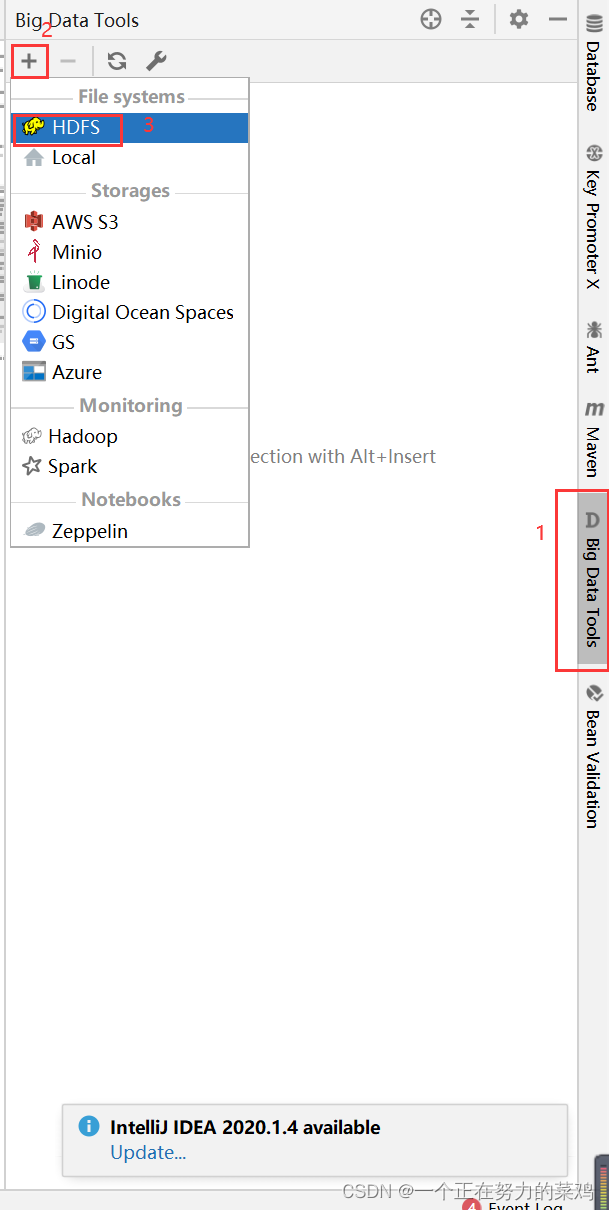
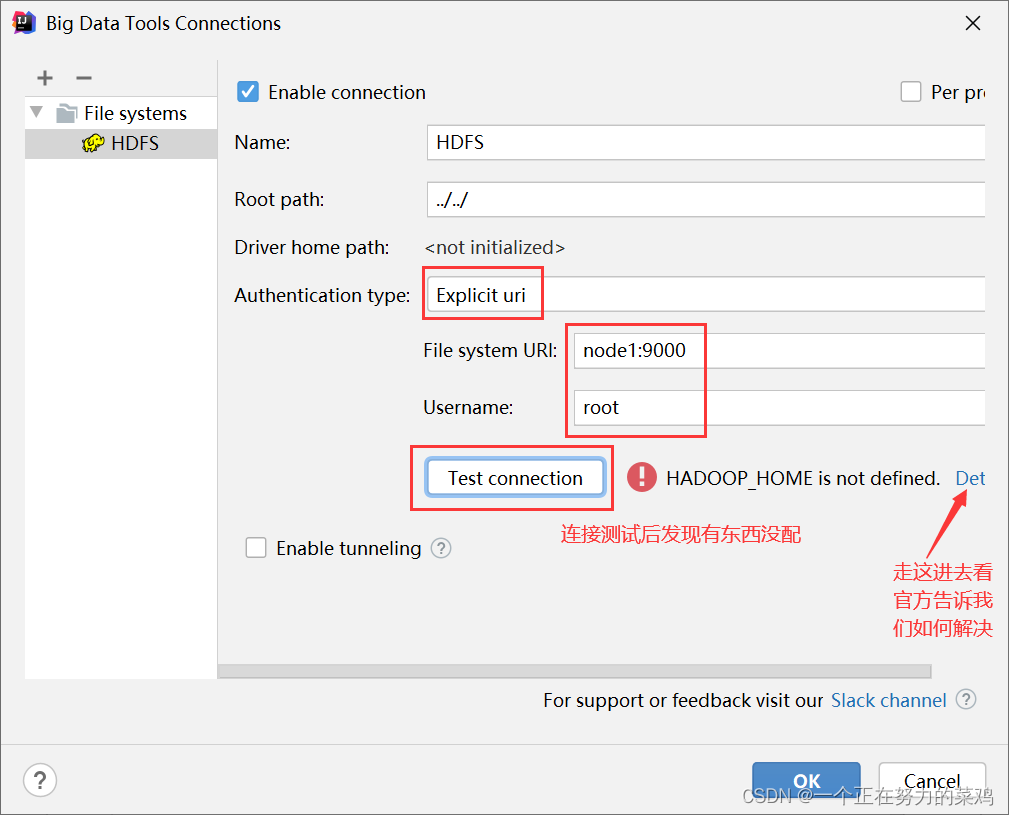
-
报错解决
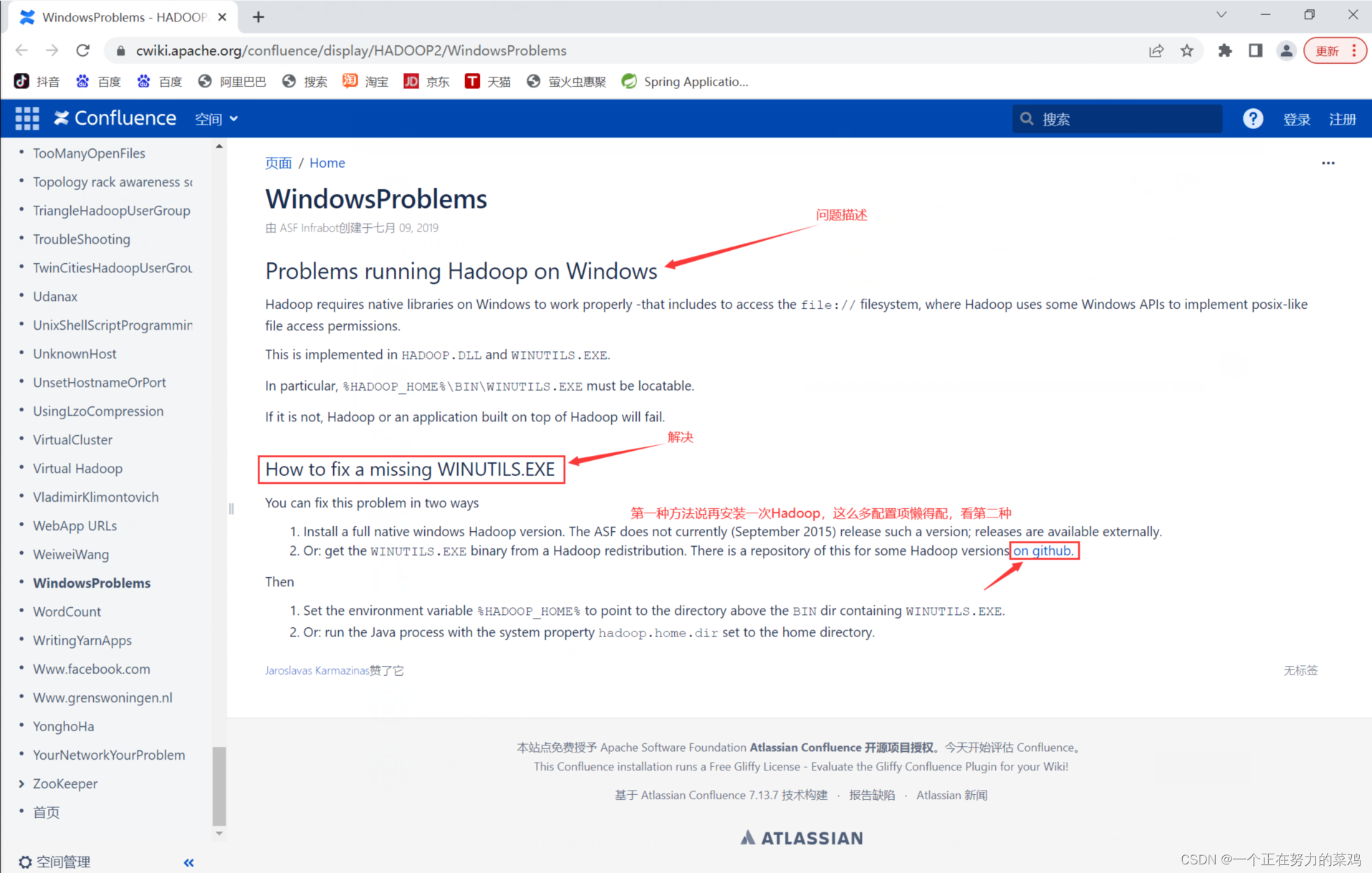
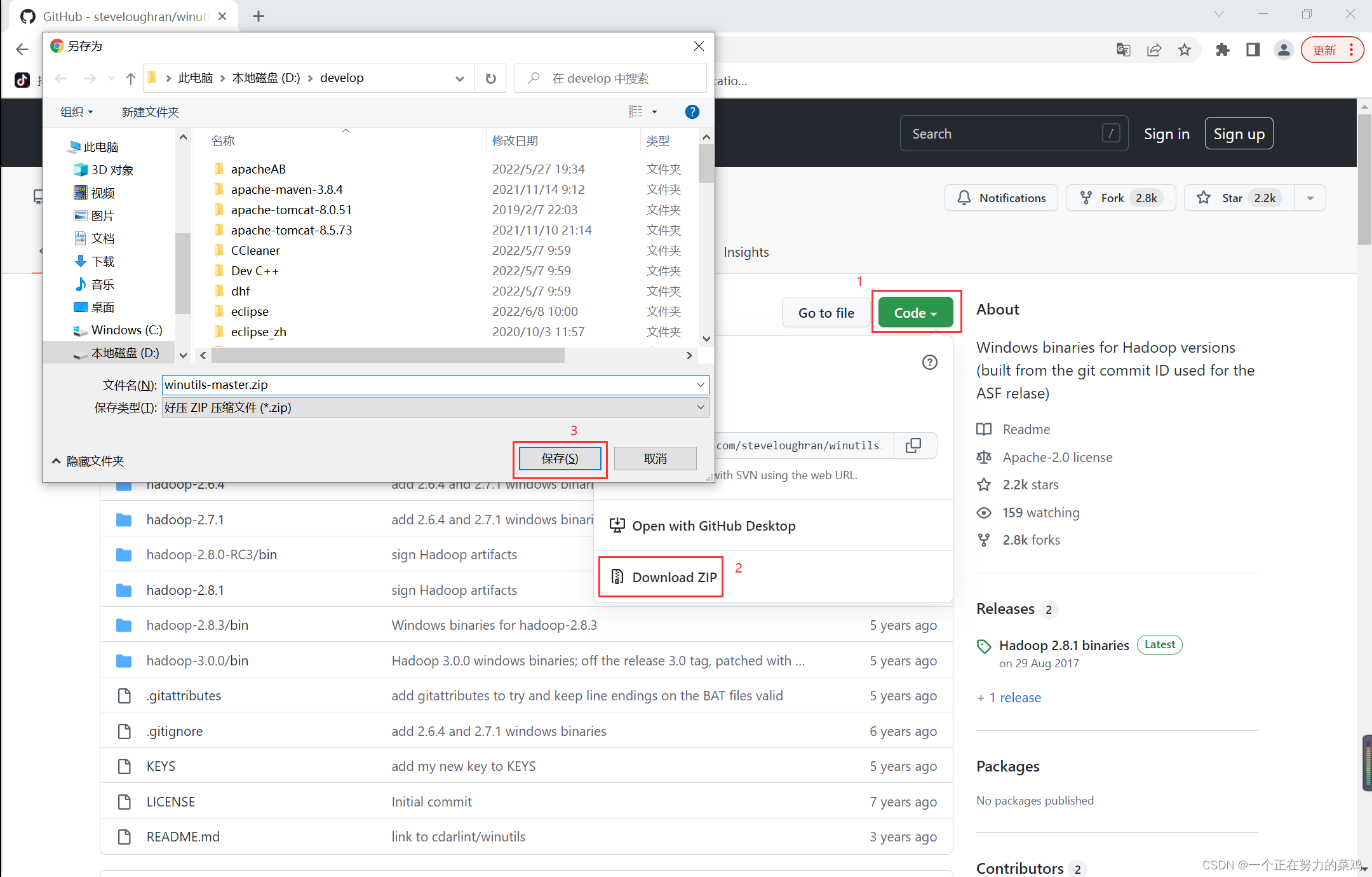
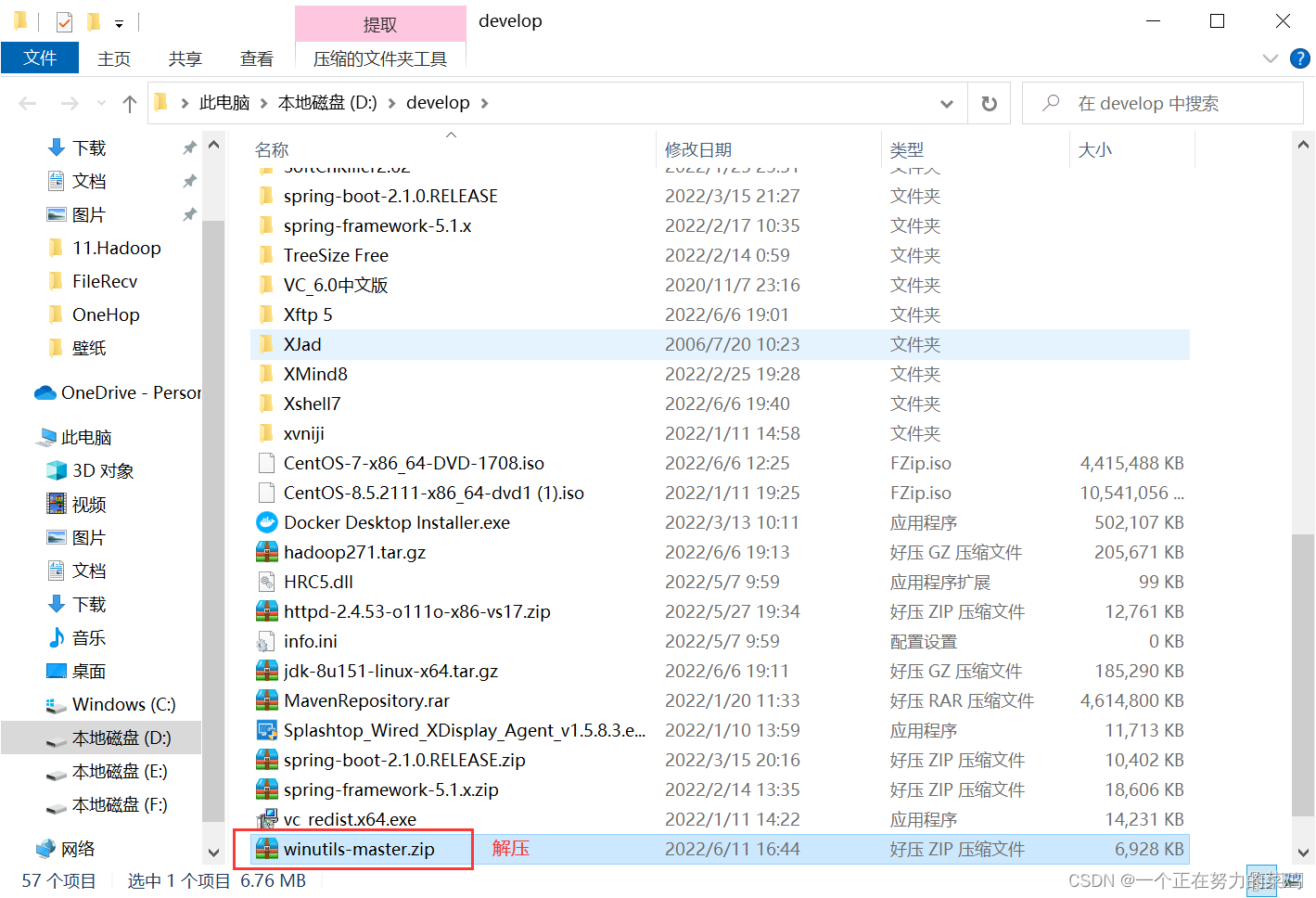
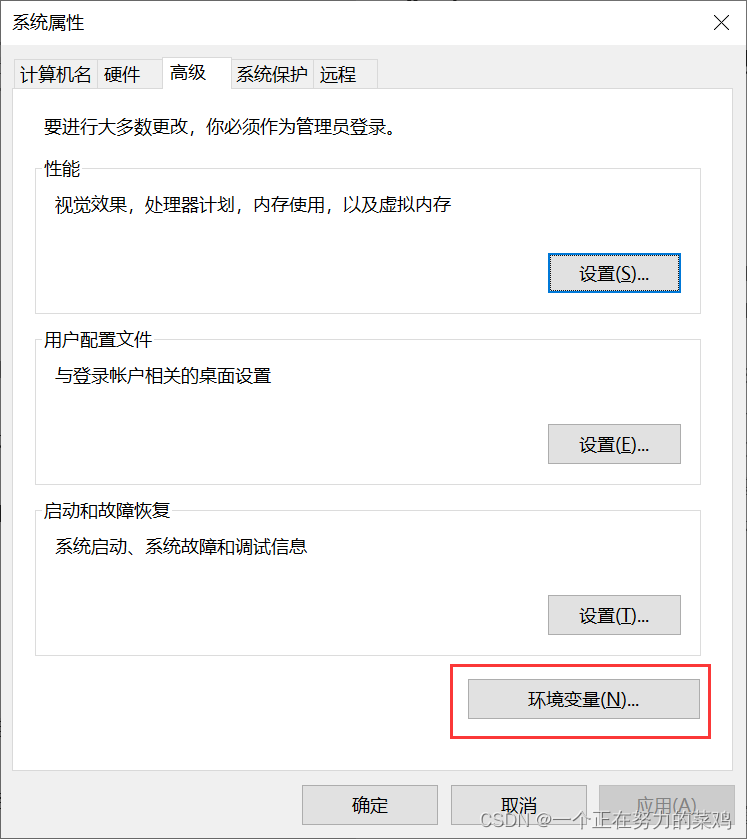
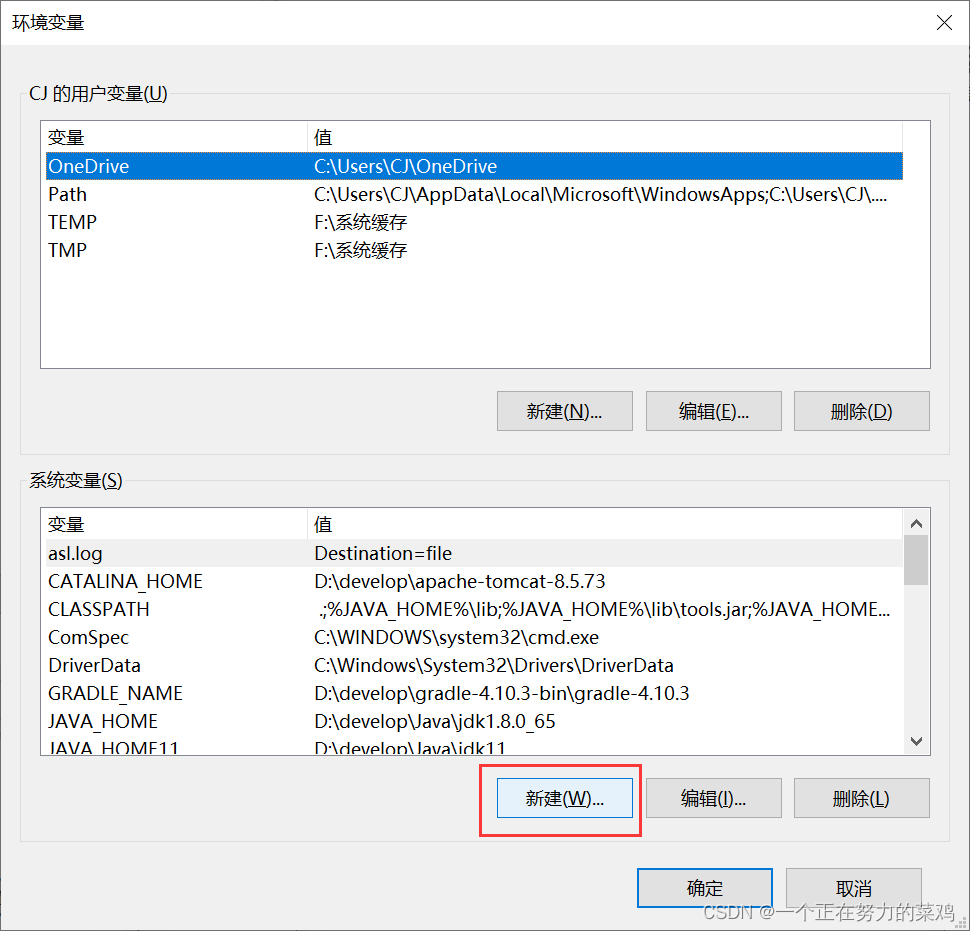

-
测试连接
-
报错解决
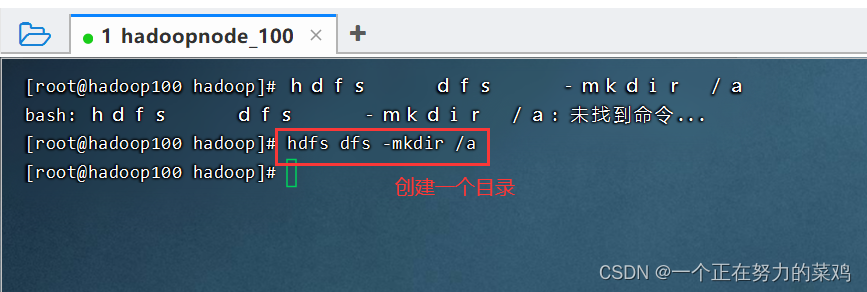
-
成功
版权声明:本文为weixin_51699336原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。