Pytorch优化器
1. 优化器含义
pytorch的优化器:管理并更新模型中可学习的参数的值,使得模型输出更接近真实标签
导数:函数在指定坐标轴上的变化率
方向倒数:指定方向上的变化率
梯度:一个向量,方向为方向倒数取得最大值的方向
2. 优化器Optimizer
2.1 optimizer的属性
- defaults:优化器超参数
- state:参数的缓存,如momentum的缓存
- params_groups:管理的参数组,是一个列表
- _step_count:记录更新次数,学习率调整中使用

2.2 optimizer的方法
- zero_grad():清空所管理参数的梯度 【Pytorch特性:张量梯度不自动清零】
- step():执行一步更新
- add_param_group():添加参数组
- state_dict():获取优化器当前状态信息字典
- load_state_dict():加载状态信息字典
-
optimizer.step()方法
import torch
import torch.optim as optim
torch.manual_seed(1) # 设置随机种子
weight = torch.randn([2,2], requires_grad=True) # 设置随机权重,需要求导
weight.grad = torch.ones([2,2]) # 设置下降的梯度,正常情况是由反向传播提供
optimizer = optim.SGD([weight], lr=0.1) # 构建SGD优化器,学习率为0.1, 优化参数必须是一个列表
print(weight) # 打印优化前的数据
optimizer.step() # 以学习率0.1进行更新参数一步
print(weight) # 打印优化后的数据
# 结果
tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)
tensor([[ 0.5614, 0.1669],
[-0.0383, 0.5213]], requires_grad=True)
-
optimizer.zero_grad()方法
import torch
import torch.optim as optim
torch.manual_seed(1) # 设置随机种子
weight = torch.randn([2,2], requires_grad=True) # 设置随机权重,需要求导
weight.grad = torch.ones([2,2]) # 设置下降的梯度,正常情况是由反向传播提供
optimizer = optim.SGD([weight], lr=0.1) # 构建SGD优化器,学习率为0.1, 优化参数必须是一个列表
print(weight.grad) # 打印清空梯度之前的梯度
optimizer.zero_grad() # 清空当权参数的梯度
print(weight.grad) # 打印清空后的梯度
# 结果
tensor([[1., 1.],
[1., 1.]])
tensor([[0., 0.],
[0., 0.]])
-
optimizer.add_param_group({‘参数名1’: 值, ‘参数名2’: 值})
import torch
import torch.optim as optim
torch.manual_seed(1) # 设置随机种子
weight = torch.randn([2,2], requires_grad=True) # 设置随机权重,需要求导
weight.grad = torch.ones([2,2]) # 设置下降的梯度,正常情况是由反向传播提供
optimizer = optim.SGD([weight], lr=0.1) # 构建SGD优化器,学习率为0.1, 优化参数必须是一个列表
print(optimizer.param_groups) # 打印添加参数前的参数列表
w2 = torch.randn([2,3], requires_grad=True)
optimizer.add_param_group({'params': w2, 'lr': 0.02}) # 添加参数组,注意是以字典的形式添加
print(optimizer.param_groups) # 打印添加后的参数列表
# 结果
# 添加前列表
[{'params': [tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
# 添加后的列表
[{'params': [tensor([[0.6614, 0.2669],
[0.0617, 0.6213]], requires_grad=True)], 'lr': 0.1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False},
{'params': [tensor([[-0.4519, -0.1661, -1.5228],
[ 0.3817, -1.0276, -0.5631]], requires_grad=True)], 'lr': 0.02, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
-
optimizer.state_dict()方法
import torch
import torch.optim as optim
torch.manual_seed(1) # 设置随机种子
weight = torch.randn([2,2], requires_grad=True) # 设置随机权重,需要求导
weight.grad = torch.ones([2,2]) # 设置下降的梯度,正常情况是由反向传播提供
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9) # 构建SGD优化器,学习率为0.1, 优化参数必须是一个列表
print(optimizer.state_dict()) # 打印优化器当前状态信息字典
for i in range(10):
optimizer.step() # 更新10步后
print(optimizer.state_dict()) # 再次打印当前优化器的状态信息字典
torch.save(optimizer.state_dict(), os.path.join(".", "optimizer_state_dict.pkl")) # 保存状态信息字典,保存为.pkl文件
# 结果
# 更新前的优化器状态信息
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [139774591170096]}]}
# 更新后的优化器状态信息
{'state': {139774591170096: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [139774591170096]}]}
-
optimizer.load_state_dict(state_dict)方法
import torch
import torch.optim as optim
torch.manual_seed(1) # 设置随机种子
weight = torch.randn([2,2], requires_grad=True) # 设置随机权重,需要求导
weight.grad = torch.ones([2,2]) # 设置下降的梯度,正常情况是由反向传播提供
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9) # 构建SGD优化器,学习率为0.1, 优化参数必须是一个列表
state_dict = torch.load(os.path.join(".", "optimizer_state_dict.pkl")) # 加载状态信息字典文件
print(optimizer.state_dict()) # 打印加载前的字典
optimizer.load_state_dict(state_dict) # 从文件加载状态信息字典
print(optimizer.state_dict()) # 打印加载的字典
print(optimizer.state_dict()['param_groups'][0]['lr']) # 打印字典中的lr参数
# 结果
# 加载前状态信息字典
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [140224607761968]}]}
# 加载后状态信息字典
{'state': {140224607761968: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [140224607761968]}]}
# 打印lr学习率参数
0.1
2.3 optimizer实例展示
import os
import torch
import torch.optim as optim
torch.manual_seed(10) # 设置随机种子
weight = torch.randn([2, 2], requires_grad=True) # 设置随机权重,需要求导
weight.grad = torch.randn([2, 2]) # 设置下降的梯度,正常情况是由反向传播提供
optimizer = optim.SGD( [weight], lr=0.1, momentum=0.9 ) # 构建SGD优化器,学习率为0.1, 优化参数必须是一个列表
print("更新前的权重参数:\n", weight.data)
optimizer.step() # 更新一步权重参数
print("更新后的权重参数:\n", weight.data)
print("未清空前的梯度:\n", weight.grad)
optimizer.zero_grad() # 将参数梯度清0
print("清空后的梯度:\n", weight.grad)
print("添加参数前的参数列表:\n", optimizer.param_groups) # 获取参数列表
w = torch.randn([1,2], requires_grad=True)
optimizer.add_param_group( {'params': w, 'lr': 0.02} ) # 添加参数字典
print("添加参数后的参数列表:\n", optimizer.param_groups)
print("更新前优化器状态信息字典:\n", optimizer.state_dict()) # 获取优化器状态信息字典
for i in range(10):
optimizer.step()
print("更新后优化器状态信息字典:\n", optimizer.state_dict())
torch.save(optimizer.state_dict(), os.path.join('.', 'optimizer_state_dict.pkl')) # 保存优化器状态信息字典,保存为pkl文件
optimizer.zero_grad()
state_dict = torch.load(os.path.join('.', 'optimizer_state_dict.pkl')) # 加载优化器状态信息字典
print("加载前的状态信息字典:\n", optimizer.state_dict())
optimizer.load_state_dict(state_dict) # 将参数加载到优化器中
print("加载后的状态信息字典:\n", optimizer.state_dict())
print("加载字典中的学习率:\n", optimizer.state_dict()['param_groups'][1]['lr']) # 读取状态字典中的学习率
3. Optimizer方法
3.1 学习率
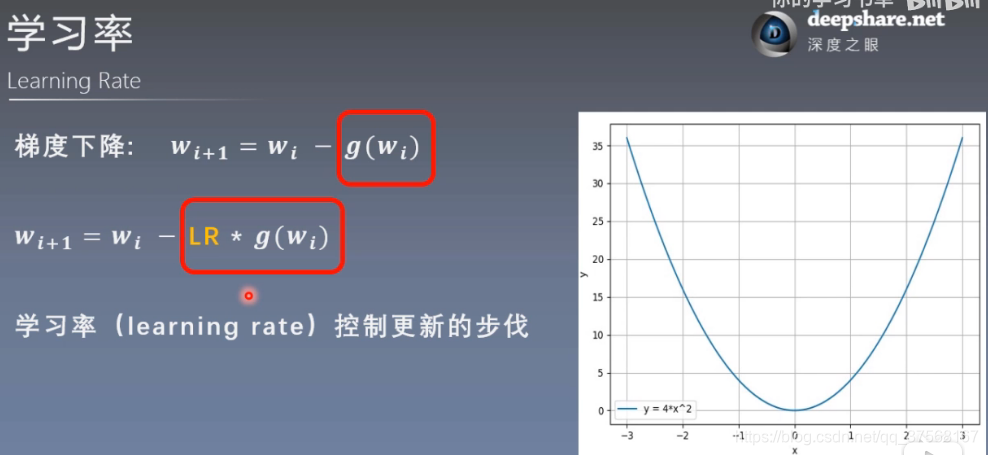
学习率:用于控制更新的步长, 通常取值 lr=0.01
3.2 动量
Momentum(动量,冲量): 结合当前梯度与上一次更新信息,用于当前更新, 通常取值 momentum=0.9
-
梯度下降:
wi
+
1
=
w
i
−
l
r
∗
g
(
w
i
)
w_{i+1}=w_{i}-lr*g(w_{i})
w
i
+
1
=
w
i
−
l
r
∗
g
(
w
i
)
-
Pytorch中的更新公式
vi
=
m
∗
v
i
−
1
+
g
(
w
i
)
v_{i}=m*v_{i-1}+g(w_{i})
v
i
=
m
∗
v
i
−
1
+
g
(
w
i
)
wi
+
1
=
w
i
−
l
r
∗
v
i
w_{i+1}=w_{i}-lr*v_{i}
w
i
+
1
=
w
i
−
l
r
∗
v
i
wi
+
1
:
第
i
+
1
次
更
新
的
参
数
w_{i+1}: 第i+1次更新的参数
w
i
+
1
:
第
i
+
1
次
更
新
的
参
数
lr
:
学
习
率
,
通
常
设
置
0.01
lr:学习率,通常设置0.01
l
r
:
学
习
率
,
通
常
设
置
0
.
0
1
vi
:
更
新
量
v_{i}:更新量
v
i
:
更
新
量
m:
m
o
m
e
n
t
u
m
系
数
,
通
常
设
置
0.9
m:momentum系数,通常设置0.9
m
:
m
o
m
e
n
t
u
m
系
数
,
通
常
设
置
0
.
9
g(
w
i
)
:
w
i
的
梯
度
g(w_{i)}:w_{i}的梯度
g
(
w
i
)
:
w
i
的
梯
度
3.3 常用优化器
-
optim.SGD(params, lr, momentum)
# 函数形式:
optim.SGD(net_SGD.parameters(), lr=0.01, momentum=0.9, weight_decay=0, nesterov=False}
# 参数:
net_SGD.parameters(): 管理的参数组,list的形式,其中list里面是字典dict, 一般是网络模型参数
lr: 学习率,默认le-2
momentum: 动量系数
weight_decay: L2正则化系数,默认0
nesterov: 是否采用NAG,默认False
# 实例
import torch
import torch.optim as optim
weight = torch.randn([2,3])
optimizer = optim.SGD([weight], lr=0.01, momentum=0.9)
-
optim.Adam(params, lr, betas)
# 函数形式:
optim.Adam(net_Adam.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
# 参数
net_Adam.parameters():用于迭代优化的参数或者定义参数组的dict,一般是网络模型参数
lr:学习率(默认 1e-3)
betas(float, float):用于计算梯度的平均和平方的系数(默认(0.9, 0.999))
eps:为了提高数值稳定性而添加到分母的一个项(默认 1e-8)
weight_decay:权重衰减(如L2惩罚)(默认 0)
# 实例
import torch
import torch.optim as optim
weight = torch.randn([2,3])
optimizer = optim.Adam([weight], lr=0.001, betas=(0.9, 0.999))