目录
map的底层结构是红黑树,映射是关联容器。
map中的元素是一些关键字-值对:关键字 起到索引的作用,值则表示与索引向关联的数据。
关键字是唯一的,不能重名。对于迭代器来说,可以修改实值,而不能修改key
。根据key值快速查找记录,查找的复杂度基本是Log(N),
map是按key值排序,且与插入顺序无关。
头文件:
#include <map>
using namespace std;
1、map定义
map<key类型, val类型> 对象名;
示例:
map<int, string> m; // std::string初始化:
Amap m1, m2;
m1[1] = a1;
m1[2] = a2;
m1[3] = a3;
m2.insert(m1.begin(), m1.end());
Amap mp2(m1); // mp2是m1的副本(通过拷贝构造)
m2 = m1; // m2是mp1的副本(通过复制赋值)
2、赋值 or 插入
赋值:
m[1] = "One";插入:
m.insert(make_pair(2, "Two"));以上两种写法等效。
注意:
若已存在该键值,再进行插入操作无效,不报错,只能通过赋值改变内容。
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main()
{
map<int, string> m;
m[1] = "One";
m.insert(make_pair(1, "Two"));
cout << "m[1] = " << m[1] << endl;
return 0;
}输出:
![]()
将:m.insert(make_pair(1, “Two”));改为m[1] = “Two”;输出为:
![]()
3、访问
3.1、通过key直接访问
m[key] = val若访问的key值不存在,则输出该类型的默认值。string输出””。
3.2、迭代器
begin: 返回迭代器到开始(公共成员函数)
end: 返回迭代器到末尾(公共成员函数)
rbegin:返回反向迭代器到反向开始(公共成员函数)
rend: 返回反向迭代器到反向端(公共成员函数)
cbegin: 将const_iterator返回到开始(公共成员函数)
cend: 返回const_iterator末尾(公共成员函数)
crbegin: 返回const_reverse_iterator到反向开始(公共成员函数)
crend: 返回const_reverse_iterator到reverse end(公共成员函数)
顺序迭代:
for (auto it = m.begin(); it != m.end(); ++it)
{
cout << " first:" << it->first << " " << it->second << endl;
}
![]()
逆序迭代:
for (auto it = m.rbegin(); it != m.rend(); ++it)
{
cout << " first:" << it->first << " " << it->second << endl;
}
![]()
其中it的完整定义为:
map<string,int>::iterator it;
4、查找key值是否存在
m.find(key)返回查找到的key值所对应的迭代器。若为未找到则返回m.end()迭代器。
m.find(key) != m.end() // key值存在示例:查找key值,并使用:
auto it = m.find(1);
cout << " m.find: " << it->first << endl;通过map对象的方法获取的iterator数据类型是一个std::pair对象,包括两个数据 iterator.first 和 iterator.second 分别代表关键字和存储的数据。
5、移除key
iterator erase(iterator it);
iterator erase(iterator first, iterator last);
size_type erase(const Key& key);1)移除值为key的键值对
m.eraser(key)移除key值所对应的键值对,如不存在该键值,不报错。
2)依据迭代器位置移除
m.erase(m.begin()); // 删除第一个元素
使用迭代器删除元素时,顺序依赖key值的顺序排序顺序,与插入顺序无关。
测试:
#include <iostream>
#include <map>
#include <string>
using namespace std;
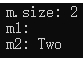
int main()
{
map<int, string> m;
m[2] = "Two";
m[1] = "One";
m[3] = "Three";
m.erase(m.begin());
cout << " m.size: " << m.size() << endl;
cout << " m1: " << m[1] << endl;
cout << " m2: " << m[2] << endl;
return 0;
}输出:
删除所有元素:
m.erase(m.begin(), m.end()); //删除所有元素与下面等价:
m.clear(); //删除所有元素
注意:m.end()为末尾标记,不能访问。
6、容量
m.size(); // 实际数据的数据
m.max_size(); // 最大数据的数量
m.empty(); // 判断容器是否为空
7、顺序比较
map<char,int> mymap;
map<char,int>::key_compare mycomp = mymap.key_comp();
mymap['a']=100;
mymap['b']=200;
mycomp('a', 'b'); // a排在b前面,因此返回结果为true
8、key值顺序
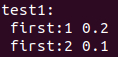
默认按关键字排序。
map<int, float> m1;
m1[2] = 0.1;
m1[1] = 0.2;
cout<< test1: <<endl;
for (auto it = m1.begin(); it != m1.end(); ++it)
cout << first: << it->first << << it->second << endl;输出:
9、map按value排序
正常的map默认按照key值排序,而map又没有像vector一样的sort()函数,那么如果将map按照value值排序呢?有两种方法:
9.1、将map中的key和value分别存放在一个pair类型的vector中,然后利用vector的sort函数排序。
#include <map>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
typedef pair<float, int> PAIR;
int cmp(const PAIR &x, const PAIR &y)
{
return x.second > y.second;
}
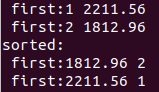
int main()
{
map<int, float> m;
m[2] = 1812.96;
m[1] = 2211.56;
cout<< "m: " << endl;
for(auto it = m.begin(); it != m.end(); ++it)
{
cout << first: << it->first << << it->second << endl;
}
cout<< "sorted:" <<endl;
// ... 执行排序
}最重要是vector的sort函数~~(用sort函数需要引入头文件 #include )
// 排序
vector<PAIR> pair_vec;
for(auto it = m.begin(); it != m.end(); ++it)
pair_vec.push_back(make_pair(it->second, it->first));
sort(pair_vec.begin(), pair_vec.end(), cmp);
for(vector<PAIR>::iterator curr=pair_vec.begin(); curr!=pair_vec.end(); ++curr)
cout << first: << curr->first << << curr->second << endl;9.2、再新建一个map结构,然后把已知的map值得key和value分别作为新map的value和key,这样map结构就会自动按照value值排序。
map<float, int> m2;
for(auto it = m.begin(); it != m.end(); ++it)
{
m2[it->second] = it->first;
m2[it->first] = it->second;
cout << first: << it->first << << it->second << endl;
}
for(auto it = m2.begin(); it != m2.end(); ++it)
cout << first: << it->first << << it->second << endl;结果: