Python常用的数据文件存储格式大全(2021最新/最全版)_小鸿的摸鱼日常的博客-CSDN博客_python存储数据的方式
Python——数据存储的三种方法_lalaSay Something的博客-CSDN博客_python数据存储的几种方式
本文简述数据文件操作(包括csv文件、json文件、excel文件、txt文本文件、mat文件、dat文件、json文件及数据库文件)
注:pandas模块含有读取各种文件的模块,包括xlxs、csv、pickle等:

目录
一、csv文件
CSV,全称为Comma-Separated Values,中文名可以叫做字符分隔值或逗号分隔值,以纯文本形式存储表格数据,文本默认以逗号分隔,CSV相当于一个结构化表的纯文本形式,比Excel文件更加简洁,保存数据非常方便。注:一般数据处理而言,还是建议尽量减少使用csv,保障处理的效率。
1.从csv文件读取数据
(1)csv读取
基于csv库读取csv文件到list中,方法如下:
import csv
with open('test.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(f)
next(reader) #跳过标题行,从第一行开始
for read in reader:
data = read[0]
print(data)结果:通过遍历输出每行内容,即一行一行读,每一行都是一个列表形式
(2)
pandas读取
基于pandas库读取csv文件,得到的数据是DataFrame格式,方法如下:
# 用pandas库中的read_csv()读取csv数据,常用于数据分析
import pandas as pd
data = pd.read_csv('test.csv',sep='\t',header=None)
print(data)
(3)numpy读取
基于numpy库读取csv文件,得到的数据是numpy.array数组格式,方法如下:
from numpy import genfromtxt
data = genfromtxt('test.csv', delimiter=',') #csv默认分隔符是逗号,也可能是\t
2.
把数据写入csv文件
基于csv库写入数据,方法如下:
import csv
headers = ['name', 'age', 'height']
value = [
('张三', '13', '160'),
('李四', '18', '180')
]
# 使用open函数把数据写入csv文件
with open('test.txt', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f) # 初始化写入对象
# writer = csv.writer(f, delimiter=' ') # 可修改列之间的分隔符为空格,传入参数delimiter
writer.writerow(headers) # 读取一行,调用writerow()传入每行数据完成写入操作
writer.writerows(value) # 读取多行,多行写入,参数为二维列表
# 输出结果
name,age,height
张三,13,160
李四,18,180
注:若没有newline=’ ‘,会出现空行
# 字典写入 如爬虫数据是结构化数据,用字典表示
import csv
with open('test.csv', 'a', encoding='utf-8') as f:
headers = ['name', 'age', 'height']
value1 = {'name':'张三', 'age':'13', 'height':'160'}
value2 = {'name':'李四', 'age':'18', 'height':'180'}
writer = csv.DictWriter(f,fieldnames=headers) # fieldbames定义头信息,再传给DictWriter初始化字典写入对象
writer.writeheader() # 写入头信息
writer.writerow(value1) # 调用writerow()传入字典
writer.writerow(value2)注:csv文件格式为逗号分隔值文件格式,属于纯文本,window下默认通过excel打开;若csv文件包含中文,需要指定文件编码
二、excel文件
Excel文件中包含了文本、数值、公式和格式等内容,而CSV不包含这些,默认打开编码为Unicode,是现在比较流行的数据存储格式
1.从excel文件读取数据
(1)xlrd读取
基于xlrd库读取数据,方法如下:
pip install xlrd #xlrd库,读取excel数据
case1:
import xlrd
book = xlrd.open_workbook('test.xls') #新建excel对象
sheet = book.sheet_by_index(0) # 通过下标index获取sheet页数
# sheet = book.sheet_by_name() # 通过名字获取sheet页面
row = sheet.nrows # 获取sheet的行数
col = sheet.ncols # 获取sheet的列数
# 获取单元格的值
cell = sheet.cell(1,1).value
cell_1 = sheet.row(2)[1].value
cell_2 = sheet.col(1)[1].value
row_vaule = sheet.row_values(0) # 获取第0行的值
col_vaule = sheet.col_values(0) # 获取第0列的值
# 获取行里面的值
for i in range(row):
print(sheet.row_values(i))
执行结果:
['九九乘法表', '', '', '', '', '', '', '', '']
['1 * 1 = 1', '', '', '', '', '', '', '', '']
['2 * 1 = 2', '2 * 2 = 4', '', '', '', '', '', '', '']
['3 * 1 = 3', '3 * 2 = 6', '3 * 3 = 9', '', '', '', '', '', '']
['4 * 1 = 4', '4 * 2 = 8', '4 * 3 = 12', '4 * 4 = 16', '', '', '', '', '']
['5 * 1 = 5', '5 * 2 = 10', '5 * 3 = 15', '5 * 4 = 20', '5 * 5 = 25', '', '', '', '']
['6 * 1 = 6', '6 * 2 = 12', '6 * 3 = 18', '6 * 4 = 24', '6 * 5 = 30', '6 * 6 = 36', '', '', '']
['7 * 1 = 7', '7 * 2 = 14', '7 * 3 = 21', '7 * 4 = 28', '7 * 5 = 35', '7 * 6 = 42', '7 * 7 = 49', '', '']
['8 * 1 = 8', '8 * 2 = 16', '8 * 3 = 24', '8 * 4 = 32', '8 * 5 = 40', '8 * 6 = 48', '8 * 7 = 56', '8 * 8 = 64', '']
['9 * 1 = 9', '9 * 2 = 18', '9 * 3 = 27', '9 * 4 = 36', '9 * 5 = 45', '9 * 6 = 54', '9 * 7 = 63', '9 * 8 = 72', '9 * 9 = 81']
Process finished with exit code 0
case2:
import xlrd
def read(xlsfile):
file = xlrd.open_workbook(xlsfile) # 得到Excel文件的book对象,实例化对象
sheet0 = file.sheet_by_index(0) # 通过sheet索引获得sheet对象
# sheet1 = book.sheet_by_name(sheet_name) # 通过sheet名字来获取,当然如果知道sheet名字就可以直接指定
nrows = sheet0.nrows # 获取行总数
ncols = sheet0.ncols # 获取列总数
list = []
for i in range(nrows):
list.append([])
for j in range(ncols):
# print(sheet0.cell_value(i, j))
list[i].append(str(sheet0.cell_value(i, j)))
print(list)
return list
def excel_to_data():
list = read('demo.xls')
for lis in list:
print(lis)
if __name__ == '__main__':
excel_to_data()
首先调用xlrd的open_workbook()方法创建操纵Excel文件的对象,然后通过sheet_by_index(index)方法或sheet_by_name(sheet_name)方法根据索引、sheet名获取sheet对象,然后获取数据的总行数以及总列数,通过两个for循环,调用sheet对象的cell_value(i, j)获取单元格的值,强制转换成字符串类型之后再根据索引添加到列表list中,以此构成二维数组,输出并返回,最后再遍历二维数组的每个元素(每个列表)进行输出即可
注:xlrd支持对后缀为.xls以及.xlsx的Excel文件的读取;并且不论是xlwt还是xlrd,数据的起始索引位置都为0
(2)转换为csv文件再读取
相比csv文件,xls文件内部存在格式信息,可把Excel文件转换为csv文件,直接更改后缀名会出错,建议另存为改格式;
(3)pandas读取
基于pandas库读取,
pandas
读取为
dataframe
格式,其中
dataframe.values
是
nparray
格式,
nparray.tolist()
是
python list
格式。方法如下:
# pandas库读取Excel
import pandas as pd
data = pd.read_excel('test.xlsx')注:pandas和 xlrd的区别在于,pandas会把第一行和第一列作为索引的表头;xlrd则会把所有的数据都读取,没有索引表头一说 。
(4)openpyxl库读取
基于openpyxl读取Excel文件,方法如下:
# openpyxl读取Excel数据
import openpyxl
wb = openpyxl.load_workbook('demo.xlsx')
ws = wb.get_sheet_by_name('data')
rows = ws.max_row
columns = ws.max_column
datas = []
for i in range(1,rows+1):
for j in range(1,columns+1):
datas.append(str(ws.cell(i,j).value))
print(datas)
2.写入数据到excel
(1)xlwt写入
基于xlwt库写入数据,方法如下:
pip install xlwt # xlwt库,excel写入数据和格式化数据
case1:
import xlwt
workbook = xlwt.Workbook(encoding='utf-8') # 创建workbook对象
worksheet = workbook.add_sheet('sheet1') # 添加一个sheet页面
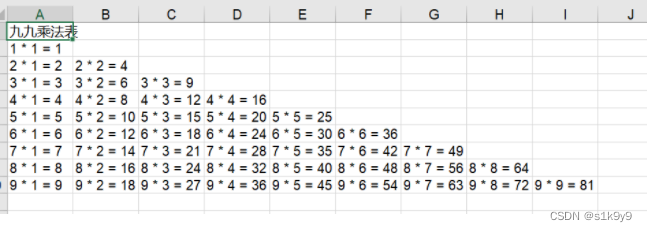
head = ['九九乘法表']
# 写入主体
for j in range(0,1):
worksheet.write(0,j,head[j])
for i in range(0,9):
for j in range(0,i+1):
worksheet.write(i+1,j,'%d * %d = %d'%(i+1, j+1, (i+1)*(j+1)))
# 保存excel数据表
workbook.save('test.xls')
case2:
import xlwt
file = xlwt.Workbook(encoding='utf-8')
table = file.add_sheet('data')
datas = [
['python实习生','贵阳','本科'],
['java实习生','杭州','本科'],
['爬虫工程师','成都市','硕士']
]
for i,p in enumerate(datas):
for j,q in enumerate(p):
table.write(i,j,q)
file.save('demo.xls')
首先导入xlwt库,然后调用Workbook()方法初始化一个可以操纵Excel表格的对象,并指定编码格式为utf-8,接着再创建一个要写入数据的指定表,用列表的形式创建二维数组,再用两个for循环指定要添加数据的位置,这里的i表示外层列表元素所在位置的序号,j表示里层列表元素所在位置的序号,p和q分别表示外层列表和里层列表的元素值,table.write(i,j,q)表示在第i行和第j列插入数据q,最后保存Excel文件

注:xlwt库支持的Excel版本兼容问题,只支持Excel 97-2003(.xls),不支持Excel 2010(.xlsx)和Excel 2016(.xlsx),所以保存时后缀需为.xls
(2)pandas写入
基于pandas库写入数据,方法如下:
# pandas库写入Excel
import pandas as pd
data = pd.DataFrame([['python实习生','贵阳','本科'],['java实习生','杭州','本科'],['爬虫工程师','成都市','硕士']])
data.to_excel('demo.xlsx')

以pandas库的DataFrame()方法存储的数据是带有索引序号的,方便进行数据分析、建模等
注意:pandas库支持后缀为.xlsx的Excel表格
(3)openpyxl库写入
基于openpyxl写入Excel,方法如下:
# openpyxl写入Excel
import openpyxl
wb = openpyxl.Workbook()
ws = wb.create_sheet('data')
ws.cell(row=1,column=1).value="职位"
ws.cell(row=1,column=2).value="位置"
ws.cell(row=1,column=3).value="学位"
wb.save('demo.xlsx')
注意:openpyxl只支持后缀为.xlsx的Excel文件,并且读取或写入数据的索引位置均为1
个人推荐使用xlrd和xlwt以及pandas,这些库操作Excel文件时数据的起始索引位置都为0,比较方便,不过也可以根据个人使用习惯以及需求来决定
三、文本文件
TXT文本几乎兼容任何平台,但是不利于检索,如果对检索和数据结构要求不高,寻求方便的话,可以采用TXT文本存储格式
1. 操作方法
# 基本写法
f = open('test.txt', 'a', encoding='utf-8') # 参数a:以追加方式写入文本
f.write(data)
f.close()
# 简化写法 with...as
with open('test.txt', 'a', encoding='utf-8') as f:
f.write(data)
2. read\readline\readlines函数
read() 函数逐个字节(或者逐个字符)读取文件中的内容;后2 个函数都以“行”作为读取单位,即每次都读取目标文件中的一行。对于读取以文本格式打开的文件,读取一行很好理解;对于读取以二进制格式打开的文件,它们会以“\n”作为读取一行的标志。
(1)read()
逐个字节或者字符读取文件中的内容,若有参数,则根据指定值读取字节或字符。
基本语法格式:file.read([size])
file 表示已打开的文件对象;size 作为一个可选参数,用于指定一次最多可读取的字符(字节)个数,如果省略,则默认一次性读取所有内容。
with open('test.txt', 'r', encoding='utf-8') as f:
f.read()调用 read() 函数逐个字节(或者逐个字符)读取文件中的内容,即如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。
(2)readline()
readline() 函数用于读取文件中的一行,包含最后的换行符“\n”。
基本语法格式为:file.readline([size])
file 为打开的文件对象;size 为可选参数,用于指定读取每一行时,一次最多读取的字符(字节)数。
使用 open() 函数指定打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
with open('test.txt', 'r', encoding='utf-8') as f:
print(f.readline())注:readline() 会读取最后的换行符“\n”,再加上 print() 函数输出内容时默认会换行,所以输出结果中会看到多出了一个空行。
(3)readlines()
readlines() 函数用于读取文件中的所有行,它和调用不指定 size 参数的 read() 函数类似,只不过该函数返回是一个字符串列表,其中每个元素为文件中的一行内容。
基本语法格式:file.readlines()
file 为打开的文件对象。和 read()、readline() 函数一样,它要求打开文件的模式必须为可读模式(包括 r、rb、r+、rb+ 4 种)。
# case 1
with open('test.txt', 'rb', encoding='utf-8') as f:
print(f.readlines())
#输出
[b'Python\r\n', b'http://c.net/python/']# case 2:以字典形式读取数据,名字作为键,年龄作为值
content = []
with open('members.txt', 'r') as f:
for line in f.readlines():
line_list = line.strip('\n').split('\t') # 去除换行符,以制表符分隔
content.append(line_list)
keys = content[0]
for i in range(1, len(content)):
content_dict = {}
for k, v in zip(keys, content[i]):
content_dict[k] = v
print(content_dict)
#输出
{'Name': 'Andy', 'age': '32'}
{'Name': 'Bob', 'age': '20'}
{'Name': 'Jenny', 'age': '43'}
{'Name': 'Holly', 'age': '48'}
{'Name': 'Danie', 'age': '27'}
3. 文本打开方式
除了参数a,还存在以下方式打开文件:
| r |
以 只读方式 打开文件 |
| rb | 二进制只读方式 |
| r+ | 读写方式 |
| rb+ | 二进制读写方式 |
| w | 写入方式 |
| wb | 二进制写入方式 |
| w+ | 读写方式 |
| wb+ | 二进制读写方式 |
| a | 追加方式 |
| ab | 二进制追加方式 |
| a+ | 读写方式 |
| ab+ | 二进制追加方式 |
表中b表示二进制,+表示读写方式,r表示读,w表示写
4. numpy读取
基于numpy读取txt文件,方法如下:
import numpy
data = numpy.loadtxt('test.txt')
四、mat文件
mat数据格式是
Matlab
的数据存储的标准格式。在Matlab中主要使用load()函数导入一个mat文件,使用save()函数保存一个mat文件。
1.从mat文件中读取数据
(1)numpy读取
使用numpy读取,得到一个字典,顺便mat转换为array。方法如下:
# mat文件读取
from mat4py import loadmat
import numpy as np
data = np.array(loadmat('test.mat')['DE_time']).astype('float')
(2)scipy.io读取
使用scipy.io读取,得到字典格式’dict’,mat文件中的矩阵格式为numpy中的矩阵格式’numpy.ndarray’。方法如下:
# mat文件读取
import os
import scipy.io as scio
os.chdir('E:\data')
data = scio.loadmat('test.mat')
de = data['DE_time']注:以上两种方式只是库不同,推荐(1).
2.写入数据到mat文件
(1)scipy.io写入
import scipy.io as scio
scio.savemat('dataNew.mat', {'A':data['A']}) #将data中的矩阵A以字典形式保存注:上面是以字典形式保存
五、dat文件
.dat文件双击是无法打开的,可认为是一种
加密
模式,方法是打开记事本,然后选择”另存为”,然后在文件名框里面输入”xxx.dat”,点确定后即可.
将dat格式的文件作为数据库保存方法:GetDataParse(Application.StartupPath + “\\DataFilePath.dat”);
注:GetDataParse是操作函数,括号内是链接逻辑,DataFilePath.dat是txt名称。
dat文件作为数据库保存的优点在于方便使用,也可以直接进去查看,缺点是数据量不能太大。
1.从dat文件中读取数据
(1)pandas读取(推荐)
基于pandas读取dat文件,得到DataFrame格式,方法如下:
#从dat文件读取数据
import pandas as pd
data = pd.read_csv('test.dat', sep='::', header=None, names=['UserID','Gender','Age'])
(2)numpy读取
import numpy as np
data = np.fromfile('test.dat', dtype=int)
(3)dat文件转换成txt文件,再读取
需要把
.dat
格式 转化成
.txt
格式,参考:
(14条消息) python文件操作3–批量修改文件后缀名_rosefunR的博客-CSDN博客_python 修改文件后缀
六、json文件
JSON,全称为JavaScript Object Notation,也就是JavaScript对象标记,构造简洁但是结构化程度非常高,采用对象和数组的组合来表示数据,和XML有点类似,如果对数据结构有要求的话,可根据需求考虑此种方式.
json是一种轻量级的数据交换格式。采用完全独立于编程语言的文本格式来存储和表示数据。层次结构简洁而清晰,易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
最主要的是,通过json这个包可以很方便的解决无论是py2还是py3中的编码问题,json的内容结构也近似于python中的字典和列表,操作起来特别方便。
1. 从json文件读取
基于json库的dumps()方法读取json对象,方法如下:
# python提供json库实现对json文件的读写操作
import json
# 调用dumps()方法可以将json对象转换为文本字符串
with open('demo.json','w',encoding='utf-8') as f:
f.write(json.dumps(data,indent=2,ensure_ascii=False))
# indent代表缩进字符个数,ensure_ascii=False规定文件输出的编码
# 使用dumps将列表序列化并且转换为unicode编码,储存的时候,就可以存utf-8了
lis = [{},{},{}...]
data = json.dumps(lis, ensure_ascii=False)
f.write(data.encode('utf-8'))
2.写入json文件
基于json库的loads()方法写入json对象,方法如下:
import json
# 调用json库的loads()方法可以将json文本字符串转换为json对象
with open('demo.json','r',encoding='utf-8') as f:
data = f.read()
data = json.loads(data)
price = data.get('price')
location = data.get('location')
size = data.get('size')
注:JSON 的数据需要用双引号来包围,不能使用单引号,代码如下:
[
{
"name":"makerchen',
"gender":"male",
"hobby":"running"
}
]
如果我们想要把数据存储为TXT格式,又想要把数据变为json这样的结构,可以这样实现:
import json
with open('demo.txt','a',encoding='utf-8') as f:
f.write(json.dumps(data,indent=4,ensure_ascii=False) + '\n')
七、Mysql数据库文件
1. 数据库安装
https://mp.csdn.net/mp_blog/creation/editor/126879843
图形化工具:Navicat或者SQLyog
2. 导入
import pymysql # python3.x 用于连接Mysql服务器
3. 操作方法
#在mysql的数据库中创建一个表格
@python3
import pymysql
@python2
import Mysqldb
# 连接database
conn = pymysql.connect(
host=“你的数据库地址(如localhost)”,
user=“用户名”,password=“密码”,
database=“数据库名”,port=“端口号”
charset=“utf8”)
# 得到一个可以执行SQL语句的光标对象cursor
cursor = conn.cursor()
# 得到一个可以执行SQL语句的游标
#cursor = conn.cursor()
# 定义要执行的SQL语句
sql = """
CREATE TABLE `USER1` (
`id` INT auto_increment PRIMARY KEY ,
`name` CHAR(10) NOT NULL UNIQUE,
`age` TINYINT NOT NULL
)ENGINE=innodb DEFAULT CHARSET=utf8; #注意:charset='utf8' 不能写成utf-8
"""
# 执行SQL语句
cursor.execute(sql)
#映射到数据库上
conn.commit()
# 关闭光标对象
cursor.close()
# 关闭数据库连接
conn.close()
4. 实战
import pymysql
import requests
from lxml import etree
from fake_useragent import UserAgent
headers = {
"User-Agent": UserAgent().random
}
conn = pymysql.connect(host='localhost', user='root', password='小编的密码(这里隐去)',
database='mydb', port=3306, charset='utf8')
cursor = conn.cursor()
#防止与mysql连接中断
conn.ping(reconnect=True)
#定义一个函数来获取数据并返回一个列表
def get_data(url):
list=[]
response = requests.get(url,headers=headers)
response.encoding='utf-8'
trees = etree.HTML(response.text)
ranks = trees.xpath("//div/ul/li/@data-index")
songnames = trees.xpath('//div/ul/li/a[@class="pc_temp_songname"]/text()')
songtimes = trees.xpath('//div/ul/li/span/span[@class="pc_temp_time"]/text()')
for i in zip(ranks, songnames, songtimes):
rank, songname, songtime = i
data = (int(rank) + 1, songname, songtime.replace("\t", "").replace("\n", ""))
list.append(data)
return list
#定义一个函数来把数据插入mysql数据库中
def insert_mysql(list):
#sql语句,表名为song_list,各列名为rank,song,time
sql = "insert into song_list(`rank`,`song`,`time`) values (%s,%s,%s)"
#将得到的list进行遍历从下标取值,将(li[0], li[1], li[2])映射(%s,%s,%s)上
for li in list:
cursor.execute(sql, (li[0], li[1], li[2]))
conn.commit()
if __name__ == '__main__':
url = "https://www.kugzhiou.com/yy/rank/home/1-8888.html?from=rank"
alist = get_data(url)
insert_mysql(alist)
cursor.close()
conn.close()
注:除了Mysql数据库,还有Redis数据库、Mongdb数据库