目前spark2.x版本底层并不支持spark直接访问hive事务表,只能获取表结构,不能获取数据,有兴趣的同学可以试验一下。网上也查阅了很多相关的资料,现在把它们总结一下,目前能想到的解决方案就是通过jdbc的方式获取,以下就是解决方案:
sql: str = "(select * from std.ice_tiantongfen_back_for_resolve_url_2) as temp" jdbcDF = sparkSession.read \ .format("jdbc") \ .option("driver", "org.apache.hive.jdbc.HiveDriver") \ .option("url", "jdbc:hive2://cdhmaster02:10000") \ .option("user", "etl") \ .option("dbtable", sql) \ .option("fetchsize", "100") \ .load()
在运行上述脚本时,需要引用相应的jar包hive-jdbc-1.1.0-cdh5.12.2.jar和hive-service-1.1.0-cdh5.12.2.jar。这两个jar包可以在CDH安装目录下找到。以下是运行的结果:

数据还是有异常的,居然和列名一模一样。在网上查阅相关资料以及阅读spark源码发现问题如下:
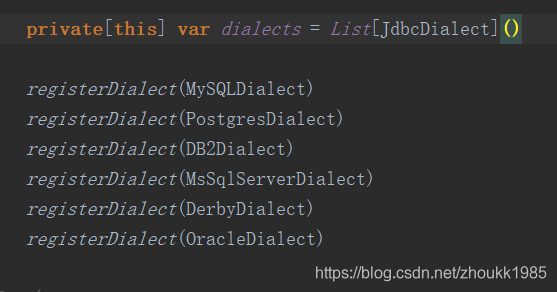
spark的底层居然没有添加HiveJDBC,所以无法解析正常的数据。问题已经发现 ,现在要做的就是新建一个类,继承JdbcDialect,并重写了canHandle和quoteIdentifier方法,然后再进行注册,代码如下:
case object HiveSqlDialect extends JdbcDialect { override def canHandle(url: String): Boolean = url.startsWith("jdbc:hive2") override def quoteIdentifier(colName: String): String = { colName.split('.').map(part => s"`$part`").mkString(".") } }class RegisterHiveSqlDialect { def register(): Unit = { JdbcDialects.registerDialect(HiveSqlDialect) } }
和hive交互的程序是用python编写,但是上述代码是用scala编写,要打成jar包,jar包名字叫做:sparkhivejdbc-1.0.jar。python中还要引用java_import模块才可以调用上述代码。如果和hive交互的程序是scala或java,则可以直接调用。具体如下:
gw = sparkSession.sparkContext._gateway from py4j.java_gateway import java_import java_import(gw.jvm, "HiveJdbcDialects.RegisterHiveSqlDialect") registerHiveSqlDialect = gw.jvm.RegisterHiveSqlDialect() registerHiveSqlDialect.register() sql: str = "(select * from std.ice_tiantongfen_back_for_resolve_url_2) as temp" jdbcDF = sparkSession.read \ .format("jdbc") \ .option("driver", "org.apache.hive.jdbc.HiveDriver") \ .option("url", "jdbc:hive2://cdhmaster01:10000") \ .option("user", "etl") \ .option("dbtable", sql) \ .option("fetchsize", "100") \ .load()
在运行时,需要添加相关的jar包依赖–jars sparkhivejdbc-1.0.jar,hive-jdbc-1.1.0-cdh5.12.2.jar,hive-service-1.1.0-cdh5.12.2.jar.结果如下:

数据现在可以正常显示。至此困扰多日的spark读取hive事务表数据的问题得到解决。