1、HashMap
HashMap的数据结构在JDK1.8以下是:(数组+链表)
在JDK1.8时更新为 (数组+链表+红黑树)
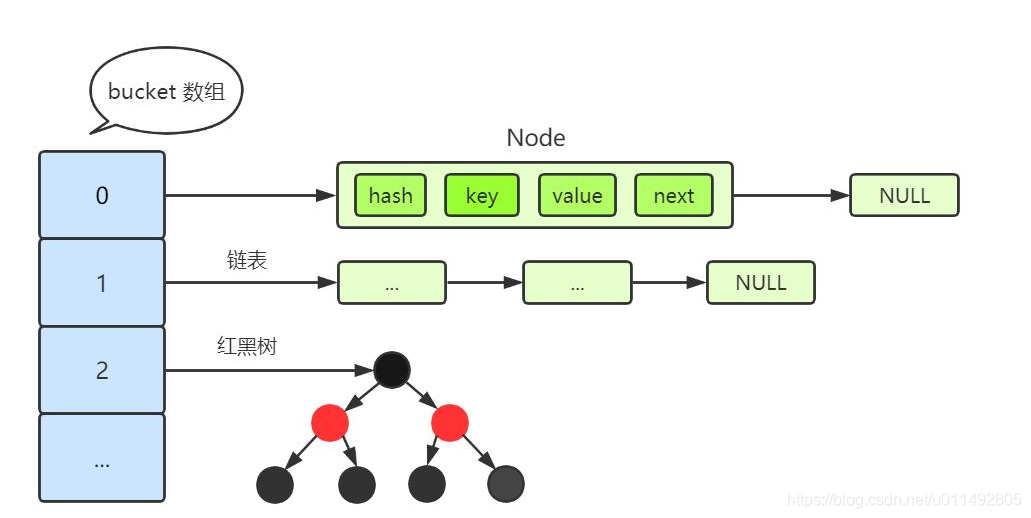
为什么要做这种转变呢?
原因是当链表长度过长时会查询的时间复杂度时O(n),而转换成红黑树后查询的时间复杂度为O(logn),提高了查询效率,那么什么时候由链表转化为红黑树呢?
//树化阈值
static final int TREEIFY_THRESHOLD = 8;
//树化数组容量阈值
static final int MIN_TREEIFY_CAPACITY = 64;
//取自putVal
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); //插入节点
if (binCount >= TREEIFY_THRESHOLD - 1) // 长度到达阈值
treeifyBin(tab, hash); //树化
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
//取自treeifyBin
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) //如果数组容量小于阈值
resize(); //扩容
else if ((e = tab[index = (n - 1) & hash]) != null) { //树化
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}查看源代码可知,当链表长度>=8时,且数组长度>=64时,链表转化成红黑树,这是为啥呢?
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million翻译过来的意思就是红黑树的占用的空间大小是链表的两倍,只有当链表中的元素足够多时才做转化,而链表长度的概率则符合泊松分布,
链表长度为8的概率已经很低了,所以在这个时候转化成红黑树已优化查询效率的性价比是很高的。
那么什么时候红黑树会还原成链表呢?
//红黑树转链表阈值
static final int UNTREEIFY_THRESHOLD = 6;
//取自split
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}从上可知当链表长度<=6时,红黑树转化为链表。
我们知道HashMap在遍历时是无序的(即非插入顺序),那为什么会是无序的呢? 我们来看看HashMap实现的迭代器代码
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // 定位到table中第一个不为空的Node
do {} while (index < t.length && (next = t[index++]) == null);
}
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//如果next为空且table不为空就继续定位下一个不为空的Node
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
...//其他代码省略
}可以看到,遍历时按照数组顺序+链表的next遍历的,而插入Node时是根据hashcode算出在某个位置插入的,所以HashMap遍历时无序的。
2、LinkedHashMap
LinkedHashMap继承自HashMap并声明了3个字段
//头结点
transient LinkedHashMap.Entry<K,V> head;
//尾节点
transient LinkedHashMap.Entry<K,V> tail;
//true 为访问顺序,false为插入顺序
final boolean accessOrder;干嘛用的?
我们知道HashMap是无须的,即插入顺序和遍历顺序不一致。
而LinkedHashMap在HashMap的基础上增加了2个指针分别指向当前这个Node的头尾节点,从而使得可以按照插入顺序或者访问顺序来进行元素遍历(默认为插入顺序)
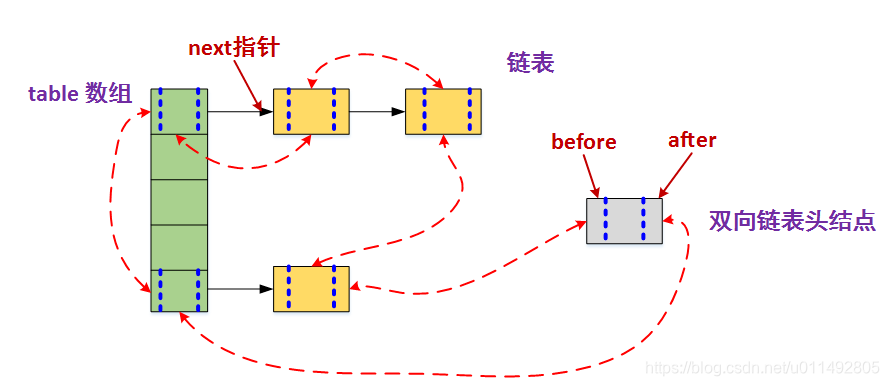
我们来看一下其中一个构造函数,可以指定为访问顺序排序,即LRU(最近最少使用算法)
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}当指定了为LRU方式排序时,每当访问或插入一个元素之后,便会把这个元素放到链表的最后面 ,我们来看一下代码
//取自putVal片段
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //放到最后
return oldValue;
}
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder) //设置为true
afterNodeAccess(e); //移动节点到最后
return e.value;
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}LinkedHashMap还可以实现简单的缓存功能
void afterNodeInsertion(boolean evict) { // 可能移除最少使用的节点
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) { //条件允许则移除头结点
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//子类基础重写
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}栗子:
public class TestLinked extends LinkedHashMap<String,String>{
private int size;
public TestLinked(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<String, String> eldest) {
return size>=3;
}
@Override
public String put(String key, String value) {
String result = super.put(key, value);
size++;
return result;
}
public static void main(String[] args) {
TestLinked linked = new TestLinked(16, 0.75f, true);
linked.put("a", "a");
linked.put("b", "b");
linked.put("c", "c");
linked.get("a"); //get一下不然元素会被删除
linked.put("d", "d");
linked.put("e", "e");
System.out.println(linked); //输出{a=a, d=d, e=e}
}
}
3、TreeMap
TreeMap是无序的(插入和遍历顺序不一致),可以通过使用不同的构造方法指定其遍历顺序
数据结构为:(红黑树)
值得注意的是,若使用TreeMap的默认构造方法,作为Key的类必须实现Comparable接口,若使用传入比较器的构造函数则作为Key的类不用实现Comparable接口
//默认构造
public TreeMap() {
comparator = null; //Key的类必须实现Comparable
}
//传入比较器
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}普通排序栗子:
public static void main(String[] args) {
Comparator<? super String> comparator1 = (k1,k2)->k2.compareTo(k1);
Comparator<? super String> comparator2 = (k1,k2)->k1.compareTo(k2);
Map<String,String> map = new TreeMap<String, String>(comparator1);
map.put("c", "c");
map.put("a", "a");
map.put("b", "b");
System.out.println(map);
//使用comparator1输出{c=c, b=b, a=a}
//使用comparator2输出{a=a, b=b, c=c}
}一些有用的方法
public static void main(String[] args) {
Comparator<? super String> comparator2 = String::compareTo;
TreeMap<String,String> map = new TreeMap<String, String>(comparator2);
map.put("c", "c");
map.put("a", "a");
map.put("b", "b");
map.put("e", "e");
map.put("f", "f");
System.out.println(map);
System.out.println(map.firstKey()); //a
System.out.println(map.lastKey()); //f
System.out.println(map.lowerKey("f")); //e
System.out.println(map.higherKey("a")); //b
}
4、IdentityHashMap
IdentityHashMap的数据结构为数组
IdentityHashMap可以保存”相同”的key,这里的相同指的是O1.hashCode()==O2.hashCode(),或者O1.equals(O2),为什么呢?
因为IdentityHashMap的hash算法与上述的两个方法无关,我们看看源代码怎么说:
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
/**
* Returns the same hash code for the given object as
* would be returned by the default method hashCode(),
* whether or not the given object's class overrides
* hashCode().
* The hash code for the null reference is zero.
*
* @param x object for which the hashCode is to be calculated
* @return the hashCode
* @since 1.1
* @see Object#hashCode
* @see java.util.Objects#hashCode(Object)
*/
@HotSpotIntrinsicCandidate
public static native int identityHashCode(Object x);
//和默认方法的hashCode有关,不管子类是否覆盖都无效可以简单的理解为与对象的内存地址有关,和其他无关,地址一样就是相同的key反之则不相同。
举例子:
public static void main(String[] args) {
Map<String,String> map = new IdentityHashMap<String, String>();
String a = "a";
String b = "a";
String c = new String("a");
map.put(a, "c");
map.put(a, "a");
map.put(b, "b");
map.put(c, "d");
System.out.println(map); //输出{a=d, a=b}
}
5、EnumMap
EnumMap是针对枚举的集合类,其中存储的Key必须为枚举类型。
数据结构为数组,而在数组中的顺序是依赖枚举中定义的顺序,看看它的put代码:
public V put(K key, V value) {
typeCheck(key);
int index = key.ordinal(); //枚举中定义的顺序
Object oldValue = vals[index];
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
}数组的长度是固定的,在其构造时会算出数组的固定长度:
public EnumMap(Class<K> keyType) {
this.keyType = keyType;
keyUniverse = getKeyUniverse(keyType); //获取所有枚举
vals = new Object[keyUniverse.length]; //长度固定
}使用栗子:
public static void main(String[] args) {
EnumMap<Style,String> map = new EnumMap<>(Style.class);
map.put(Style.GREEN, "绿");
map.put(Style.BLUE, "蓝");
map.put(Style.RED, "红");
System.out.println(map);
}
6、WeakHashMap
WeakHashMap是一个特殊的HashMap,它的Entry继承了弱引用类WeakReference,并传入Key作为弱引用,这表名它的每个Entry中的key的存活时间只能到下次GC前。
数据结构为:(数组+链表)
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
final int hash;
Entry<K,V> next;
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
//调用WeakReference的构造,传入Key
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
}那么有一个问题,key被回收了,那Value呢,我们来看看它是怎么做的:
/**
* Returns the table after first expunging stale entries.
*/
private Entry<K,V>[] getTable() { //get|put|remove啥的都会调用到这个方法
expungeStaleEntries(); //去除过期entry
return table;
}
/**
* Expunges stale entries from the table.
*/
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
@SuppressWarnings("unchecked")
//过期对象
Entry<K,V> e = (Entry<K,V>) x;
int i = indexFor(e.hash, table.length);
//定位到Entry
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
//遍历清空
while (p != null) {
Entry<K,V> next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
// Must not null out e.next;
// stale entries may be in use by a HashIterator
e.value = null; // Help GC
size--;
break;
}
prev = p;
p = next;
}
}
}
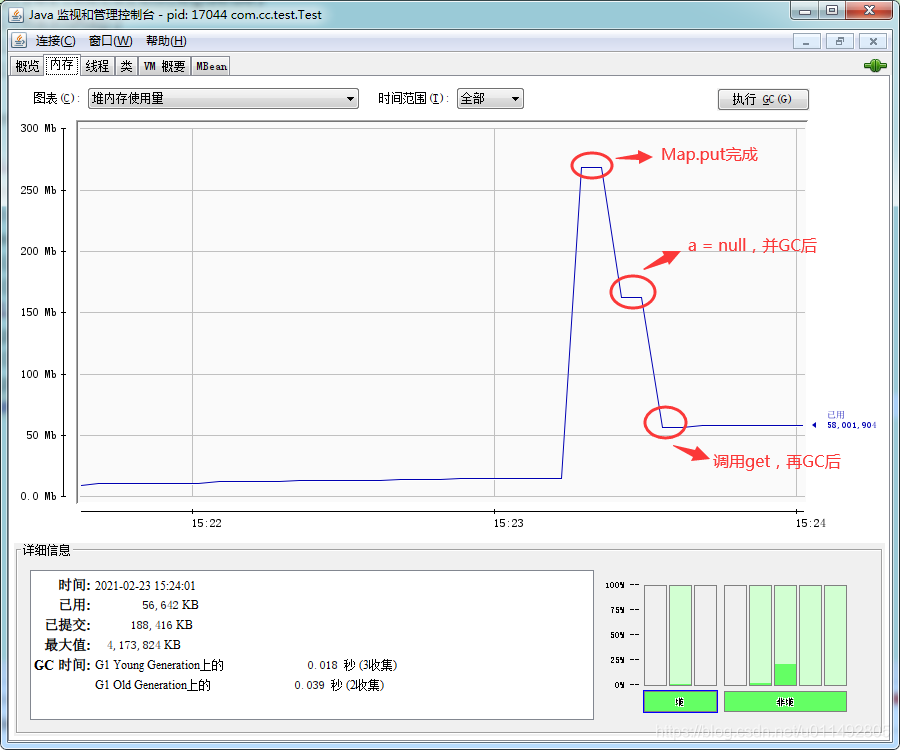
}做个小测试:
public static void main(String[] args) {
byte[] a = new byte[1024*1024*100];
Object b = new Object();
Map<Object,byte[]> map = new WeakHashMap<Object, byte[]>();
map.put(a,new byte[1024*1024*100]);
map.put(b,new byte[1024*1024*50]);
a = null;
System.out.println(map.size()); //2
System.out.println(map); //{[B@7d6f77cc=[B@606d8acf, java.lang.Object@5aaa6d82=[B@782830e}
System.gc();
System.out.println(map.size()); //1
System.out.println(map); //{java.lang.Object@5aaa6d82=[B@782830e}
map.get(b); //触发expungeStaleEntries
System.gc(); //回收掉entry的value
System.out.println(map.size()); //1
System.out.println(map); //{java.lang.Object@5aaa6d82=[B@782830e}
}看一下内存情况:
7、HashTable
HashTable是一个线程安全的集合类,内部的数据结构为(数据+链表)
所有操作都加上了锁来确保线程安全,我们看一下它的默认构造方法:
public Hashtable() {
this(11, 0.75f); //默认容量为11,为什么设置为11?
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
//threshold = 初始*加载因子 或 最大容量+1
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}HashTable的put方法比HashMap来的简单,put时容量不够就扩容
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length; //先与上Integer.MAX_VALUE,确保为正数,然后再取模
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
modCount++;
}
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1; //扩容2倍+1
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// 保持在最大容量值
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) { //循环重新插入元素
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}其他也没什么好看的了,现在HashTable也几乎没人用。
参考文章:
https://blog.csdn.net/liubenlong007/article/details/87937209
https://blog.csdn.net/a724888/article/details/80290276