在了LSTM之前要对循环神经网络RNN有简单的认识!!!
定义:长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
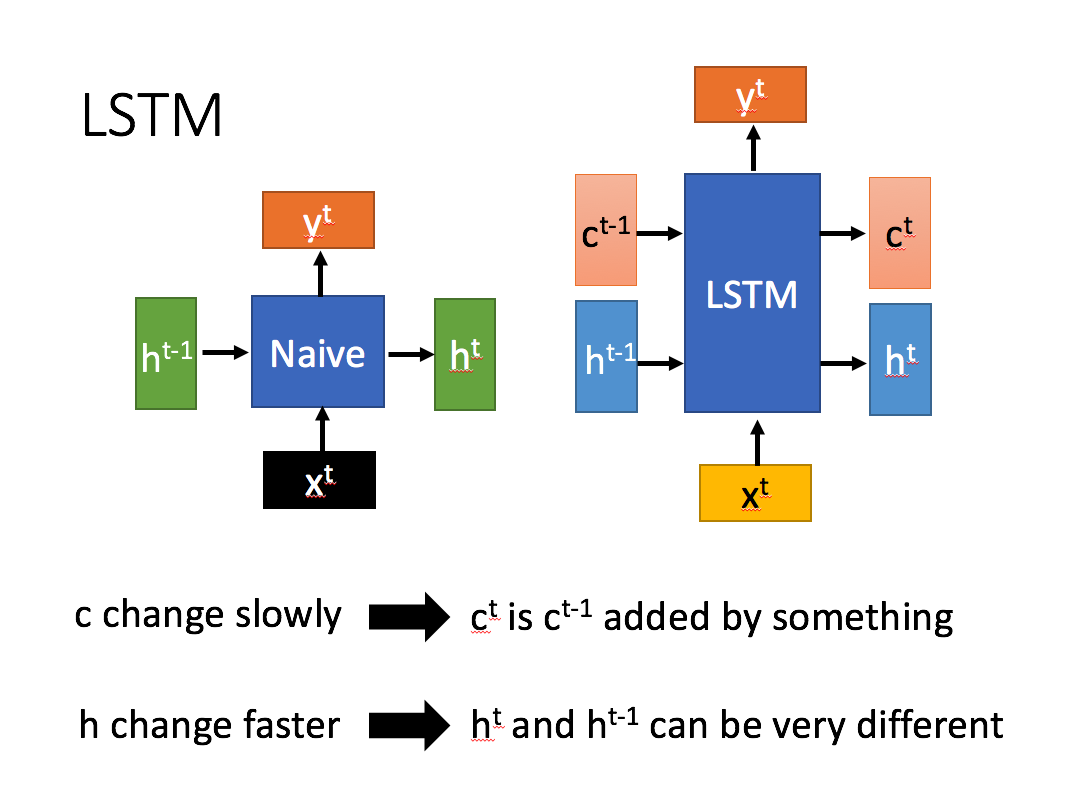
相比RNN只有一个传递状态 h^t ,LSTM有两个传输状态,一个 c^t (cell state),和一个 h^t (hidden state)。(Tips:RNN中的 h^t 对于LSTM中的 c^t )
其中对于传递下去的 c^t 改变得很慢,通常输出的 c^t 是上一个状态传过来的 c^{t-1} 加上一些数值。而 h^t 则在不同节点下往往会有很大的区别。
这是LSTM的运算结构
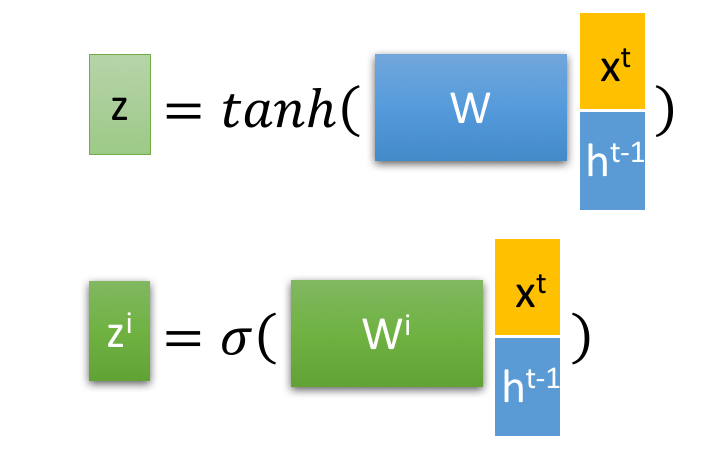
下面是GRU的计算结构
(GRU和LSTM差不多,但是GRU的运算量比LSTM小的多,主要区别之一在于门控状态的计算,LSTM依赖于三个权重,但是GRU只用了一个权重,仔细想一下,其实是一样的,这个过程中没有相关的变量(个人见解,如有错误,请指正))
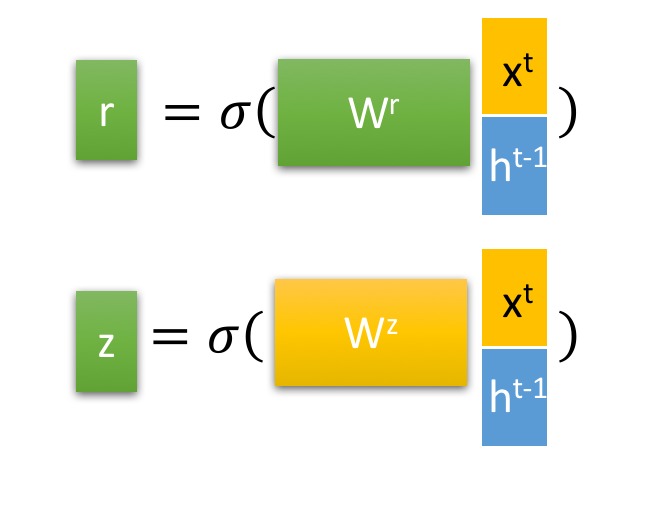
LSTM内部主要有三个阶段:
-
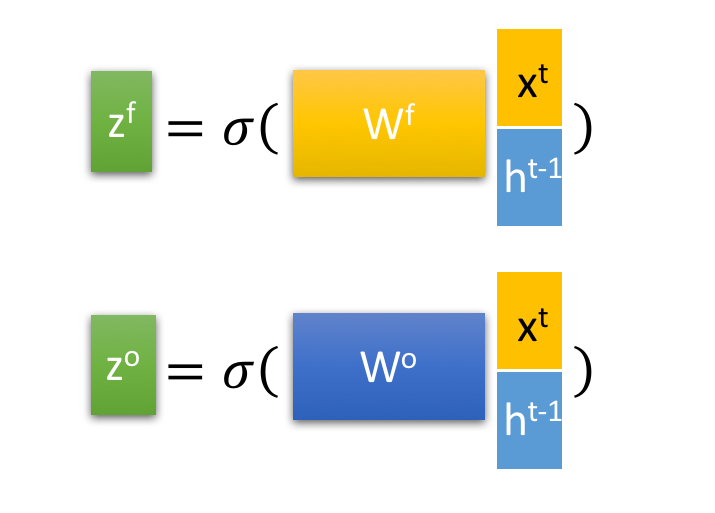
忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。具体来说是通过计算得到的 z^f (f表示forget)来作为忘记门控,来控制上一个状态的 c^{t-1} 哪些需要留哪些需要忘。
-
选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 x^t 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 z 表示。而选择的门控信号则是由 z^i (i代表information)来进行控制。将上面两步得到的结果相加,即可得到传输给下一个状态的 c^t 。也就是上图中的第一个公式。
-
输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 z^o 来进行控制的。并且还对上一阶段得到的 c^o 进行了放缩(通过一个tanh激活函数进行变化)。与普通RNN类似,输出 y^t 往往最终也是通过 h^t 变化得到。
这篇文章的思路可以为显著性检测提供思路,暂时没有想到““““““
LSTM的主要优点是迭代删除无关信息,并通过更新内存单元来学习强大的表示。这一点可以为以后打开思路