GRU介绍
上篇文章提到了
RNN(循环神经网络)
的变体
LSTM(长短期记忆网络)
,现在说一下它们的另一个变体GRU(Gate Recurrent Unit)——门控循环单元。虽然LSTM能够解决循环神经网络因长期依赖带来的梯度消失和梯度爆炸问题,但是在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值,参数较多,训练起来比较困难。而在GRU模型中只有两个门:分别是更新门和重置门,且在超参数全部调优的情况下,二者性能相当,GRU结构更为简单,训练样本较少,易实现。
GRU的结构
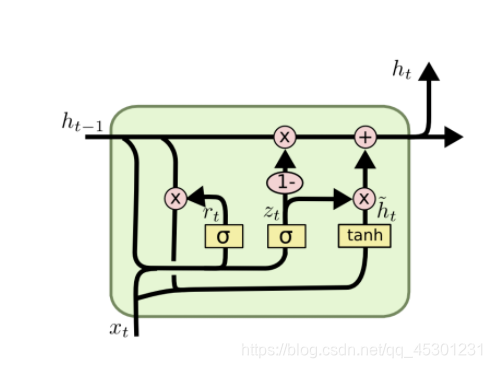
图中的zt和rt分别表示更新门和重置门。
GRU的前向传播
根据GRU的模型结构图,我们来看一下GRU的前向传播公式:
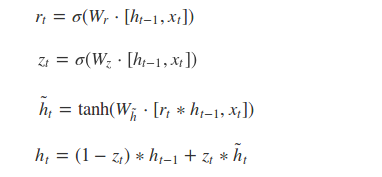
(1)更新门Zt :更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多, 将前一时刻和当前时刻的信息分别右乘权重矩阵,然后相加后的数据送入更新门,也就是与sigmoid函数相乘,得出的数值在[0, 1]之间。
(2)重置门rt:控制前一状态有多少历史信息被写入到当前的候选集 h~t 上,重置门越小,前一状态的信息被写入的越少,同更新门的数据处理一样,将前一时刻和当前时刻的信息分别右乘权重矩阵,然后相加后的数据送入重置门,也就是与sigmoid函数相乘,得出的数值在[0, 1]之间。只是两次的权重矩阵的数值和用处不同。
GRU直接使用更新门来控制输入和遗忘的平衡,而LSTM中输入门和遗忘门相比GRU就具有一定的冗余性了。