
一、背景
公司的注册信息里没有用户性别这一项,但是我们的场景算是电商,如果知道用户的性别,对用户的商品推荐及排序都会比较重要,产品体验会更好
二、大致思路
参考现有的数据,一种是用户的维度数据,比如用户使用的手机型号,用户装的app(会有很多维的数据),用户是不是活动来的(我们平台的拉新活动),另一种是用户在app上的行为,比如用户浏览的商品的价格,用户选择的尺码,用户关注的商品的配色等,选这些完全是基于对业务的理解。
维度数据的好处是不会变化,且在新用户来的时候就能判断出来性别,能够实现实时计算,且数据比较完整,先用维度数据做,效果不好再结合用户行为数据一起做。
模型选择,最先想到的就是树模型,主观上觉得随机森林和GBDT应该是第一选择,其次LR,SVM都可以试下,觉得结果应该是差不多的
三、数据处理
我的原始数据都存在hive,数据基本都是string类型,其实用户装的app是个字符串存的,用户的手机型号也是字符串,然后就是case when先把手机型号存成1-20这样子,比如华为1,苹果2,树模型对数字大小不是很敏感,用户装的机型太少的就都标记为其他,然后是用户装的app,取出来用户整体装的app降序,选大概1000个,再加上用户是否参加活动,这样数据就有1002维了。
开始想的是直接喂给模型跑,就直接跑了小,效果贼差(这和决策树的投票有关系),主要是测试数据(微信登录的用户的性别)的男女比例差距太大,我们平台男性用户太多了,后面就改成1:1的关系;还有用户装的app我没做删减,比如微信,几乎所有的用户都装了,这个特征就没啥用,然后整体算下app男性女性的占比,然后整体排名100多的app只有10%用户装了,所以之后的特征也先去掉,这样删减完我还剩72个特征。
四、算法测试
由于公司买了阿里的pai,所以直接就在里面测试了,先出结果,可行了再自己写代码(主要我写的不怎么样)。
pai的流程还是很简单,和自己写代码差不多,先分测试数据和预测数据,训练模型,预测结果,看结果好坏,直接训练3个模型,流程如下:
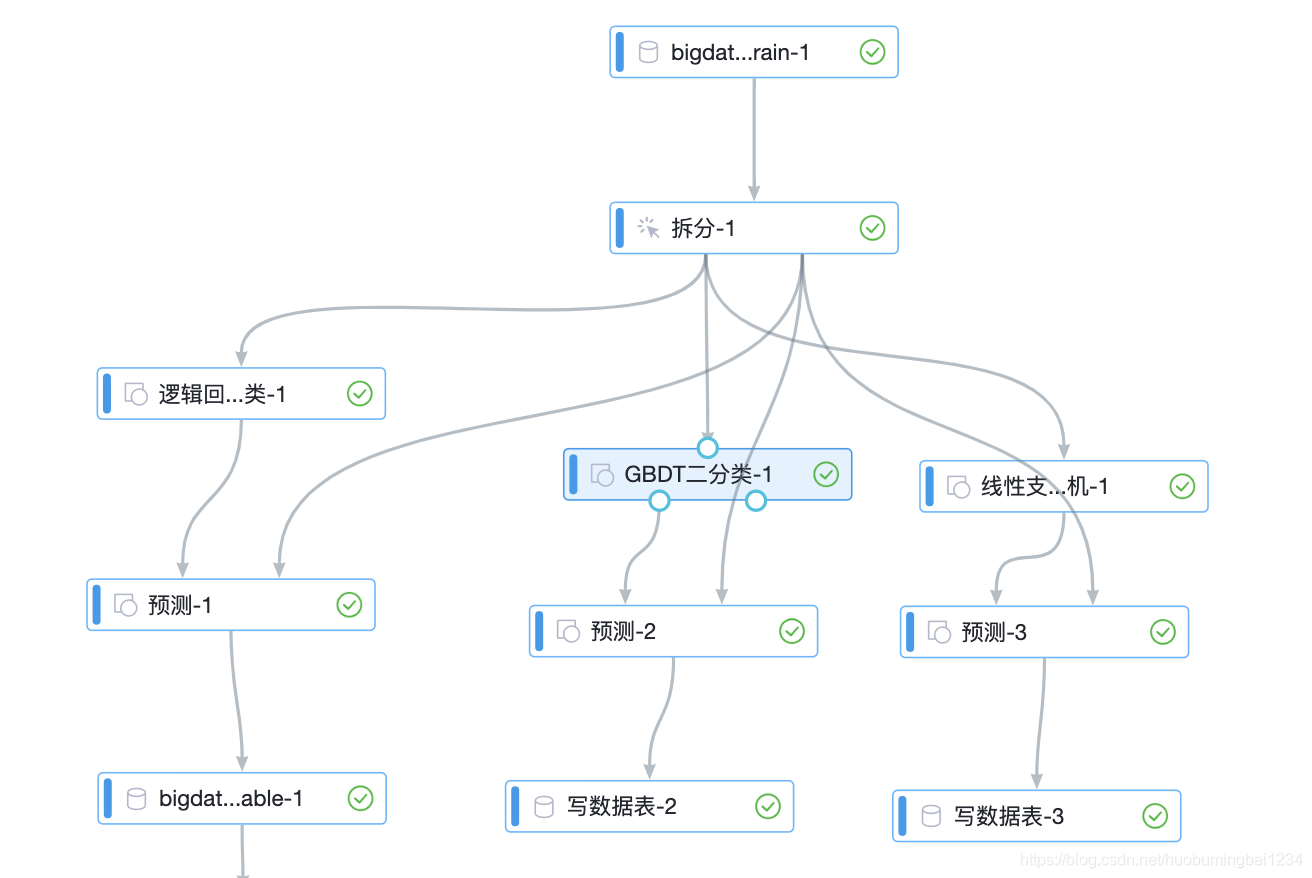
结果会自动写回hive,这个训练的模型也行直接在线部署,每天批任务预测下,同时也可以输出PMML。
最后的结果:

看男女的预测结果,三种算法准确率都在80%左右,即使用volting,提升的结果几乎就是0.1个百分点
五、总结
三种策略下结果没大的变化,,想要提升需要找更多的特征。