目录

TCmalloc简介
TCMalloc 是 Google 自定义的 c 的 malloc () 和 c + + 操作符 new 的实现,用于 c 和 c + + 代码中的内存分配。TCMalloc 将 c 的 malloc () 和 c + + 操作符 new 的内部实现替换为 TCMalloc 的实现,开发者只需编译链接 TCMalloc 的静态库或动态库即可,无需改动任何与内存分配有关的代码。
TCMalloc 通常被用于提高内存分配的性能,实现了高效的内存管理。在与glibc中的内存分配器
ptmalloc2
作比较:
- tcmalloc分配一次内存的时间更快
- tcmalloc优化了对小对象的存储,需要更少的空间
- tcmalloc特别在多线程方面做了优化,一方面是对于小对象(<32k)的分配基本不存在锁,内存资源竞争,另一方面是对大对象(>=32k)使用了细粒度、高效的自旋锁。
- tcmalloc分配给本地线程的内存资源,在长时间空闲的情况下会被回收,供其他线程使用,提高了多线程时内存利用率,不会浪费内存,这一点ptmalloc2无法做到。
粒度解释:“粒度”表示的是精确程度问题。粗粒度角度描述一个系统,是关注系统中大的组件;细粒度角度描述一个系统是从组成大组件的小组件,或者更小组件的角度认识系统。
“粒度”此处是用来描述一个系统,或者对比多个系统的术语,它是一个相对的概念。
说明:glibc是
GNU
发布的libc库,即c
运行库
。glibc是
linux系统
中最底层的
api
,几乎其它任何运行库都会依赖于glibc。glibc除了封装
linux
操作系统所提供的
系统服务
外,它本身也提供了许多其它一些必要功能服务的实现。由于 glibc 囊括了几乎所有的
UNIX
通行的标准,可以想见其内容包罗万象。而就像其他的 UNIX 系统一样,其内含的档案群分散于系统的树状
目录结构
中,像一个支架一般撑起整个操作系统。在 GNU/Linux 系统中,其C函式库发展史点出了GNU/Linux 演进的几个重要里程碑,用 glibc 作为系统的C函式库,是GNU/Linux演进的一个重要里程碑。(参考于
glibc 简介: – the_tops – 博客园 (cnblogs.com)
)
TCMalloc内部结构
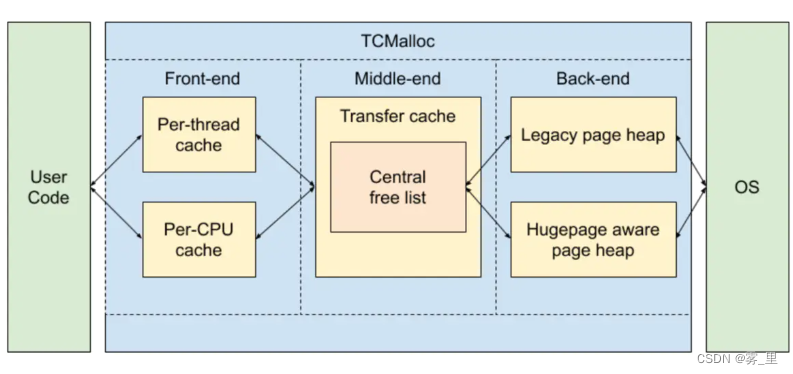
- front-end :front-end 是一个缓存,它为应用程序提供内存的快速分配和释放。
- middle-end :middle-end 负责为 front-end 填充或回收缓存。
- back-end : back-end 负责从 OS 获取或释放内存。
TCMalloc 的工作模式
- tcmalloc会为每个线程分配本地缓存,小对象请求可以直接从本地缓存获取,如果没有空闲内存,则从central heap中一次性获取一连串小对象。
- tcmalloc对于小内存,按8的整数次倍分配,对于大内存,按4K的整数次倍分配。
- 当某个线程缓存中所有对象的总大小超过2MB的时候,会进行垃圾收集。垃圾收集阈值会自动根据线程数量的增加而减少,这样就不会因为程序有大量线程而过度浪费内存。

图1: Page和Span的关系
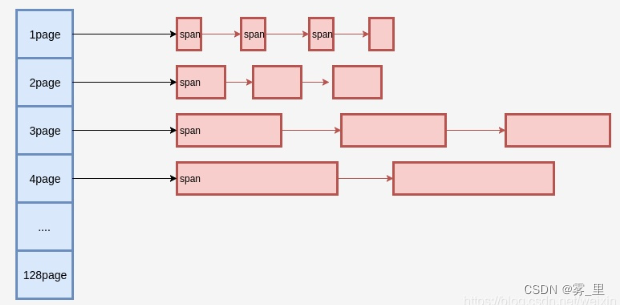
图2:通过PageMap实现Page到Span的映射\通过伙伴系统,实现了Span的分裂与合并
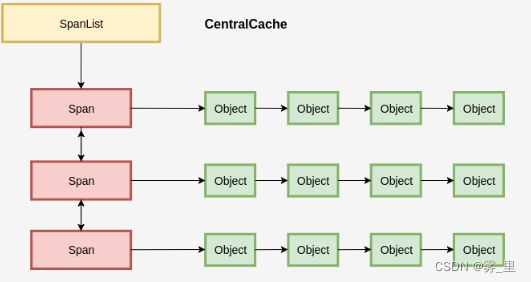
图3:每种规则的对象,都有一个CentralCache、向PageHeap申请Span,为用户分配对象
每种规则的对象都有一个独立的内存分配单元:
CentralCache
。在一个CentralCache内存,我们用链表把所有的Span组织起来,每次需要分配时就找一个Span从中分配一个Object;当没有空闲的Span时,就从PageHeap申请Span。
但是多线程情景,大家都在
CentralCache
分配资源,就会出现竞争。
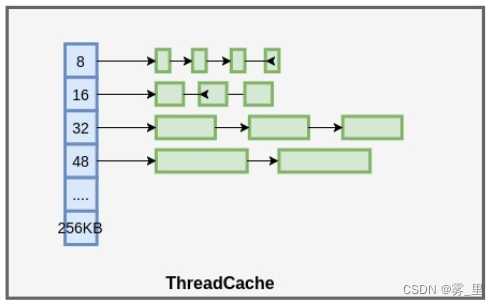
每一个线程都有一个局部的
ThreadCache,
如果
ThreadCache
不够了,就在
CentralCache
集中分配,如果
CentralCache
中依然没有内存可分配,就在
PageHeap
中申请
Span
,如果
PageHeap
没有合适的
Page
可以申请
Span
,就在操作系统中申请。
释放内存时,
ThreadCache
遵循着批量释放的原则,当对象积累到一定程度就释放上一层
CentralCache
;当
CentralCache
发现一个
Span
的内存完全释放了,就将这个
Span
归还给
PageHeap
;
PageHeap
发现一批连续的
Page
都释放了,就归还给操作系统了。
tcmalloc申请内存流程
- 首先根据申请空间的大小从当前线程的可用内存块里面找(每个进程维护一组链表,每个链表代表一定大小的可用空间)
-
.分配对象时,大的对象直接分配给Span,小的对象从Span中分配object

- . 如果没找到,就到central list里面查找(central list跟线程各自维护的list结构很像,为不同的size各自维护一组可用空间列表)
- 如果scentral list也没有找到,则计算分配size个字节需要分配多少page(变量:class_to_pages)
- 根据pagemap查找page对应的可用的span列表,如果找到了,则直接返回span,central list会将该span切割成合适的大小放入对应的列表中,然后交给thread cache
- 如果没有找到可用的span,则向OS直接申请,然后步骤同step 5。
page管理:
伙伴系统:合并相邻的page,减少外部碎片
内存申请:分裂Span
内存释放:合并Span
tcmalloc释放内存流程
1. 释放某个object
2. 找到该object所在的span
3. 如果该span中所有object都被释放,则释放该span到对应的可用列表,在释放的过程中,尝试将该span跟左右spans merge成更大的span
4. 如果当前thread cache的free 空间大于指定预置,归还部分空间给central list
5. central list也会试图通过释放可用span列表的最后几个span来将不用的空间归还给OS
tcmalloc向OS申请/释放资源是以span为单位的。
注意:tcmalloc向系统申请空间有三种方式:
sbrk,mmap,/dev/mem文件
,默认是三种都可以的,一种不行换另外一种。注:大对象直接使用页级分配器(一个页是一个4K的对齐内存区域)从中央堆直接分配。