简介
蒸馏算法分为多种,基于特征、logit以及基于关系的三种
1 logit蒸馏
1.1 开山之作
论文名称:Distilling the Knowledge in a Neural Network Hilton 2015
提出了标签温度的概念,温度T越高,标签越soft

具体步骤:
1)在T=1时训练教师网络
2)在高温下用teancher softmax输出的概率作为soft label,与GT的hard label进行融合训练

hard损失使用交叉熵损失,soft损失使用KL散度损失,二者都是衡量两个分布间差异的函数,但是KL散度能保证soft label下的loss为零,交叉熵计算简单,适用于one-hot标签(具体可参考公式)
2 特征蒸馏
在深度卷积神经网络中,网络学习到的知识是分层的,从浅到深层对应的知识抽象程度越来越高。因此中间层的特征也可以作为知识的载体,供学生网络进行学习。基于特征的知识迁移可以建模为:
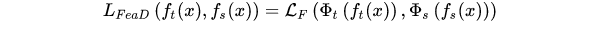
其中FAI表示一个转换函数,因为教师网络和学生网络的特征层可能出现尺寸不匹配的情况,所以需要转换。LF表示用于匹配教师网络和学生网络的相似度计算函数,特征计算
一般而言,在基于特征的知识迁移中,研究的对象包括了:
如何需选择知识类型?特征图、注意力图、gram矩阵或其他
如何选择教师层和学生层?简单的一对一匹配,自适应通过注意力匹配。
如何弥补教师网络与学生网络之间的GAP
?如果容量相差过大,可能会导致学习效果变差。
2.1 代表论文A Comprehensive Overhaul of Feature Distillation
以fastreid代码为例,在reid中试验resnet50蒸馏,resnet18,resnet50是训练好的网络,主要是训练18,训练18的时候,除了正常的loss外,还有个蒸馏的loss,就是两个网络特征间的差异loss(L2loss或mseloss),训练过程中50仅用来推理,取特定层的特征。Res网络都有四次降采样的大模块,在每个降采样的模块中BN之后,relu之前把特征取出来,学生网络即18,要把对应的relu换成margin relu,为了更好的学习特征,并且舍弃学习一些没意义的负值。
模型剪枝
利用BN层 Network Slimming-Learning Efficient Convolutional Networks through Network Slimming
主要思路
1、利用batch normalization中的缩放因子γ 作为重要性因子,即γ越小,所对应的channel不太重要,就可以裁剪(pruning)。
2、约束γ的大小,在目标方程中增加一个关于γ的L1正则项,使其稀疏化,这样可以做到在训练中自动剪枝
参考链接
添加链接描述