?????
更多资源链接,欢迎访问作者gitee仓库:
https://gitee.com/fanggaolei/learning-notes-warehouse/tree/master
1.什么是分流?
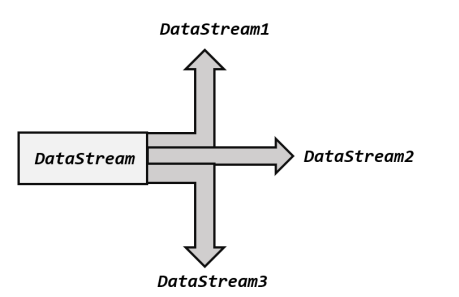
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流
。也就是基于一个DataStream,得到完全平等的多个子 DataStream。一般来说,我们会定义一些筛选条件,
将符合条件的数据拣选出来放到对应的流里
。
2. 过滤器(filter)
其实根据条件筛选数据的需求,本身非常容易实现:只要针对同一条流多次独立调用.filter()方法进行筛选,就可以得到拆分之后的流了。
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env
.addSource(new ClickSource());
// 筛选Mary的浏览行为放入MaryStream流中
DataStream<Event> MaryStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Mary");
}
});
// 筛选Bob的购买行为放入BobStream流中
DataStream<Event> BobStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Bob");
}
});
// 筛选其他人的浏览行为放入elseStream流中
DataStream<Event> elseStream = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return !value.user.equals("Mary") && !value.user.equals("Bob") ;
}
});
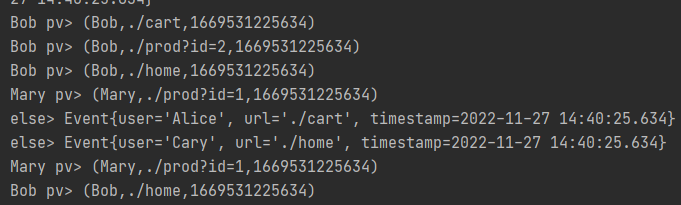
MaryStream.print("Mary pv");
BobStream.print("Bob pv");
elseStream.print("else pv");
env.execute();
}
}

这种实现非常简单,但代码显得有些冗余——我们的处理逻辑对拆分出的三条流其实是一样的,却重复写了三次。而且这段代码背后的含义,是将原始数据流 stream 复制三份,然后对每一份分别做筛选;这明显是不够高效的。
3. 使用侧输出流(SideOutput)
在 Flink 1.13 版本中,已经弃用了.split()方法,取而代之的是直接用处理函数(process function)的侧输出流(side output)。
我们知道,处理函数本身可以认为是一个转换算子,它的输出类型是单一的,处理之后得到的仍然是一个 DataStream;
而侧输出流则不受限制,可以任意自定义输出数据,它们就像从“主流”上分叉出的“支流”。尽管看起来主流和支流有所区别,不过实际上它们都是某种类型的 DataStream,所以本质上还是平等的。
利用侧输出流就可以很方便地实现分流操作,而且得到的多条 DataStream 类型可以不同,这就给我们的应用带来了极大的便利
import com.atguigu.chapter05.ClickSource;
import com.atguigu.chapter05.Event;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class SplitStreamByOutputTag {
// 定义输出标签,侧输出流的数据类型为三元组(user, url, timestamp)
private static OutputTag<Tuple3<String, String, Long>> MaryTag = new OutputTag<Tuple3<String, String, Long>>("Mary-pv"){};
private static OutputTag<Tuple3<String, String, Long>> BobTag = new OutputTag<Tuple3<String, String, Long>>("Bob-pv"){};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env
.addSource(new ClickSource());
SingleOutputStreamOperator<Event> processedStream = stream.process(new ProcessFunction<Event, Event>() {
@Override
public void processElement(Event value, Context ctx, Collector<Event> out) throws Exception {
if (value.user.equals("Mary")){
ctx.output(MaryTag, new Tuple3<>(value.user, value.url, value.timestamp));
} else if (value.user.equals("Bob")){
ctx.output(BobTag, new Tuple3<>(value.user, value.url, value.timestamp));
} else {
out.collect(value);
}
}
});
processedStream.getSideOutput(MaryTag).print("Mary pv");
processedStream.getSideOutput(BobTag).print("Bob pv");
processedStream.print("else");
env.execute();
}
}