1、何为计算
“计算”一词对我们来讲并不陌生,如并行计算、分布式计算、云计算……,前面都是修饰词,关键词是计算。为什么google能提出map-reduce分布式计算框架呢,本文就以自己的理解和感想,去解读”计算”一词。
“计算”存在学习和生活中,一直伴随着我们,如应用计算题,有很多条件,计算路径有多远、花了多少钱……,这些现象本质后面有一个共同点:
凡是可计算的前提是事物之间存在某种关系
,如何来理解这句话呢?比如小明有3本书,小李有2本书,求他们共有多少本书,很明显是5本,两者相加就ok;但如果小李有1本书,小王有1个手机,这就不好计算了。所以计算是有前提的,事物之间存在某种关系。
既然可计算的前提是事物之间存在某种关系,那么不禁发问了,这种关系是什么呢?如何去找到这个关系呢?这是一个非常好的问题,其实我们解决可计算的问题,也一直围绕这两点来思考的。为了探寻这个问题,不妨回想一下数学,数学是最好体现计算的,我们学数学,也一直在计算中,计算数值和、计算面积、计算极值……,这所有又会发现有一个共同点:
计算是按种某种规则来进行的
,这种规则或者是关系就是计算公式,在解决实际复杂问题时,有人称之为数学建模,可以看到数学建模一般是方程式的集合,方程式可以看作是一种公式。
上面讲了两段,提到了两个观点:一个是
凡是可计算的前提是事物之间存在某种关系
,另一个是
计算关系体现在某种运算规则上
。我之前的老师,和我谈到一个观点:
人是怎么想的,计算机就是怎么做的,因为计算机是人设计的
,这也好理解,这也是为什么在实践之前都要把整个设计想明白,当你没有想清楚,写的程序代码也不会很完善,因为机器是按照你的指令去执行。
那人又是怎么想的呢?
,大部分人都有这种的一种不知不觉的思绪方式:
分类
。我们在看到一个新事物时,喜欢与之前见过的事物进行类比,两者之间有没有关联关系,这些是为什么说面向对象是按照人的思想去设计的,一个个的类都体现了认识,通过关联关系进行组合,形成整体结构。
解决问题,不管是计算问题,还是其它的问题,都是遵循
由已知的抽象推导未知的抽象
。推导的过程就是建立关联关系的过程,只有先找到了这种关联关系,才能做后续的具体的操作。
好了,上面进行了一堆的铺垫,主题就要出来了,用下面的一张来表示。
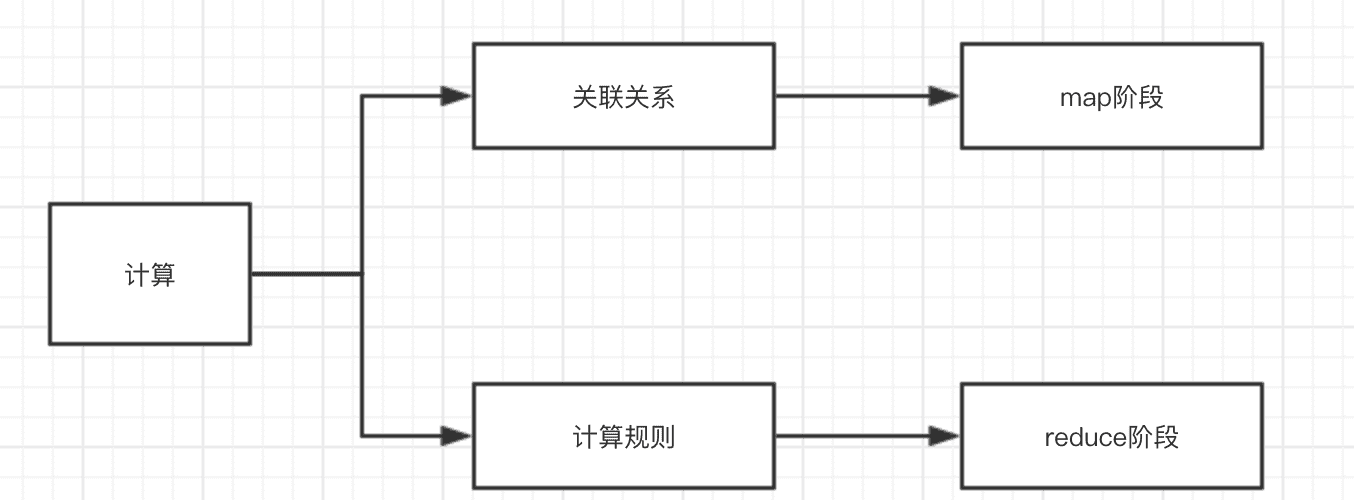
接下来就讲讲大数据计算的特点,为什么map-reduce这么固定的模式在里面。
2、大数据计算
现在提到大数据计算,如hadoop、spark、storm等,不管何种分布式计算,它们存在一些共同的特征。大数据计算存在几个特征:
- 数据的离散价值低,但挖掘价值高
- 数据之间的关联关系弱,所以可以并行处理,如果彼此存在关系,很难并行处理
- 数据量大,但可拆分
大数据计算的本质是:
分而治之+蛮力计算+移动计算而不是数据
,这三点基本上概括了分布式计算的内涵,下面分点说明。
-
分而治之
:对于大数据量的而言,分而治之是不二法宝,单台机器能力有限,人多力量大。 -
蛮力计算
:计算机永远不知疲惫地干活,不会觉得累,数据量大,计算机往往是按照规则一条条数据进行处理运算,所以叫它”蛮力计算”,正是这种简单、机械的干活,如果发现运算能力低,那就再加机器呗。 -
移动计算而不是数据
:数据一般很大,计算的代码往往不大,几M的代码量已经很吓人了。
现有的分布式计算框架,都体现了单一职责的特点,将资源调度和任务调度分离开来了,这种职责就更清晰了。
现有的分布式计算框架帮我们做了的事,让我们更关注业务逻辑:
- 容错处理:出现错误了能够进行错误转移
- 节点资源分配:任务节点资源分配&管理
- 任务调度:任务启动&管理
- 节点前后依赖关系:主要体现在shuffle
- ……
3、总结
本文主要探寻为什么map-reduce能解决分布式计算的原理,发现计算有两个阶段:找关联关系+具体处理,map、reduce对应上面两个阶段,掌握好了本质,再去学习分布式计算,会达到事半功倍的效果。