转自:
计算机视觉方向简介 | 深度相机室内实时稠密三维重建 – 知乎
室内场景的稠密三维重建目前是一个非常热的研究领域,其目的是使用消费级相机(本文特指深度相机)对室内场景进行扫描,自动生成一个精确完整的三维模型,这里所说的室内可以是一个区域,一个房间,甚至是一整栋房屋。此外,该领域注重(一般是GPU上)实时重建,也就是一边扫描就可以一边查看当前重建的结果。如下所示。

主要的应用包括室内的增强现实游戏、机器人室内导航、AR家具展示等。

什么原理?
在介绍原理前,先简单了解一下历史发展。
1、发展历史
在消费级深度相机出现之前,想要采用普通相机实现实时稠密三维重建比较困难。微软2010年发布了Kinect之后,基于深度相机的稠密三维重建掀起了研究热潮。早期比较有代表性的工作是2011年微软的Newcombe(单目稠密重建算法DTAM 的作者)、Davison等大牛发表在SIGGRAPH上的KinectFusion算法,算是该领域的开山之作。KinectFusion算法首次实现了基于廉价消费类相机的实时刚体重建,在当时是非常有影响力的工作,它极大的推动了实时稠密三维重建的商业化进程。下图所示是几款消费级深度相机。

KinectFusion之后,陆续出现了Kintinuous,ElasticFusion,InfiniTAM,BundleFusion等非常优秀的工作。其中2017年斯坦福大学提出的BundleFusion算法,可以说是目前基于RGB-D相机进行稠密三维重建效果最好的方法了。本文主要以该算法为基础进行介绍。值得一提的是,目前室内三维重建和语意理解结合的研究越来越多,这方面暂不做介绍。
2、基本原理
BundleFusion是目前效果最好的开源算法框架,其概览图如下所示。
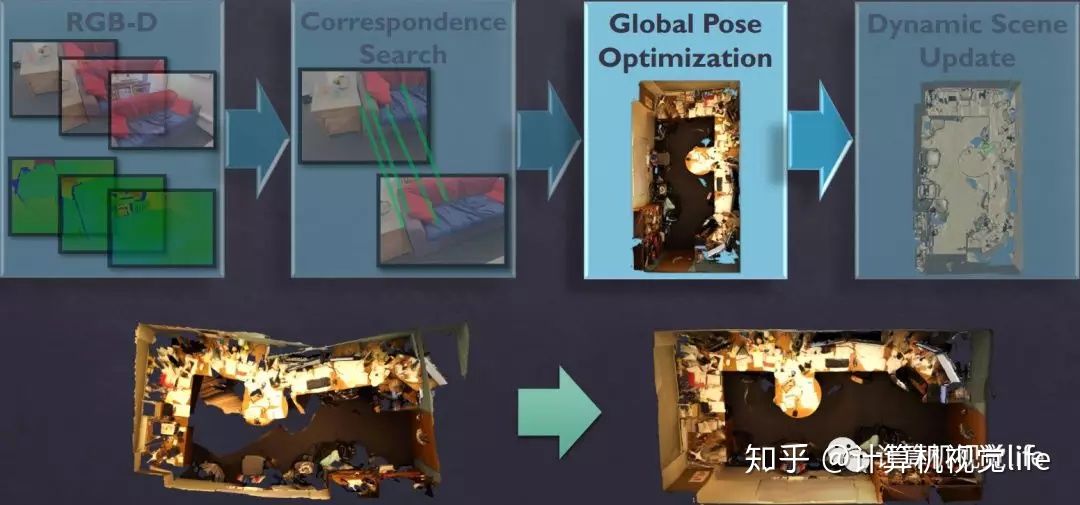
我们先来看一下输入输出是什么。
- 输入:RGB-D相机采集的对齐好的color+depth的数据流,这里使用的是structure sensor+iPad输出的30Hz,分辨率为640×480的序列图像。
- 输出:重建好的三维场景。
输入的color+depth的数据流首先需要做帧与帧之间的对应关系匹配,然后做全局位姿优化,将整体的漂移校正过来(上图下方所示),整个重建过程中模型是在不断动态更新的。
上面只是一个概括的介绍,我们深入看一下。算法具体流程图如下:
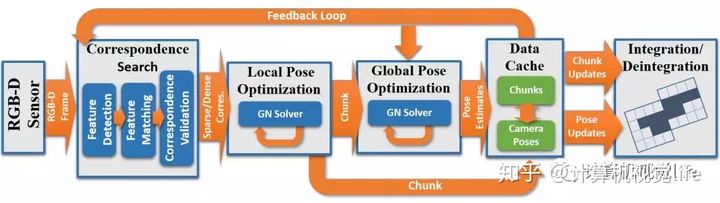
虽然看起来很复杂,其实思想还是非常直观的。下面分别介绍一下。
在匹配方面,这里使用的是一种sparse-then-dense的并行全局优化方法。也就是说,先使用稀疏的SIFT特征点来进行比较粗糙的配准,因为稀疏特征点本身就可以用来做loop closure检测和relocalization。然后使用稠密的几何和光度连续性进行更加细致的配准。下图展示了sparse+dense这种方式和单纯sparse的对比结果。

在位姿优化方面。这里使用了一种分层的 local-to-global 的优化方法,如下图所示。总共分为两层,在最低的第一层,每连续10帧组成一个chunk,第一帧作为关键帧,然后对这个chunk内所有帧做一个局部位姿优化。在第二层,只使用所有的chunk的关键帧进行互相关联然后进行全局优化。为什么要分层这么麻烦呢?或者说这样分层有什么好处呢?因为可以剥离出关键帧,减少存储和待处理的数据。并且这种分层优化方法减少了每次优化时的未知量,保证该方法可扩展到大场景而漂移很小。

在稠密场景重建方面。一个关键的点在于模型的对称型更新:若要增加更新的一帧估计,需先去掉旧的一帧,然后在新的位姿处重新整合。这样理论上来说,随着帧越来越多,模型会越来越精确。
作为纯视觉的算法,其鲁棒性非常重要,因此该算法在特征匹配对筛选方面还是做了不少工作。特征点对需要经历如下三种考验才能通关:
第一种是直接对关键点本身分布的一致性和稳定性进行考验。如下图所示,绿色部分才是符合一致性的对应关系。

第二道关卡是对特征匹配对跨越的表面面积进行考验,去掉特别小的,因为跨越面积较小的的话很容易产生歧义。第三道关卡是进行稠密的双边几何和光度验证,去掉重投影误差较大的匹配对。如下图所示两个同样的显示屏导致了左右的错误匹配,是通不过这道关卡的。

此外在chunk内外如何进行局部和全局的处理,以及具体的位姿优化能量函数方面的细节就不介绍了,可以参考文末给出的论文和代码。