在使用sparkStreaming任务实时加载机器学习CTR模型并做实时预测时,调用transform方法抛出java.util.NoSuchElementException: next on empty iterator异常。
...
//加载模型
val model =PipelineModel.load("/user/hdfs/model/LRmodel")
dataStream.foreachRDD(rdd => {
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
val dataFrame = rdd.toDF()
val prediction = model.transform(dataFrame)
...
})
任务运行后,抛出异常
ERROR JobScheduler JobScheduler: Error running job streaming job
java.util.NoSuchElementException: next on empty iterator
at scala.collection.Iterator$$anon$2.next(Iterator.scala:39)
at scala.collection.Iterator$$anon$2.next(Iterator.scala:37)
at scala.collection.IndexedSeqLike$Elements.next(IndexedSeqLike.scala:63)
at scala.collection.IterableLike$class.head(IterableLike.scala:107)
at scala.collection.mutable.ArrayOps$ofRef.scala$collection$IndexedSeqOptimized$$super$head(ArrayOps.scala:186)
at scala.collection.IndexedSeqOptimized$class.head(IndexedSeqOptimized.scala:126)
at scala.collection.mutable.ArrayOps$ofRef.head(ArrayOps.scala:186)
at org.apache.spark.sql.Dataset.head(Dataset.scala:2502)
at org.apache.spark.sql.Dataset.first(Dataset.scala:2509)
at org.apache.spark.ml.feature.VectorAssembler.first$lzycompute$1(VectorAssembler.scala:57)
at org.apache.spark.ml.feature.VectorAssembler.org$apache$spark$ml$feature$VectorAssembler$$first$1(VectorAssembler.scala:57)
at org.apache.spark.ml.feature.VectorAssembler$$anonfun$2$$anonfun$1.apply$mcI$sp(VectorAssembler.scala:88)
at org.apache.spark.ml.feature.VectorAssembler$$anonfun$2$$anonfun$1.apply(VectorAssembler.scala:88)
at org.apache.spark.ml.feature.VectorAssembler$$anonfun$2$$anonfun$1.apply(VectorAssembler.scala:88)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.ml.feature.VectorAssembler$$anonfun$2.apply(VectorAssembler.scala:88)
at org.apache.spark.ml.feature.VectorAssembler$$anonfun$2.apply(VectorAssembler.scala:58)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.TraversableLike$$anonfun$flatMap$1.apply(TraversableLike.scala:241)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.flatMap(TraversableLike.scala:241)
at scala.collection.mutable.ArrayOps$ofRef.flatMap(ArrayOps.scala:186)
at org.apache.spark.ml.feature.VectorAssembler.transform(VectorAssembler.scala:58)
at org.apache.spark.ml.PipelineModel$$anonfun$transform$1.apply(Pipeline.scala:306)
at org.apache.spark.ml.PipelineModel$$anonfun$transform$1.apply(Pipeline.scala:306)
at scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:57)
at scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:66)
at scala.collection.mutable.ArrayOps$ofRef.foldLeft(ArrayOps.scala:186)
at org.apache.spark.ml.PipelineModel.transform(Pipeline.scala:306)
首先定位到问题出现在org.apache.spark.ml.feature.VectorAssembler.first方法,可是我们之前的模型也调用过该方法,并没有报错,所以查看该方法的源码,发现first方法是lazy方法,只有当真正调用时才被加载。
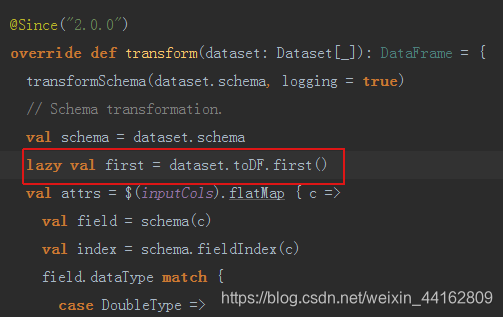
而只有当入参dataSet的字段类型存在Vector且非自定义时才会加载DataSet.first方法,而恰好本次我们传入的字段中有一个特征的类型为Vector。
进一步分析,first方法抛出next on empty iterator表示入参dataSet为空, 而我们使用的是实时任务加载模型,所以会存在数据流为空情况,那么dataframe也就为空了,所以问题就迎刃而解了,只需当dataframe不为空时再调用transform预测即可避免该异常了。
...
//加载模型
val model =PipelineModel.load("/user/hdfs/model/LRmodel")
dataStream.foreachRDD(rdd => {
val sqlContext = SQLContext.getOrCreate(rdd.sparkContext)
import sqlContext.implicits._
val dataFrame = rdd.toDF()
if(dataFrame.collect().length > 0){
val prediction = model.transform(dataFrame)
...
}
val prediction = model.transform(dataFrame)
...
})
附VectorAssembler.transform部分源码
@Since("2.0.0")
override def transform(dataset: Dataset[_]): DataFrame = {
transformSchema(dataset.schema, logging = true)
// Schema transformation.
val schema = dataset.schema
lazy val first = dataset.toDF.first()
val attrs = $(inputCols).flatMap { c =>
val field = schema(c)
val index = schema.fieldIndex(c)
field.dataType match {
case DoubleType =>
val attr = Attribute.fromStructField(field)
// If the input column doesn't have ML attribute, assume numeric.
if (attr == UnresolvedAttribute) {
Some(NumericAttribute.defaultAttr.withName(c))
} else {
Some(attr.withName(c))
}
case _: NumericType | BooleanType =>
// If the input column type is a compatible scalar type, assume numeric.
Some(NumericAttribute.defaultAttr.withName(c))
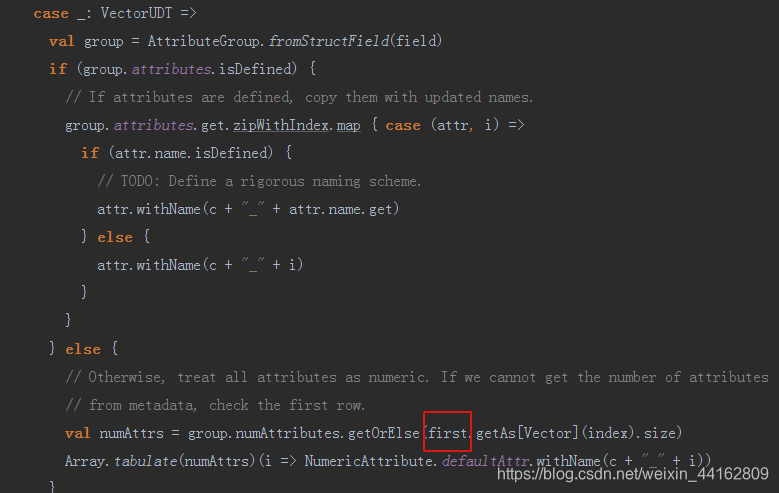
case _: VectorUDT =>
val group = AttributeGroup.fromStructField(field)
if (group.attributes.isDefined) {
// If attributes are defined, copy them with updated names.
group.attributes.get.zipWithIndex.map { case (attr, i) =>
if (attr.name.isDefined) {
// TODO: Define a rigorous naming scheme.
attr.withName(c + "_" + attr.name.get)
} else {
attr.withName(c + "_" + i)
}
}
} else {
// Otherwise, treat all attributes as numeric. If we cannot get the number of attributes
// from metadata, check the first row.
val numAttrs = group.numAttributes.getOrElse(first.getAs[Vector](index).size)
Array.tabulate(numAttrs)(i => NumericAttribute.defaultAttr.withName(c + "_" + i))
}
case otherType =>
throw new SparkException(s"VectorAssembler does not support the $otherType type")
}
}
val metadata = new AttributeGroup($(outputCol), attrs).toMetadata()
// Data transformation.
val assembleFunc = udf { r: Row =>
VectorAssembler.assemble(r.toSeq: _*)
}.asNondeterministic()
val args = $(inputCols).map { c =>
schema(c).dataType match {
case DoubleType => dataset(c)
case _: VectorUDT => dataset(c)
case _: NumericType | BooleanType => dataset(c).cast(DoubleType).as(s"${c}_double_$uid")
}
}
dataset.select(col("*"), assembleFunc(struct(args: _*)).as($(outputCol), metadata))
}
版权声明:本文为weixin_44162809原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。