性能问题分析
性能优化的目标
用户体验 = 产品设计(非技术)+ 系统性能(快)
- 3S定理:页面加载速度超过3s,57%的访客会离开。
- seo排名:速度在google、百度等搜索引擎的PR评分中也占有一定的比例,会影响seo排名。
应用调优方面
-
后端:RT、TPS、并发数、Throughput(吞吐量)、Footprint(埋点)、Latency(延迟)
– TPS和RT受数据库读写、RPC、网络IO、逻辑计算复杂度、JVM - Web端:首屏时间、白屏时间、可交互时间、完全加载时间…
- 移动端:端到端响应时间、Crash率、内存使用率、FPS…
首屏时间 = DNS时间+建立连接时间+后端响应时间+网络传输时间+首屏页面渲染时间
FPS : 是体现页面顺畅程度的一个重要指标。
端到端响应时间 = DNS解析时间+后端响应时间+网络传输时间
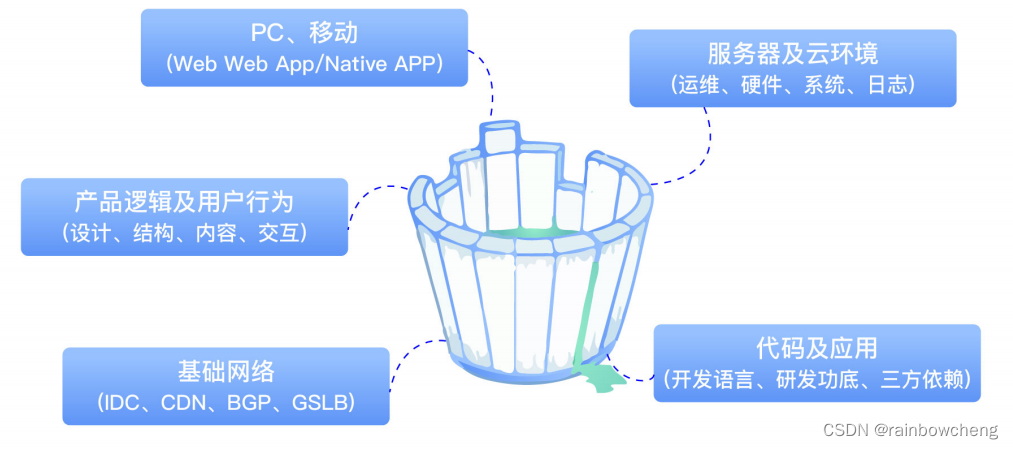
影响性能的关键要素
- 产品设计:产品逻辑、功能交互、动态效果、页面元素
- 基础网络:网络 = 连接介质(光纤、微波) + 计算终端(手机、穿戴设备、家电)
-
代码质量&架构:
- 架构不合理:业务发展超越架构支持能力而导致系统负荷过载,进而导致出现系统奔溃、响应超时等现象。另外不合理的架构:单点、应用混部署、没有考虑分布式、集群化等。
- 研发功底和经验不足:server效率和性能较低、不稳定也是常见的事情
- 没有性能意识:只实现了业务功能不注意代码性能,新功能上线后整体性能下降,或当业务上量后系统出现连锁反应,导致性能问题叠加,直接影响用户体验。
- 多数的性能问题发生在数据库上:由慢SQL、过多查询等原因造成的数据库瓶颈,没有做读写分离、分库分表等
压力测试
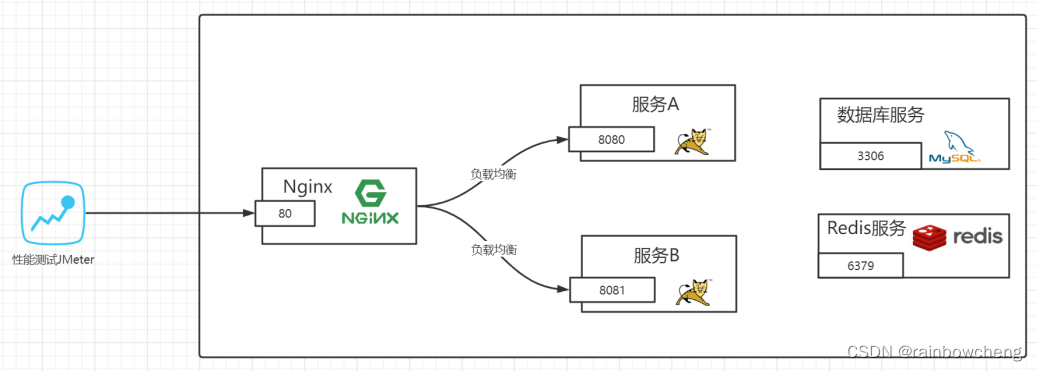
阿里云:5台4C8G机器,4台压力机2C4G
服务器环境:1台压力机,1台应用服务主机,1台数据库与缓存服务器,1CICD服务器
- CICD服务器4C8G:Nginx、JMeter、CICD (25Mbps峰值 = 3.125 MB/S)
- 数据库与缓存服务器4C8G:MySQL、Redis、MQ、ES (25Mbps峰值)
- 应用服务器01-4C8G:Application (25Mbps峰值)
- 监控服务器02-4C8G:Grafana、Prometheus、InfluxDB (25Mbps峰值)
只有在系统基础功能测试验证完成、系统趋于稳定的情况下,才会进行压力测试。
目的
- (负载上升各项指标是否正常)当负载逐渐增加时,观察系统各项性能指标的变化情况是否有异常
- (发现性能短板)发现系统的性能短板,进行针对性的性能优化
- (高并发下系统是否稳定)判断系统在高并发情况下是否会报错,进程是否会挂掉
- (预估系统最大负载能力)测试在系统某个方面达到瓶颈时,粗略估计系统性能上限
性能指标
| 指标 | 含义 |
|---|---|
| 响应时间(RT) | 系统对请求作出响应的时间。对于单用户的系统,响应时间可以很好地度量系统的性能 |
| 吞吐量 | 系统在单位时间内处理请求的数量。每秒事务数TPS是吞吐量的一种 |
| 并发用户数 | 系统可以同时承载的正常使用系统功能的用户的数量。用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求 |
| 错误率 | 失败请求占比。在测试时添加响应断言,验证不通过即为错误;若不添加,响应码非200即为错误 |
| 资源利用率 | cpu占用率、内存使用率、系统负载、网络I/O |
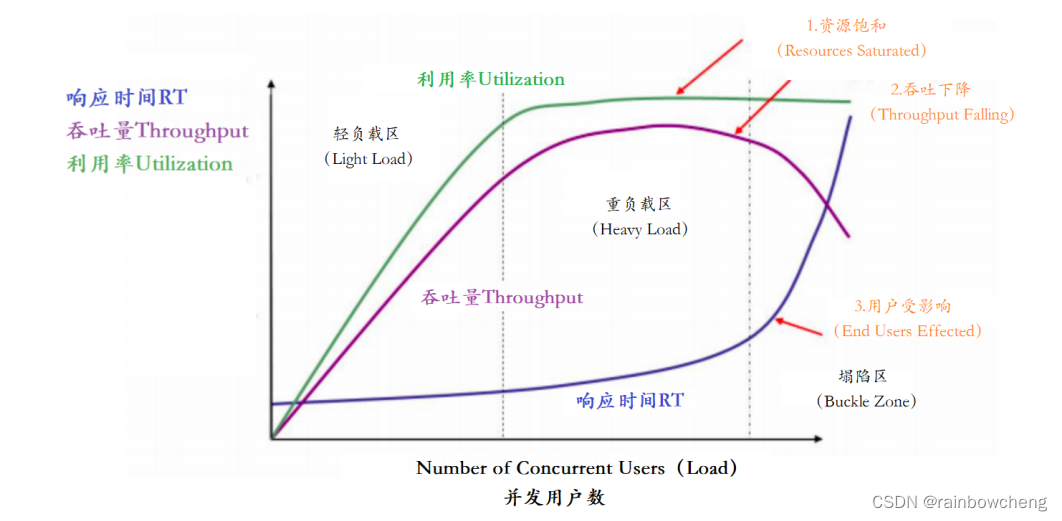
图中定义了
三条曲线
、
三个区域
、
两个点
以及三个状态描述。
常用压测工具
-
Apache JMeter:可视化的测试工具
-
Apache的ab压力测试
-
nGrinter韩国研发
-
PAS阿里测试工具
-
MeterSphere:国内持续测试的开源平台
案例 – springboot项目
Apache JMeter最初被设计用于web应用测试,但后来扩展到其他测试领域。用于测试静态和动态资源,例如静态文件、java小服务程序、CGI脚本、java对象、数据库、FTP服务器等。用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。另外,能够对应用程序做功能/回归测试,通过创建带有
断言
的脚本来验证程序返回了你期望的结果。
步骤
-
新建测试计划 –》右键“添加”–》线程用户–》线程组
-
配置线程组:线程数 20;ramp-up 指定时间之内把这些线程全部启动起来(如1,表示1s内把20个线程全部启动起来);循环次数 2000 表示把20线程循环2000次,也就是说让线程循环调用接口2000次
-
配置HTTP接口:选择keepalive方式,表示使用了长连接(长连接防止频繁建立连接,关闭连接消耗性能)。如果不勾选,压测部分性能消耗会发生在建立,关闭连接上,导致我们的压测数据不准确。
-
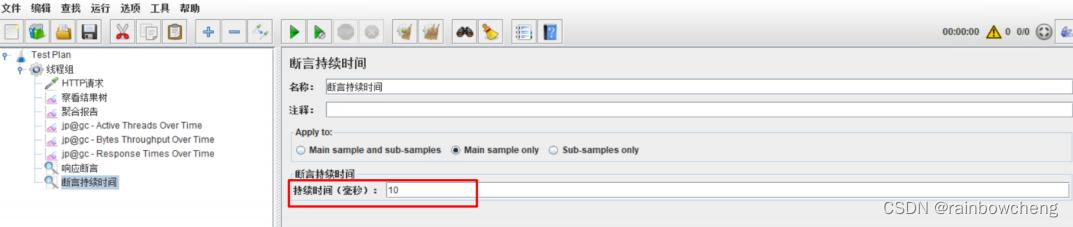
配置断言:一种是响应断言,一种是响应时间断言,如果响应内容不满足断言的配置,则认为这次的请求是失败的。右键测试计划的http请求,选择添加–》断言–》加断言和断言持续时间。
-
响应断言:判断响应内容是否包含指定的字符信息,用于判断api接口返回内容是否正确。
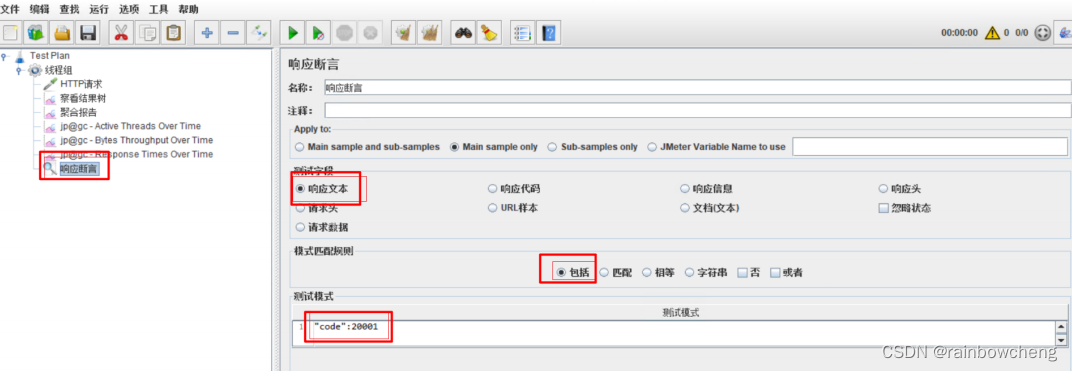
-
响应时间断言:判断响应时间,是否超过预期的时间,用于判断api接口返回时间是否超过预期。
-
响应断言:判断响应内容是否包含指定的字符信息,用于判断api接口返回内容是否正确。
-
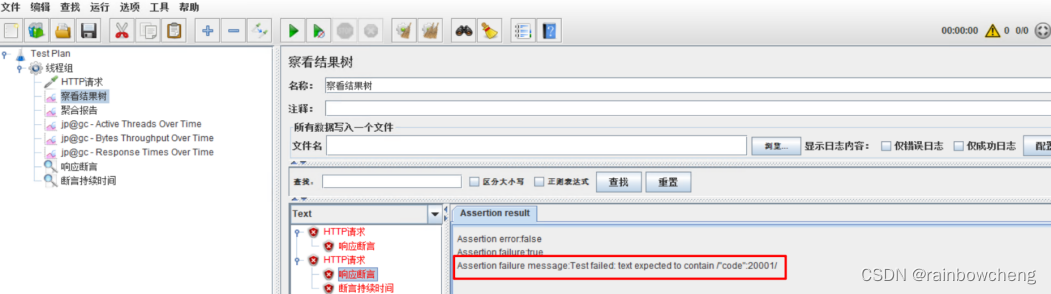
配置结果监听:监听压测结果【聚合报告和汇总报告很类似】
- 聚合报告:查询结果信息聚合汇总,例如样本、平均值、吞吐量、最大值、最小值等
- 查看结果树:记录每一次压测请求
- 图像结果:分析了所有请求的平均值、中值、偏离值和吞吐量之间的关系
- 汇总结果:汇总压测结果
- 汇总图:将压测结果以图像形式展示
结果
| label | 样本 | 平均值 | 中位数 | 90%百分位 | 95%百分位 | 99%百分位 | 最小值 | 最大值 | 标准偏差 | 异常% | 吞吐量 | 接收KB/sec | 发送 | 平均字节数 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| http | 100000 | 5921 | 6206 | 7108 | 7587 | 8883 | 1 | 17300 | 1576.95 | 0.00% | 779/sec | 341.57 | 0.00 | 449 |
- 样本:发送请求的总样本数量
-
响应时间【单位ms】:
- 平均值(average):平均的响应时间
- 中位数(median):50%请求的响应时间
- 90%百分位(90% Line):90%的请求的响应时间,意思就是说90%的请求<=1765ms返回
- 最小值(min):请求返回的最小时间,其中一个用时最短的请求。max反之。
- 标准偏差:度量响应时间分布的分散程度的标准,衡量响应时间值偏离平均响应时间的程度。标准偏差越小,偏离越少
- 异常(error):出现错误的百分比,错误率=错误的请求的数量 / 请求的总数
- 吞吐量(throughout):吞吐能力,在这相当于TPS
- Received KB/sec — 每秒从服务器端接收到的响应数据量
- Sent — 每秒从客户端发送的请求数量
线程组配置
线程组用来模拟一组用户访问系统资源(API接口)。可以使用JMeter的分布式测试功能,通过一个JMeter的Master来远程控制多个JMeter的Salve完成测试。
- 线程数:用来发送http请求的线程的数量。
-
循环次数:循环执行多少次操作。循环次数直接决定整个测试单个线程的执行时间,和整体测试执行时间。
- 单线程执行时间 = 单请求平均响应时间*循环次数
- 整个测试耗时 = 单线程执行时间+(ramp-Up – Ramp-Up/线程数)
- Ramp-Up:建立全部线程耗时。需要花费多久的时间启动全部的线程,默认0是代表同时并发。
常用你插件
增加新的内容分析维度:QPS 、RT、压力机活动线程数(表明压测过程中施加的压力的情况)、服务器资源信息等。
下载地址:http://jmeter-plugins.org/downloads/all/,官网上下载plugins-manager.jar直接在线下载,
average response time:平均响应时间;active threads 活动线程数;Bytes Throughput 吞吐量;Connect Times连接时间
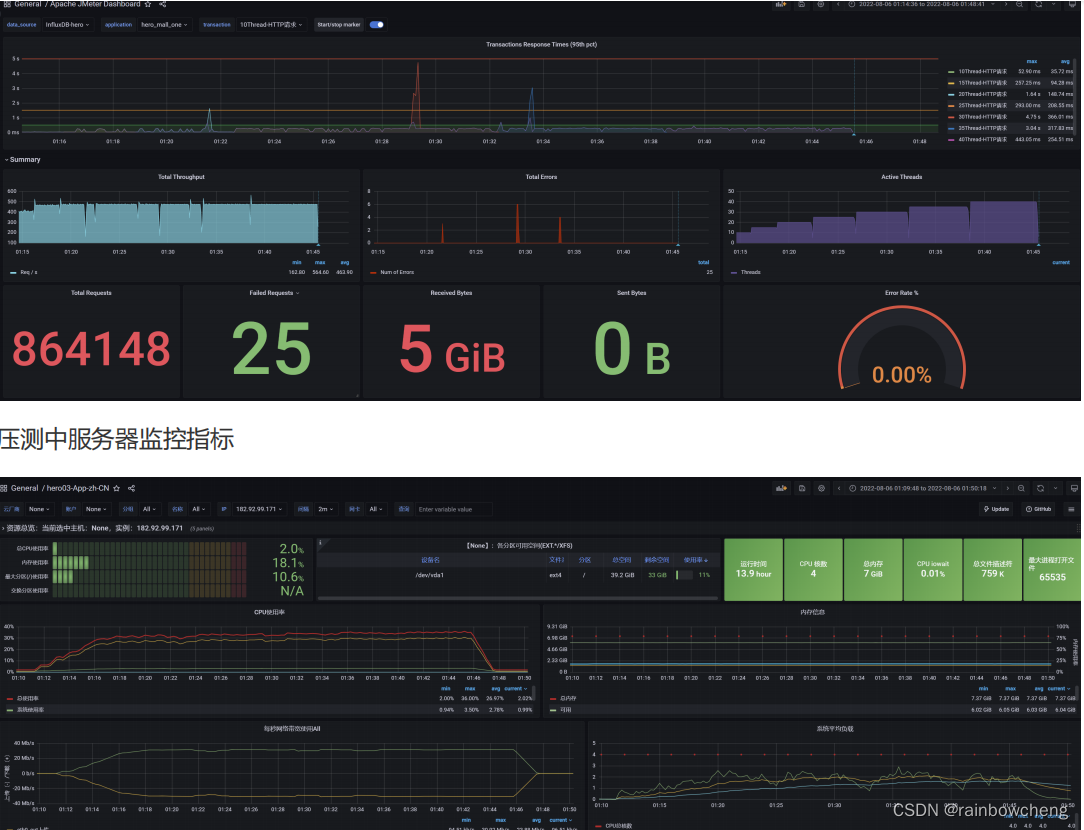
服务器硬件资源监控
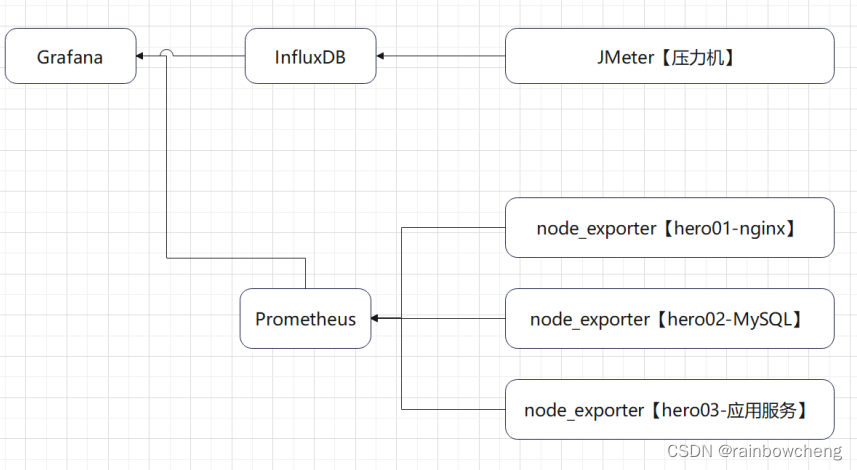
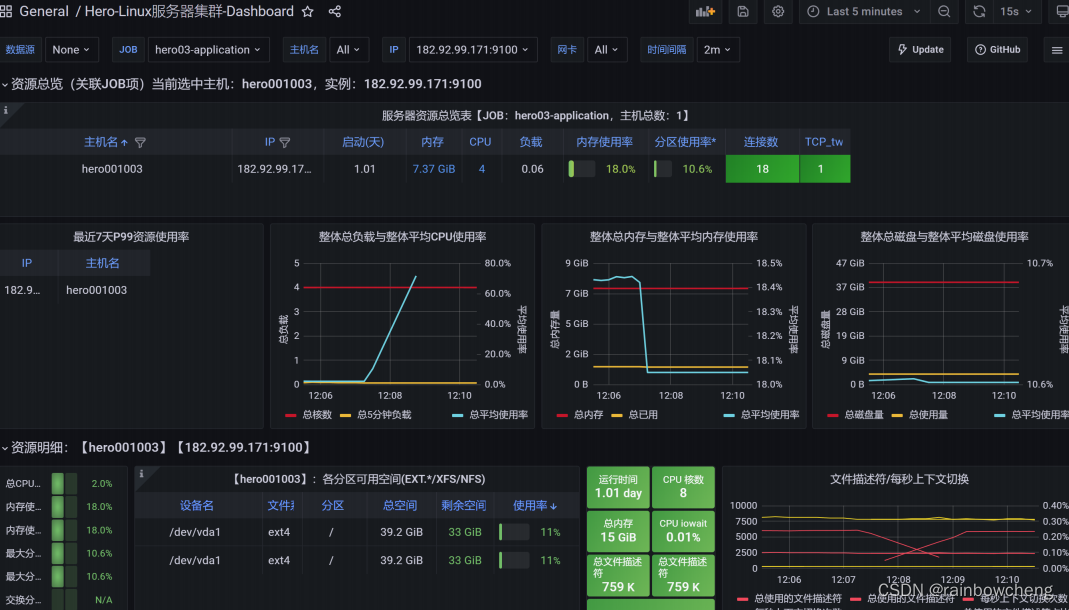
使用操作系统命令:top -H、vmstat、iostat、iotop、dstat、sar;使用finalshell;使用JMeter压测工具PerfMon;使用Grafana+Prometheus+node_exporter
-
配置服务端代理:必须在服务端安装serverAgent代理服务,JMeter才能实现监控服务端的cpu、内存、IO的使用情况。
ServerAgent下载地址:https://github.com/undera/perfmon-agent/blob/master/README.md
## 默认启动运行 startAgent.sh 脚本即可
## 服务启动默认4444端口,根本连接不上,因此自己创建一个部署脚本文件对此进行部署,且把端口修 改为7879
nohup java -jar ./CMDRunner.jar --tool PerfMonAgent --udp-port 7879 --tcp- port 7879 > log.log 2>&1 &
## 赋予可执行权限
chmod 755 startAgent.sh
-
CPU监控
- Elapse time:消耗时间
- Performance Metrics:性能指标
- idle:CPU空闲
- iowait:IO等待
- system:系统占用
- CPU user:cpu用户占用
- 网络监控:byteSrecv接收字节;byteSent发送字节;tx发送;rx接收
- 内存监控:usedPerc每分钟使用内存;freePerc每分钟未使用内存
好处:将所有信息汇总到JMeter工具中,查看方便。 缺点:数据记录时间有限,记录数据的量也有限
系统负载 load average
-
系统负载System Load是系统CPU繁忙程度的度量,既有多少进程在等待被cpu调用(进程等待队列的长度)
-
平均负载(Load Average)是一段时间内系统的平均负载,这个一段时间一般取1分钟、5分钟、15分钟
-
多核CPU和单核CPU的系统负载数据指标的理解还不一样
指标范围 -
【0.0 – 0.7]】 :系统很闲,马路上没什么车,要考虑多部署一些服务
-
【0.7 – 1.0 】:系统状态不错,马路可以轻松应对
-
【等于1.0】 :系统马上要处理不多来了,赶紧找一下原因
-
【大于5.0】 :马路已经非常繁忙了,进入马路的每辆汽车都要无法很快的运行
问题分析
-
1分钟>5,5分钟<1,15分钟<1(5.18,0.05,0.03)
短期繁忙,中长期空闲
,初步判断“抖动”或是“拥塞前兆”。 -
1分钟>5,5分钟>1,15分钟<1(5.18,1.05,0.03)
短期内繁忙,中期内紧张
,很可能是一个“拥塞的开始” -
1分钟>5,5分钟>5,15分钟>5(5.18,5.05,5.03)
短中长期都繁忙
,系统“正在拥塞”
压测监控平台
配置Docker环境
# 更新包
yum update
# 安装需要的软件包
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# 设置yum源为阿里云,加速下载
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker- ce/linux/centos/docker-ce.repo
# 安装docker
sudo yum install docker-ce
# 安装后查看docker版本
docker -v
# #### #### ####安装InfluxDB
# 下载influxDB的镜像
docker pull influxdb:1.8
# 启动InfluxDB的容器,并将端口8083和8086映射出来
docker run -d --name influxdb -p 8086:8086 -p 8083:8083 influxdb:1.8
# 进入容器内部,创建名为jmeter的数据库
docker exec -it influxdb /bin/bash
# ## 容器系统命令
influx
# Connected to http://localhost:8086 version 1.7.10
create database jmeter
show databases
设置JMeter脚本后置监听器
想要将 JMeter的测试数据导入 InfluxDB ,就需要在 JMeter中使用 Backend Listener 配置。
线程组右键–》添加–》监听器–》后端监听器
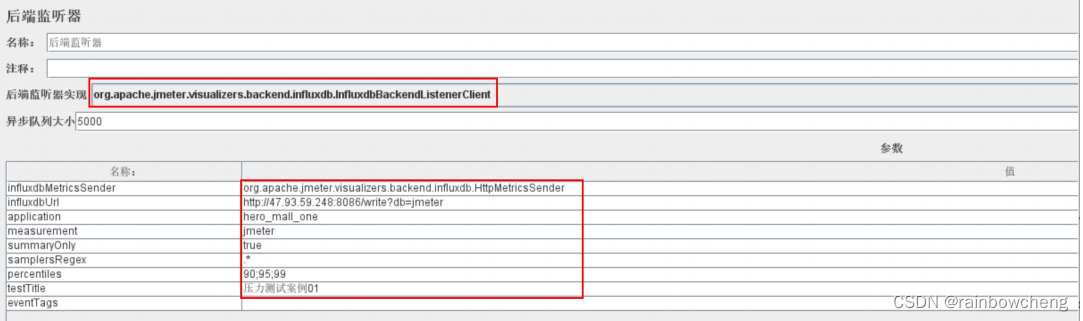
- influxdbUrl:自己部署IP和映射端口。
- application:根据需要自由定义,只是注意后面在grafana中选对即可。
- measurement:表名,默认jmeter,也可以自定义
- summaryOnly:选择true的话就只是总体的数据。false会记录总数,然后再将每个transaction都分别记录
- samplersRegex:样本正则表达式,将匹配的样本发送到数据库
- percentiles:响应时间的百分位P90、P95、P99
- testTitle:events表中的text字段的内容
- eventTags:任务标签,配合Grafana一起使用
安装Grafana
docker pull grafana/grafana
docker run -d --name grafana -p 3000:3000 grafana/grafana
# 网页端访问http://127.0.0.1:3000验证部署成功
- 默认admin/admin 选择添加数据源
- 配置数据源:url=127.0.0.1:8086;database=jmeter
- 导入模板:Import,直接输入模板ID号(在官网找到我们需要的展示模板,如5496,3351);直接上传模板JSON文件;直接输入模板JSON内容。
安装node_exporter
# 下载
wget -c https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_ex porter-0.18.1.linux-amd64.tar.gz
# 解压
tar zxvf node_exporter-0.18.1.linux-amd64.tar.gz -C /usr/local/hero/
# 启动
cd /usr/local/hero/node_exporter-0.18.1.linux-amd64
nohup ./node_exporter > node.log 2>&1 &
注意:在被监控服务器中配置开启端口9100 .127.0.0.1:9100/
安装Prometheus
# 下载
wget -c https://github.com/prometheus/prometheus/releases/download/v2.15.1/prometheus -2.15.1.linux-amd64.tar.gz
# 解压
tar zxvf prometheus-2.15.1.linux-amd64.tar.gz -C /usr/local/hero/
# 运行
nohup ./prometheus > prometheus.log 2>&1 &
#配置 Prometheus.yml中加入如下
- job_name: 'hero-Linux' static_configs: - targets: ['172.17.187.78:9100','172.17.187.79:9100','172.17.187.81:9100']
测试是否安装配置成功:http://127.0.0.1:9090/targets
在Grafana中配置Prometheus的数据源:
导入Linux系统dashboard(如ID:11074、16098)
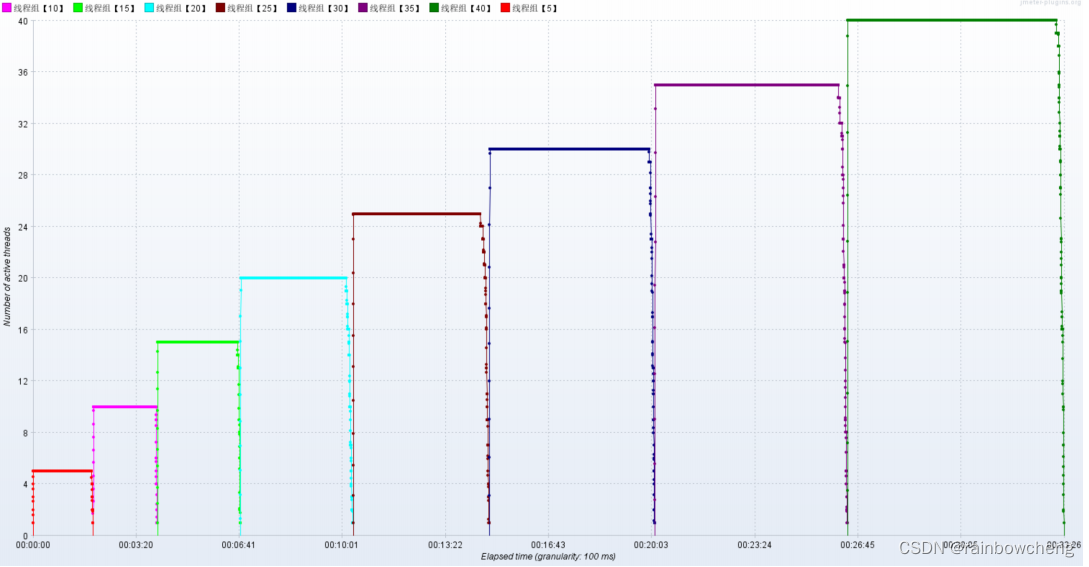
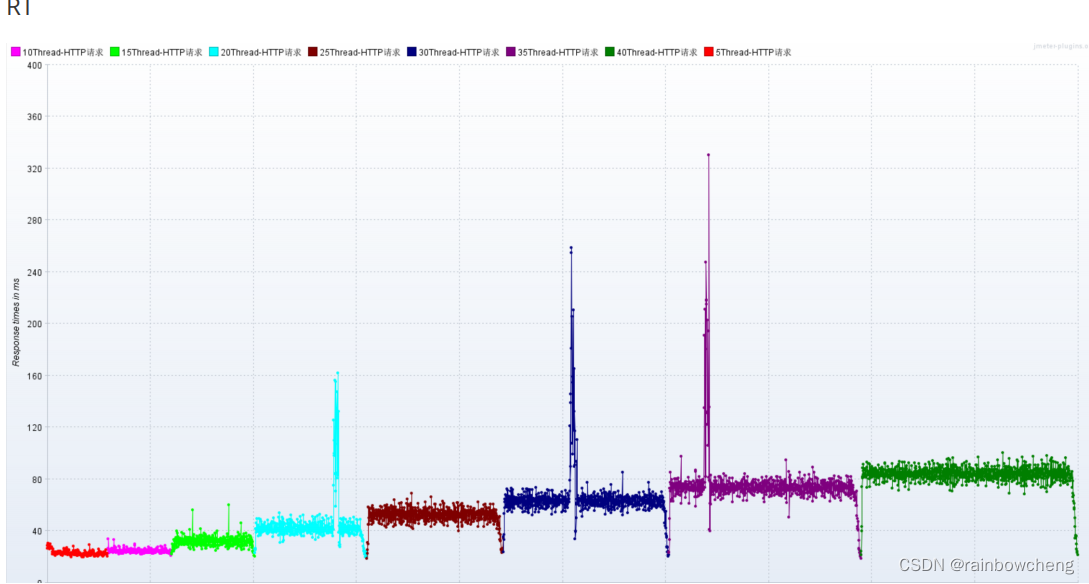
梯度压测:分析接口性能瓶颈
压测接口:响应时间20ms,响应数据包3.8kb,请求数据包0.421kb
压测配置
-
模拟低延时场景,用户访问接口并发逐渐增加的过程。
预计接口的响应时间为20ms- 线程梯度:5、10、15、20、25、30、35、40个线程
- 循环请求次数5000次
- 时间设置:Ramp-up period(inseconds)的值设为对应线程数(测试总时长:约等于20ms x 5000次 x 8 = 800s = 13分)
- 配置断言:超过3s,响应状态码不为20000,则为无效请求
-
机器环境
- 应用服务器配置:4C8G(外网-25Mbps=3MB/s;内网-基础1.5/最高10Gbit/s)
- 集群规模:单节点
- 服务版本:v1.0
- 数据库服务器配置:
1Gbit/s = 1Gbps = 125MB/s
1Mbps = 1Mb/s = 0.125MB/s
- 配置监听器:聚合报告、结果树、活动线程数、TPS统计分析、RT统计分析、后置监听器(压测信息汇总到InfluxDB,在Grafana中呈现)、压测监控平台(JMeter DashBoard、应用服务器、Mysql)
性能瓶颈剖析
-
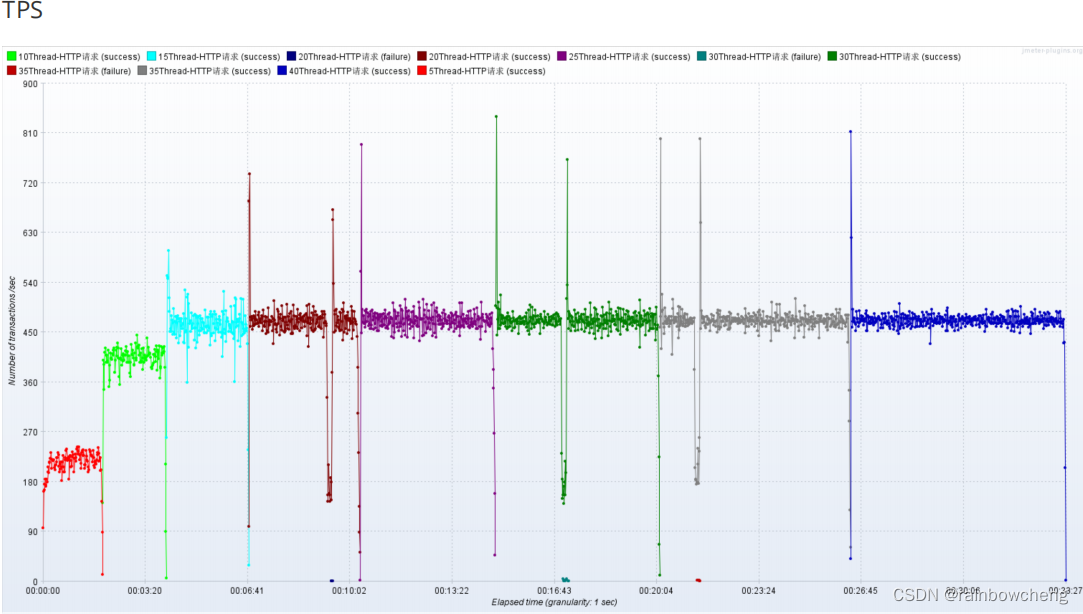
梯度压测,测出瓶颈
进一步提升压力,发现性能瓶颈
线程数 5,循环5000次,共2.5万个样本;线程数10,循环5000次,共5w样本;… 线程数40,循环5000次,共20万个样本。
-
网络到达瓶颈:随着压力的上升,
TPS不再增加,接口响应时间逐渐在增加
,偶尔出现异常,瓶颈凸显。系统的负载不高。cpu、内存正常,说明
系统资源利用率不高,带宽已经触顶了
。优化方案:降低接口响应数据包大小;提升带宽。
服务端线程数:TPS/RT*1000(如 RT=1000ms,TPS=800,线程数=800) -
接口的响应时间是否正常?是不是所有的接口响应都这么快
高延时场景:用户访问接口并发逐渐增加的过程。接口的响应时间为500ms(模拟sleep 500)- 线程梯度:100、200、300、400、500、600、700、800个线程;
- 循环请求次数200次
- 时间设置:Ramp-up period(inseconds)的值设为对应线程数的1/10(约等于500ms x 200次 x 8 = 800s = 13分)
- 配置断言:超过3s,响应状态码不为20000,则为无效请求
结论:在高延时场景下,服务器瓶颈主要在容器最大并发线程数(800/RT*1000);
-
TPS在上升到一定的值之后,异常率较高:理解为与IO模型有关系,因为当前使用的是阻塞式IO模型。这个问题我们在服务容器优化部分解决。
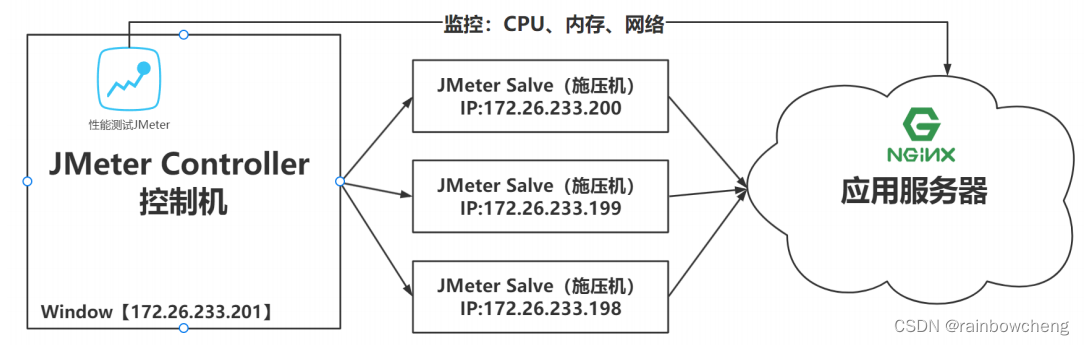
分布式压测
使用JMeter做大并发压力测试的场景下,单机受限与内存、CPU、网络IO,会出现服务器压力还没有上去,但是压测机压力太大已经死机!为了让JMeter拥有更强大的负载能力,JMeter提供分布式压测能力。
- 单机网络带宽有限,CPU等也有限
- 高延迟场景下,单机可模拟最大线程数有限
搭建注意事项
- 需保证Salve和Server都在一个网络中。如果在多网卡环境内,则需要保证启动的网卡都在一个网段
- 需保证Server和Salve之间的时间是同步的
- 需在内网配置JMeter主从通信端口【1个固定,1个随机】,简单的配置方式就是关闭防火墙,但存在安全隐患。
wget https://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache- jmeter-5.4.1.tgz
tar -zxvf apache-jmeter-5.4.1.tgz
mv apache-jmeter-5.4.1 ./apache-jmeter-5.4.1-salve
# 配置修改rmi主机hostname
# 1.改ip
vim jmeter-server
# RMI_HOST_DEF=-Djava.rmi.server.hostname=本机ip
# 2.改端口
vim jmeter.properties
# RMI port to be used by the server (must start rmiregistry with same port)
server_port=1099
# To change the default port (1099) used to access the server:
server.rmi.port=1098
# 配置rmi_keystore.jks
# 启动jmeter-server服务
nohup ./jmeter-server > ./jmeter.out 2>&1 &
分布式环境配置
- 确保JMeter Master和Salve安装正确。
- Salve启动,并监听1099端口
- 在JMeter Master机器安装目录bin下,找到jmeter.properties文件,修改远程主机选项,添加3个Salve服务器的地址。remote_hosts=172.17.187.82:1099,172.17.187.83:1099,172.17.187.84:1099
- 启动jmeter,如果是多网卡模式需要指定IP地址启动 jmeter -Djava.rmi.server.hostname=172.26.233.201
- 验证分布式环境是否搭建成功:界面–》“运行”菜单 –》 远程启动 –》里面有多台机器
名词解释
一、QPS:
Queries Per Second(每秒查询率),每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
计算公式:
qps = 请求查询数 / 秒
qps = fetchs / per second
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
qps相当于最大吞吐率
二、RPS:
Requests Per Second(每秒发送请求数/吞吐率),指客户端每秒发出的请求数。阿里云PTS 对于这个词的解释为RPS有些地方也叫做QPS,在不单独讨论“事务”的情况下可以近似对应到Loadrunner/jmeter的TPS(Transaction Per Second, 每秒事务数)。
计算公式:
吞吐率 = 总请求数 / 处理这些请求的总完成时间
Requests per second = Complete requests / Time taken for tests
吞吐率是服务器并发处理能力的量化描述,单位是reqs/s,指的是某个并发用户数下单位时间内处理的请求数。
某个并发用户数下单位时间内能处理的最大的请求数,称之为最大吞吐率。
截图来源:《并发模式与 RPS 模式之争,性能压测领域的星球大战》
链接:https://mp.weixin.qq.com/s?__biz=MzU4NzU0MDIzOQ==&mid=2247487138&idx=1&sn=be66769443f8157461c9ef12cba7722c&chksm=fdeb3cc2ca9cb5d423dceb71977e01a07be3be552a9b7cc63afec96936ee0b14ef07ff602345&token=1058504863&lang=zh_CN#rd
三、TPS:
Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS一般包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
CAPS: Call Attempts Per Second (每秒建立呼叫数量)
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
四、RT
Reponse Time(响应时间),从发起请求到完全接收到应答的时间消耗。
五、并发数
同时访问服务器站点的连接数。
建议参考文章:https://www.cnblogs.com/xiaowenshu/p/10727523.html
六、并发连接数
(The number of concurrent connections)
并发连接数就是服务器某个时刻所接受的请求数目,也就是某个时刻所接受的会话数目。
七、并发用户数
(The number of concurrent users, Concurrent Level)
一个用户可能产生多个会话,所以并发用户数和并发连接数并不重复。并发用户数是指服务器某个时刻所能接受的用户数。
八、用户平均请求等待时间
(Time per requests)
计算公式:
用户平局请求等待时间 = 总时间 / (总请求数 / 并发用户数)
Time per requests = Time taken for tests / (Complete requests / Concurrent Level)
九、服务器平均请求等待时间
(Time per requests: across all concurrent requests)
计算公式:
服务器平均等待时间 = 总时间 / 总请求数
Average request latency server = Time taken for tests / Complete requests
十、线程数
程序运行中消耗cpu的线程数,在正常消耗范围内线程数越大越好。
十一、吞吐量
吞吐量,是指在一次性能测试过程中网络上传输的数据量的总和。