单阶段YOLO系列模型:
一、YOLO发展史
单阶段模型:YOLO, SSD, Retina-Net
两阶段模型:RCNN, SPPNet
yolo系列:精度并不是最高的,但推理运行速度高
FPS:帧/s
精度、速度性价比高
1、YOLOv1
将目标检测当作一个单一的回归任务
-
将图片分成s*s个网格
-
物体中心点落在哪个网格上,就由该网格对应锚框负责检测该物体
2、YOLOv2
-
优化方法
骨干网络:224*224 -> 448 *448 ,DarkNet19
全卷积网络结构:Conv+Batch Norm
Kmeans聚类Anchor
多尺度训练
-
优化效果
推理速度由40FPS到67FPS
-
待改进点
小目标召回率不高
靠近的群体目标检测效果不好
检测精度需要进一步优化
3、YOLOv3
-
优化方法
骨干网络:DarkNet53
多尺度预测,跨尺度特征融合
COCO数据集聚类9种不同尺度的Anchor,每个尺度三个
-
优化效果
COCO数据集精度33.0
推理速度高于SSD 3倍
推理速度高于RetinaNet 3.8倍
-
待改进的点
召回率相对较低
定位精度优化
靠近群体目标检测效果差
整体网络构造:
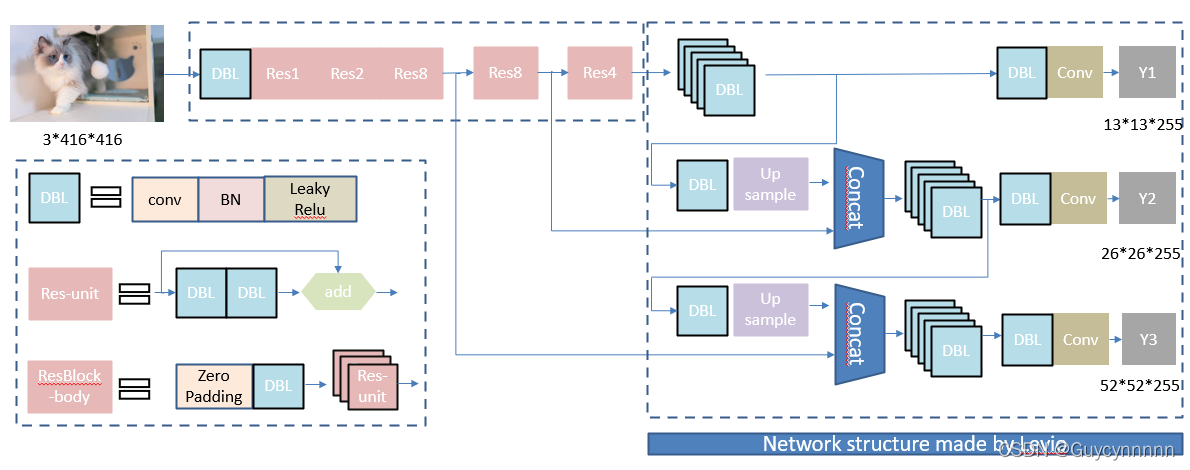
首先
输入图片,然后
Darknet53
特征提取,其中经过五次下采样,还使用了残差结构,目的是使网络结构在很深的情况下,仍能收敛并继续训练下去。
然后
经过
DBL
特征提取得到第一个尺度特征图
:
然后接着用
DBL
后特征图上采样后与倒数第二次下采样的结果相加,得到第二个尺度特征图
;
最后
的特征图上采样后与倒数第三次下采样的特征图相加得到第三个尺度的特征图
;
总的来说会输出
3
个不同尺度的特征图,每个尺度的特征图负责预测不同大小的目标。
每个特征图对应
3
种
anchor
大小不同的负责预测目标。最初图像还被分成
13×13
个网格,目标落在哪个网格中,哪个网格就负责预测目标,一个网格对应
3
个
anchor(anchor
的尺寸根据特征图相对于原图的比例等比缩小
)
。预测时,
yolov3
采用多个独立的逻辑分类器来计算属于特定标签的可能性,在计算分类损失时,它对每个标签使用二元交叉熵损失,降低了计算复杂度。
BackBone
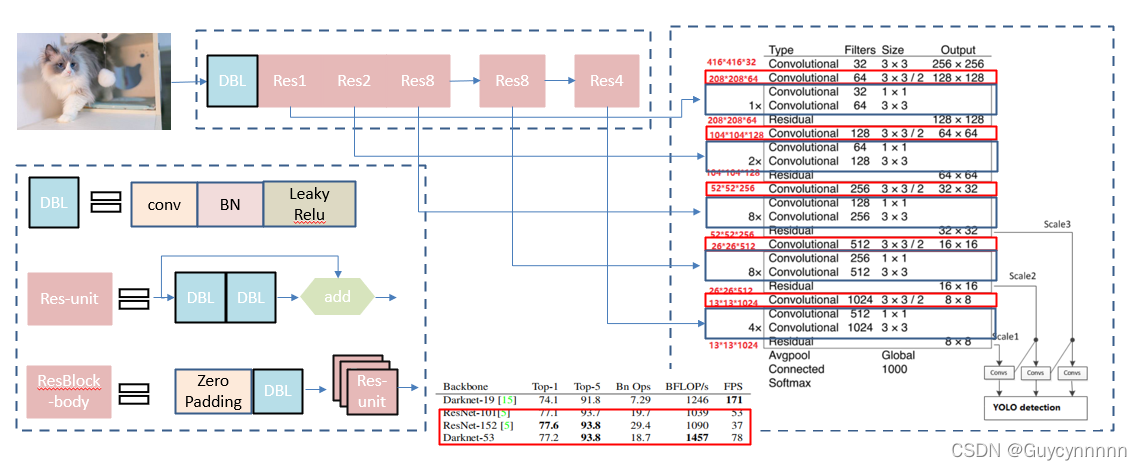
为了提升模型的检测精度,作者单独设计了
darknet-53
。在
ImageNet
上实验结果表明:
darknet-53
达到了和
ResNet-152/ResNet-101
相当的分类精度前提下,计算速度大幅度提升,网络层数也比他们少。
Yolo_v3
使用了
darknet-53
的前
52
层(去掉全连接层)做为
backbone
,用于特征提取。
yolo_v3
是一个全卷积网络,大量使用残差的跳层连接;同时为了降低池化带来的梯度负面效果,作者直接摒弃了
POOLing
,降采样是通过改变卷积核的步长来实现的
【
即使用的是步长为
2
的卷积来进行降采样
】
,如红色框所示,
darknet-53
一共进行
5
次下采样操作,将输出特征图缩小到输入的
1/32
。
所以,通常都要求输入图片的分辨率大小是
32
的倍数。
-
优点:
推理速度快,性价比高
背景误检率低
通用性强
-
缺点
召回率低
定位精度差
对于靠近/遮挡的群体、小物体,检测能力相对较弱
3、Output:
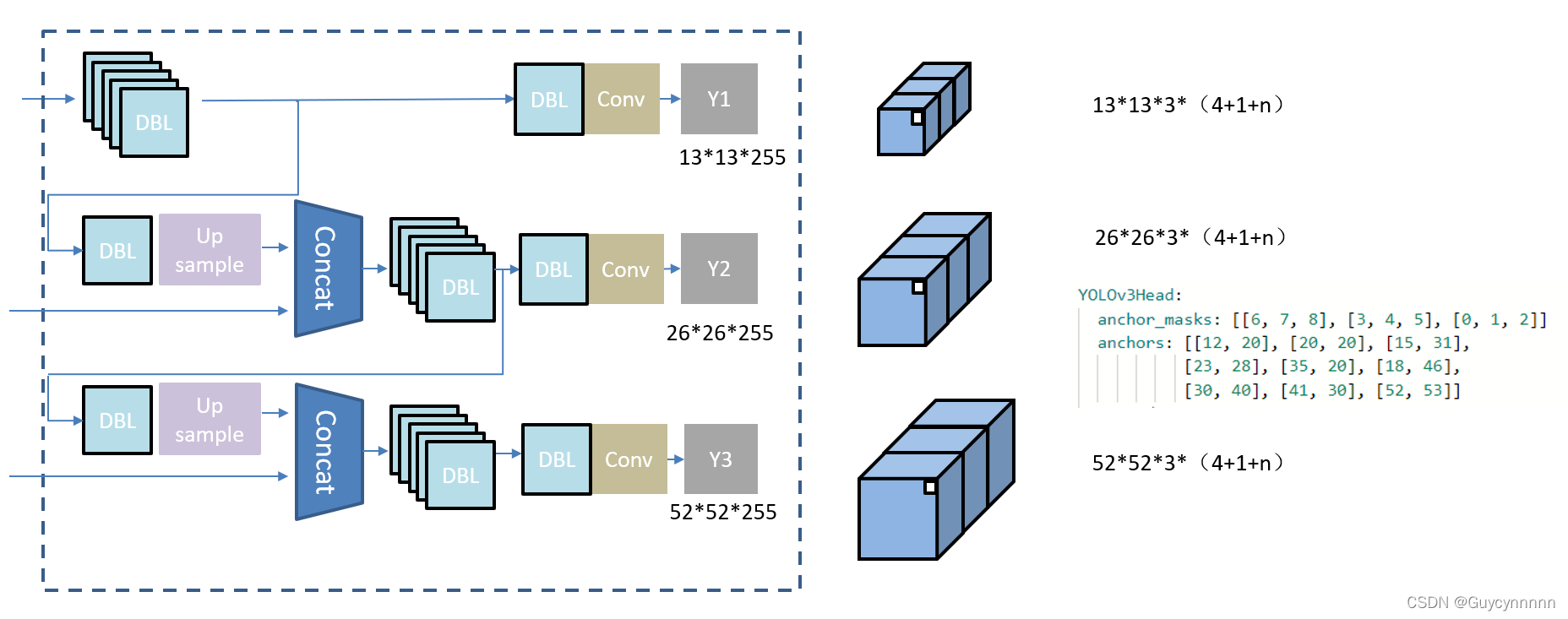
为了兼顾大小物体的检测精度,
YOLO v3
通过
upsample
和
concat
操作进行多尺度输出。
一共输出
3
个
scale
,输出特征图大小分别为
13-13
、
26-26
和
52-52【
以输入分辨率
416-416
为例
】
,小的特征图下采样倍数大,拥有更大的感受野,即每个格子对应的原图的范围更大。用于大目标的检测,大分辨率则用于小目标的检测。通过上采样将深层特征提取,其维度是与将要融合的特征层维度相同的(
channel
不同),通过
concat
实现深层
–
浅层特征的融合,提升检测的精度。
YOLO v3
采用
3
条支路进行检测输出,每条支路最后一个卷积层的卷积核个数等于网络的输出维度。以
COCO
数据集
80
类为例,输出的维度为
3*(80+4+1)=255
,其中
3
表示一个
grid cell
(网格点)包含
3
个
bounding box
,
80
表示类别的个数,每个维度表示该类的分数,
4
表示框的
4
个坐标信息(
x, y, w, h
),
1
表示
objectness
score
。
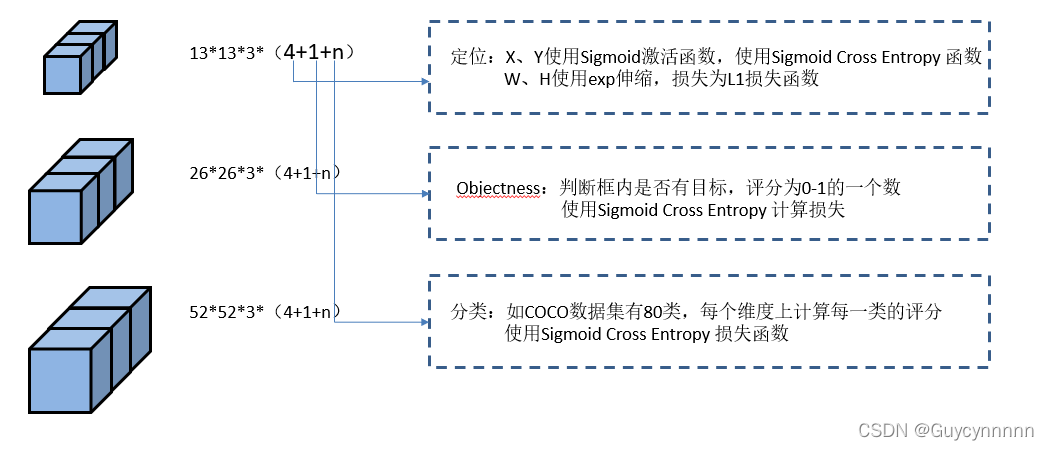
(1)32倍下采样输出结果:
1)13*13网格数
2)3个先验框
3)每个框分别有:4个边框坐标系-1个边框置信度-80个对象类别数
(2)16倍下采样输出结果:
1)26*26网格数
2)3个先验框
3)每个框分别有:4个边框坐标系-1个边框置信度-80个对象类别数
(3)8倍下采样输出结果:
1)52*52网格数
2)3个先验框
3)每个框分别有:4个边框坐标系-1个边框置信度-80个对象类别数
(4)锚框
-
在COCO数据集的真实框上Kmeans聚类了9(3*3)种尺度的anchor(
先验的超参数
)
特征图:13×13
感受野大,先验框为(116×90)(156×189)(373×326)
特征图:26×26
感受野中等,先验框为(30×61)(62×45)(59×119)
特征图:52×52
感受野中等,先验框为(10×13)(16×30)(×)
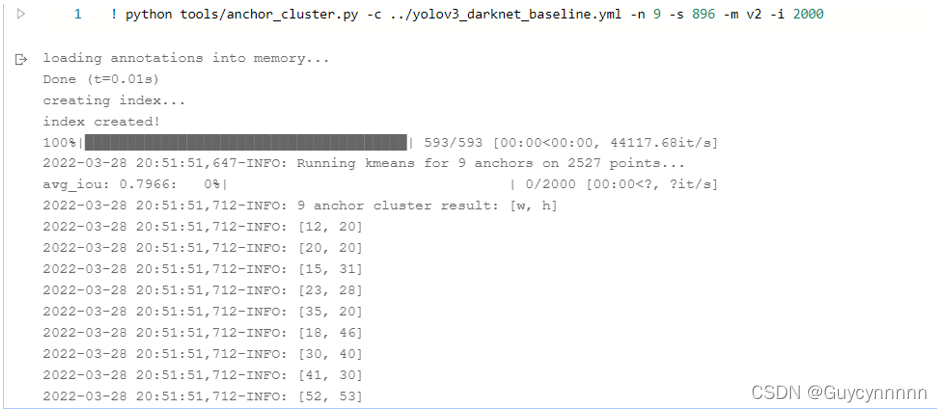
-
paddle中实现
-
! python tools/anchor_cluster.py -c ../yolov3_darknet_baseline.yml -n 9 -s 896 -m v2 -i 2000
聚类后的输出需要手动在配置文件中修改:

(4)
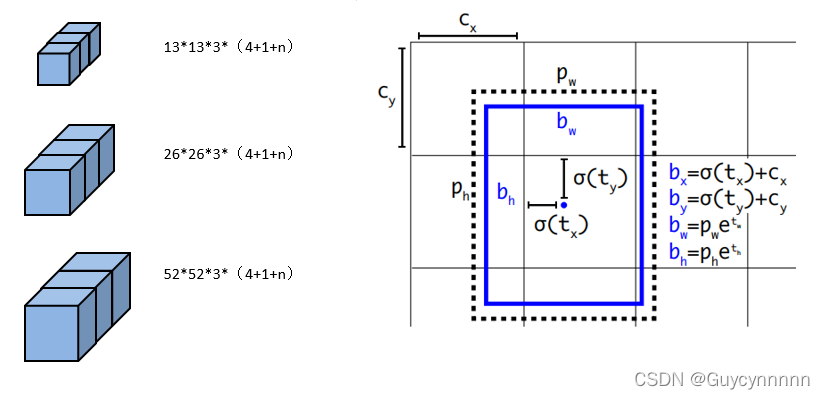
最初图像首先分成
13×13
个网格,目标落在哪个网格中,哪个网格就负责预测目标,一个网格对应
3
个
anchor(anchor
的尺寸根据特征图相对于原图的比例等比缩小
)
。
有目标的网格左上角为初始点
(
Cx
, Cy)
输出特征图高度、宽度为H、W,相当于将图像划分为H*W个网格
图像的每个网格对应输出特征图HW平面上的一个特征点
将每个网格上都放上锚框,每个网格上的每个锚框都对应一个预测框(网格数*锚框数=预测框数)
所有的9个锚框中,与真实框最匹配的,即IOU最大的锚框负责检测这个真实框
C = B*(5+class_num) B为该特征图上分配的锚框个数
-
中心点偏移:每个锚框初始点都在左上角
使用sigmoid函数:值固定在0-1之间
中心点偏移不能出网格
,偏移应在0-1之间
-
宽高拉伸:
使用exp函数:无论x取值符号,输出都为正
(5)LOSS
三、PaddleDetection中YOLOv3模型介绍
-
一键式训练:
python tools/train.py -c configs/yolov3_darknet.yml --eval-
一键式预测:
python tools/eval.py -c configs/yolov3_darknet.yml \
-o weights==https://paddlemodels.bj.bcebos.com/object_detection/yolov3_darknet.tar-
一键式评估:
python tools/eval.py -c configs/yolov3_darknet.yml \
-o weights==https://paddlemodels.bj.bcebos.com/object_detection/yolov3_darknet.tar \
--infer_img=demo/000000014439.jpg