https://github.com/McFly-byte/compiler/tree/master
文章目录
课程设计总览
课程设计要求
-
创建一个词法分析程序,该程序支持分析常规单词。
a) 输入:一个文本文档,包括一组 3º型文法(正规文法)的产生式。
b) 输出:一个源代码文本文档,包含一组需要识别的字符串(程序代码)。
c) 要求:词法分析程序可以准确识别:科学计数法形式的常量(如 0.314E+1),复数常量(如10+12i),可检查整数常量的合法性,标识符的合法性(首字符不能为数字等),尽量符合真实常用高级语言要求的规则。 -
创建一个使用 LL(1) 方法或 LR(1) 方法的语法分析程序。
a) 输入:包含 2º型文法(上下文无关文法)的产生式集合的文本文档;任务 1 词法分析程序输出的(生成的)token 令牌表。
b) 输出:YES 或 NO(源代码字符串符合此 2º型文法,或者源代码字符串不符合此 2º型文法);错误提示文件,如果有语法错标示出错行号,并给出大致的出错原因。
项目基本内容
词法分析器
a) 输入:自定义正规文法文件、程序源代码
b) 输出:Token串(三元组)
c) 流程:读入正规文法,生成对应NFA,确定化NFA,根据生成的DFA对输入源程序代码进行分析,产生Token串
语法分析器
a) 输入:自定义2型文法文件、词法分析产生的Token串
b) 输出:LR(1)分析信息(项目集族、状态信息等)、错误信息、分析结果
c) 流程:
i) 第一步,读入2型文法,构造项目族规范集,根据LR(1)分析法产生对应的DFA、Action表、Goto表。
ii) 第二步,读入Token串,根据LR(1)的产物进行语法分析。
项目结构
文件说明:
a) 文件夹
i) Compiler 项目文件夹
ii) Lexer 子项目词法分析器
iii) Parser 子项目语法分析器
b) .cpp/.h
i) LR LR(1)分析法
ii) NFA 不确定、确定的有穷自动机
iii) Op 将复杂的文法描述转换成字母符号产生式
c) .txt(输入、输出文件)
i) Input.txt/output.txt: 输入、输出测试
ii) Regular grammar.txt: 正规文法
iii) Source code.txt: 源程序代码
iv) Lexer.txt: Token(行号、内容、类别)序列
v) Describe.txt:语法描述
vi) 2NF grammar.txt: 语法对应2型文法
vii) Parser.txt:程序输出
项目结构:

a) Compiler
b) Lexer
c) Parser
词法分析器(Lexer)
实现原理
识别类型
| 类型 | 具体说明 |
|---|---|
| 关键字 | “if”、“then”、“else”、“bool”、“char”、“int”、“double”、“const”、“while”、“do”、“begin”、“end” |
| 标识符 | 可以由数字、字母、下划线组成。 |
| 常量 | 可以识别整数、小数、科学计数法、复数 |
| 运算符 | 单目运算符:“=”、“+”、“-”、“>”、“<”、“*”、“/”、“%” |
| 运算符 | 双目运算符:“==”、“>=”、”<=”等 |
| 界符 | “;”、“(”、“)”、“{”、“}”、“,” |
正规文法
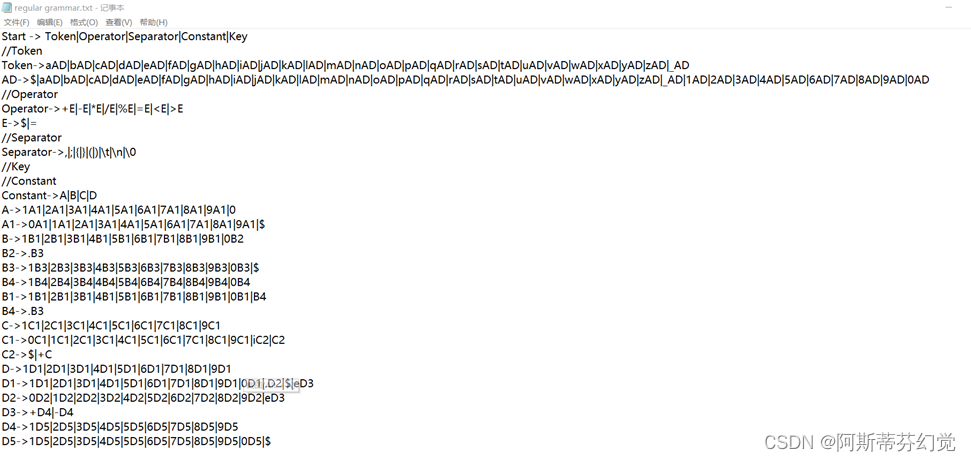
说明:
i) 内容类别由正规文法第一行产生式右部确定:Token-标识符、Operator-运算符、Separator-界符、Constant-常量、Key-关键字
ii) 根据此正规文法,可识别“识别类型”中全部类别
iii) 文法已由符号代替非终结符,并作正规化,该步骤独立与机器手动完成
iv) 程序读入时自动跳过“//”注释之后该行的内容
重要类与结构定义
NFA 不确定的有穷自动机
LA 词法分析
class LA /* Lexical Analysis
/
{
public:
ofstream fout;
string line; /
输入行
/
string word; /
当前处理串
/
string T; /
当前状态
/
int index; /
当前状态对应List中下标
/
int id; /
输出编号 */
LA();
void analysis( NFA& nfa, string file3, string file2 );
void read_next_VT( char ch, NFA& nfa, string file2 );
void output( int tag, NFA& nfa, string file2 );
};
isEquallALL 比较类(在map中根据second找key)
class isEqualALL
{
public:
explicit isEqualALL(char c) : ch© {}
bool operator() (const std::pair<string, char>& element) const {
return element.second == ch;
}
private:
const char ch;
};
重要函数
| 函数定义 | 注释 |
|---|---|
| void NFA::nfa_2_dfa() | /* NFA的图转化为 DFA的图 */ |
| void NFA::cope_line( string line ) | /* 每次处理一行,可能有多条产生式*/ |
| void NFA::cope_formula( string formula ) | /* 每次处理一条产生式 */ |
| void NFA::e_closure( string status, vector& T ) | /* 给出一个状态,求$闭包 */ |
| void NFA::vt_move( char vt, vector V, vector& T ) | /* 在闭包V中找到vt弧转换, 将新状态放入T中 */ |
| string NFA::get_first_VN( string formula ) | /* 从输入种获取第一个VN,这是起始符 */ |
| string NFA::get_next_VN( string & formula ) | /* 从输入中得到下一个VN,并在line中去掉其与其之后的-> */ |
| string NFA::get_next_VT( string & formula ) | /* 从输入中得到下一个VT */ |
| void LA::analysis( NFA& nfa, string file3, string file4 ) | /* 根据NFA对象进行词法分析 */ |
| void LA::read_next_VT( char ch, NFA& nfa, string file4 ) | /* 处理下一个非终结符 */ |
运行结果
输入源程

运行时相关信息
a) NFA信息

b) NFA 状态-弧 (部分)
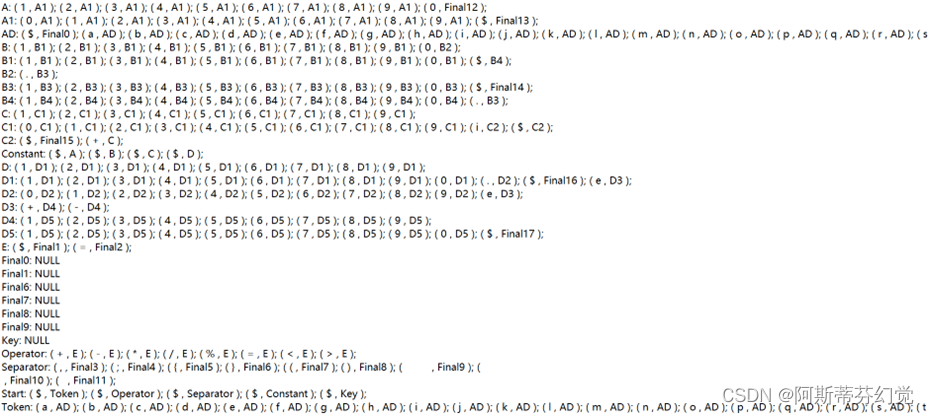
c) DFA信息

d) DFA 状态-弧
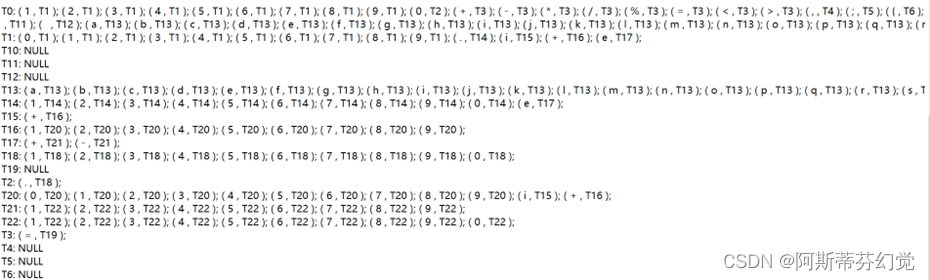
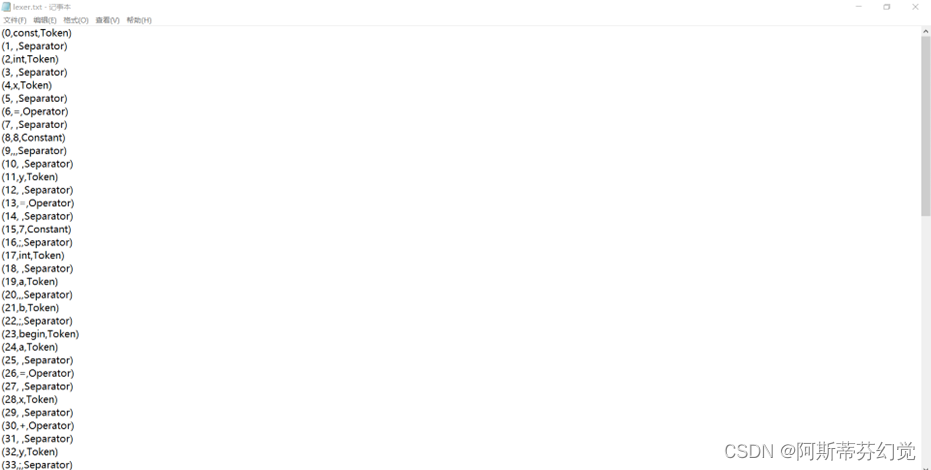
运行结果
(部分截图)
语法分析器(Parser)
实现原理
原理
先根据2型文法,利用LR(1)分析法构造项目集,进而得到DFA、Action表和Goto表。再利用词法分析的结果进行语法分析,输出相应信息
文法

对应2型文法
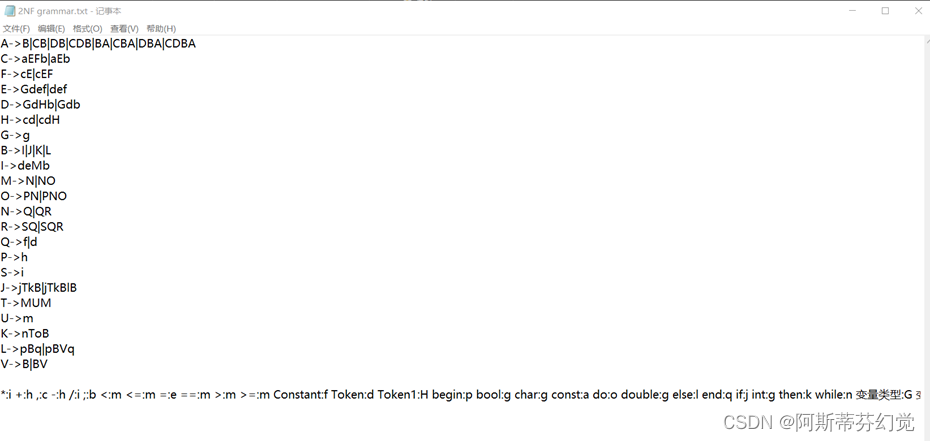
说明:
i) 语法由describle.txt给出,由op转为2型文法并输出到2NF grammar.txt中。
ii) 每个大写字母对应一个或一类非终结符,每个小写字母对应一个或一类终结符。
iii) 最终分析的结果再由文件最后一行字典转换为字符对应的状态
重要类与结构定义
LR(0)
LR(1)
class LR1 : public LR
{
public:
map<char,string> First; /* 每个非终结符的First集的集合 */
map<string,char> Dic;
void generate_firstset();
bool contains( string a, string b );
string first( string remaider, string lookahead );
virtual void input( string File );
void analysis( string FileIn, string FileOut );
void build_DFA();
void build_table( vector<clcn>& Collections );
void enclosure( clcn& C );
int verify_conflict( clcn C );
void print_state( clcn C );
};
重要函数
void LR::collection_2_dfa()
/* 根据项目集规范组得到DFA、Action、Goto */
void LR::build_table( vector<vector >& States )
/* 根据DFA构造Action表和Goto表
/
/
规定0状态遇初态结束 */
void LR::enclosure( vector& Closure )
/* 把闭包根据规则扩充,不改变其状态 */
int LR::verify_conflict( vector Closure )
/* 检测闭包中是否存在冲突 */
void LR::report( int error )
/* 根据error的类型报告错误 */
void LR::input( string File )
/* 输入2型文法产生式
/
/
因为是2型文法,故规定每个Vt、Vn长度都为1
/
/
Production第0位是产生式左部,后面是产生式右部 */
void LR1::analysis( string FileIn, string FileOut )
/* 读入词法分析结果,进行语法分析,输出 */
void LR1::generate_firstset()
/* 生成每个非终结符的First集的集合 */
void LR1::print_state( clcn C )
/* 输出项目集族 */
string LR1::first( string remainder, string lookahead )
/* 输入项目分隔符右边部分以及该项目向前搜索符,求给出字串的first集 */
void LR1::build_DFA()
/* 重写LR1中项目集规范族的构造, 产生DFA、Action、Goto */
string UTF8ToGB(const char* str);
/* 读入一行包含中文字符的字符串,使其能够存入map中不产生乱码 */
void turn_to_2NF( string In, string Out );
/* 逐字符处理语法,生成2NF */
*具体实现见代码包
运行结果
运行时相关信息
a) 各项目集规范族内容(部分截图)
序号即代表状态号,从结果来看,共186个状态



b) DFA状态-弧 (部分截图)


c) Action表

d) Goto表 (部分截图)

运行结果

将输入远程序改写后(去掉while-do语句的后半部分),重新执行:
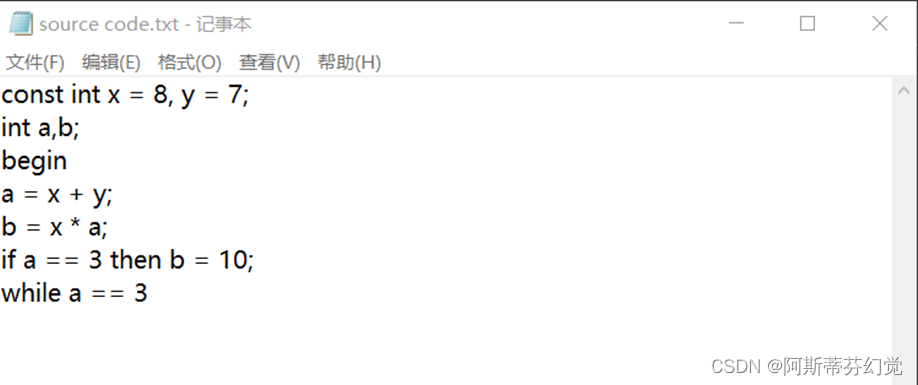
输出
