计算图像相似度——《
Python
也可以》之一
声明:本文最初发表于赖勇浩(恋花蝶)的博客
http://blog.csdn.net/lanphaday
,如蒙转载,敬请确保全文完整,未经同意,不得用于商业用途。
关于《
Python
也可以》系列:这是我打算把这几年里做的一些实验和代码写出来,涉及的面比较广,也比较杂,可能会有图像处理、检索等方面的内容,也会有中文分词、文本分类、拼音、纠错等内容。毫不掩饰地说:在博客发这系列文章的原因在于宣传
python
,所以这系列文章都会带有源码和相关的测试用例,这也是特色之一。但这系列文章都是“浅尝辄止”的,不会深入到专属领域,只是为了表明
python
功能很强大,不仅适合于
web
或者
game
开发,也适合于科学研究。
要计算图像的相似度,肯定是要找出图像的特征。这样跟你描述一个人的面貌:国字脸,浓眉,双眼皮,直鼻梁,大而厚的嘴唇。
Ok
,这些特征决定了这个人跟你的同事、朋友、家人是不是有点像。图像也一样,要计算相似度,必须抽象出一些特征比如蓝天白云绿草。常用的图像特征有颜色特征、纹理特征、形状特征和空间关系特征等。颜色特征的算是最常用的,在其中又分为直方图、颜色集、颜色矩、聚合向量和相关图等。直方图能够描述一幅图像中颜色的全局分布,而且容易理解和实现,所以入门级的图像相似度计算都是使用它的;作为一篇示例性的“浅尝辄止”的文章,我们也不例外。
在进行我们试验之前,我们需要找到一批图片来作为测试用例。我上穷碧落下黄泉,最后终于在我的前同事西门的博客(
http://blog.163.com/johnal1
)找到了一系列他在公司组织的年度旅游时去西藏林芝拍的一组风光图片(
http://blog.163.com/johnal1/blog/static/9394912200812105654784
),实在是难得之佳品,简直可以说得到了它们我们的实验已经完成了
90%
。哦耶!下面来看一下我们最重要的一组照片(两张):


找到一组很好的测试图片之后,我们需要再给
Python
环境安装一个图像库,我的选择是
PIL
(
Python image library
)。
PIL
为
Python
提供了图像处理功能,并且支持数十种图像格式。(关于
PIL
的介绍,可以查看我之前的文章《用
Python
做图像处理》
http://blog.csdn.net/lanphaday/archive/2007/10/28/1852726.aspx
)
虽然这两张图片大小都是一样的,但为了通用性,我们有必要把所有的图片都统一到特别的规格,在这里我选择是的
256×256
的分辨率。


因为
PIL
为
RGB
模式的图像计算的
histogram
样点数为
768
,计算量并不算太大,所以本文就直接使用,没有再作降维处理了。
6 def make_regalur_image(img, size = (256, 256)):
7
return img.resize(size).convert(‘RGB’)
转化为规则图像之后,可以调用
img.histogram()
方法获得直方图数据,如上文两图的直方图如下:
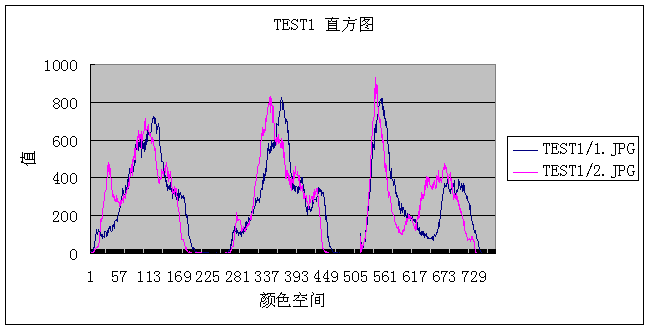
得到规则图像之后,图像的相似度计算就转化为直方图的距离计算了,本文依照如下公式进行直方图相似度的定量度量:
Sim(G,S)=
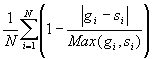
,其中
G,S
为直方图,
N
为颜色空间样点数
转换为相应的
Python
代码如下:
19 def hist_similar(lh, rh):
20
assert len(lh) == len(rh)
21
return sum(1 – (0 if l == r else float(abs(l – r))/max(l, r)) for l, r in zip(lh, rh))/len(lh)
22
23 def calc_similar(li, ri):
24
return hist_similar(li.histogram(), ri.histogram())
短短十行代码不到就完成了图片相似度的计算,再加上从硬盘读取图像的函数和测试代码,也不过二十行上下:
28 def calc_similar_by_path(lf, rf):
29
li, ri = make_regalur_image(Image.open(lf)), make_regalur_image(Image.open(rf))
30
return calc_similar(li, ri)
31
32 if __name__ == ‘__main__’:
33
path = r’test/TEST%d/%d.JPG’
34
for i in xrange(1, 7):
35
print ‘test_case_%d: %
.3f
%%’%(i, calc_similar_by_path(‘test/TEST%d/%d.JPG’%(i, 1), ‘test/TEST%d/%d.JPG’%(i, 2))*100)
那么这样做的效果到底怎么样呢?且来看看测试结果(测试用例和代码请
猛击这里
下载):
test_case_1: 63.322%
test_case_2: 66.950%
test_case_3: 51.990%
test_case_4: 70.401%
test_case_5: 32.755%
test_case_6: 42.203%
结合我们肉眼对测试用例的观察,这个程序工作得还算可以。不过
test_case_4
就暴露了直方图的缺点:它只是图像中颜色的全局分布的描述,无法描述颜色的局部分布和色彩所处的位置。
test_case_4
的规则图如下:


可以看到它们的色彩局部分布有相当大的不同,但事实上它们的全局直方图相当相似:
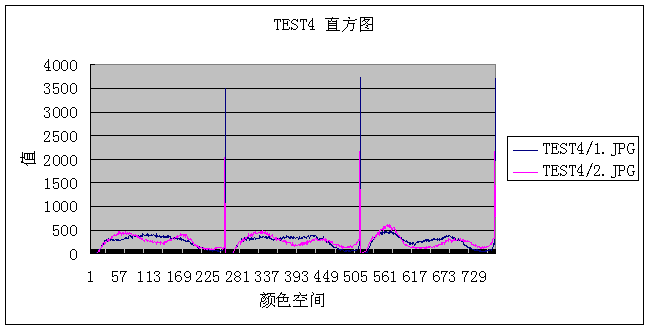
虽然从直方图来看两图是极其相似的,但上述算法计算出相似度为
70.4%
的结果肯定是不可接受的。那么,怎么样才能克服直方图的缺点呢?答案是把规则图像分块,再对相应的小块进行相似度计算,最后根据各小块的平均相似度来反映整个图片的相似度。在实验中,我们把规则图像分为
4×4
块,每块的分辨率为
64×64
:

分割图像的代码为:
9 def split_image(img, part_size = (64, 64)):
10
w, h = img.size
11
pw, ph = part_size
12
13
assert w % pw == h % ph == 0
14
15
return [img.crop((i, j, i+pw, j+ph)).copy() /
16
for i in xrange(0, w, pw) /
17
for j in xrange(0, h, ph)]
相应地,把计算相似图的函数
calc_similar()
修改为:
23 def calc_similar(li, ri):
24 #
return hist_similar(li.histogram(), ri.histogram())
25
return sum(hist_similar(l.histogram(), r.histogram()) for l, r in zip(split_image(li), split_image(ri))) / 16.0
进行这样的改进后,算法已经能够在一定的程序上反映色彩的局倍分布和颜色所处的位置,可以比较好的弥补全局直方图算法的不足。新的算法计算出来的结果如下:
test_case_1: 56.273%
test_case_2: 54.925%
test_case_3: 49.326%
test_case_4: 40.254%
test_case_5: 30.776%
test_case_6: 39.460%
可以看到,
test_case_4
的相似度由
70.4%
下降到
40.25%
,基本上跟肉眼的判断是切合的;另外其它图像的相似度略有下降,这是因为加入了位置因子之的影响。从而可见基于分块的直方图相似算法是简单有效的。
图像的相似度计算是图像检索、识别的基础,本文只是浅尝辄止地介绍了其中最基本的计算方法,如果你要学习和研究更好的算法,也请记住
Python
也能帮助你哦
~