一,使用pycharm创建项目
我创建的项目下只有两个文件,一个停分词文件,一个脚本代码文件
停分词文件(stopwords.txt):作用:在用
jieba分词库
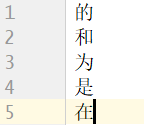
对文件进行分词处理时,有些无用却频繁出现的分词,像“的”、“得”、“地”、“是”等,我们并不希望这些分词也被进行词频统计,因为统计这些分词没有什么意义,所以事先建立一个停分词文件,等会代码中利用这些停分词进行数据清洗
注意
:文件中一个停分词必须按照独占一行的格式来写
二,全部代码如下:
import os
import os.path
import codecs
filePaths=[]
fileContents=[]
# c盘的Documents文件夹下放好自己要进行词频统计的txt文件
# os.walk()方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下
for root,dirs,files in os.walk('C:\\Documents'):
for name in files:
print(name)
filePath = os.path.join(root,name)
filePaths.append(filePath)
f=codecs.open(filePath,'r','utf-8')
fileContent =f.read()
f.close()
fileContents.append(fileContent)
# 数据清洗
Contents=""
for i in range(len(fileContents)):
# strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)
Contents= Contents+(str(fileContents[i])).strip()
# 文件基本都是中文,我们也只想对中文词汇进行词频统计
import re
# 利用正则,匹配一个或以上的汉字
pattern = re.compile(r'[\u4e00-\u9fa5]+')
filterdata = re.findall(pattern,Contents)
cleaned_data= ''.join(filterdata)
# print(cleaned_data)
import pandas
corpos = pandas.DataFrame({
'filePath':filePaths,
'fileContent':cleaned_data
})
import jieba
# 还需指明分词的出处
segments=[]
filePaths=[]
for index,row in corpos.iterrows():
filePath = row['filePath']
fileContent = row['fileContent']
# 调用cut方法,对文章内容进行分词
segs = jieba.cut(fileContent)
for seg in segs:
segments.append(seg)
filePaths.append(filePath)
# 把得到的分词和分词来源再存到一个数据框中
segmentDataFrame = pandas.DataFrame({
'segment':segments,
'filePath':filePaths
})
import numpy
# 进行词频统计
segStat=segmentDataFrame.groupby(
by=['segment']
)['segment'].agg({'计数':numpy.size})
segStat = segStat.reset_index().sort_values(
'计数',
ascending=False
)
print(segStat)
# 这里就用到了停分词文件
stopwords=pandas.read_csv("./stopwords.txt",index_col=False,names=['stopword'], encoding='utf-8')
print(stopwords)
fSegStat=segStat[
# ~取反符号,这里意思就是不包括停分词文件中的这些停分词 ,即fSegStat去掉了那些无用的分词
~segStat.segment.isin(stopwords.stopword)
]
# wordcloud库,可以说是python非常优秀的词云展示第三方库
from wordcloud import WordCloud
# Matplotlib 是一个 Python 的 2D绘图库
import matplotlib.pyplot as plt
wordcloud = WordCloud(
# simhei.ttf先百度下载字体文件,再在这里写保存字体文件的路径
font_path="C:\\Downloads\\simhei.ttf",
background_color='black',
# 设置最多显示的词汇数
max_words = 20
)
# to_dict将list数据转成字典
words=fSegStat.set_index('segment').to_dict()
wordcloud.fit_words(words['计数'])
plt.imshow(wordcloud)
# 不展示坐标系
plt.axis('off')
plt.show()
plt.close()
三,运行脚本文件结果截图
我这里是根据一份计算机网络作业的文件进行词频统计的,可以明显看到,这里显示的20个高频词汇与计算机网络息息相关

版权声明:本文为weixin_41320468原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。