01 CNN卷积神经网络
参考
1.1 基本模块
| 模块名称 | 备注 |
|---|---|
| 输入层 | 二维向量 |
| 卷积层 |
对输入层进行卷积,提取高层次特征 滤波器/内核——对输入信号进行筛选,选择和它类似的信号 |
| 池化层(下采样层) |
每领域四个像素中的最大值变为一个像素 ——卷积已提取特征,相邻区域特征类似,池化选出最能表征特征的像素,缩减数据量,同时保留特征 |
| RELU层 | 神经元的激活函数 |
| 全连通层 |
常规的神经网络 ——based on经过多次卷积层和多次池化层所得出的高级特征进行全连接,算出最后预测值 |
| 输出层 | 一般最后会加一个softmax层 |
1.2 CNN与传统神经网络相比
-
局部感知——通过卷积提取局部特征,CNN是一个从局部到整体的过程,传统神经网络是一个整体的过程
-
权重共享——参数量小,计算量小
-
多卷积核
1.3 dropout
正则化,防止过拟合
如:每个隐藏层的输入设置概率判决,如概率为0.5,一半的神经元被丢失
02 FCN
参考
2.1 与CNN的比较与继承
个人理解:
CNN是为了分类,而FCN是语义分割;
CNN是一维向量得到的概率,而FCN则是一组由色块组成的,与原图像大小一致的图像)
2.2 CNN的缺点
FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片
传统的基于CNN的分割方法
:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:
一是存储开销很大。
例如对每个像素使用的图像块的大小为15×15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。
(这里的滑动窗口个人理解为卷积对不同特征的提取)
二是计算效率低下。
相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。
三是像素块大小的限制了感知区域的大小。
通常像素块的大小比整幅图像的大小小很多,只能提取一些
局部的特征
,从而导致分类的性能受到限制。
2.3 FCN对CNN的改进:
通常CNN网络
在卷积层之后会接上若干个全连接层
, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。
以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个
数值描述(概率)
,比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
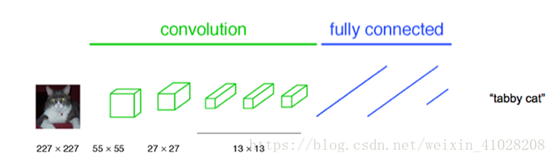
【图】CNN
FCN对图像进行
像素级的分类
,从而解决了
语义级别的图像分割(semantic segmentation)问题
。
FCN把CNN
全连接层换成了卷积层
,可以接受任意尺寸的输入图像,采用
反卷积
对卷积层的特征图进行采样,使它恢复到输入图像相同的尺寸,从而可以
对每个像素都产生了一个预测
,同时保留了原始输入图像的空间信息,然后在上采样上的特征图进行逐像素分类,最后逐个像素计算softmax损失,
相当于每个像素对应一个训练样本
。
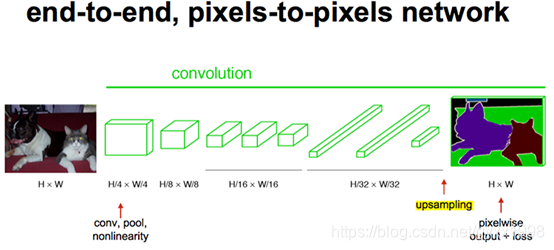
【图】FCN
2.4 FCN的几个关键技术
经过多次卷积后,图像的分辨率越来越低,为了从低分辨率的heatmap恢复到原图大小,
以便对原图上每一个像素点进行
分类预测
,需要
对heatmap进行反卷积,也就是上采样
。论文中首先进行了一个
上池化
操作,再进行
反卷积
,使得图像分辨率提高到原图大小
2.4.1 卷积化
经典的CNN分类所使用的网络通常会在最后连接全连接层,它会将原来二维的矩阵压缩成一维的,从而丢失了空间信息,最后训练输出一个向量,这就是我们的
分类标签
。
而图像语义分割的输出则需要是个
分割图
,且不论尺寸大小,但是至少是二维的。所以,我们丢弃全连接层,换上卷积层,而这就是所谓的卷积化了。
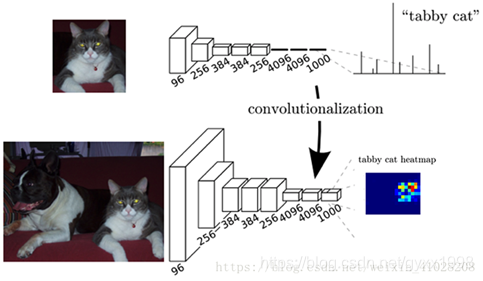
个人对这段的理解:
CNN只是得到一个一维向量,然后根据向量确定概率→→判别是哪一类的;
而FCN,则能得到一个与原图像相同大小的二维或三维图像→→并在这个图像中用“色块”标出不同种类的物体,这在语义分割中极为重要,如:汽车的无人驾驶
2.4.2 上采样 Upsampling(即反卷积)
上采样也就是对应于上图中最后生成heatmap的过程。
上面采用的网络经过5次卷积+池化后,图像尺寸依次缩小了 2、4、8、16、32倍,对最后一层做32倍上采样,就可以得到与原图一样的大小,现在我们需要将卷积层输出的图片大小还原成原始图片大小,在FCN中就设计了一种方式,叫做上采样,具体实现就是
反卷积
。
| 卷积 | 反卷积 |
|---|---|

|

|
(蓝色是input,绿色是output)
2.4.3 FCN结构设计
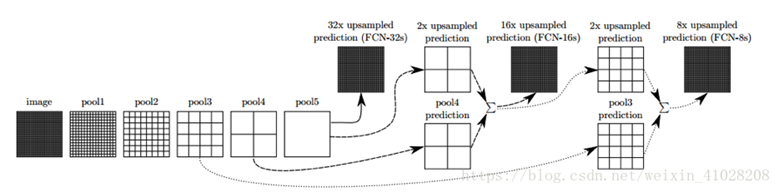
在文章中,作者发现直接做32倍反卷积,结果不精确,所以设计了一种方式来解决这个问题。
过程:
-
对原图像进行卷积conv1、pool1后原图像缩小为1/2;
-
之后对图像进行第二次conv2、pool2后图像缩小为1/4;
-
接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;
-
接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;
-
最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32;
-
然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
【其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特诊图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。】
现在文章有
- 1/32尺寸的heatMap
- 1/16尺寸的featureMap
- 1/8尺寸的featureMap
- 1/32尺寸的heatMap
进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里
向前迭代
。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个
差值过程
),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
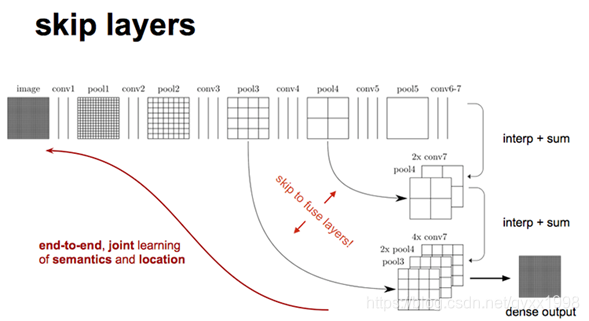
03 UNet
3.1 UNet
参考:
-
https://www.jianshu.com/p/ab0a10c2e710
-
https://www.jianshu.com/p/f9b0c2c74488
-
https://blog.csdn.net/u012931582/article/details/70215756
-
https://blog.csdn.net/awyyauqpmy/article/details/79290710
3.2 UNet++
参考:
-
https://www.jianshu.com/p/3d9df4aa69bb?tdsourcetag=s_pctim_aiomsg
-
https://zhuanlan.zhihu.com/p/44958351
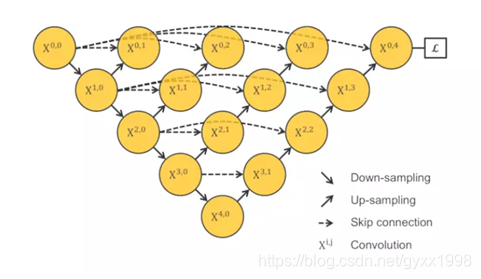
每层U-net
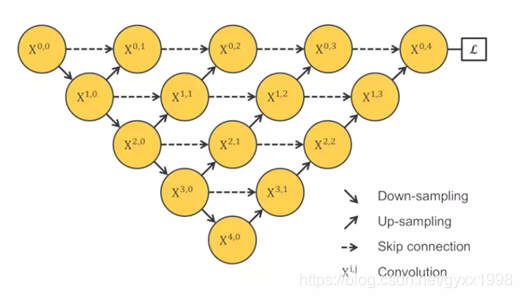
3.3 Attention-Unet
参考:
-
https://blog.csdn.net/qingmeiann/article/details/80555981
-
https://blog.csdn.net/qq_41352018/article/details/80551737
04 其他的一些概念
4.1 Auto-context
https://blog.csdn.net/weixin_42569673/article/details/89073865
(参考论文
AutoContext.pdf
)
- 第一步用传统分类器对新数据进行识别,得到这个数据属于各类别的概率P(0)(i);
- 第二步的数据训练集S不仅包含数据X,类别Y,还包含有上述所得的P(0)(i),得到一个新的分类器后再对新数据识别得到其分别属于个类别的概率P(1)(i);更新S中的P,
- 重复第二步,一直到收敛,即P几乎不变。这时便得到比传统方法更清晰的识别图像。
4.1.1 特征设计
(1)
图像特征
①彩色图像→
L
∗
u
∗
v
L*u*v
L
∗
u
∗
v
分解,计算三通道上的Hear特征
②补充功能→梯度直方图(HOG)(与Hear特征互补)
③医学图像、场景理解→像素的固定位置
④其他方法:Gabor函数和Canny边缘图的滤波器响应
(2)
上下文特征 → 特征候选池、稀疏的抽样
对于每个感兴趣的像素:
长距离
——以45度间隔的八条光线从当前像素延伸出来,并且我们稀疏地对这些光线上的上下文位置进行采样。
短距离
——距离当前像素3个像素内的所有位置都在候选特征池中。这确保了本地情境不会错过
(3)
其他特征
MRI图像分割→显示生成模型来提取自适应图谱
4.1.2 与UNet的耦合
(参考论文
AutoContext-Net.pdf
)
论文地址
https://ieeexplore.ieee.org/document/7961201
a. Unet网络建立
b. AutoContext(pdf P4-5)
Step1 对每个像素点进行后验估计

Step2 最优化?(根据真实分布和估计分布的交叉熵)


Step3 计算
假设特征深度为2,则有

其中W1,W2为k×k×d权重矩阵,*是2D卷积运算,d是输入特征的深度(假设为2),而b是偏差。
其中W1和W2分别是对应于
强度输入
(y1)和
标签输入
(y2)的k×k权重矩阵。
根据以下信息,W2值被优化,如:它们关于脑形状的标签进行编码,它们各自的位置和连接性信息。
在
步骤0的网络训练期间
,对应于标签输入W2的权重被分配比对应于强度输入的权重(即
W2 << W1
)低得多的值,因为标签输入在开始时不携带关于图像的信息。 注意,p0 j(Ni)构造为在类上具有均匀分布。
另一方面,在以下步骤中,对应于标签输入W2,区域的权重指定的值高于对应于强度输入的权重(即
W2> W1
)。 因此,在测试中,对应于预测标签的过滤器比对应于强度的过滤器更有效。
4.2 随机森林
随机森林的基础知识:
https://www.cnblogs.com/gczr/p/7097704.html
前面提到,随机森林中有许多的分类树。我们要将一个输入样本进行分类,我们需要将输入样本输入到每棵树中进行分类。打个形象的比喻:森林中召开会议,讨论某个动物到底是老鼠还是松鼠,每棵树都要独立地发表自己对这个问题的看法,也就是每棵树都要投票。该动物到底是老鼠还是松鼠,要依据投票情况来确定,获得票数最多的类别就是森林的分类结果。森林中的每棵树都是独立的,99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会超脱于芸芸“噪音”,做出一个好的预测。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想(关于bagging的一个有必要提及的问题:bagging的代价是不用单棵决策树来做预测,具体哪个变量起到重要作用变得未知,所以bagging改进了预测准确率但损失了解释性。)。
4.2.1 信息、熵以及信息增益的概念
对于机器学习中的决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(xi)的信息可以定义如下:
I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率。
熵是用来度量不确定性的,当熵越大,X=xi的不确定性越大,反之越小。对于机器学习中的分类问题而言,熵越大即这个类别的不确定性更大,反之越小。
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好。
4.3 ResNet
4.4 DenseNet
-
DenseNet算法详解(有论文及代码地址)
https://blog.csdn.net/u014380165/article/details/75142664/
-
DenseNet论文及tensorflow实现详解
https://blog.csdn.net/langzi453/article/details/84098964
-
densenet作者解读
http://www.sohu.com/a/161639222_114877
-
denseNet在Tensorflow下的使用
https://github.com/taki0112/Densenet-Tensorflow
-
从ResNet到DenseNet
https://blog.csdn.net/shwan_ma/article/details/78165966
-
从CNN到DenseNet
https://www.cnblogs.com/skyfsm/p/8451834.html
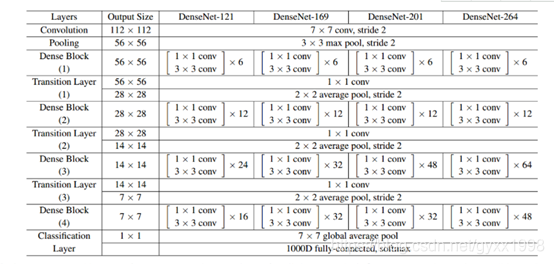

Input=>卷积=>dense block 1=>卷积=>池化
分类