和其它的机器学习方向一样,强化学习(Reinforcement Learning)也有一些经典的实验场景,像Mountain-Car,Cart-Pole等。由于近年来深度强化学习(Deep Reinforcement Learning)的兴起,各种新的更复杂的实验场景也在不断涌现。于是出现了OpenAI Gym,MuJoCo,rllab, DeepMind Lab, TORCS, PySC2等一系列优秀的平台。
博主环境
Ubuntu16.04
Anaconda2
python 3.6(建议重新在anaconda中创建新的环境,以下操作均在conda创建环境下配置)
tensorflow-gpu 1.4.1 (baseline 最低要求1.4.1)
CUDA 8.0 (CUDA的安装可参考
https://blog.csdn.net/Hansry/article/details/81008210
)
Cudnn 6.0
1.安装mujoco
MuJoCo(Multi-Joint dynamics with Contact)是一个物理模拟器,可以用于机器人控制优化等研究。
1.准备工作
在
官网上
下载
mjpro150 linux
,同时点击
Licence
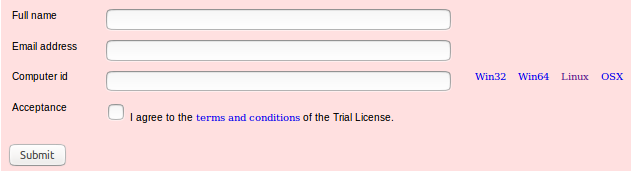
下载许可证,需要
full name
email address
computer id
等信息,其中根据使用平台下载
getid_linux(可执行文件)
获取
computer id
, 步骤如下:
$ chmod a+x getid_linux (给予执行权限)
$ ./getid_linux - 1
- 2
输出结果类似于
LINUX_A1EHAO_Q8BPHTIM10F05D0S3TB3293
点击
submint
后,从输入的邮箱中下载证书
mjkey.txt
2.环境配置
2.1 创建隐藏文件夹并将
mjpro150_linux
拷贝到
mujoco
文件夹中
mkdir ~/.mujoco
cp mjpro150_linux.zip ~/.mujoco
cd ~/.mujoco
unzip mjpro150_linux.zip- 1
- 2
- 3
- 4
2.2 将证书
mjkey.txt
拷贝到创建的隐藏文件夹中
cp mjkey.txt ~/.mujoco
cp mjkey.txt ~/.mujoco/mjpro150/bin- 1
- 2
2.3.添加环境变量, 打开
~/.bashrc
文件,将以下命令添加进去
export LD_LIBRARY_PATH=~/.mujoco/mjpro150/bin${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
export MUJOCO_KEY_PATH=~/.mujoco${MUJOCO_KEY_PATH}- 1
- 2
3.运行结果
cd ~/.mujoco/mjpro150/bin
./simulate ../model/humanoid.xml- 1
- 2

2.安装mujoco_py
首先现在官网上下载安装
mujoco_py源码
, 注意的是在这里安装的时候可能会缺很多包,但是提示什么装什么就行了。
pip3 install -U 'mujoco-py<1.50.2,>=1.50.1'- 1
如下顺利执行则说明安装成功
>>> import mujoco_py
>>> from os.path import dirname
>>> model = mujoco_py.load_model_from_path(dirname(dirname(mujoco_py.__file__)) +"/xmls/claw.xml")
>>> sim = mujoco_py.MjSim(model)
>>> print(sim.data.qpos)
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
>>> sim.step()
>>> print(sim.data.qpos)
[ 2.09217903e-06 -1.82329050e-12 -1.16711384e-07 -4.69613872e-11
-1.43931860e-05 4.73350204e-10 -3.23749942e-05 -1.19854057e-13
-2.39251380e-08 -4.46750545e-07 1.78771599e-09 -1.04232280e-08]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
一定会出现的问题为
Creating window glfw
ERROR: GLEW initialization error: Missing GL version
Press Enter to exit ...- 1
- 2
- 3
- 4
将
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia-390
加入到
~/.bashrc
中解决问题
运行
python body_interaction.py
3.安装gym
OpenAI Gym是OpenAI出的研究强化学习算法的toolkit,它里边cover的场景非常多,从经典的Cart-Pole, Mountain-Car到Atar,Go,MuJoCo都有。官方网站为
https://gym.openai.com/
,源码位于
https://github.com/openai/gym
,它的readme提供了安装和运行示例,按其中的安装方法:
最小安装
git clone https://github.com/openai/gym.git
cd gym
pip install -e .- 1
- 2
- 3
完全安装
apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig Pillow libglfw3-dev
pip install -e '.[all]'- 1
- 2
进入
~/gym/examples/scripts
中,通过
./list_envs
可发现
gym
中拥有很多环境。
通过调用gym中的环境,如下代码所示,可以运行
import gym
env = gym.make('Hero-ram-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
<
>
import gym
env = gym.make('Hero-ram-v0')
for i_episode in range(20):
observation = env.reset()
for t in range(100):
env.render()
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

4.安装baseline
OpenAI Baseline
是一系列高质量的强化学习控制算法,需要python>=3.5, 且需要
OpenMPI
和
zlib
,有些
baseline example
是基于
Mujoco
物理仿真环境的,可以根据上面的教程进行安装。
4.1 下载
baselines
包并且配置相关工具
git clone https://github.com/openai/baselines.git
cd baselines
pip install -e .- 1
- 2
- 3
4.2 安装
tensorflow-gpu
,由于我们的CUDA 和Cudnn 分别是8.0 和6.0, 所以我们需要安装对应的
tensorflow-gpu
conda install tensorflow-gpu=1.4.1- 1
4.3 为了在
baseline
中对算法进行测试,需要安装
pytest
pip install pytest
pytest- 1
- 2
输出以下内容即配置成功
================================================================================== test session starts ==================================================================================
platform linux -- Python 3.6.6, pytest-3.6.3, py-1.5.4, pluggy-0.6.0
rootdir: /home/hansry/append/RL/baselines, inifile:
collected 12 items
baselines/common/test_identity.py - 1
- 2
- 3
- 4
- 5
- 6
其他包都是缺什么补什么
补充:github 上有大神写的
gazebo
和
gym
的包:
https://github.com/erlerobot/gym-gazebo
5.baselines 中HER(Hindsight experience replay)的使用
进入到
/baselines/baselines/her/experiment
文件夹下,发现含有
config.py
play.py
train.py
等文件
其中
config.py
一般是设置其参数,诸如下面
DEFAULT_PARAMS = {
# env
'max_u': 1., # max absolute value of actions on different coordinates
# ddpg
'layers': 3, # number of layers in the critic/actor networks
'hidden': 256, # number of neurons in each hidden layers
'network_class': 'baselines.her.actor_critic:ActorCritic',
'Q_lr': 0.001, # critic learning rate
'pi_lr': 0.001, # actor learning rate
'buffer_size': int(1E6), # for experience replay
'polyak': 0.95, # polyak averaging coefficient
'action_l2': 1.0, # quadratic penalty on actions (before rescaling by max_u)
'clip_obs': 200.,
'scope': 'ddpg', # can be tweaked for testing
'relative_goals': False,
# training
'n_cycles': 50, # per epoch
'rollout_batch_size': 2, # per mpi thread
'n_batches': 40, # training batches per cycle
'batch_size': 256, # per mpi thread, measured in transitions and reduced to even multiple of chunk_length.
'n_test_rollouts': 10, # number of test rollouts per epoch, each consists of rollout_batch_size rollouts
'test_with_polyak': False, # run test episodes with the target network
# exploration
'random_eps': 0.3, # percentage of time a random action is taken
'noise_eps': 0.2, # std of gaussian noise added to not-completely-random actions as a percentage of max_u
# HER
'replay_strategy': 'future', # supported modes: future, none
'replay_k': 4, # number of additional goals used for replay, only used if off_policy_data=future
# normalization
'norm_eps': 0.01, # epsilon used for observation normalization
'norm_clip': 5, # normalized observations are cropped to this values
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
其中
train.py
为训练
DDPG+HER
中的参数,诸如神经网络中的参数等,在训练参数过程中,还有许多可选选项
@click.option('--env', type=str, default='FetchReach-v1', help='the name of the OpenAI Gym environment that you want to train on') (选择HER执行的任务)
@click.option('--logdir', type=str, default=None, help='the path to where logs and policy pickles should go. If not specified, creates a folder in /tmp/') (选择训练完policy的参数)
@click.option('--n_epochs', type=int, default=50, help='the number of training epochs to run') (迭代的次数)
@click.option('--num_cpu', type=int, default=1, help='the number of CPU cores to use (using MPI)') (使用多少个CPU)
@click.option('--seed', type=int, default=0, help='the random seed used to seed both the environment and the training code')
@click.option('--policy_save_interval', type=int, default=5, help='the interval with which policy pickles are saved. If set to 0, only the best and latest policy will be pickled.')
@click.option('--replay_strategy', type=click.Choice(['future', 'none']), default='future', help='the HER replay strategy to be used. "future" uses HER, "none" disables HER.')
@click.option('--clip_return', type=int, default=1, help='whether or not returns should be clipped')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
训练的命令是
python train.py --num_cpu=2 (参数可选)
其中
play.py
为调用训练好的参数进行执行,执行命令如下:
python play.py policy_best.pkl(后面需要跟着训练好的参数文件)- 1
