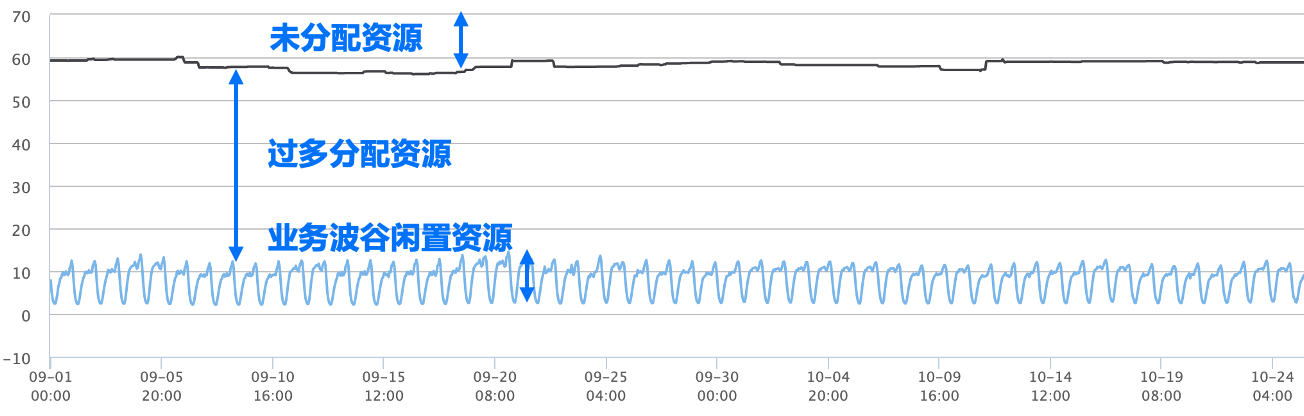
作为云平台用户,我们都希望购买的服务器物尽其用,能够达到最大利用率。然而要达到理论上的节点负载目标是很的,计算节点总是存在一些装箱碎片和低负载导致的闲置资源。下图展示了某个生产系统的CPU资源现状,从图中可以看出,浪费主要来自以下几个方面:
- 业务需求与节点可调度资源很难完全匹配,因此在每个节点上都可能剩余一些碎片资源无法被分配出去。
- 业务通常为了绝对稳定,会申请超出自身需求的资源,这会导致业务锁定了资源但事实上未能有效利用。
-
资源用量存在波峰波谷,很多在线业务都是有着规律性的服务高峰和低峰的,如通常白天负载较高,资源用量较大,而夜间在线访问降低,资源用量也会跌入低谷。
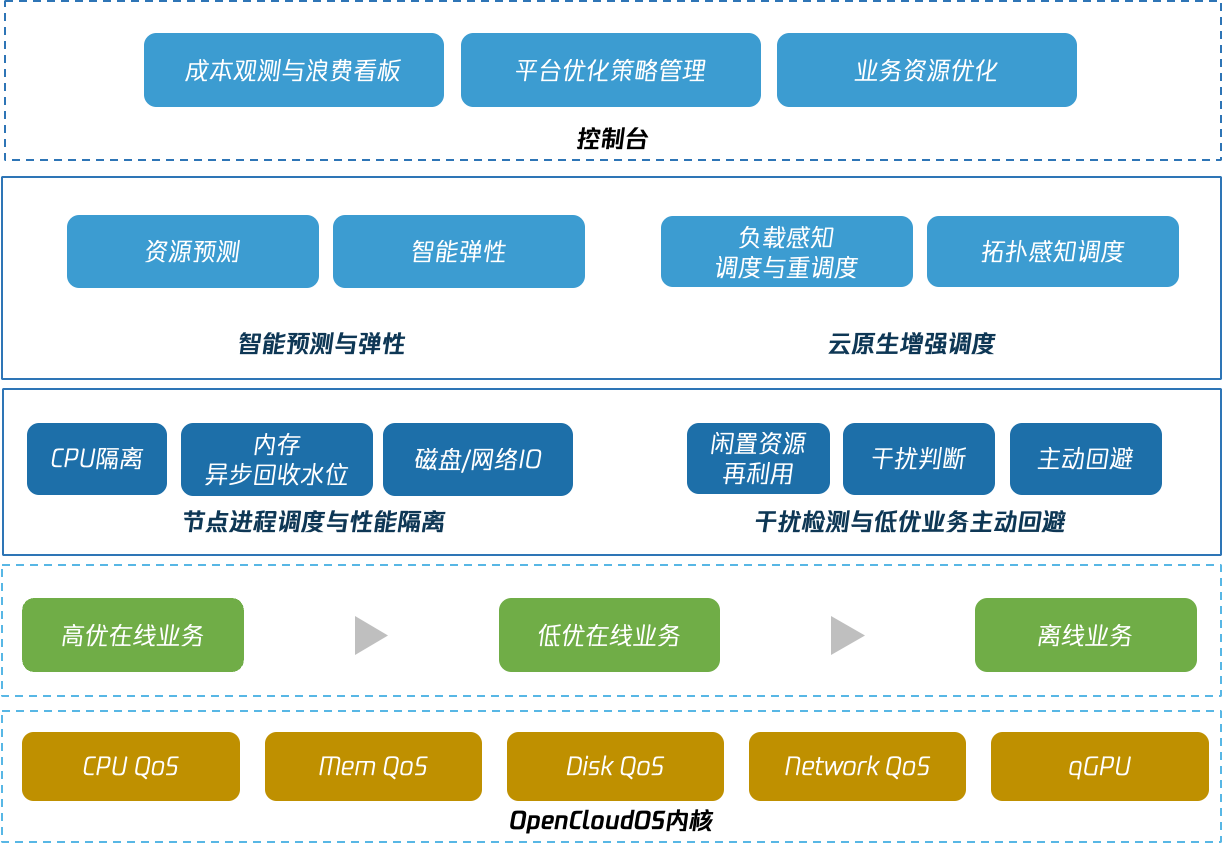
Crane提供了Request推荐、副本数推荐、HPA推荐以及EPA等业务优化能力,能辅助业务自动化决策进行资源配置优化。然而在较大的组织中,业务改需要所有业务组件负责人的支持和配合,周期长、见效慢。如何在不改造业务的前提下,迅速提升集群资源利用率,在提升部署密度的同时保证延迟敏感和高优业务的稳定性和服务质量不受干扰,Crane混部能力给出了答案。
Crane提供了高优敏感业务与低优批处理业务的混部能力,能将集群利用率提升3倍!
混部的核心挑战
所谓混部,就是将不同优先级的工作负载混合部署到相同集群中。一般来说,支撑在线服务的延迟敏感型(Latency Sensitive)业务优先级较高,支撑离线计算的高吞吐型(Batch)业务优先级通常较低。
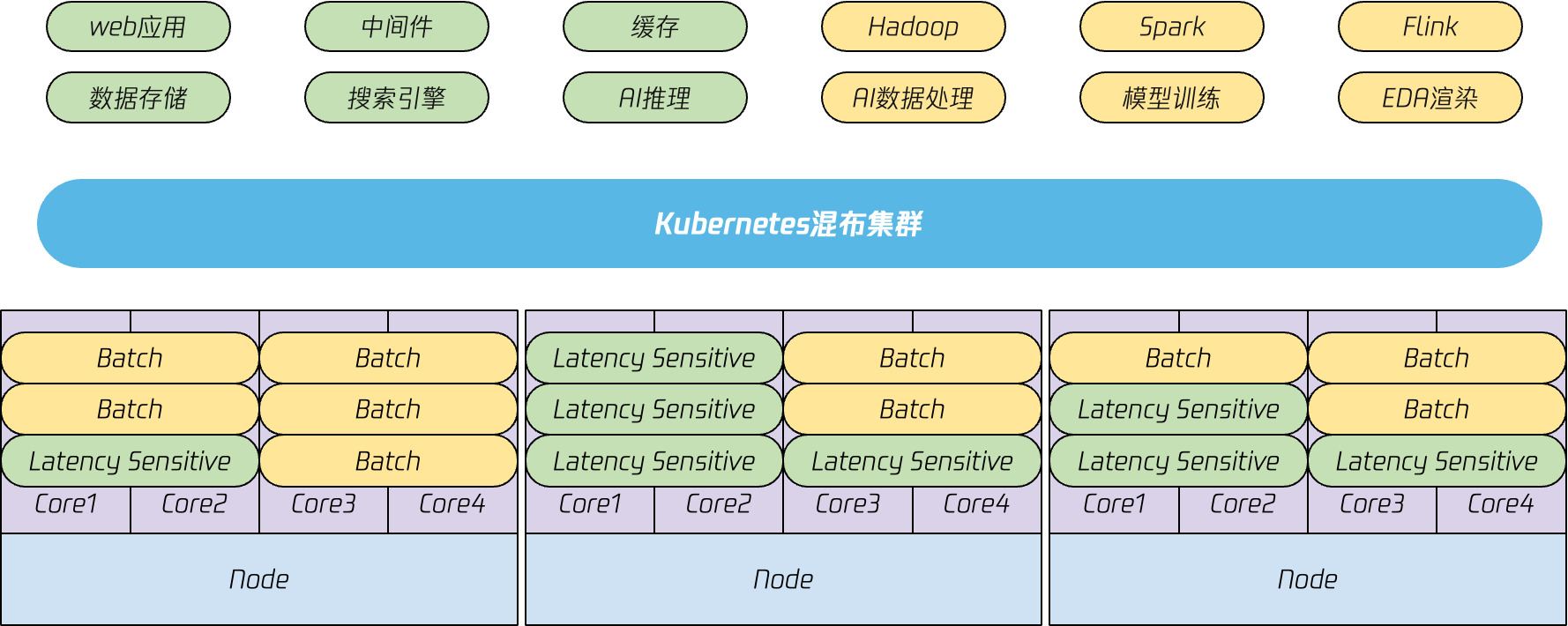
看起来将这些不同类型的业务部署在相同集群,复用计算资源,就可以有效提升资源利用率,那么为什么混部只有在顶尖科技公司才有大规模应用呢?理想很美好,现实很骨感,如果只是简单的将不同业务类型部署到一起,而不进行任何层面的资源隔离,那么在线业务服务质量必然会被影响,这也是为什么混部难以落地的核心原因。
干扰的来源
Kubernetes将计算资源分为不可压缩资源和可压缩资源。不可压缩资源是指物理内存等被应用程序独占的资源,在某个时刻一旦分配给某个进程,就不可以再被重新分配;可压缩资源是指比如可以分时复用的CPU资源,多个进程可以共享同一CPU核,虽然在CPU在某个时钟周期只为单一任务服务,但从宏观时间维度,CPU是可以同时服务于多个进程的。当多个进程都有CPU需求时,这些需求交给操作系统统一分配和调度。当多个进程争抢资源时,可能会导致应用性能下降,这便是我们所说的干扰。
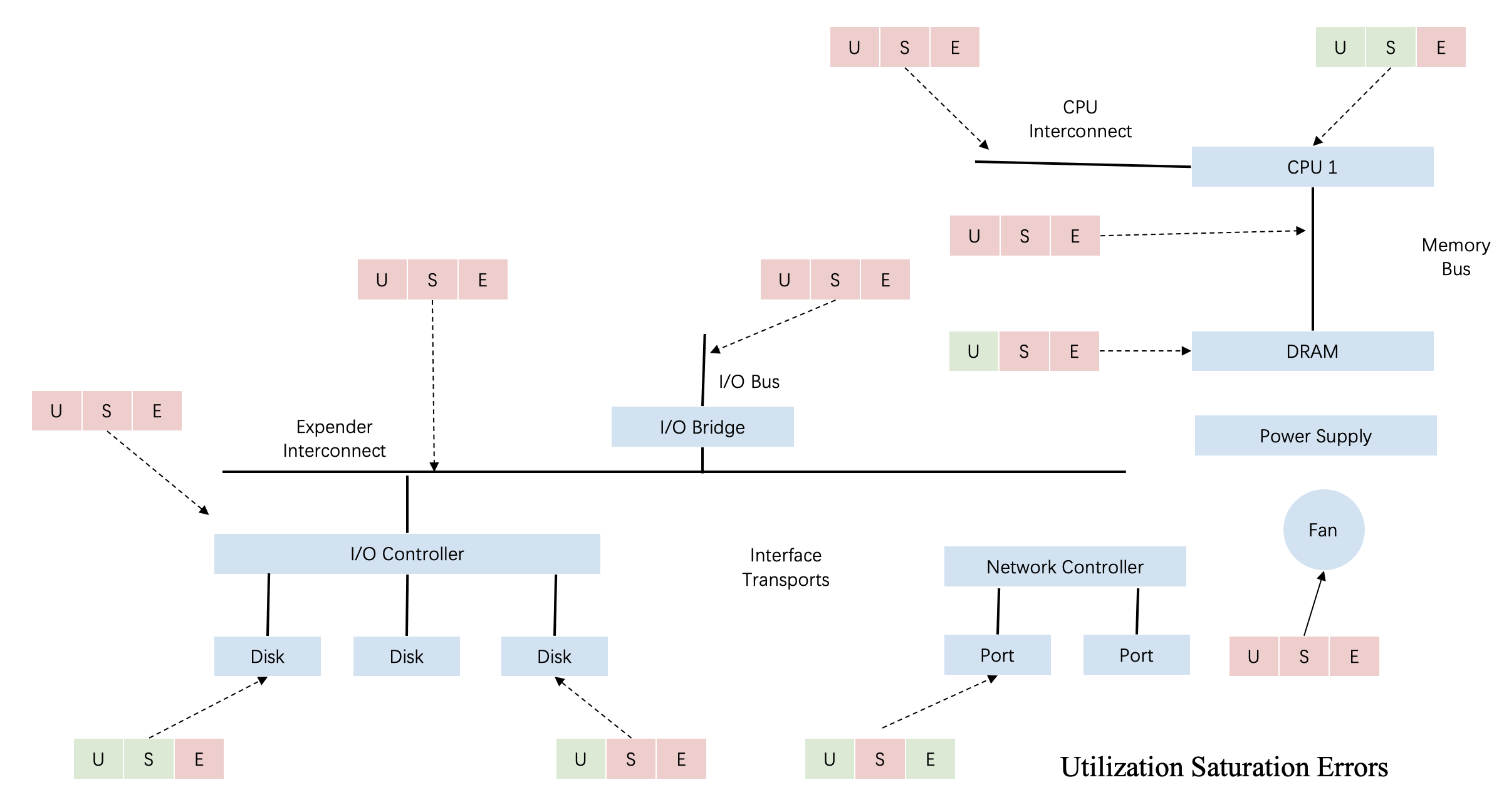
USE方法(Utilization,Saturation,Errors)是性能测试领域中广泛采用的指导理论。在评估系统性能时,通过资源利用率,饱和度和错误率,来迅速的定位资源的瓶颈和错误所在。如下图所示,针对不同资源都可以通过USE方法指导我们如何进行干扰检测。
首先从资源维度,干扰可能发生在任何一个资源维度,比如常见的CPU以及CPU相关的L1,、L2、LLC缓存、内存带宽、磁盘IO、网络IO等。其次从干扰发生的层级来看,干扰可能发生在应用代码、操作系统、硬件等不同层级。
对于应用而言,任何一环都可能成为干扰的来源;同时这些因素之间也会互相关联,例如应用网络流量上升,不仅会造成带宽的抢占,通常还会导致CPU资源消耗上升;又比如一个应用虽然计算逻辑简单,但需要频繁访问内存数据,如果此时缓存失效,则应用需要访问物理内存,而CPU负载会因为忙等而上升。
因此判断干扰是否发生,进一步寻找干扰源,并通过技术手段避免干扰是复杂的,这是干扰检测自动化门槛高的核心原因,如何能在关联的因素中识别干扰以及绕过表象找到真实的干扰源是混部需要解决的核心问题。
Crane的混部方案
Crane为混部场景提供了一套开箱即用的解决方案,借助Kubernetes CRD,该方案可灵活适配于多优先级的在线混部场景以及在离线混部场景,混部方案的能力概览如下:
- 节点负载画像与弹性资源回收 Crane实时采集节点利用率数据,并基于多种预测算法计算出未来的闲置资源,为节点构建画像,并将其以扩展资源形式更新成节点可调度资源。弹性资源的多少随高优业务真实用量变化,高优业务用量上升,弹性资源减少。
- 弹性资源再分配 低优业务使用弹性资源,调度器确保低优业务首次调度时有足够弹性资源可用,防止节点过载。
-
基于自定义水位线的干扰检测和主动回避能力
- NodeQoS API允许集群运维定义节点水位,包括总CPU水位,或者弹性资源分配率、弹性资源水位等,并定义当真实用量达到水位时的回避动作。
- PodQoS API 定义不同类型工作负载的资源隔离策略,如CPU调度优先级,磁盘IO等,同时定义该类型业务允许的回避动作。
- AvoidanceAction定义调度禁止、压制、驱逐等动作参数,当节点水位被触发,只有允许某个动作的业务Pod才可以执行该操作。
- 基于内核隔离的增强QoS能力 Crane的开源方案中,可以通过动态调节CGroup压制干扰源资源上限。同时,为支撑大规模生产系统的的隔离需求,Crane基于腾讯RUE内核,通过多级CPU调度优先级,以及绝对抢占等特性,保证高优业务不受低优业务的影响。
- 支持模拟调度的优雅驱逐等增强的重调度能力 当压制不足以抑制干扰时,就需要从节点中驱逐低优Pod以确保高优业务的服务质量。Crane支持模拟调度的优雅驱逐重调度能力能够借助集群全局视角和预调度能力降低重调度对应用的影响。
闲置资源回收
虽然Kubernetes提供了集群自动扩缩容能力,能够让云用户在业务负载降低时缩小集群规模,节省成本。然而集群扩缩容效率依赖基础架构和资源供给等因素约束,通常不是一个高频操作,绝大多数云用户的业务还运行在采用包年包月的固定节点池。
混部的第一步是从集群中识别出闲置资源并转换成可被临时借用的弹性算力,并更新成为节点可分配资源。Crane借助资源预测和本地实时检测两种手段计算节点可用弹性资源。
Crane Agent启动时会自动依据如下的默认模版为节点创建TSP对象,Craned中的资源预测组件获取该TSP对象以后立即读取节点资源用量历史,通过内置预测算法进行预测,并将预测结果更新至TSP.Status。
apiVersion: v1
data:
spec: |
predictionMetrics:
- algorithm:
algorithmType: dsp
dsp:
estimators:
fft:
- highFrequencyThreshold: "0.05"
lowAmplitudeThreshold: "1.0"
marginFraction: "0.2"
maxNumOfSpectrumItems: 20
minNumOfSpectrumItems: 10
historyLength: 3d
sampleInterval: 60s
resourceIdentif ier: cpu
type: ExpressionQuery
expressionQuery:
expression: 'sum(count(node_cpu_seconds_total{mode="idle",instance=~"({{.metadata.name}})(:\\d+)?"}) by (mode, cpu)) - sum(irate(node_cpu_seconds_total{mode="idle",instance=~"({{.metadata.name}})(:\\d+)?"}[5m]))'
predictionWindowSeconds: 3600
kind: ConfigMap
metadata:
name: noderesource-tsp-template
namespace: default
Crane Agent中的Node Resource Controller组件周期性检测该节点的实时负载信息,并按如下公式计算实时弹性CPU:
弹性CPU = 节点可分配CPU*(1-预留比例) -(节点实际CPU用量 - 弹性资源用量 + 绑核业务独占的CPU)
- 节点可分配CPU:节点可分配CPU,即Node.Status.Allocatable.CPU
- 预留比例:保证始终有一定的空闲资源不能被复用,保证集群的稳定
- 节点实际CPU用量:节点实际的CPU用量,即node_cpu_seconds_total
- 弹性资源用量:节点实际用量包含了使用弹性资源的部分业务,而这部分开销是是弹性资源,因此需要算入弹性CPU中
- 绑核业务独占的CPU:被业务绑定的CPU不可二次分配,因此需要再弹性CPU中扣除
Node Resource Controller 同时监听节点TSP对象变化,当读取到TSP对象的状态变化时,同时参考本地实时可回收弹性资源以及预测结果,并取其中较小的值更新为节点弹性资源gocrane.io/cpu。内存等其他资源原理与CPU一致。

弹性资源使用
弹性资源更新成为节点Allocatable Resource以后,低优业务即可通过资源声明将弹性资源利用起来,Kubernetes调度器确保节点弹性资源能够满足业务需求才能成功调度。
spec:
containers:
- image: nginx
name: extended-resource-demo
resources:
limits:
gocrane.io/cpu: "2"
gocrane.io/memory: "2000Mi"
requests:
gocrane.io/cpu: "2"
gocrane.io/memory: "2000Mi"
干扰检测与主动回避
弹性资源再分配能有效提升单节点业务部署密度,而更高的部署密度意味着业务面临的资源竞争的可能性更大。Crane实时对节点和应用进行多维度的指标检测,通过灵活可配的异常定义规则和筛选策略,判断干扰是否发生,并且在干扰发生时牺牲低优Pod以确保高优业务的服务等级不变。
全维度指标采集
Crane Agent通过多种手段收集全维度指标,将这些指标统一保存在stateMap中,用于资源回收和干扰检测。
基于多种手段: 通过解析系统文件、调用cAdvisor接口、eBPF Hook等多种手段,采集包括CPU 利用率、CPI、虚拟机CPU Steal Time、内存利用率、进出网络流量和磁盘读写IO等指标,Crane用户也可以编写插件采集自定义指标。
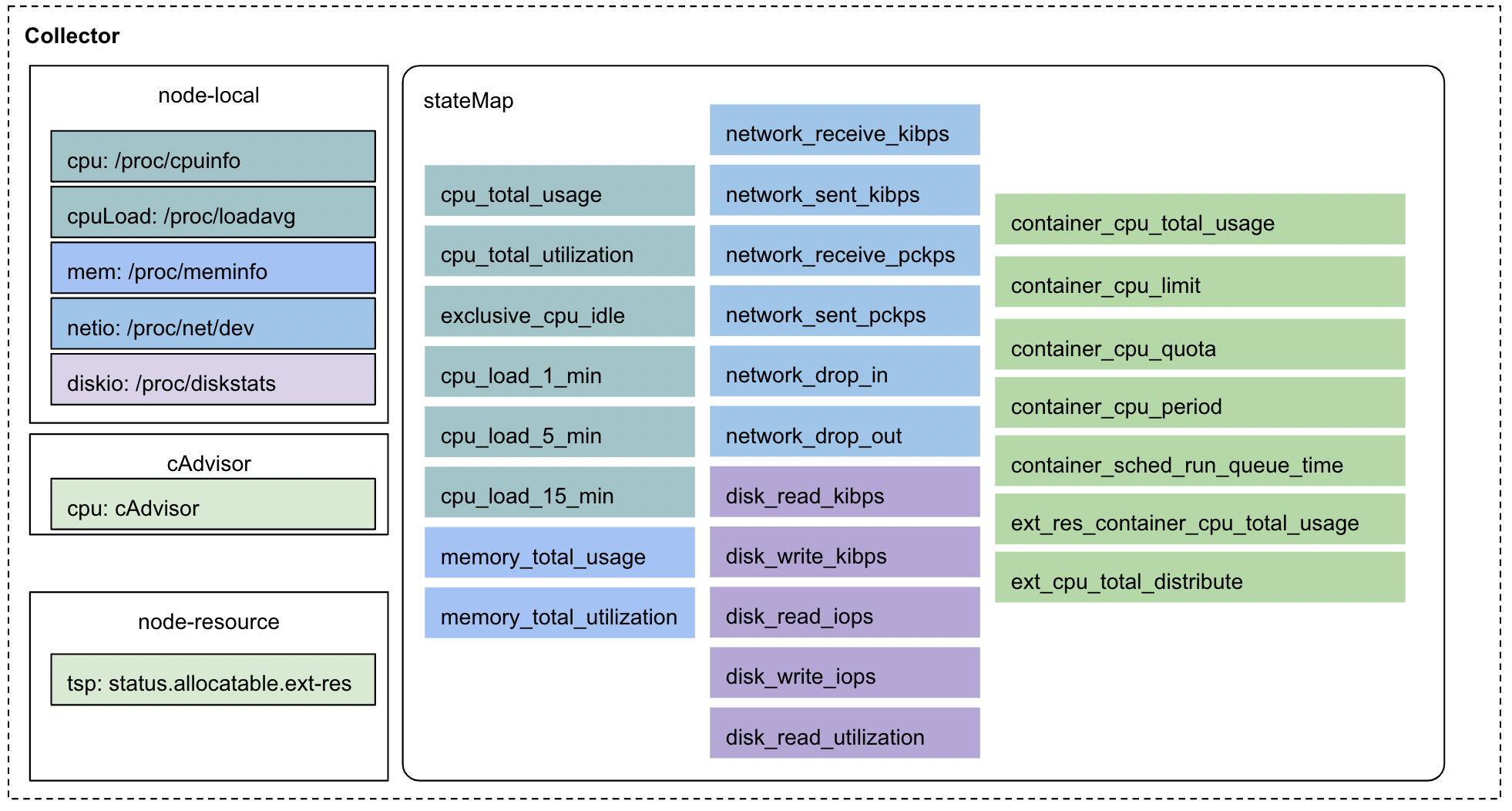
完整的指标检测有助于干扰的分析,为之后更为完善的应用画像,应用特性分析,应用之间的干扰情况提供充分的依据。
干扰判断
下图展示了Crane Agent的核心组件,在State Collector定期采集全维度指标以后,stateMap会交由Analyzer进行干扰判断。
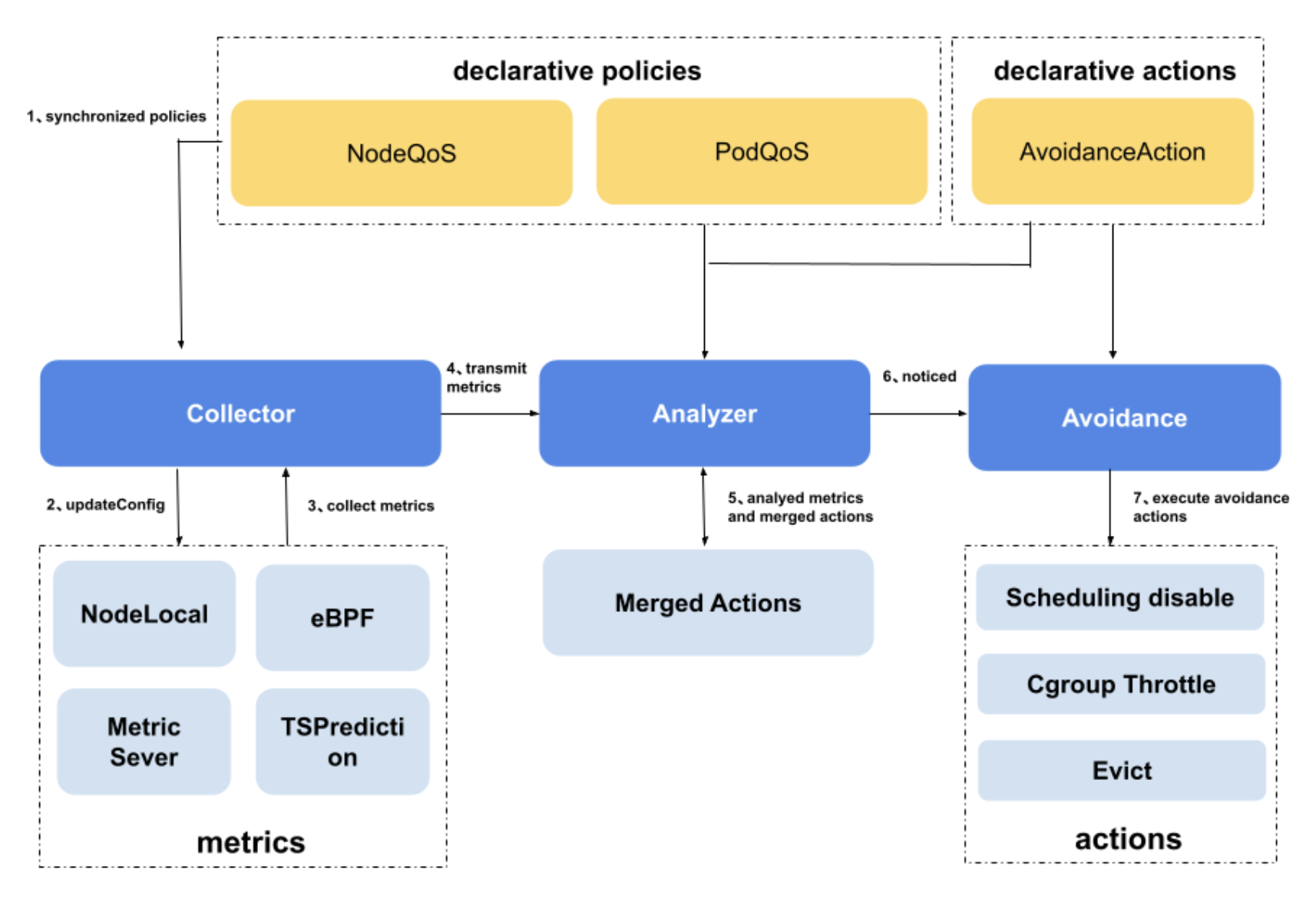
当前的干扰判断规则沿用了Kubernetes健康检查的判断逻辑,用户可基于NodeQOS对象定义干扰判断规则。该对象可定义指标采集规则,干扰判断所依赖的指标名称以及其对应的干扰水位线等,同时通过AvoidanceAction定义干扰发生时需要执行的回避动作,详情参见下面的配置示例:
apiVersion: ensurance.crane.io/v1alpha1
kind: NodeQOS
metadata:
name: "cpu-usage-percent-watermark"
spec:
nodeQualityProbe:
timeoutSeconds: 10
nodeLocalGet:
localCacheTTLSeconds: 60
rules:
- name: "cpu-usage-percent"
avoidanceThreshold: 2 # 当达到阈值并持续多次,则规则被触发
restoreThreshold: 2 # 当阈值未达到并继续多次, 则规则恢复
actionName: "throttle" # 当触发阈值时执行的 AvoidanceAction 名称
strategy: "None" # 动作的策略,可以将其设置为Preview以不实际执行
metricRule:
name: "cpu_total_utilization" # 水位线指标名称
value: 80 # 水位线指标的阈值,cpu用量达到80%NodeQOS中的actionName属性关联了回避动作的名称,需要创建AvoidanceAction对象完成回避动作的完整参数配置,当前支持 Scheduling Disable(关闭节点调度)、Throttle(通过Cgroup调节Pod的可用资源上限), Eviction(驱逐Pod)三类操作操作;同时,如果节点干扰消失,Crane Agent也会自行执行逆操作,恢复节点和业务的资源配置状态。
下面的AvoidanceAction示例展示了如何通过调节CGroup对Pod的可用资源进行压制:
apiVersion: ensurance.crane.io/v1alpha1
kind: AvoidanceAction
metadata:
name: throttle
labels:
app: system
spec:
coolDownSeconds: 300
throttle:
cpuThrottle:
minCPURatio: 10 #CPU 配额的最小比例,Pod不会被限制低于此值
stepCPURatio: 10 #在触发的回避动作中减少相应Pod的CPU配额占比,也是恢复动作中增加的CPU配额占比
description: "throttle low priority pods"
压制目标的选择
NodeQOS定义了干扰判断规则以及当干扰发生时需要执行的回避动作,那么回避动作会应用在哪些对象上呢?
Crane针对Kubelet内置驱逐规则做了一定程度的扩展,这些内置规则包括:
- 是否使用了弹性资源
- 比较优先级与QOSClass
- 比较CPU/内存用量的绝对值
- 比较实际用量与弹性资源上限的比值
- 运行时间等
Crane用户也可以针对自定义水位线指标实现特定的驱逐选择规则。
除此之外,Crane用户可以通过定义PodQOS来定义特定Namespace、特定优先级、特定标签的Pod允许执行特定的驱逐动作。如下面的例子,为有preemptible_job: “true”标签的离线BestEffort Pod配置可被压制操作。通过PodQOS的精细化管控,我们实现了业务侧的个性化需求:比如 logstash服务的负责人希望这类业务接受驱逐但不接受压制;而运行了数个星期的AI训练任务宁愿被压制而不是被驱逐。
apiVersion: ensurance.crane.io/v1alpha1
kind: PodQOS
metadata:
name: all-elastic-pods
spec:
allowedActions:
- throttle
labelSelector:
matchLabels:
preemptible_job: "true"
scopeSelector:
matchExpressions:
- operator: In
scopeName: QOSClass
values:
- BestEffort
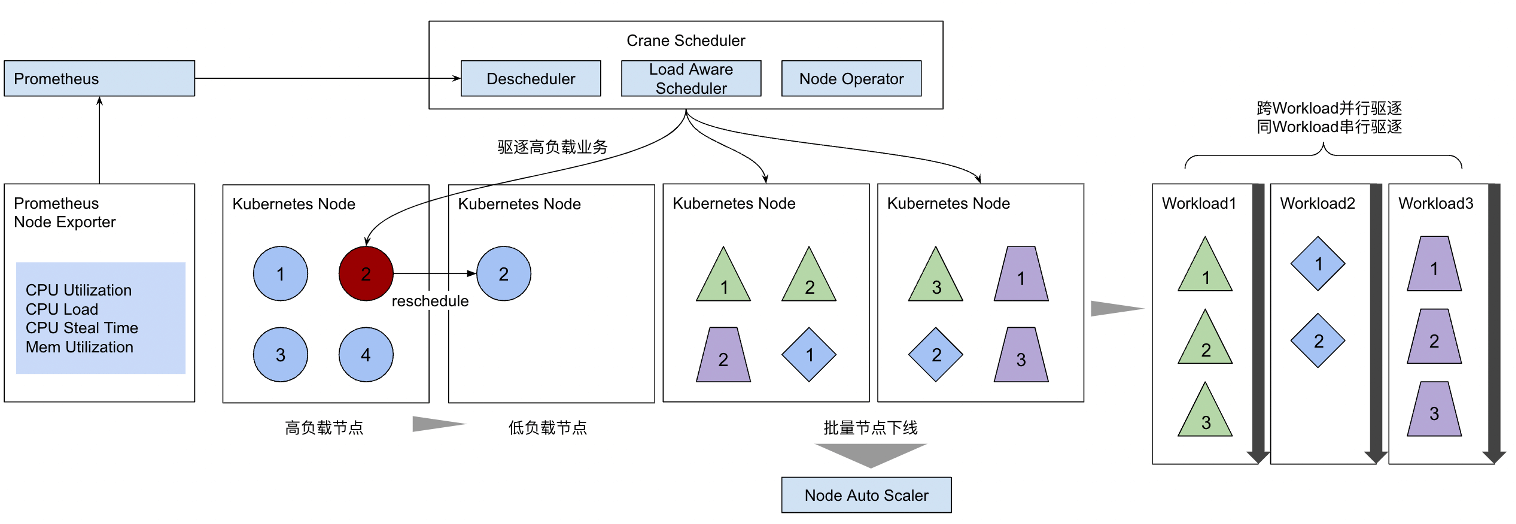
支持优雅驱逐的重调度器
Crane Agent是运行在每个节点的Daemonset Pod,它所做的决策都是基于节点而缺乏全局视角。当多个节点同时发生干扰,Agent需要对某低优业务进行驱逐时,若无PDB对最大可用副本数进行保护,很可能会导致该业务的多个Pod同时被驱逐,进而造成服务质量下降。 Crane Agent支持与中心化部署的重调度器联动,由Crane Agent为待驱逐Pod打上标签,并交由重调度器统一进行驱逐。 Crane增强的Descheduler支持优雅驱逐能力,包括:
- 支持模拟调度,集群资源不足时可停止驱逐,该过程模拟Filter,PreFilter过程,不仅包含了Scheduler默认包含的插件,同时支持调度器扩展插件,模拟实际调度过程
- 有全局视图,在多Workload并行,同一Workload内串行驱逐,适用于固定时间窗口腾空节点和基于特定标签批量驱逐Pod/Workload/母机的场景
-
可以通过先扩容后缩容的方式实现无感驱逐,保证Workload可用性
RUE内核提供混部的稳定底座
如意,TencentOS RUE(Resource Utilization Enhancement),是 TencentOS 产品矩阵 中一款专为云原生场景下服务器资源 QoS 设计,提升资源利用率,降低运营成本的产品。如意统一调度分配云上机器的 CPU、IO、网络、内存等资源,相比传统的服务器资源管理方案,如意更适用于云场景,能够显著提升云上机器的资源使用效率,降低云上客户的运营成本,为公有云、混合云、私有云等客户提供资源增值服务。如意的核心技术能做到不同优先级的业务之间不互相干扰,实现资源利用率、资源隔离性能、资源服务质量的高效统一。
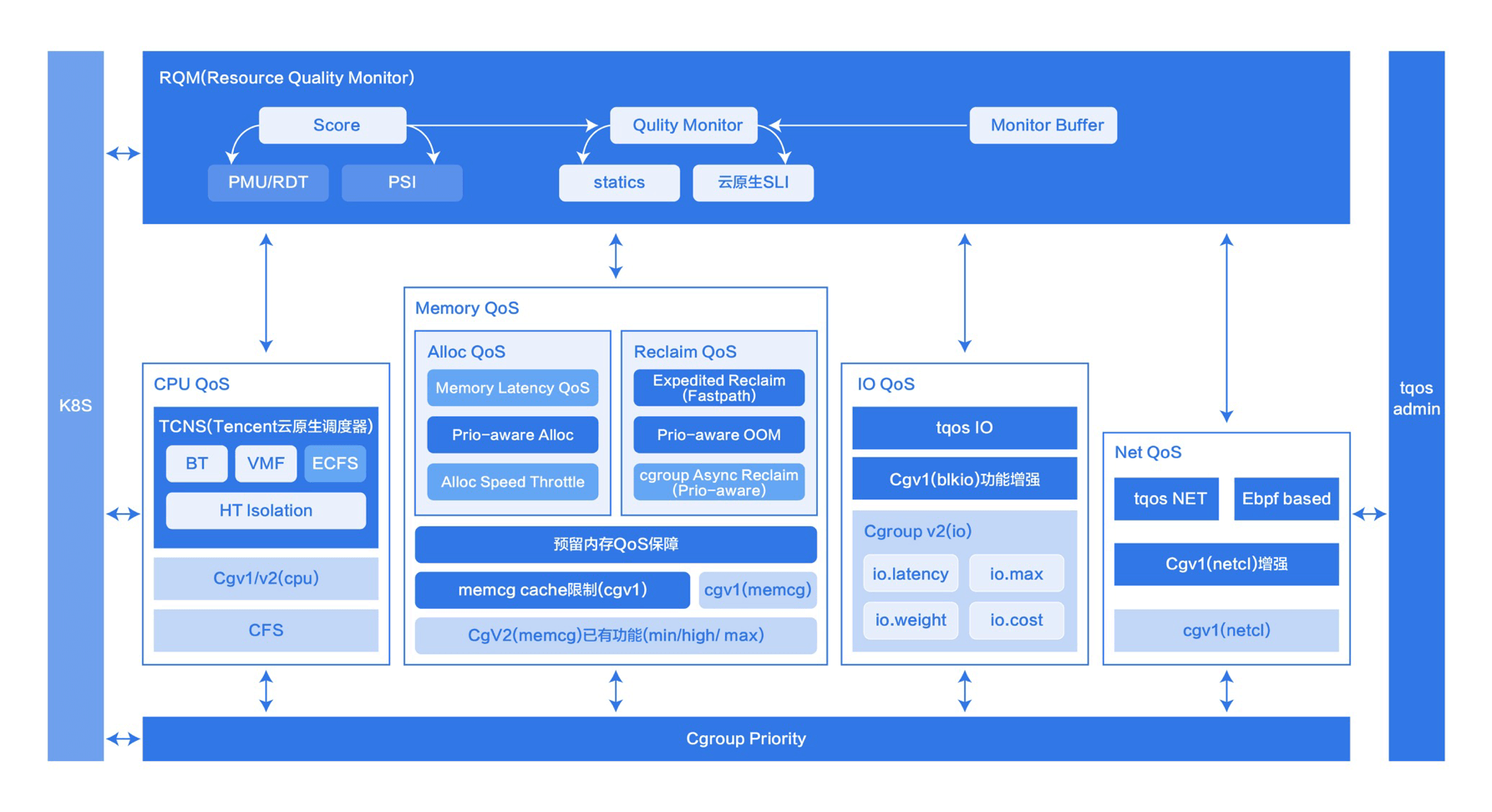
相比传统的资源管理方案,如意具有以下特点:
- 为云而生:对接 K8S 等主流资源管理平台,以容器为对象进行资源调度。
- 多优先级:支持三档基础优先级,支持更多优先级扩展。
- 多种资源:对CPU、IO、网络、内存等服务器资源进行全面统一调度。
- 资源隔离:低优先级器可以使用空闲资源,不会对高优先级容器造成影响。
- 稳定有效:在腾讯云百万级别数据中心上验证,服务众多客户。
以干扰最容易发生的CPU资源为例,如意CPU QoS 允许用户将服务器上的容器划分成不同优先级,根据优先级分配 CPU 资源,保障低优先级容器不会对高优先级容器造成干扰(包括调度时延,CPU 使用时间等),同时允许低优先级容器使用空闲 CPU 资源,从而提升 CPU 利用率,降低计算成本。
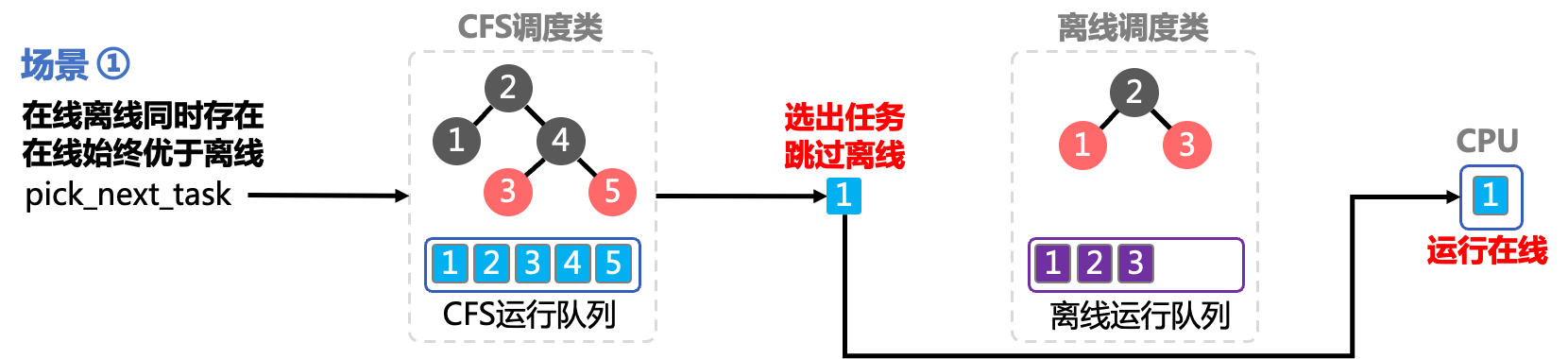


Crane涵盖了RUE的大部分功能,涉及CPU,内存,IO,网络等多个维度,通过PodQOS和NodeQOS为应用提供批量化的RUE隔离能力,使得用户无需关注复杂的CGroup配置便能轻松实现内核层面的资源隔离和保障。
最佳实践
安装配置
参考
教程
安装 Crane 和 Fadvisor
部分,即可安装Crane-Agent和Crane,其中NodeResource作为FeatureGate控制弹性资源复用功能的开启,目前默认开启,用户无需配置;如需使用到节点弹性资源TSP预测,需要同时部署监控组件,参考
教程
安装 Prometheus 和 Grafana
部分,CraneTimeSeriesPrediction作为FeatureGate控制预测功能的开启,默认开启,用户无需再做配置。
Crane-Agent支持Docker和Containerd,自动探测无需用户配置;支持cgroupfs,systemd两种cgroup-driver,默认使用cgroupfs,如需更改,command添加–cgroup-driver=”systemd”即可。
下面以将业务分为高低两个优先级为例说明如何配置使用;
- 通过PodQOS支持的scopeSelector为业务做区分和分级;同时配置低优先级的资源配置使用弹性资源,如gocrane.io/cpu
- 为每级业务创建对应的PodQOS,指定其对应范围和允许的回避动作以及资源隔离策略
- 创建NodeQOS指定一条或多条水位线和对应的回避操作,比如60%时开始压制,70%时开始驱逐等
apiVersion: ensurance.crane.io/v1alpha1
kind: PodQOS
metadata:
name: high
...
allowedActions:
scopeSelector:
...
resourceQOS:
cpuQOS:
cpuPriority: 0
apiVersion: ensurance.crane.io/v1alpha1
kind: PodQOS
metadata:
name: low
...
allowedActions:
- eviction
scopeSelector:
...
resourceQOS:
cpuQOS:
cpuPriority: 7
apiVersion: ensurance.crane.io/v1alpha1
kind: NodeQOS
metadata:
name: "watermark"
...
actionName: throttle
metricRule:
name: cpu_total_utilization
value: 70
Housekeeper
随着 Housekeeper(腾讯云原生运维新范式)的推出,QoS Agent 已经结合原生节点的能力提供了可抢占式 Job 的能力。该类型 Job 使用的资源是集群中的闲置资源,不占用集群/节点真实的剩余可调度量,在发生资源竞争时,该部分资源会被优先回收,保证正常使用节点资源的业务的稳定性。更多请参考:可抢占式Job(
https://cloud.tencent.com/document/product/457/81751)
扩展阅读
混部在离线作业调度时应优先选择满足弹性资源用量中真实负载较低的节点进行部署,避免节点负载不均;同时,需保障高优和延迟敏感业务的资源诉求,如调度到资源宽裕的节点,满足NUMA拓扑的绑核需求等。Crane通过真实负载调度和CPU拓扑感知调度满足了如上需求,具体可参考
Crane-Scheduler
和
CPU拓扑感知调度
。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
