一、预备知识
1、java的内存区
众所周知,java程序是运行在java虚拟机(Java Virtual Machine即JVM)上的,而JVM中有一个专门负责给java程序分配内存的区域,叫运行时数据区(Java Memory Allocation Area),也叫虚拟机内存或者java内存.为了不使内存数据杂乱无章,java内存通常被分为5个区域:程序计数器、本地方法栈、方法区、栈、堆。
我们主要了解一下栈(Stack)、堆(Heap)、方法区中的常量池(Constant Pool)
2、栈(Stack)
栈:又叫堆栈。JVM为每个新创建的线程都分配一个栈。也就是说,对于一个Java程序来说,它的运行就是通过对栈的操作来完成的。栈以帧为单位保存线程的状态。JVM对栈只进行两种操作:以帧为单位的压栈和出栈操作。该区域具有先进后出的特性。
3、堆(Heap)
堆:堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域。在此区域的唯一目的就是存放对象实例,几乎所有的对象实例都是在这里分配内存,但是这个对象的引用却是在栈(Stack)中分配。
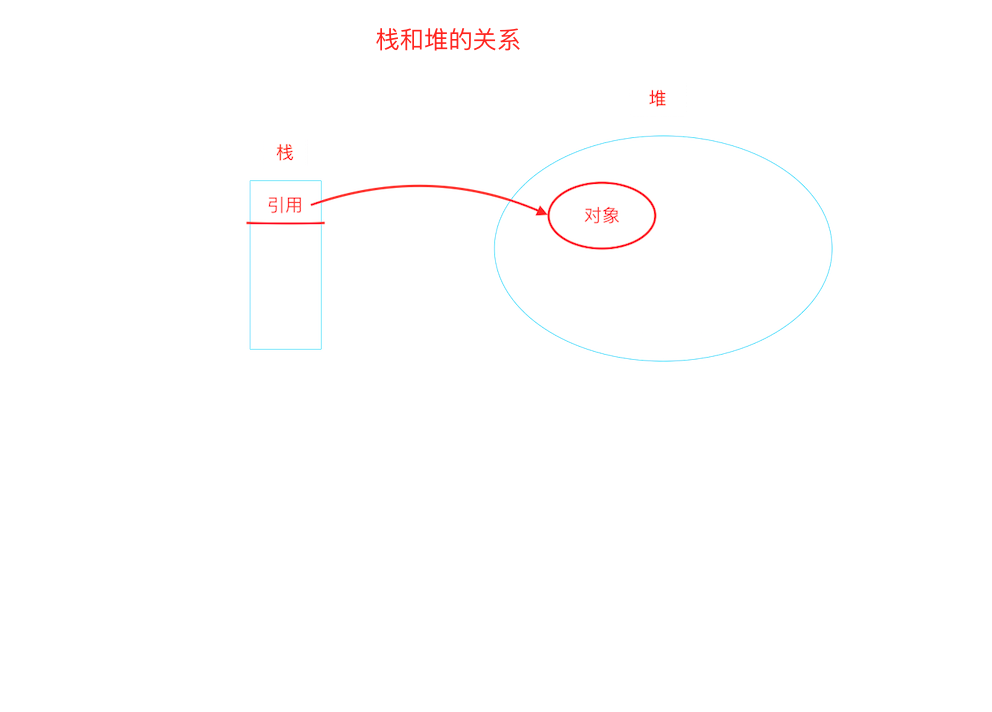
4、常量池(Constant Pool)
常量池:方法区(被所有线程共享)中会存放一些从class文件包含的二进制数据中解析的类型信息,包括类信息、常量、静态变量等。常量池是方法区中一块特殊的内存区域。
二、String类型
1、String类型的定义:
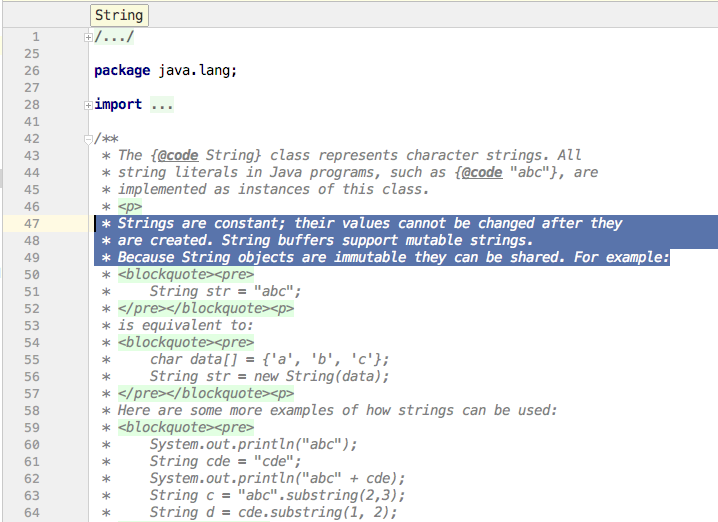
上图是String类型源码中的注释,注意看被选中的这小段话Strings are constant; their values cannot be changed after they are created.
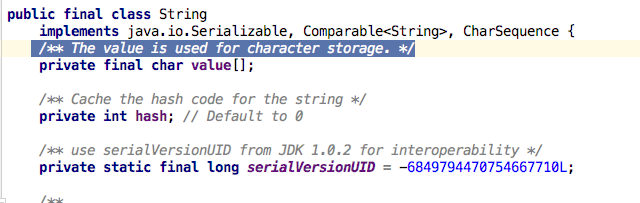
这是定义中的一部分,可以看到The value is used for character storage.
所以实质上是字符数组,且由于定义中的final,String类不可被继承且不变
2、常量池再探
什么是常量
用final修饰的成员变量表示常量,值一旦给定就无法改变!
final修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。
Class文件中的常量池
在Class文件结构中,最头的4个字节用于存储魔数Magic Number,用于确定一个文件是否能被JVM接受,再接着4个字节用于存储版本号,前2个字节存储次版本号,后2个存储主版本号,再接着是用于存放常量的常量池,由于常量的数量是不固定的,所以常量池的入口放置一个U2类型的数据(constant_pool_count)存储常量池容量计数值。
常量池主要用于存放两大类常量:字面量 (Literal)和 符号引用量 (Symbolic References),字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,符号引用则属于编译原理方面的概念,包括了如下三种类型的常量:类和接口的全限定名
字段名称和描述符
方法名称和描述符
方法区中的运行时常量池运行时常量池是方法区的一部分。
CLass文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
运行时常量池相对于CLass文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的intern()方法。
常量池的好处
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
3、从String的相等性比较看String类型的内存分配
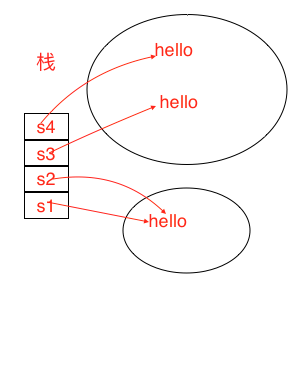
先定义几个String变量1
2
3
4String s1=”test”;
String s2=”test”;
String s3=new String(“test”);
String s4=new String(“test”);
然后做相等性比较1
2
3System.out.println(s1==s2);//true
System.out.println(s1==s3);//false
System.out.println(s3==s4);//false
首先注意到定义String变量有两种方式,一种是直接String s1=”str”,另外一中是使用new关键字来定义
对于第一种方法,看一段<>中的话:When the compiler encounters a String literal, it checks to see if an identical String already exists in the pool.
当编译器遇到一个String类型的字面量时,他首先检查看看常量池中是否已经存在相同的String量,如果没有,就在常量池里新建一个,如果已经存在,则直接指向
常量池中这个已经存在的量.
对于第二种方法,则是在堆中创建新的内存空间,不考虑该String类型对象的值是否已经存在。始终在堆区中开辟新的内存,所以怎样用==比较都是不会相等的
如图:
以上,已经算是简单的讲完了。好像有点高高举起,轻轻放下之嫌,但不举起,其实是不好讲的:)