基本介绍
一.概念
1.MapReduce是Hadoop提供的一套进行分布式计算机制
2.MapReduce是Doug Cutting根据Google的论文来仿照实现的
3.MapReduce会将整个计算过程拆分为2个阶段:Map阶段和Reduce阶段。在Map阶段,用户需要考虑对数据进行规整和映射;在Reduce阶段,用户需要考虑对数据进行最后的规约
二.特点
1.优点
a.易于编程:MapReduce提供了相对简单的编程模型。这就保证MapReduce相对易于学习。用户在使用的时候,只需要实现一些接口或者去继承一些类,覆盖需要实现的逻辑,即可实现分布式计算
b.具有良好的可扩展性:如果当前集群的性能不够,那么MapReduce能够轻易的通过增加节点数量的方式来提高集群性能
c.高容错性:当某一个节点产生故障的时候,MapReduce会自动的将这个节点上的计算任务进行转移而整个过程不需要用户手动参与
d.适合于大量数据的计算,尤其是PB级别以上的数据,因此MapReduce更适合于离线计算
2.缺点:
a.不适合于实时处理:MapReduce要求处理的数据是静态的,实时的特点在于数据池是动态的
b.不擅长流式计算:MapReduce的允许效率相对较低,在处理流式计算的时候,效率更低
c.不擅长DAG(有向图)运算:如果希望把上一个MapReduce的运行结果作为下一个MapReduce的输入数据,那么需要手动使用工作流进行调度,而MapReduce本身没有这种调度功能
三.入门案例
1.案例:统计文件中每一个非空字符串出现的次数
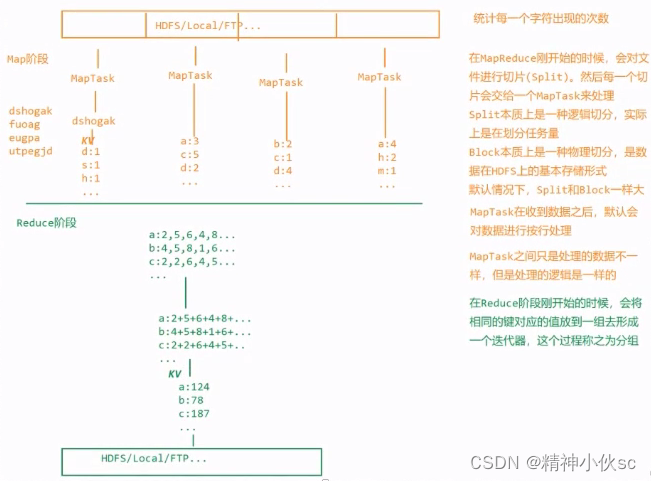
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//用于完成Map阶段
//在MapReduce中,要求被处理的数据能够被序列化
//MapReduce提供了一套序列化机制
//KEYIN - 输入的键的类型。如果不指定,那么默认情况下,表示行的字节偏移量
//VALUEIN -输入的值的类型,如果不指定,那么默认情况下,表示的读取到的一行数据
//KEYOUT - 输出的键的类型。当前案例中,输出的键表示的是字符
//VALUEOUT - 输出的值的类型。当前案列中,输出的值表示的是次数
public class CharCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
private final LongWritable once = new LongWritable(1);
//覆盖map方法,将处理逻辑写到这个方法中
//key:键。表示的是行的字节偏移量
//value:值。表示读取到的一行数据
//context:配置参数
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//将一行数据中的字符拆分出来
char[] cs = value.toString().toCharArray();
//假设数据时hello,那么拆分出来的数据中包含的就是{'h','e','l','l','o'}
//可以写出h:1 e:1 l:2 o:1
//可以写出h:1 e:1 l:1 l:1 o:1
for (char c : cs) {
context.write(new Text(c+""), once);
}
}
}
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//KEYIN,VALUEIN - 输入的键值类型。Reducer的数据从Mapper来的,所以Mapper的输出就是Reducer的输入
//KEYOUT,VALUEOUT - 输出的键值类型。当前案列中,要输出每一个字符对应的总次数
public class CharCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
//覆盖reduce方法,将计算逻辑写到这个方法中
//key:键。当前案列中,键是字符
//values:值。当前案例中,值是次数的集合对应的迭代器
//context:配置参数
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Contxt context) throw IOException, InterruptedException{
//key = 'a'
//values ={1,1,1,1,1,1...}
//定义变量来记录总次数
int sum = 0;
for(LongWritable value : values){
sum +=value.get();
}
context.write(key, new LongWritable(sum));
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CharCountDriver {
public static void main(String[] args) throw IOException{
//构建环境变量
Configuration conf = new Configuration();
//构建任务
Job job = Job.getInstance(conf);
//设置入口类
job.setJarByClass(CharCountDriver.class);
//设置Mapper类
job.setMapperClass(CharCountReducer.class);
//设置Reducer类
job.setReducerClass(CharCountReducer.class);
//设置Mapper的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置Reducer的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输入路径
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/text/characters.txt"));
//设置输出路径 - 要求输出路径必须不存在
FileOutputFormat.addOutputPath(job, new Path("hdfs://hadoop01:9000/result/char_count.txt"));
//提交任务
job.waitForCompletion(true);
}
}
组件
一.序列化
1.在MapReduce中,要求被处理的数据能够被序列化。MapReduce提供了单独的序列化机制 – MapReduce底层的序列化机制是基于AVRO实现的。为了方便操作,在AVRO的基础上,MapReduce提供了更简单的序列化形式 – 只需要让被序列化的对象对应的类实现Writeable接口,覆盖其中的write和readFields方法
2.MapReduce针对常见类型提供了基本的序列化类
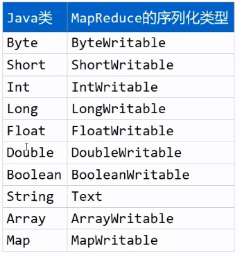
3.在MapReduce中,要求被序列化的对象对应的类中必须提供无参构造
4.在MapReduce中,要求被序列的对象的属性值不能为null
5.案例:统计一个人花费的上行流量和下行流量
/*
手机 地区 姓名 上行流量 下行流量
1860000000 bj zs 4252 5236
1860000001 bj ls 5264 2152
1860000002 sh wl 5256 3256
1860000000 bj zd 9252 9236
1860000001 bj ll 5864 4152
1860000002 sh ww 5256 6256
*/
public class Flow implements Writable{
private int upFlow;
private int downFlow;
public int getUpFlow(){return upFlow;}
public void setDownFlow(int upFlow){this.upFlow = upFlow;}
public int getDownFlow(){return downFlow;}
public void setDownFlow(int downFlow){this.downFlow = downFlow;}
//需要将有必要的属性以此序列化写出即可
@Override
public void write(DataOutput out) throws IOException{
out.writeInt(getUpFlow());
out.writeInt(getDownFlow());
}
@Override
public void readFields(DataInput in) throws IOException{
setUpFlow(in.readInt());
setDownFlow(in.readInt());
}
}
public class SerialFlowMapper extends Mapper<LongWritable, Text, Text, Flow>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//1860000000 bj zs 4252 5236
//拆分字段
String[] arr = value.toString().split(" ");
//封装对象
Flow f = new Flow();
f.setUpFlow(Integer.parseInt(arr[3]));
f.setDownFlow(Integer.parseInt(arr[4]));
context.write(new Text(arr[2]), f);
}
}
public class SerialFlowReducer extends Reducer<Text, Flow, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException{
int sumUp = 0;
int sumDown = 0;
for (Flow value : values){
sumUp += value.getUpFlow();
sumDown += value.getDownFlow();
}
context.write(key, new Text(sumUp + "\t" + sumDown));
}
}
public class SerialFlowDriver {
public static void mian(String[] args) throws IOException, ClassNotFoundException,InterruptedException
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SerialFlowDriver.class);
job.setMapperClass(SerialFlowDriver.class);
job.setReducerClass(SerialFlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/txt/flow.txt"));
FileOutputFormat.addOutputPath(job, new Path("hdfs://hadoop01:9000/result/serial_flow.txt"));
job.waitForCompletion(true);
}
}
二.Partitioner – 分区
1.在MapReduce中,分区用于将数据按照指定的条件来进行分隔,本质上就是对数据进行分类
2.在MapReduce中,如果不指定,那么默认使用的是HashPartitioner
3.实际过程中,如果需要指定自己的分类条件,那么需要自定义分区
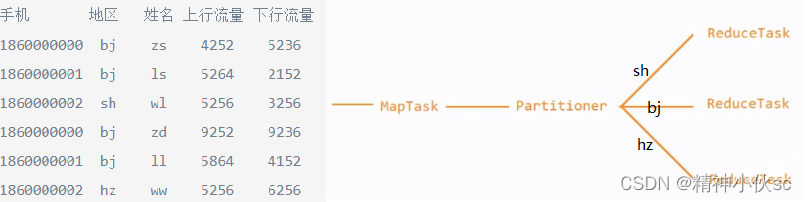
4.案例:分地区统计每一个人花费的总流量
5.在MapReduce中,需要对分区进行编号,编号从0开始依次往上递增
6.在MapReduce中,如果不指定,那么默认只有1个ReduceTask,每一个ReduceTask会对应一个结果文件。也因此,
如果设置了Partitioner,那么需要给定对应数量的ReduceTask
– 分区决定了ReduceTask的数量
/*
按地区分区:分地区统计每一个人花费的总流量
手机 地区 姓名 上行流量 下行流量
1860000000 bj zs 4252 5236
1860000001 bj ls 5264 2152
1860000002 sh wl 5256 3256
1860000000 bj zd 9252 9236
1860000001 bj ll 5864 4152
1860000002 hz ww 5256 6256
*/
public class Flow implements Writable{
private String city = "";
private int upFlow;
private int downFlow;
public String getCity(){return city;}
public void setCity(String city){this.city = city;}
public int getUpFlow(){return upFlow;}
public void setDownFlow(int upFlow){this.upFlow = upFlow;}
public int getDownFlow(){return downFlow;}
public void setDownFlow(int downFlow){this.downFlow = downFlow;}
//需要将有必要的属性以此序列化写出即可
@Override
public void write(DataOutput out) throws IOException{
out.writeUTF(getCity());
out.writeInt(getUpFlow());
out.writeInt(getDownFlow());
}
@Override
public void readFields(DataInput in) throws IOException{
setCity(in.readUTF());
setUpFlow(in.readInt());
setDownFlow(in.readInt());
}
}
public class PartFlowMapper extends Mapper<LongWritable, Text, Text, Flow>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//1860000000 bj zs 4252 5236
//拆分字段
String[] arr = value.toString().split(" ");
//封装对象
Flow f = new Flow();
f.setCity(arr[1]);
f.setUpFlow(Integer.parseInt(arr[3]));
f.setDownFlow(Integer.parseInt(arr[4]));
context.write(new Text(arr[2]), f);
}
}
public class PartFlowReducer extends Reducer<Text, Flow, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for (Flow value : values){
sumUp += value.getUpFlow() + value.getDownFlow();
}
context.write(key, new Text(sum));
}
}
public class PartFlowPartitioner extends Partitioner<Text, Flow>{
@Override
public int getPartition(Text text,Flow flow, int numPartitions){
String city = flow.getCity();
if(city.equals("bj")) return 0;
else if (city.equals("sh")) return 1;
else return 2;
}
}
public class PartFlowDriver {
public static void mian(String[] args) throws IOException, ClassNotFoundException,InterruptedException
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(PartFlowDriver.class);
job.setMapperClass(PartFlowDriver.class);
job.setReducerClass(PartFlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置分区数
job.setPartitionerClass(PartFlowPartitioner.class);
//设置完分区数之后一定要设置ReduceTask的数量,不然还是一个分区
job.setNumReduceTasks(3);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/txt/flow.txt"));
FileOutputFormat.addOutputPath(job, new Path("hdfs://hadoop01:9000/result/part_flow.txt"));
job.waitForCompletion(true);
}
}
三.WritablsComparable – 排序
1.在MapReduce中,会自动的对放在键的位置上的元素进行排序,因此要求放在键的位置上的元素对应的类必须要实现Comparable。考虑到MapReduce要求被传输的数据能够被序列化,因此放在键的位置上的元素对应的类要考虑实现 – WritableComparable
2.案列:对文件中的数据按照下行流量排序(目录:serial_flow)
3.在MapReduce中,如果需要对多字段进行排序,那么称之为二次排序(见Flow中compareTo方法中注释部分)
/*
按地区分区
姓名 上行流量 下行流量
zs 4252 5236
ls 5264 2152
wl 5256 3256
zd 9252 9236
ll 5864 4152
ww 5256 6256
*/
public class Flow implements Writable{
private String name = "";
private int upFlow;
private int downFlow;
public String getName(){return name;}
public void setName(String name){this.name = name;}
public int getUpFlow(){return upFlow;}
public void setDownFlow(int upFlow){this.upFlow = upFlow;}
public int getDownFlow(){return downFlow;}
public void setDownFlow(int downFlow){this.downFlow = downFlow;}
//按照上行流量来进行升序排序
@Override
public int compareTo(Flow o){
return this.getDownFlow() - o.getDownFlow();
//int r = this.getDownFlow() - o.getDownFlow();
//if(r == 0)
//return this.getUpFlow() - o.getUpFlow();
//return r;
}
//需要将有必要的属性以此序列化写出即可
@Override
public void write(DataOutput out) throws IOException{
out.writeUTF(getCity());
out.writeInt(getUpFlow());
out.writeInt(getDownFlow());
}
@Override
public void readFields(DataInput in) throws IOException{
setCity(in.readUTF());
setUpFlow(in.readInt());
setDownFlow(in.readInt());
}
}
//因为按键排序所以第三个参数写Flow,按流量排序
public class SortFlowMapper extends Mapper<LongWritable, Text, Flow, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//zs 4252 5236
String[] arr = value.toString().split(" ");
//封装对象
Flow f = new Flow();
f.setName(arr[0]);
f.setUpFlow(Integer.parseInt(arr[1]));
f.setDownFlow(Integer.parseInt(arr[2]));
context.write(f, NullWritabls.get());
}
}
public class SortFlowReducer extends Reducer<Flow, NullWritable, Text, Text> {
@Override
protected void reduce(Flow key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException{
context.write(new Text(key.getName()), new Text(key.getUpFlow() + "\t" + key.getDownFlow()));
}
}
public class SortFlowDriver {
public static void mian(String[] args) throws IOException, ClassNotFoundException,InterruptedException
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SortFlowDriver.class);
job.setMapperClass(SortFlowDriver.class);
job.setReducerClass(SortFlowReducer.class);
job.setOutputKeyClass(Flow.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/txt/serial_flow.txt"));
FileOutputFormat.addOutputPath(job, new Path("hdfs://hadoop01:9000/result/sort_flow.txt"));
job.waitForCompletion(true);
}
}
四.Combiner – 合并
1.可以在Driver类中通过job.setCombinerClass(XXXReducer.class);来设置Combiner类
2.Combiner实际上是不在改变计算结果前提的下来减少Reducer的输入数据量

3.在实际开发中,如果添加Combiner,那么可以有效的提高MapReduce的执行效率,缩短MapReduce的执行时间。但是需要注意的是,并不是所有的场景都适合于使用Combiner。可以传递运算的场景,建议使用Combiner,例如求和、求积、最值、去重等;但是不能传递的运算,不能使用Combiner,例如求平均值
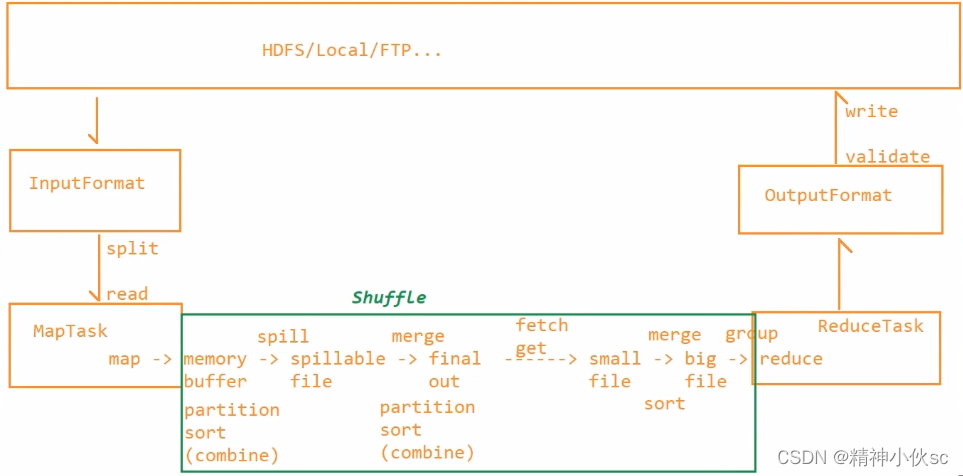
五.InputFormat – 输入格式
1.InputFormat 发生在MapTask之前。数据由InputFormat 来负责进行切分和读取,然后将读取的数据交给Maptask处理,所以InputFormat 读取来的数据是什么类型,MapTask接受的就是什么样类型
2.作用:
a.用于对文件进行切片处理
b.提供输入流用于读取数据
3.在MapReduce中,如果不指定,那么默认使用TextInputFormat ,而TextInputFormat继承了FileInputFormat 。默认情况下,FileInputFormat 负责对文件进行切分处理;TextInputFormat负责提供输入流来读取数据
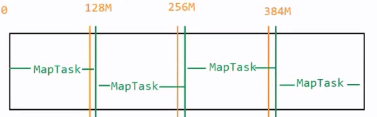
4.FileInputFormat在对文件进行切片过程中的注意问题
a.切片最小是1个字节大小,最大是Long.MAX_VALUE
b.如果是一个空文件,则整个文件作为一个切片来进行处理
c.在MapReduce中,文件存在可切与不可切的问题。大多数情况下,默认文件时可切的;但是如果是压缩文件,则不一定可切
d.如果文件不可切,无论文件多大,都作为一个切片来进行处理
e.在MapReduce中,如果不指定,Split和Block等大
f.如果需要调小Split,那么需要调小maxSize;如果需要调大Split,那么需要调大minSize

g.在切片过程中,需要注意阈值SPLIT_SLOP=1.1
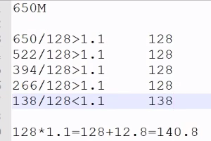
5.TextInputFormat在读取数据过程中需要注意的问题
a.TextInputFormat在对文件进行处理之前,会先判断文件是否可切:先获取文件的压缩编码,然后判断压缩编码是否为空。如果压缩编码不为空,则说明该文件不是压缩文件,那么默认可切;如果压缩编码不为空,则说明该文件是一个压缩文件,会判断这是否是一个可切的压缩文件
b.在MapReduce中,默认只有BZip2(.bz2)压缩文件可切
c.从第二个MapTask开始,会从当前切片的第二行开始处理,处理到下一个切片的第一行;第一个MapTask要多处理一行数据;最后一个MapTask要少处理一行数据。这样做的目的是为了保证数据的完整性
6.自定义输入格式:定义一个类继承InputFormat,但是考虑到切片过程相对复杂,所以可以考虑定义一个类继承FileInputFormat,而在FileInputFormat中已经覆盖了切片过程,只需要考虑如何实现读取过程即可
/*
tom
math 90 english 98
nacy
math 95 english 88
lucy
math 80 english 78
*/
class AuthReader extends RecordReader<Text, Text> {
private LineReader reader;
private Text key;
private Text value;
private long length;
private float pos = 0;
private static final byte[] blank = new Text(" ").getBytes();
//初始化方法,在初始化的时候会被调用一次
//一般会利用这个方法获取一个实际的流用于读取数据
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException {
//转化
FileSplit fileSplit = (FileSplit)split;
//获取切片所存储的位置
Path path = fileSplit.getPath();
//获取切片大小
length = fileSplit.getLength();
//链接HDFS
FileSystem fs =FileSystem.get(URI.create(path.toString()), context.getConfiguration());
//获取实际用于读数据的输入流
FSDataInputStream in = fs.open(path);
//获取到的输入流是一个字节流,要处理的文件是一个字符文件
//考虑将字节流包装成一个字符流,最好还能够按行读取
reader = new LineReader(in);
}
//判断是否有下一个键值对要交给map方法处理
//试着读取文件爱你。如果读取到了数据,那么说明有数据要交给map方法处理,此时返回true
//反之,如果没有读取到数据,那么说明所有的数据都处理完了,此时返回false
public boolean nextKeyValue() throws IOException{
//构建对象来存储数据
key = new Text();
value = new Text();
Text tmp = new Text();
//读取第一行数据
//将读取到的数据放到tmp中
//返回值表示读取到的字节个数
if(reader.readLine(tmp)<=0) return false;
key.set(tm.toString());
pos+=tmp.getLength();
//读取第二行数据
if(reader.readLine(tmp)<=0) return false;
value.set(tmp.toString());
pos+=tmp.getLength();
//读取第三行数据
if(reader.readLine(tmp) <= 0) return false;
value.append(blank, 0, blank.length);
value.append(tmp.getBytes(),0,tmp.getLength());
pos+=tmp.getLength();
//key = tom
//value = math 90 english 98
return true;
}
//获取键
@Override
public Text getCurrentKey(){
return key;
}
//获取值
@Override
public Text getCurrentValue(){
return value;
}
//获取执行进度
@Override
public float getProgress(){
return pos/length;
}
@Override
public void close() throws IOException{
if(reader != null)
reader.close();
}
}
public class AuthMapper extends Mapper<Text, Text, Text, IntWritable>{
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException{
//key = tom
//value = math 90 english 98
//拆分数据
String[] arr = value.toString().split(" ");
context.write(key,new IntWritable(Integer.parseInt(arr[1])));
context.write(key,new IntWritable(Integer.parseInt(arr[3])));
}
}
public class AuthReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable value : values){
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
public class AuthDriver {
public static void mian(String[] args) throws IOException, ClassNotFoundException,InterruptedException
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(AuthDriver.class);
job.setMapperClass(AuthDriver.class);
job.setReducerClass(AuthReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定输入格式类
job.setIntputFormatClass(AuthInputFormat.class);
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/txt/score.txt"));
FileOutputFormat.addOutputPath(job, new Path("hdfs://hadoop01:9000/result/auth_input.txt"));
job.waitForCompletion(true);
}
}
7.多源输入:在MapReduce中,允许同时指定多个文件作为输入源,而且这多个文件可以放在不同的路径下。这多个文件的数据格式可以不同,可以为每一个文件单独指定输入格式
//在driver端加入输入多路径
MutipleInputs.addInputPath(job, new Path("hdfs://hadoop01:9000/txt/words.txt"),TextInputFormat.class);
MultipleInputs.addInputPath(job, new Path("D:/characters.txt"), TextInputFormat.class);
六.OutputFormat – 输出格式
1.OutputFormat发生在ReduceTask之后,接受ReduceTask产生的数据,然后将结果按照指定格式写出
2.作用:
a.校验输出路径,例如检查输出路径不存在
b.提供输出流用于将数据写出
3.在MapReduce中,如果不指定,默认使用的是TextOutputFormat。
TextOutputFormat继承了FileOutputFormat。其中,FileOutputFormat负责对输出路径进行校验,TextOutputFormat则是对数据进行写出
4.在MapReduce中,也支持自定义输出格式以及多源数据,但是注意,实际开发中自定义输出格式以及多源输出用的非常少
Shuffle
一.Map端的Shuffle
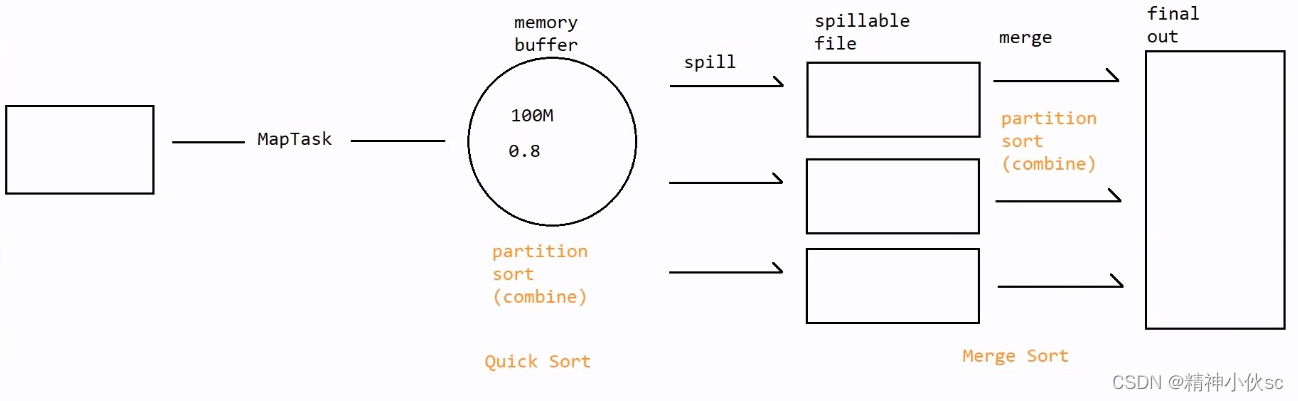
1.当MapTask调用map方法处理数据之后,会将处理结果进行写出,写出到MapTask自带的缓冲区中。每一个MapTask都会自带一个缓冲区,本质上是一个环形的字节数组,维系在内存中,默认大小是100M。
2.数据在缓冲区中会进行分区、排序,如果指定了combiner,那么还进行合并。这次排序是将完全杂乱没有规律的数据整理成有序的数据,所以使用的是快速排序
3.当缓冲区使用达到指定阈值(默认是0.8,即缓冲区使用达到80%)的时候,会进行spill(溢写),产生一个溢写文件文件。因为数据在缓冲区已经分区且排序,所以产生的单个溢写文件中的数据时分好区且排好序的
4.溢写之后,MapTask产生的数据会继续写出到缓冲区中,如果再次达到条件,会再次进行溢写。每一个溢写都会产生一个新的溢写文件。多个溢写文件之间的数据是局部有序但整体无序的
5.当所有数据都处理完成之后,那么MapTask会将所有的溢写文件进行合并(merge),合并成一个大的结果文件final out。在merge的时候,如果有数据依然在缓冲区中,那么会将缓冲区中的数据直接merge到final out中。
6.在merge过程中,数据会再次进行分区且排序,因此final out中的数据时分好区且排好序的。如果溢写文件个数达到3个及以上,并且指定了Combiner,那么在merge过程中还会进行combine。这次排序是将局部有序的数据整理成整体有序的状态,所以采用的是归并排序
7.注意问题
a.缓冲区设置为环形的目的减少了重复寻址的次数
b.设置阈值的目的是为了降低阻塞的几率
c.溢写过程不一定产生
d.原始数据的大小并不能决定溢写次数
e.溢写文件的大小受序列化因素的影响
二.Reduce端的Shuffle
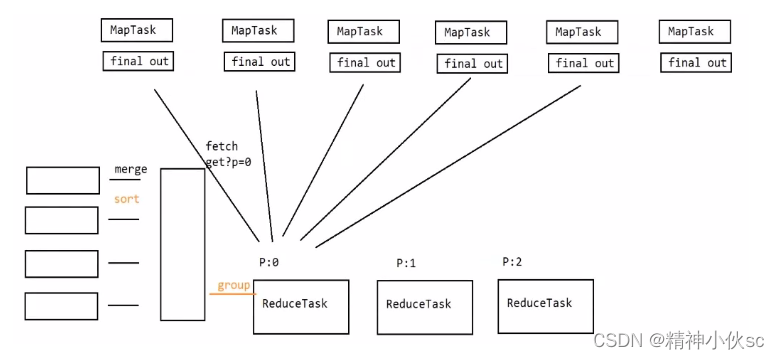
1.当ReduceTask达到启动阈值(0.05,即当有5%的MapTask结束)的时候,就会启动来抓取数据
2.ReduceTask启动之后,会在当前服务器上来启动多个(默认是5个)fetch线程来抓取数据
3.fetch线程启动之后,会通过HTTP请求中的get请求来获取数据,在发送请求的时候会携带分区号作为参数
4.fetch线程会将抓取来的数据临时存储到本地磁盘上,形成一个个的小文件
5.当所有的fetch抓取完数据之后,ReduceTask会将这些小文件进行merge,合并成一个大文件。在merge过程中,会对数据再次进行排序。这次排序是将局部有序的数据整理成整体有序的状态,所以采用的是归并排序
6.merge完成之后,ReduceTask会将相同的键对应的值分到一组区,形成一个(伪)迭代器(本质上是一个基于迭代模式实现的流),这个过程称之为分区(group)
7.分组时候,每一个键调用一次reduce方法
三.MapReduce执行流程
四.Shuffle优化
1.适当的增大缓冲区。实际过程中,可以缓冲区设置为250M~400M
2.增加Combiner,但是不是所有场景都适用于使用Combiner
3.可以考虑对结果进行压缩传输。如果网络条件比较差,那么可以考虑将final out文件压缩之后再传递给ReduceTask,但是ReduceTask收到数据之后需要进行解压,所以这种方案是在网络传输和压缩解压之间的一种取舍
4.适当的考虑fetch线程的数量。
扩展:
一.小文件问题
1.在大数据环境下,希望所处理的文件都是大文件,但是在生产环境中,依然不可避免的会产生很多小文件
2.小文件的危害
a.存储:每一个小文件在HDFS上都会对应一条元数据。如果有大量的小文件,那么在HDFS中就会产生大量的元数据。元数据过多,就会占用大量的内存,还会导致查询效率变低。
b.计算:每一个小文件都会对应一个切片,就会导致产生大量的MapTask。如果MapTask过多,那么就会导致使服务器的线程的承载压力变大,致使服务器产生卡顿甚至崩溃
3.到目前为止,市面上针对小文件的处理手段无非两种:合并和打包
4.Hadoop针对小文件提供了原生的打包手段:Hadoop Archive,将指定小文件打成一个har包
二.压缩机制
1.MapReduce支持对数据进行压缩:可以对MapTask产生中间结果(final out)进行压缩,也支持对ReduceTask的输出结果进行压缩
2.在MapReduce中,默认支持的压缩格式有:Default,BZip2,GZip,Lz4,Spappy,Zstandard,其中比较常用的是BZip2
//在Driver类中加入两行代码
//开启Mapper结果的压缩机制
conf.set("mapreduce.map.output.compress","true");
//设置压缩编码类
conf.setClass("mapreduce.map.output.compress.codec",BZip2Codec.class,CompressionCodec.class);
//对Reduce结果进行压缩
FileOutputFormat.setCompressOutput(job,true);
FileOutputFormat.setOutputCompressorClass(job,BZip2codec.class);
三.推测执行机制
1.推测执行机制本质上是MapReduce针对慢任务的一种优化。慢任务指的是其他任务都正常执行完,但是其中几个任务依然没有结束,那么这几个任务就称之为慢任务
2.一旦出现了慢任务,那么MapReduce会将这个任务拷贝一份放到其他节点上,两个节点同时执行相同的任务,谁先执行完,那么它的结果就作为最终结果;另外一个没有执行完的任务就会被kill掉
3.慢任务出现的场景
a.任务分配不均匀
b.节点性能不一致
c.数据倾斜
4.在实际生产过程中,因为数据倾斜导致慢任务出现的机率更高,此时推测执行机制并没有效果反会占用更多的集群资源,所以此时一般会考虑关闭推测执行机制
5.推测执行机制配置(放在mared-site.xml文件中)

四.数据倾斜
1.数据倾斜指的是任务之间的数据量不均等。例如统计视频网站上各个视频的播放量,那么此时处理热门视频的任务所要处理的数据量就会比其他的任务要多,此时就产生了数据倾斜
2.Map端的数据倾斜的产生条件:多源输入、文件不可切、文件大小不均等。一般认为Map端的倾斜无法解决
3.实际开发中,有90%的数据倾斜发生在了Reduce端,直接原因就是因为是对数据进行分类,本质原因是因为数据本身就有倾斜的特性,可以考虑使用二阶段聚合的方式来处理Reduce端的数据倾斜
五.join
1.如果在处理数据的时候,需要同时处理多个文件,且文件相互关联,此时可以考虑将主要处理的文件放在输入路径中,将其他文件关联缓存中,需要的时候再从缓存中将文件取出来处理
2.案例:统计每一天卖了多少钱
/*
按地区分区
订单id 日期 商品编号 商品数量
1001 20220322 2 24
1002 20220322 1 28
1003 20220322 3 21
1004 20220323 4 22
1005 20220323 1 25
1006 20220323 3 20
1007 20220324 4 20
1008 20220324 2 26
商品编号 商品名称 商品价格
1 huawei 5999
2 xiaomi 3999
3 oppo 3599
4 apple 8999
*/
public class Order implements Writable{
private String productId = "";
private int num;
private double price;
public String getProductId(){return productId;}
public void setProductId(String productId){this.productId = productId;}
public int getNum(){return num;}
public void setNum(int num){this.num= num;}
public double getPrice(){return price;}
public void setPrice(double price){this.price= price;}
//需要将有必要的属性以此序列化写出即可
@Override
public void write(DataOutput out) throws IOException{
out.writeUTF(getProductId());
out.writeInt(getNum());
out.writeInt(getPrice());
}
@Override
public void readFields(DataInput in) throws IOException{
setProductId(in.readUTF());
setNum(in.readInt());
setPrice(in.readInt());
}
}
public class JoinMapper extends Mapper<LongWritable, Text, Flow, Order>{
//其他文件关联缓存map中
private final Map<String, Order> map = new ConcurrentHashMap<>();
@Override
protected void setup(Context context) throws IOException{
//获取文件路径
URI file =context.getCacheFiles()[0];
//连续HDFS
FileSystem fs = FileSystem.get(file,context.getConfiguration());
//获取到的输入流是一个字节流,要处理的文件时一个字符文件,考虑将字节流转化为字符流
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line;
while ((line = reader.readLine()) != null){
//拆分字段
//1 huawei 5999
String[] arr = line.split(" ");
Order o = new Order();
o.setProductId(arr[0]);
o.setPrice(Double.parseDouble(arr[2]));
map.(o.getProductId(),o);
}
reader.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//1001 20220322 2 24
String[] arr = value.toString().split(" ");
//封装对象
Order 0 = new Order();
o.setProductId(arr[2]);
o.setUpNum(Integer.parseInt(arr[3]));
o.setPrice(map.get(o.getProduceId()).getPrice());
context.write(new Text(arr[1]), o);
}
}
public class JoinReducer extends Reducer<Text, Order, Text, DoubleWritable> {
@Override
protected void reduce(Text key, Iterable<Order> values, Context context) throws IOException, InterruptedException{
double sum = 0;
for(Order value : values){
sum += value.getNum() * value.getPrice();
}
context.write(key, new DoubleWritable(sum))
}
}
public class JoinDriver {
public static void mian(String[] args) throws IOException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(JoinDriver.class);
job.setMapperClass(JoinMapper.class);
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Order.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//确定主要处理文件 - 统计每一天卖了多少钱 ->键是日期,值是钱
//主要处理文件 ->order.txt
FileInputFormat.addInputPath(job, new Path("hdfs://hadoop01:9000/txt/order.txt"));
//将关联文件的路径放到缓存中,需要使用的时候再从缓存中取出来处理即可
URI[] files = {URI.create("hdfs://hadoop01:9000/txt/product.txt")};
job.setCacheFiles(files);
FileOutputFormat.addOutputPath(job, new Path("hdfs://hadoop01:9000/result/join.txt"));
job.waitForCompletion(true);
}
}