前文回顾
:
机器学习概述
?线性回归概念
我们要使用一个数据集,数据集包含俄勒冈州波特兰市的住房价格。在这里,我要根据不同房屋尺寸所售出的价格,画出我的数据集。比方说,如果你朋友的房子是 1250 平方尺大小,你要告诉他们这房子能卖多少钱。那么,你可以做的一件事就是构建一个模型,也许是条直线,从这个数据模型上来看,也许你可以告诉你的朋友,他能以大约 220000(美元)左右的价格卖掉这个房子。这就是监督学习算法的一个例子。
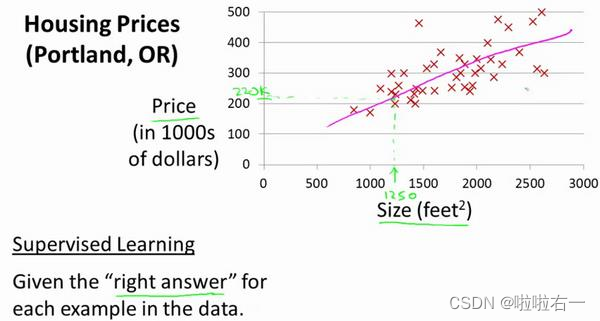
它被称作监督学习是因为对于每个数据来说,我们给出了“正确的答案”,即告诉我们:根据我们的数据来说,房子实际的价格是多少,而且,更具体来说,这是一个回归问题。
线性回归
:
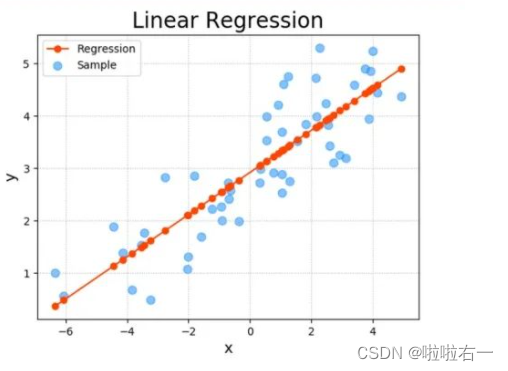
一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,
使得预测值与真实值之间的误差最小化
。
?
符号约定

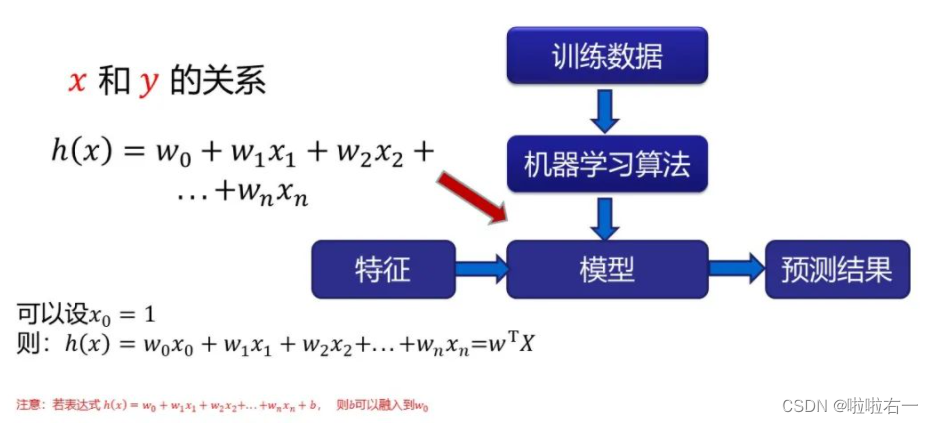
这里x/y的上标指的是索引,表示第几行/第几列
?
算法流程
损失函数:
度量单样本预测的错误程度,损失函数值越小,模型就越好。
代价函数:
度量全部样本集的平均误差。
目标函数:
代价函数和正则化函数,最终要优化的函数。
?单变量回归
下式为一种可能的表达式,因为只有一个输入变量,因此这样的问题叫做
单变量线性回归问题
。
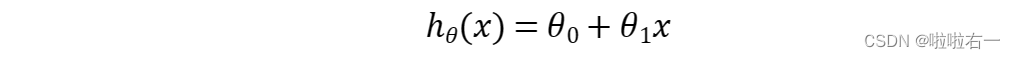
?
代价函数

-
通过训练集我们可以得到假设函数
h即我们建立的模型
,
y是测试集
。
-
通过输入测试集的自变量向函数h和y,
得出预测出来的结果与实际的结果
,
让两者相减得到误差。
-
通过误差可以看出我们预测的结果好还是不好
,如果误差小于某一个极小数时,我们可以认为我们建立的模型非常成功,反之则是失败。
-
求和的目的是把所有预测值的误差加起来,平方的目的是保证求和的时候误差是正数,除以m是求平均误差,
除以2是为了计算方便,有没有这个2最后所求出的最小代价对应的假设函数都是一样的
。
?
假设函数与代价函数的关系
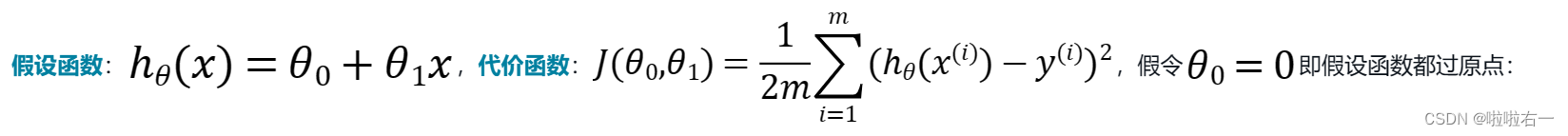
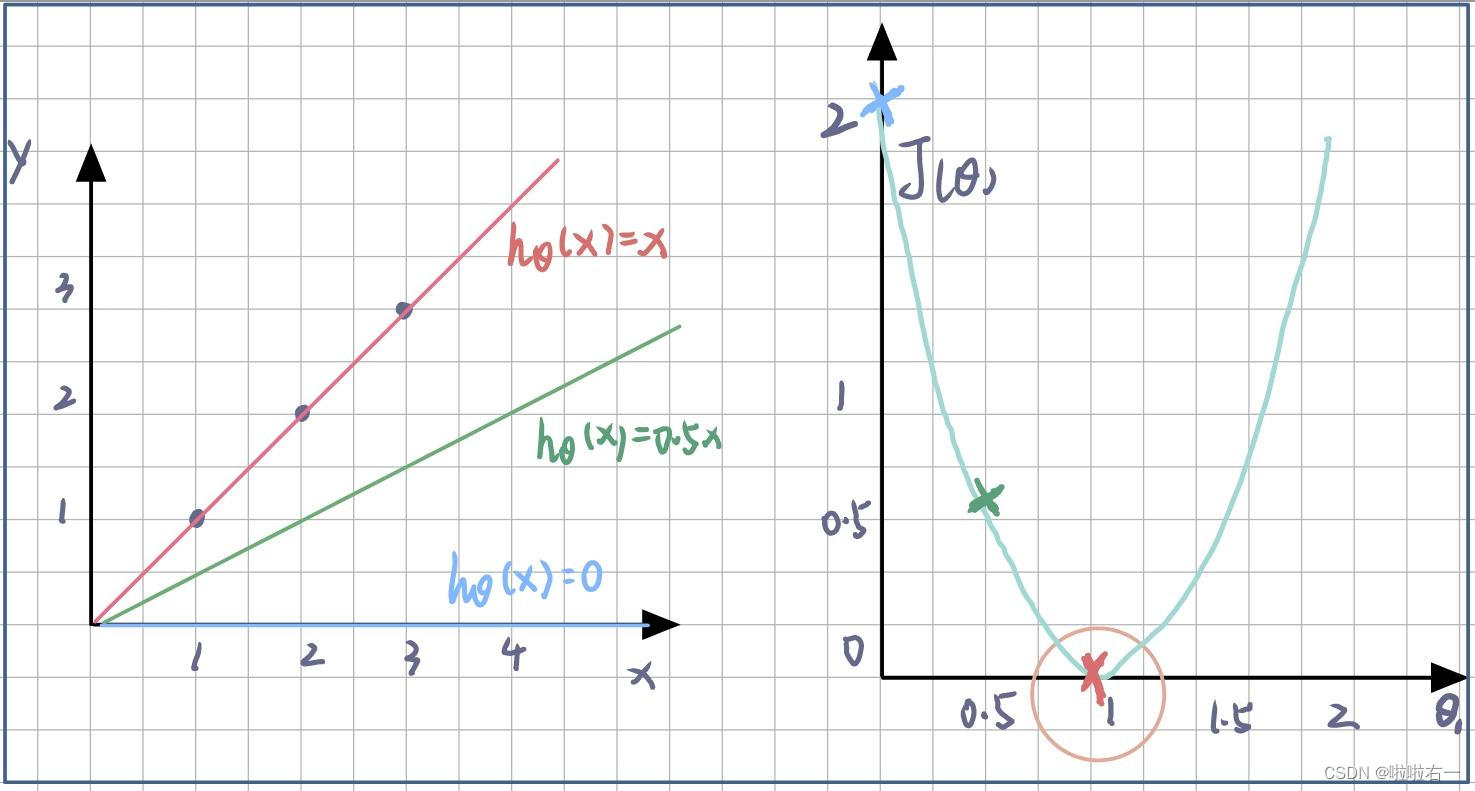

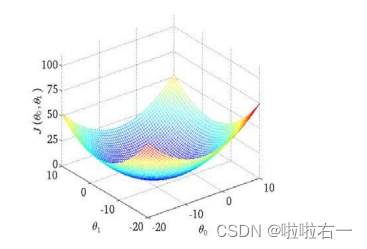
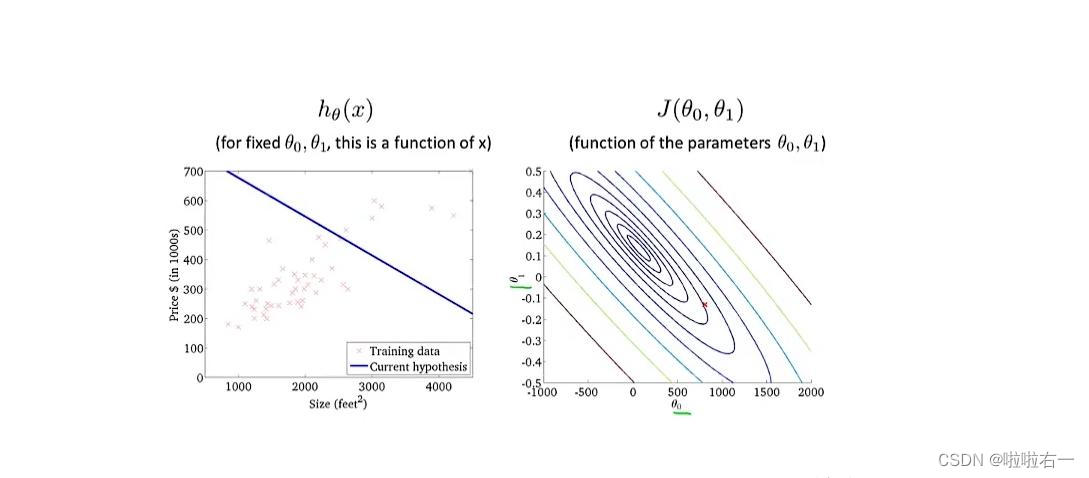
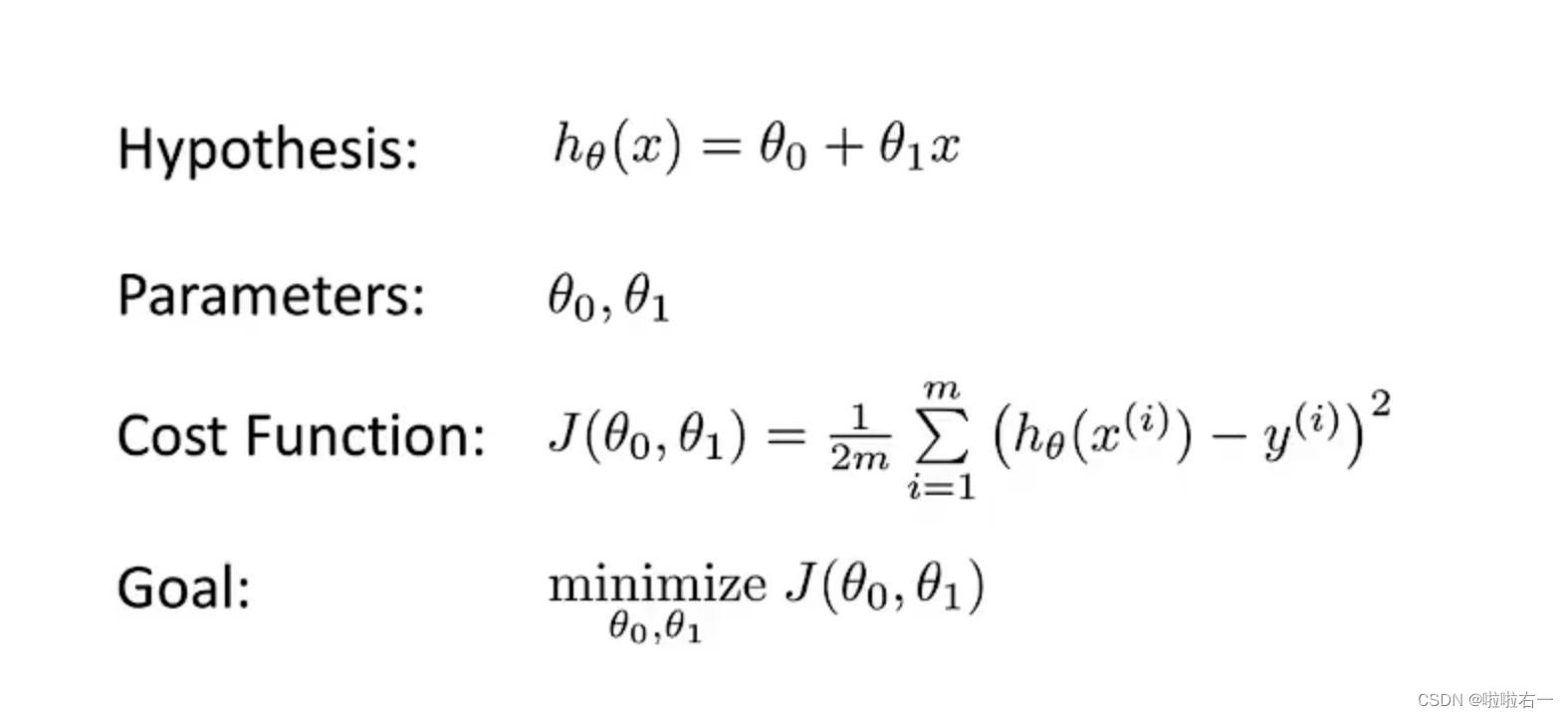
?
梯度下降
梯度下降的目的
即求代价函数的最小值
。且梯度下降有种“动态规划”的意思。

理解“梯度下降”
:我们把它想象成“下山”的场景。
如何从山上尽快下山
❓
以我们所在的位置为基准,寻找该位置
最陡峭(即变化最快)
的方向,然后沿该方向走一段路程,并且每走一段路程,都要
重新
寻找
当前位置最陡峭(即变化最快)
的方向,然后沿新的方向再走一段路程,
反复采用以上的方法,就能以最快的速度走到山脚下
。
?
背后的数学原理

?
梯度下降的直观感受
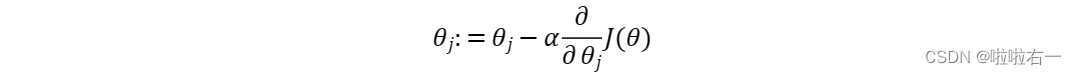
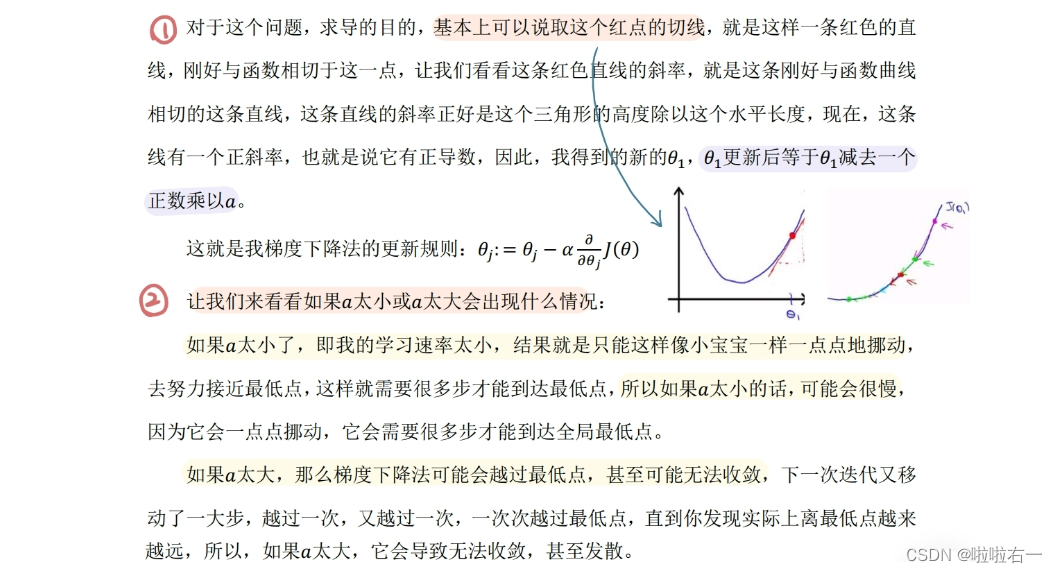
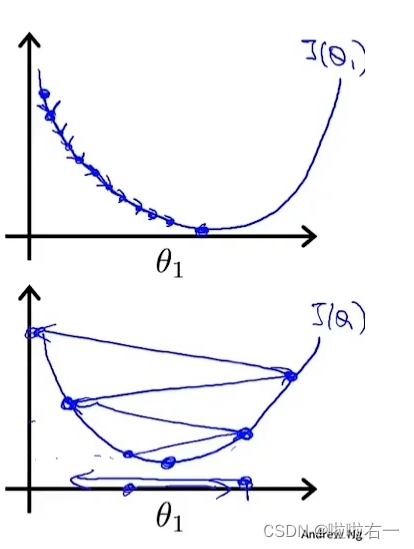
在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低点时导数等于0,所以当我们接近局部最低时,
导数值会自动变得越来越小,所以梯度下降将采取较小的幅度
,这就是梯度下降的做法,所以实际上没有必要再另外减小α。
?
线性回归的梯度下降
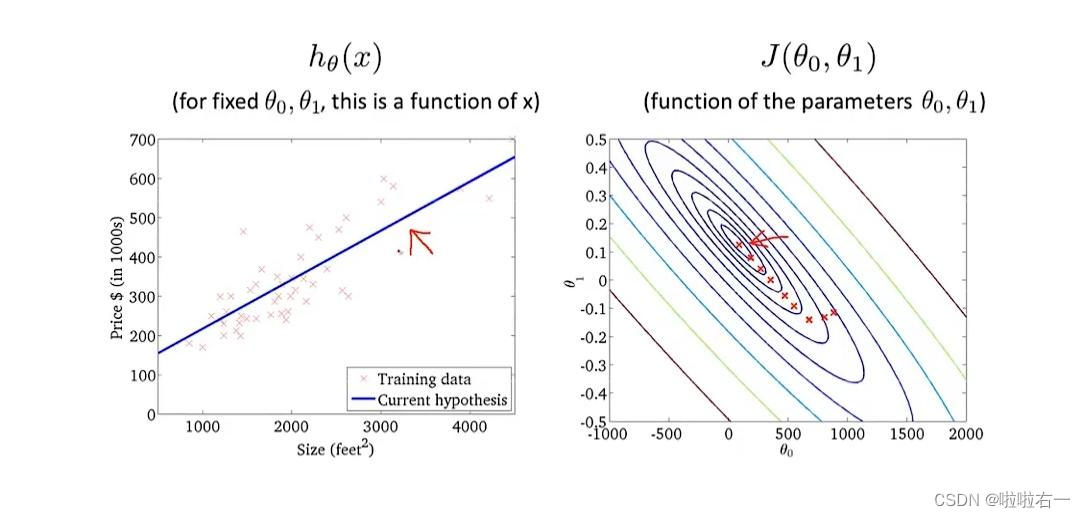
我们将梯度下降和代价函数结合,将其应用于具体的拟合直线的线性回归算法里。

梯度下降算法和线性回归算法
对我们之前的线性回归问题运用梯度下降法,关键在于求出代价函数的导数,即:

在下山的过程中,我们每走一段路,就要确定新的方向,不断确定新的方向意味着代价函数的参数不断在变化,而
新的参数又在已知旧的参数的基础上获得
。在梯度下降的每一步中,我们都用到了
所有的训练样本
,我们需要不断重复更新参数的过程是
批量梯度下降
。

参考学习链接:
【中英字幕】吴恩达机器学习系列课程
,本篇对应
2.1-2.7
?富文本编辑器电脑里头的LaTeX公式在手机平板看就错行,只能额外加一步截图——不乐。
?电脑富文本编辑器里头,引用里边不能插图片——不乐。
?电脑富文本编辑器里开的草稿在手机平板内容编辑里都会出现混乱,打开的总是别的文章——不乐。
