计算机体系结构
第一章.量化设计与分析基础
计算机体系结构:指令集体系结构 + 计算机的实现
计算机的实现: 组成或微体系结构 + 硬件
1.局域性原理:一段程序90%的执行时间花费在10%的代码中
时间局部性:
最近被访问过的内容很可能短期内再次被访问
空间局部性:
最近被访问过的地址的相邻地址很可能短期内被访问
for (int i=0; i<10; i++)
for (int j=0; j<10; j++)
a[i] += j;
//外层循环i展示了空间局部性,a[0],a[1].....a[9]等相邻地址被访问
//内层循环j展示了时间局部性,a[i]在循环内被不停访问
2. Amdahl定理(阿姆达尔定理)
加
速
比
=
升
级
后
的
性
能
升
级
前
的
性
能
=
升
级
前
的
执
行
时
间
升
级
后
的
执
行
时
间
加速比=\tfrac{升级后的性能}{升级前的性能}=\tfrac{升级前的执行时间}{升级后的执行时间}
加
速
比
=
升
级
前
的
性
能
升
级
后
的
性
能
=
升
级
后
的
执
行
时
间
升
级
前
的
执
行
时
间
新
执
行
时
间
=
原
执
行
时
间
∗
(
(
1
−
升
级
比
例
)
+
升
级
比
例
升
级
时
间
)
新执行时间=原执行时间 *( (1-升级比例)+\tfrac{升级比例}{升级时间})
新
执
行
时
间
=
原
执
行
时
间
∗
(
(
1
−
升
级
比
例
)
+
升
级
时
间
升
级
比
例
)
总
加
速
比
=
原
执
行
时
间
新
执
行
时
间
=
1
(
1
−
升
级
比
例
)
+
升
级
比
例
升
级
时
间
总加速比=\tfrac{原执行时间}{新执行时间}=\frac{1}{(1-升级比例)+\tfrac{升级比例}{升级时间}}
总
加
速
比
=
新
执
行
时
间
原
执
行
时
间
=
(
1
−
升
级
比
例
)
+
升
级
时
间
升
级
比
例
1
3.处理器性能公式
CPI:每条指令的时钟周期数(组成 与 指令集体系结构 可以改变)
IC:每条指令的执行次数 ——指令数(组成 与 指令集体系结构 可以改变)
CCT:时钟周期时间 (硬件技术 与 组成 可以改变)
CPI=CPU时钟周期数 / IC
CPU时间 = CPI * IC * CCT
C
P
U
时
间
=
(
∑
i
=
1
n
I
C
i
∗
C
P
I
i
)
∗
时
钟
周
期
时
间
(
C
C
T
)
CPU时间 = (\sum_{i=1}^n {IC}_{i} * {CPI}_{i}) * 时钟周期时间(CCT)
C
P
U
时
间
=
(
i
=
1
∑
n
I
C
i
∗
C
P
I
i
)
∗
时
钟
周
期
时
间
(
C
C
T
)
附录A.指令集
指令集体系结构分类
- 栈结构
- 累加器结构(每一步的操作数即是结果,也是是隐式输入操作数)
- 寄存器-存储器结构
- 寄存器-寄存器结构(只能做load,store)
寻址方式
- Register(寄存器寻址) DADD R1 , R1 , R2
- Immediate(立即数寻址) DADDI R1 ,R1 , #100
- Displacement(位移量寻址) LD R1 , 100(R2)
- Register indirect(寄存器间接寻址) LD R1 , 0(R2)
- Direct(直接寻址) LD R1 , #100(R0) ——————R0 == 0
第二章.存储器层次结构设计(+附录B)
处理器——存储器结构
1.Cache(缓存)
离开处理器后遇到的最高级或者第一级存储器层次结构
cache命中:cache找到需要的数据返回
cache缺失:cache找不到数据,需要从主存储器中提取
存放方式(映射方式)
直接映射
:每一个地址只能映射到一个特定的cache line(也叫block)
全相联映射
:可以映射到cache的任何一个位置(有n个cache line,则是否命中判断时间为O(n))
组相联
: 一个或多个组
一路组相联采用
直接映射
:按照结构规则映射到具体的cache line(是否命中判断时间为O(1))
多路组相联采用
组相联映射
:映射到每个组的相同的cache line(n路组相联,是否命中判断时间为O(n))
组相联cache块结构
:

组相联映射规则
:
1.index索引找到是哪一个组
2.再用tag判断是否组内地址命中(是否相等)
3.最后offset偏移量表示取哪些位置(全字,半字,一字节)
替换策略
1.随机 2.FIFO 3.LRU 4.DRU
写入策略
1.写直达
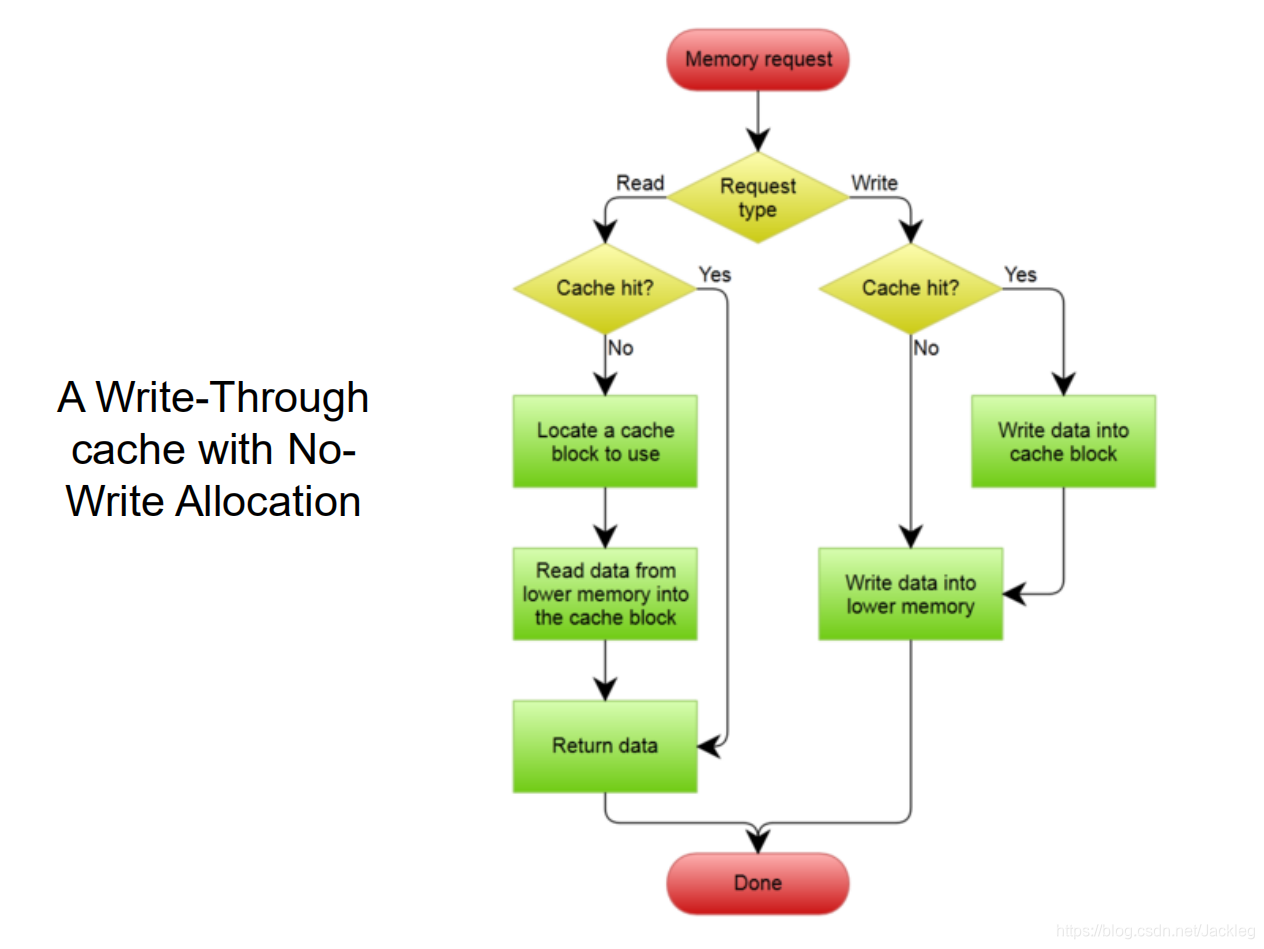
2.写回
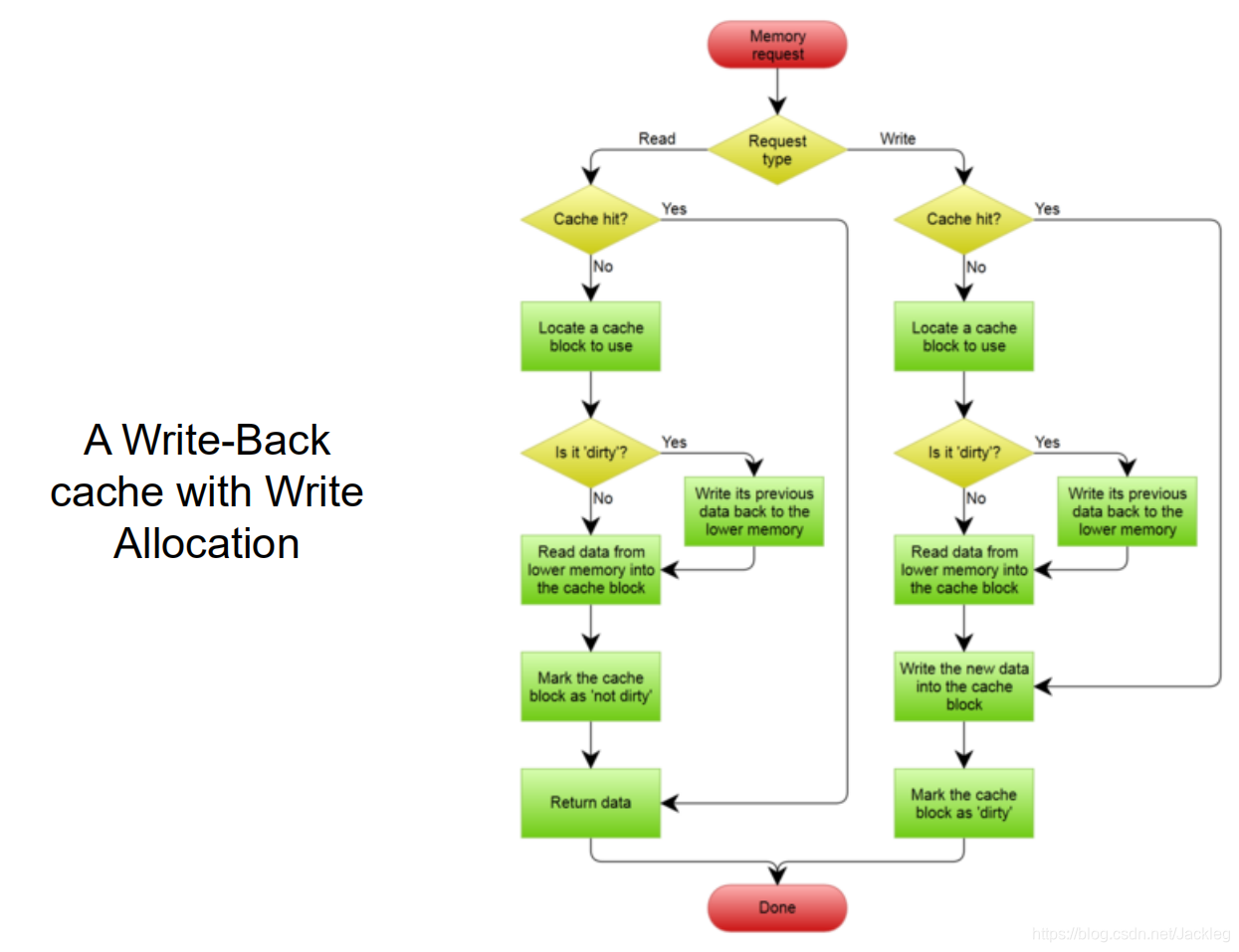
优化方法
存储器平均访问时间 = 命中时间 + 缺失率*缺失代价
命中时间:命中目标花费的时间
缺失代价:才内存中替换块的时间
强制缺失
:第一次访问该块时必然不存在,需要从内存中读入
容量缺失
:块的大小不够容纳,需要另行提取(偏移量不够)
冲突缺失
:不同地址映射到同一个cache line,超过组的数量(即同一个组内),交替访问时会被替换
(1)增大块(cache line)来降低缺失率:导致cache块数量降低,更容易造成容量缺失与冲突缺失
(2)增大缓存(cache) 来降低缺失率:增加成本和功耗,也可能延长命中时间
(3)提高组相联程度来降低缺失率:较大的相联程度是以延长命中时间为代价的
(4)采用多级cache来降低缺失代价
(5)读取缺失指定高于写入操作的优先级来降低缺失率:发生读取缺失时替换cache块,写入缺失时则不替换
2.存储器性能
存储器停顿时间 = 缺失数*缺失代价
存储器平均访问时间 = 命中时间 + 缺失率*缺失代价
二级存储器平均访问时间 = 命中时间(L1) + 缺失率(L1) * ( 命中时间(L2) + 缺失率(L2) * 缺失代价(L2))
CPU时间 = (IC * CPI + 存储器停顿周期数)* CCT
= IC * ( CPI + (缺失数 / 指令数 ) * 缺失代价 ) * CCT
= IC * (CPI + 缺失率 * (存储器访问数 / 指令数) * 缺失代价 ) * CCT
附录C:流水线(RISC)
MIPS指令类型
:ALU指令 , 载入和存储指令 ,分支与跳转指令
每条指令最多五个时钟周期:
五个阶段
:F(取指),D(译码),EX(执行),M(访存),W(写回)
流水线冒险
类型:
-
结构冒险
:硬件无法支持当前指令所有的组和可能,即资源冲突(该指令在某一个时钟周期超出最大的资源使用量) -
数据冒险
:指令之间存在先后顺序,一条指令需要某数据而该数据正在被之前的指令操作(数据依赖) -
控制冒险
:分支或跳转指令需要的判断结果还没有运算出来,造成了冒险(要执行哪条指令,是由之前指令的运行结果决定,而现在那条之前指令的结果还没产生)
冒险及其解决方法
一.数据冒险
1.数据依赖类型
-
RAW(写后读)
:
ADD R3 R1 R2
ADD R5 R4 R3
R3存在先写后读的依赖 -
WAR(读后写)
:
ADD R3 R1 R2
ADD R1 R4 R5
R1存在先读后写的依赖 -
WAW(写后写)
:
ADD R3 R2 R1
ADD R3 R4 R5
R3存在先写再写的依赖
2.数据冒险解决方法
-
转发
(forwarding,也叫旁路):将执行阶段运算出的ALU结果转发给后面的指令,而不选择等待写回后从寄存器读值 -
停顿
(旁路不能解决的其他数据冒险情况):等到前一条指令执行完成再继续这一条指令,中间过程流水线暂停
二.控制冒险(分支冒险)
对于
无条件分支
,在D阶段前不知道是否为分支跳转指令(固定浪费一个时钟周期)
对于
有条件分支
,在EX阶段前不知道是否满足跳转的条件,但可以采取一定的
预测机制
(一但条件满足,发生跳转,也必然损失一个时钟周期)
解决方法
1.流水线暂停
2. 分支预测
1.静态分支预测:
- 预测未选中机制:无法判断是否需要跳转之前继续按照顺序取下一条指令
- 预测选中机制:只要明确当前是分支跳转指令,则取跳转后位置指令的地址
- 延迟转发:一定执行完下一条指令才会执行分支跳转指令
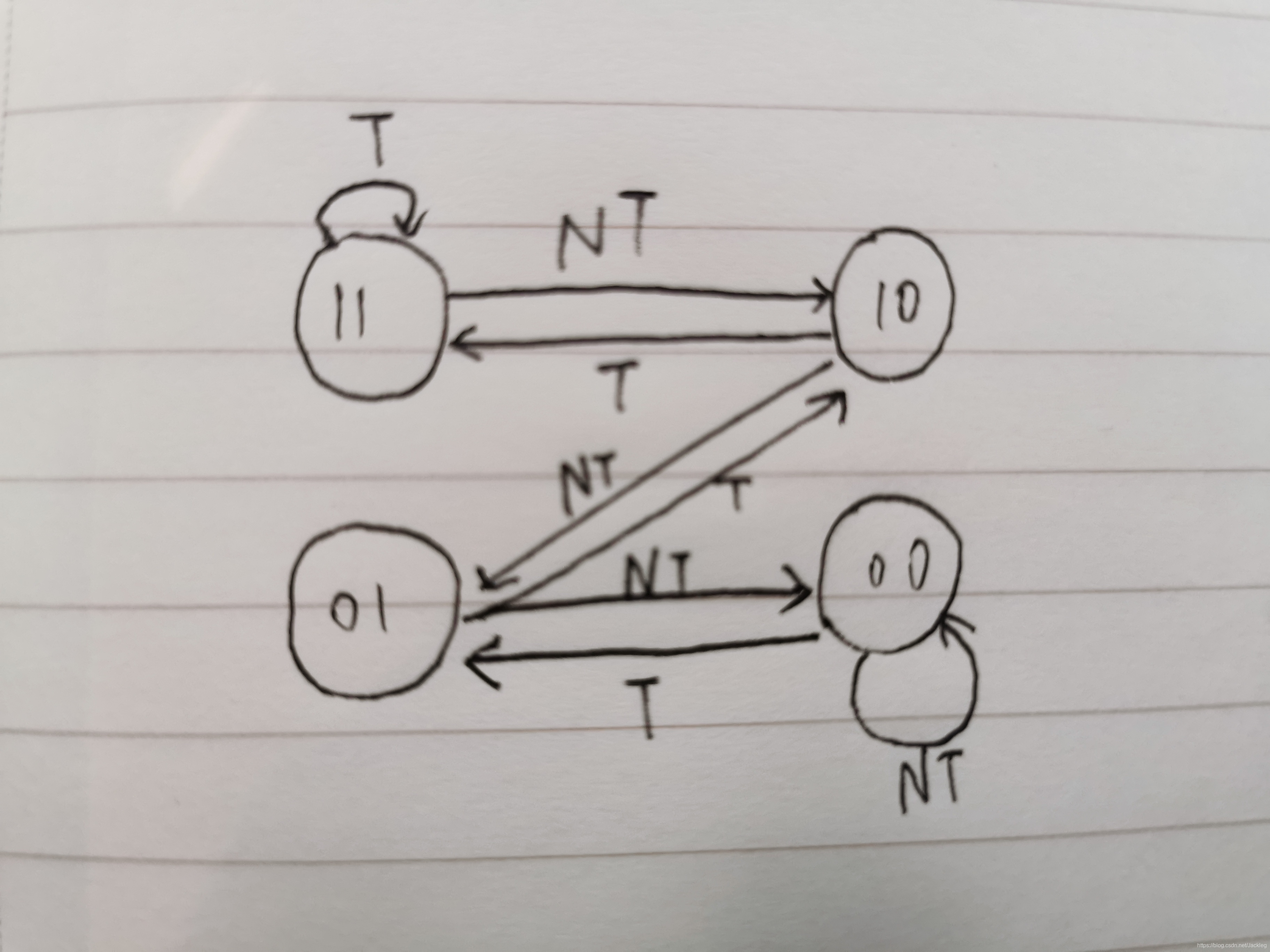
2.动态分支预测:
1位预测机制:
2位预测机制:
正方形
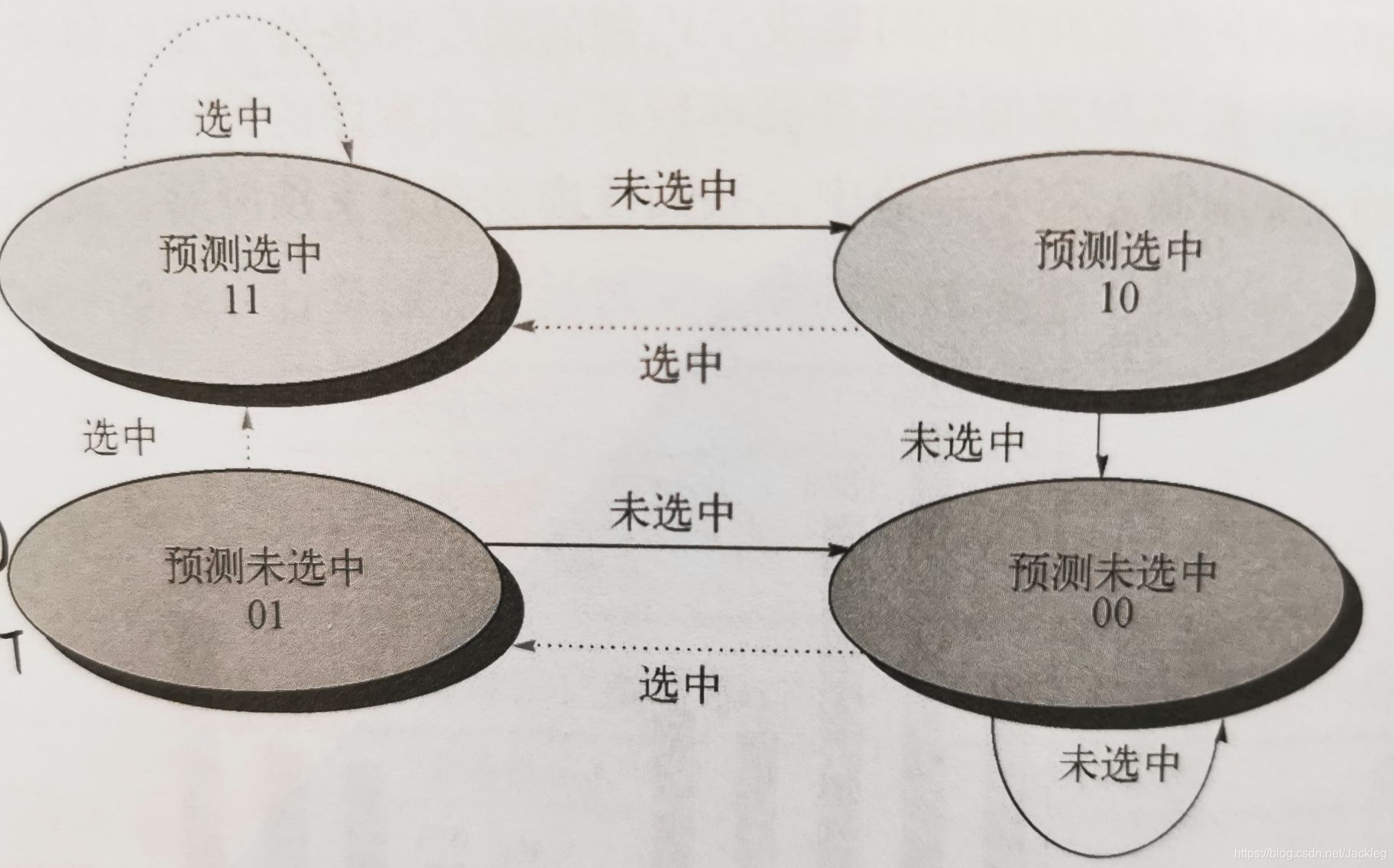
Z字形
流水线CPI和加速比计算
流
水
化
加
速
比
=
非
流
水
化
指
令
平
均
执
行
时
间
流
水
化
指
令
平
均
执
行
时
间
流水化加速比= \tfrac{非流水化指令平均执行时间 }{流水化指令平均执行时间}
流
水
化
加
速
比
=
流
水
化
指
令
平
均
执
行
时
间
非
流
水
化
指
令
平
均
执
行
时
间
流
水
化
加
速
比
=
非
流
水
化
C
P
I
流
水
化
C
P
I
∗
非
流
水
化
时
钟
周
期
流
水
化
时
钟
周
期
流水化加速比= \tfrac{非流水化CPI }{流水化CPI}* \tfrac{非流水化时钟周期}{流水化时钟周期}
流
水
化
加
速
比
=
流
水
化
C
P
I
非
流
水
化
C
P
I
∗
流
水
化
时
钟
周
期
非
流
水
化
时
钟
周
期
假定时钟周期相等
如果所有指令的周期数都相同,周期数必然等于那么流水线深度(流水线级数)
则非流水化CPI等于流水线深度
流
水
化
加
速
比
=
非
流
水
化
C
P
I
1
+
每
条
指
令
的
流
水
线
停
顿
周
期
流水化加速比 = \tfrac{非流水化CPI}{1+每条指令的流水线停顿周期}
流
水
化
加
速
比
=
1
+
每
条
指
令
的
流
水
线
停
顿
周
期
非
流
水
化
C
P
I
假定非流水化CPI和流水线理想CPI为1
流
水
线
深
度
=
非
流
水
化
时
钟
周
期
流
水
化
时
钟
周
期
流水线深度 = \tfrac{非流水化时钟周期}{流水化时钟周期}
流
水
线
深
度
=
流
水
化
时
钟
周
期
非
流
水
化
时
钟
周
期
流
水
化
加
速
比
=
非
流
水
化
C
P
I
流
水
化
C
P
I
∗
非
流
水
化
时
钟
周
期
流
水
化
时
钟
周
期
流水化加速比= \tfrac{非流水化CPI }{流水化CPI}* \tfrac{非流水化时钟周期}{流水化时钟周期}
流
水
化
加
速
比
=
流
水
化
C
P
I
非
流
水
化
C
P
I
∗
流
水
化
时
钟
周
期
非
流
水
化
时
钟
周
期
流
水
化
加
速
比
=
非
流
水
化
C
P
I
∗
流
水
线
深
度
流
水
化
C
P
I
流水化加速比 = \tfrac{非流水化CPI * 流水线深度 }{流水化CPI}
流
水
化
加
速
比
=
流
水
化
C
P
I
非
流
水
化
C
P
I
∗
流
水
线
深
度
考虑分支代价的流水线
流水线理想CPI:1
分支导致的流水线停顿周期 = 分支频率 * 分支代价
流水化CPI = 1 +每条指令平均停顿时钟周期
流
水
线
加
速
比
=
流
水
线
深
度
1
+
每
条
指
令
平
均
停
顿
周
期
=
流
水
线
深
度
1
+
分
支
频
率
∗
分
支
代
价
流水线加速比 = \tfrac{流水线深度 }{1 + 每条指令平均停顿周期} = \tfrac{流水线深度 }{1 + 分支频率 * 分支代价}
流
水
线
加
速
比
=
1
+
每
条
指
令
平
均
停
顿
周
期
流
水
线
深
度
=
1
+
分
支
频
率
∗
分
支
代
价
流
水
线
深
度
第三章.指令集并行
循环级并行:循环的各次迭代之间可以并行执行
指令相关性
1.数据依赖(真数据依赖)
i,j存在数据相关的条件:(满足任意一个)
1.指令i生成的结果被指令j用到(
RAW
)
2.指令i数据相关于指令k,指令k数据相关于指令j(即存在一条相关的链)

2.名称依赖(不是真正的依赖)
两条指令使用相同的寄存器或存储器位置(称为名称),但指令间并没有数据流通
类型
:(指令i在指令j之前)
(1)反依赖:指令j对指令i读取的寄存器或存储器位置执行写操作(
WAR
)

(2)输出依赖:指令i和指令j对同一个寄存器和存储器位置执行写操作(
WAW
)

解决方法
:寄存器重命名
3.控制依赖
无:不会
4.循环展开
1.展开(循环体复制多次)
2.融合(消除不必要的代码,去除多余的测试和分支指令,调整迭代代码和终止条件)
3.重命名(使用不同的寄存器,防止名称依赖)
4.scheduling(排序,将代码重新按照一定顺序排列,保持必要依赖)
动态调度算法
1.Scoreboard(记分牌)
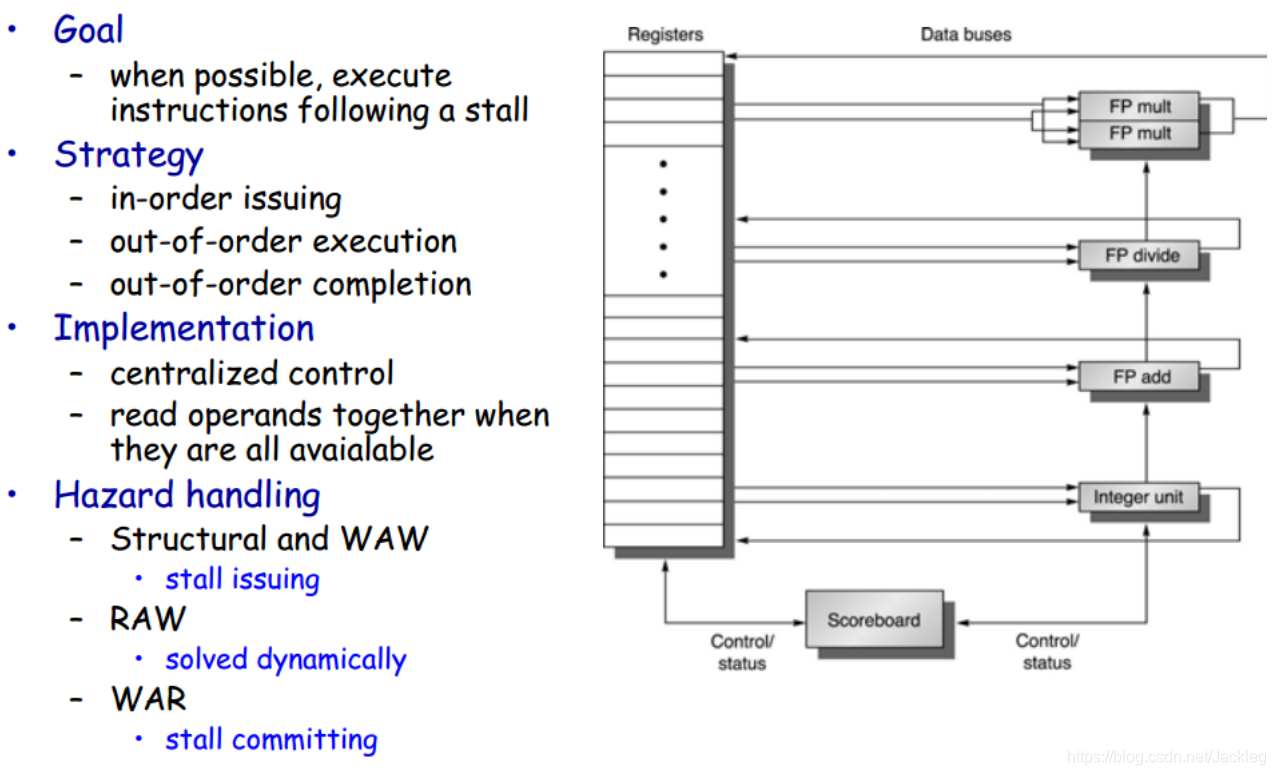
过程:
1.Issue(发射) 2.Read Operation(读取操作数) 3.EX(执行) 4.WB(写回)
特点:顺序发射,乱序执行
执行时间:
| 编号 | 类别 | 时钟周期数 |
|---|---|---|
| 1 | FP add(浮点加) | 2 cycle |
| 2 | FP mut(浮点乘) | 10 cycle |
| 3 | FP div(浮点除) | 40 cycle |
| 4 | integer(整数类型) | 1 cycle |
2.Tomasulo(托马苏洛)
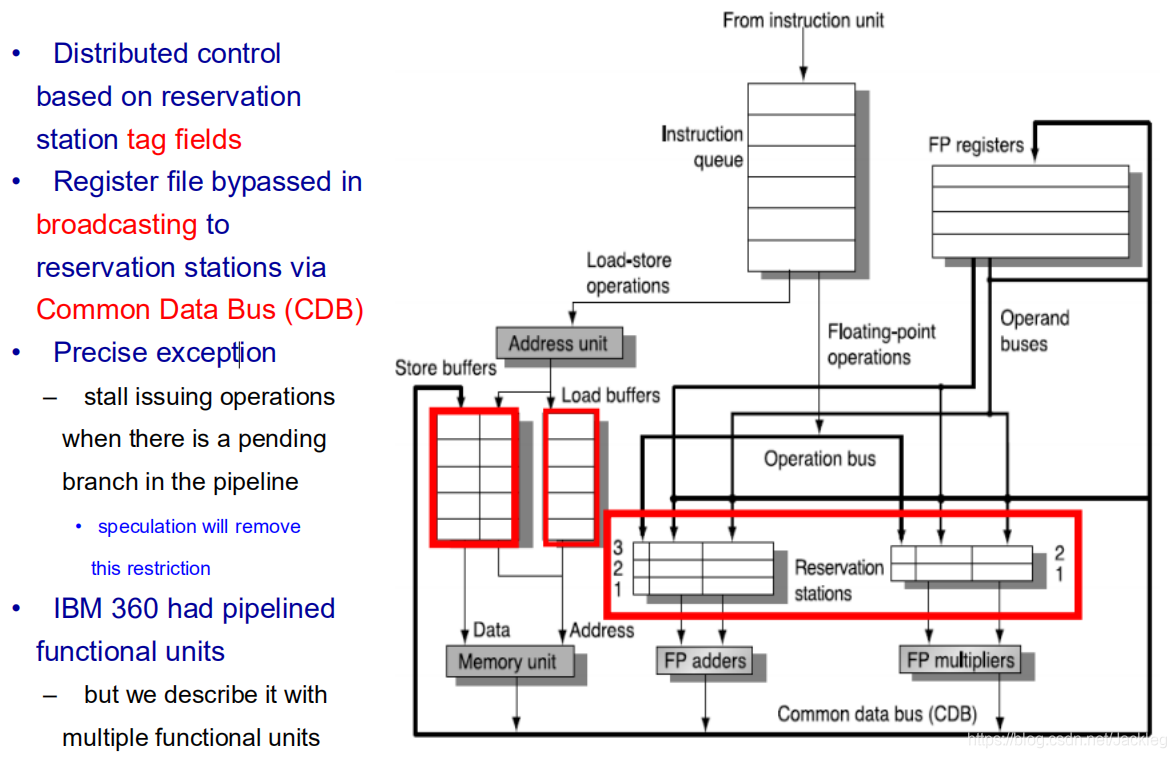
过程:
1.Issue(发射+取操作数) 2.EX(执行) 3.WB(写回)
特点:
- 采用总线传输数据
- Issue时取操作数到寄存器中,EX后存储写回地址,都实现了寄存器重命名,因此不用考虑WAR,WAW依赖(但是RAW依赖要等到写回之后)
举例:

流水线时空图:

3.Tomasulo VS Scoreboard
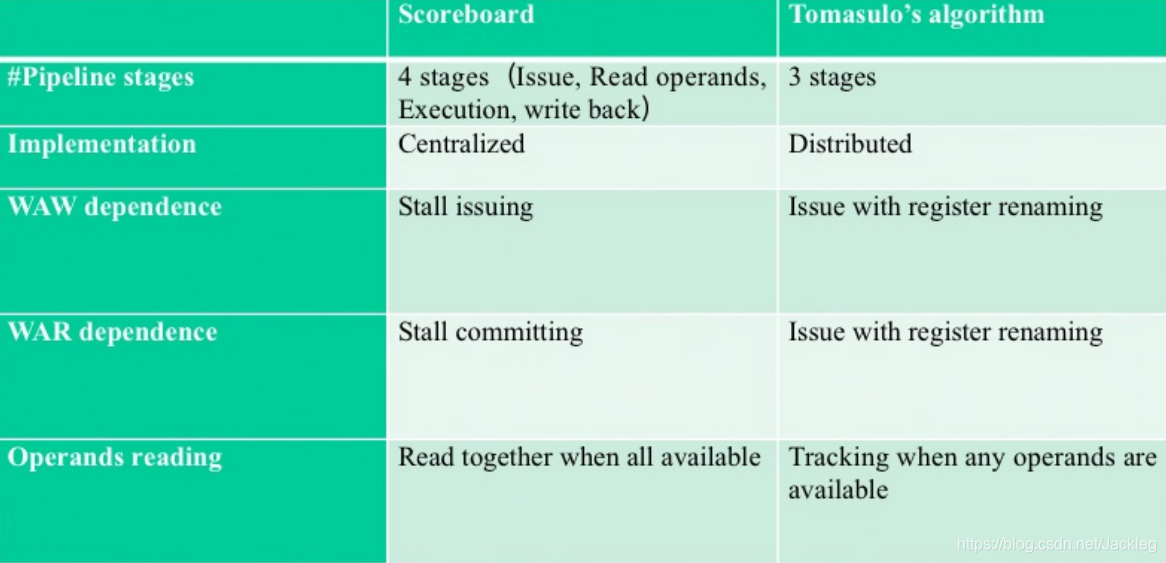
**Tomasulo优势:**减少了结构冒险(load,store),基于总线(CBD)传输数据