一、流程简介
mmdetection训练 -> mmdeploy转onnx -> onnx2tf转成tflite
各部分安装流程,参考各自官方文档即可
二、mmdetection 使用经验 & 问题记录
2.1 yolox相关
不要做大角度旋转增强:非旋转目标检测,矩形框在大角度旋转增强后会产生较大偏差,所以数据增强mosaic+仿射变换时,限制了小角度10度的旋转。(加了大角度增强后,map下降很多)
单独关mosaic而保留仿射变换,目标检测框数据异常(待确认):
import matplotlib.pyplot as plt
import mmengine, mmdet
from mmengine.runner import Runner
from mmdet.registry import DATASETS#from mmdet.datasets import build_dataloader, build_dataset
from mmdet.utils import register_all_modules
register_all_modules()
cfg = mmengine.config.Config.fromfile('../yolox.py')
d = DATASETS.build(cfg.train_dataloader.dataset)
d.get_data_info(11700)#gt数据
#增强后的数据,检测框消失??
dd = d.__getitem__(11700)
input_data = np.array(dd['inputs'])
print(input_data.shape)
print(dd['data_samples'].gt_instances['bboxes'])
rgb = cv2.cvtColor(np.transpose(input_data,[1,2,0]), cv2.COLOR_BGR2RGB)
plt.imshow(rgb)
2.2 误差分析gt_instances找不到
解决:直接注释掉/mmdetection/tools/analysis_tools/analyze_results.py中 gt_instances相关的行
影响:不画出gt框而已
三、mmdeploy 使用经验 & 问题记录
3.1 onnx转换时,去除模型中的nms算子
参考文档说明
如何拆分 onnx 模型 — mmdeploy 0.12.0 文档
_base_ = ['./detection_onnxruntime_static.py']
onnx_config = dict(input_shape=[608, 352]) #w, h
partition_config = dict(
type='yolox_partition', # the partition policy name
apply_marks=True, # should always be set to True
partition_cfg=[
dict(
save_file='yolox.onnx', # filename to save the partitioned onnx model
start=['detector_forward:input'], # [mark_name:input/output, ...]
end=['yolo_head:input'], # [mark_name:input/output, ...]
output_names=[f'pred_maps.{i}' for i in range(3)]) # output names
])转换命令:python ./tools/deploy.py …onnxruntime_static_partition.py 模型配置 pth模型 测试图片 –work-dir ./tmp
转换过程会报错,但是onnx模型已生成,只是图片预测没有正常执行。
3.2 支持指定模型输入尺寸(H,W)
问题:上述配置的input_shape=[608, 352],实际上会被强制pad到608×608。
原因:test_pipline中有pad操作
解法:修改mmdeploy/codebase/mmdet/deploy/object_detection.py,create_input函数里194行
pipeline = cfg.test_pipeline
#onnx转换时强制删除pad,避免转出来的模型文件H==W。[可能会影响推理结果对齐,仅影响mmdeploy]
for i, step in enumerate(pipeline):
if step['type'] == 'Pad' :
pipeline.pop(i)
break影响:会影响mmdeploy转换时的推理结果对齐,但不影响mmdetection
3.3 deploy.py源码分析
torch2ir -> torch2onnx -> load pytorch model,调用onnx.export生成end2end.onnx
ir_files = end2end.onnx
partition_cfgs -> extract_model -> parttion.onnx [mark名称可以通过打印跟踪,apis/onnx/partiton.py, line109的attr属性]
| mark标记:rotate rtmdet后处理的输入是box、score,前序还有一些角点计算转换,要去掉。(一般是在models/xxx_head里)
| partition里的start、end写[mark名称:input]
ir_files = end2end.onnx + parttion.onnx
四、onnx2tf 使用经验 & 问题记录 (主要对齐pad计算)
onnx2tf能解决pytorch(N,C,H,W) 与 tf(N,H,W,C)间的转换,避免出现多余的transpose op。
但pytorch与tf之间stride=2卷积pad方式不同导致的计算差异,
理论上必现通过卷积前置pad op的方式实现
。(想完全对齐结果,只能在pytorch、tf里选一个加pad,看要牺牲哪边的性能)
4.1 pytorch与tensorflow卷积padding差异
原因:pytorch卷积使用对称pad, tensorflow卷积在stride>1时会出现非对称pad(优先pad右下),导致计算结果不对齐
现象:为了修复这种不对齐,onnx2tf导出的tflite会在卷积前置pad op。即(pytorch/onnx)conv_s2_pad1 -> (tflite)pad 1 + conv_s2_’valid’, 如下
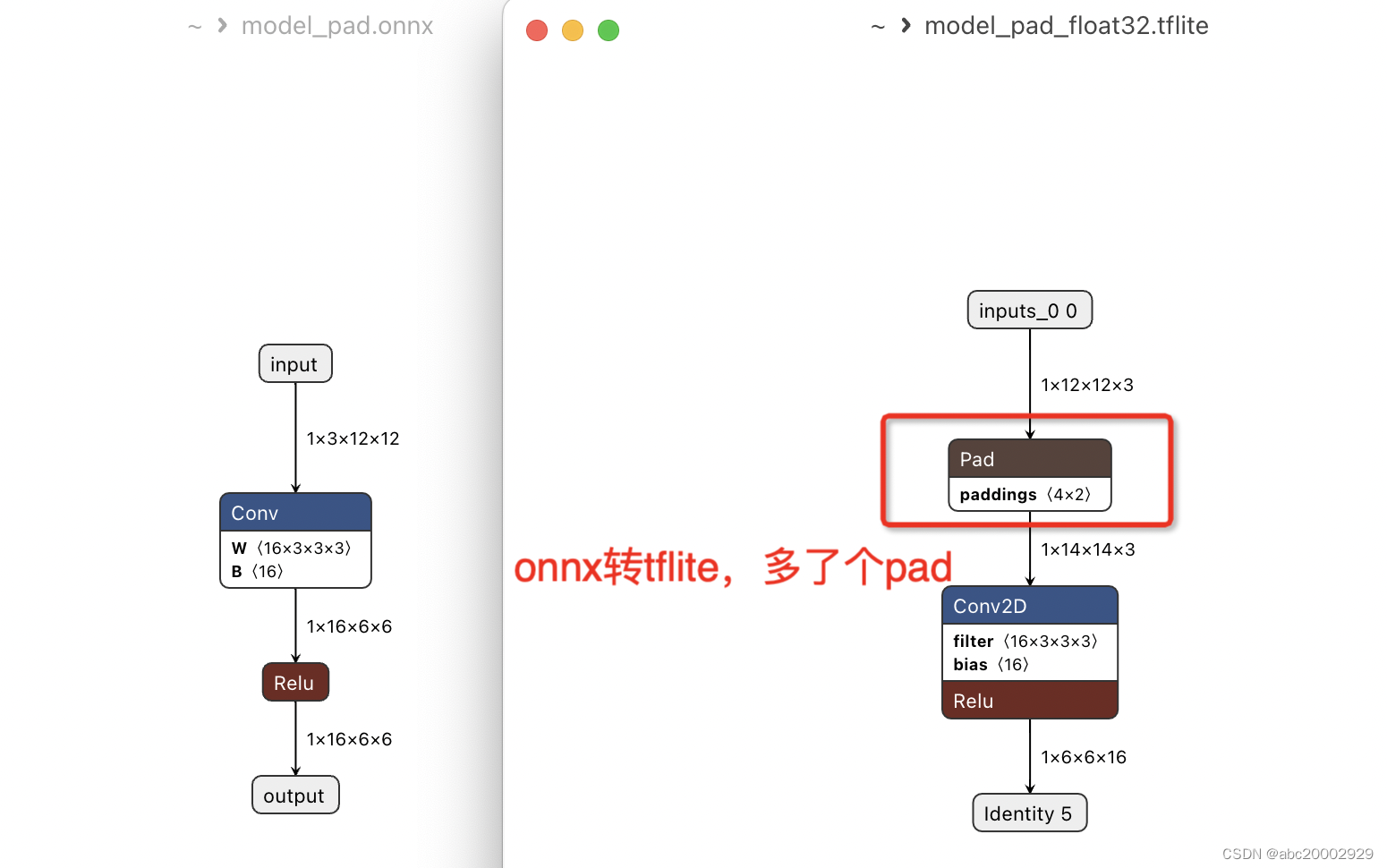
解法1:(tflite)pad 1 + conv_s2_’valid’ -> (tflite)conv_s2_’same’ 。pad强制改为SAME,删除Pad节点,但
计算结果会不对齐,要看对任务精度影响大不大
。修改源码onnx2tf/ops/Conv.py, 167行
备注 – 如果是(tflite)pad 0101 + conv_s2_’valid’ -> (tflite)conv_s2_’same’,则计算是对齐的。
(如果pytorch导出的onnx模型自动把pad+conv融合了,那就直接用这个解法)
pad_mode = 'VALID'
padded = False
+ #删除conv前的padding机制, 强制用SAME
+ auto_pad = "SAME_UPPER"
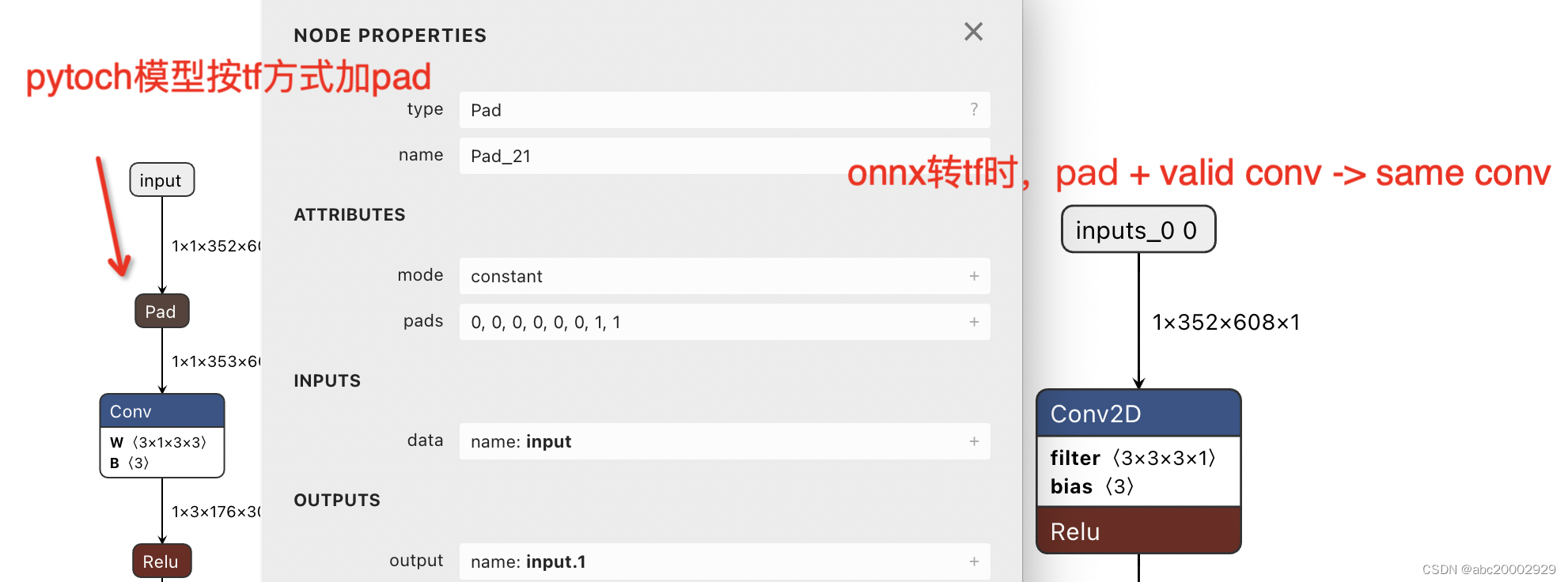
解法2:(pytorch/onnx)pad_
0101
+ conv_s2_pad
0
-> (tflite)conv_s2_’same’。pytorch建模时按tf的stride=2、’same’方式,卷积前前置一个pad op,替换原来的conv_s2_pad
1
。onnx转换时,在强制融合pad+conv。(思考:这个方式之所以没人支持,主要是因为需要pytorch侧配合加pad op。而且是
以转tflite为最终目的,牺牲了pytorch推理性能,且需要重新训练修改后的pytorch模型
)
(如果pytorch导出的onnx模型是pad前置在conv前的,那就用这个解法)
pytorch的opset>=11的时候会出现constant无法折叠的问题,export时需设为opset=10
具体的mmdetection模型修改代码:
from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
import torch
import torch.nn as nn
import numpy as np
class tfConvModule(ConvModule):
def __init__(self, *argv, **kw):
if ('stride' in kw) and kw['stride'] == 2: #只修改stride==2的情况
kw['padding'] = 0 #取消原来的pad, 原来stride=2时pad会设为1
self.tf_pad = True
else:
self.tf_pad = False
super().__init__(*argv, **kw)
def forward(self, x, *argv, **kw):
if self.tf_pad:
x = torch.nn.functional.pad(x, (0,1,0,1)) #右下pad1
return super().forward(x, *argv, **kw)
class tfDepthwiseSeparableConvModule(DepthwiseSeparableConvModule):
def __init__(self, *argv, **kw):
if ('stride' in kw) and kw['stride'] == 2: #只修改stride==2的情况
kw['padding'] = 0 #取消原来的pad, 原来stride=2时pad会设为1
self.tf_pad = True
else:
self.tf_pad = False
super().__init__(*argv, **kw)
def forward(self, x, *argv, **kw):
if self.tf_pad:
x = torch.nn.functional.pad(x, (0,1,0,1)) #右下pad1
return super().forward(x, *argv, **kw)然后在对应的模型结构backbone/neck/head中,替换原卷积:
#from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
from ..tfconv import tfConvModule as ConvModule
from ..tfconv import tfDepthwiseSeparableConvModule as DepthwiseSeparableConvModuleonnx2tf中对pad、conv进行fuse:
###onnx2tf/onnx2tf.py文件
last_pad_node = None
for graph_node in graph.nodes:
optype = graph_node.op
+
+ # 强制融合tf_pad + conv(valid) -> conv(same)
+ if optype == 'Pad':
+ last_pad_node = graph_node
+ continue
+ if optype == 'Conv' and last_pad_node.outputs[0] == graph_node.inputs[0]:
+ graph_node.inputs[0] = last_pad_node.inputs[0] #skip pad
+ graph_node.attrs['pads'] = [1,1,1,1]
+ graph_node.attrs['auto_pad'] = 'SAME_UPPER' #valid -> same
+
try:
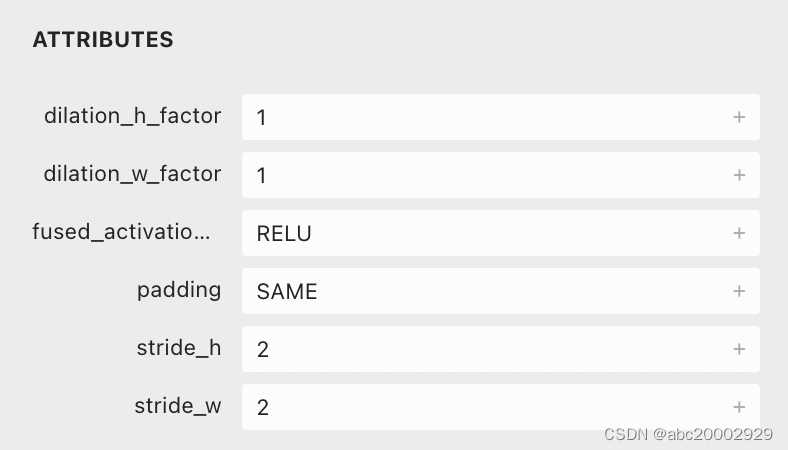
op = importlib.import_module(f'onnx2tf.ops.{optype}')解法3:修改tflite推理引擎,让其卷积在stride=2的时候按左上pad方式计算(右下也pad了,但数据没用到)。(思考:tflite为什么不支持?这样会影响正常的tf conv,需要额外加一个标记区分是否是torch conv,但这个标记加在哪呢?)
tflite conv op没有这类参数,如果加个is_pytorch,true时pad左上角,false按原tf方式pad右下角(非标准的私有引擎比较容易支持,只需考虑conv时pad的行为就可以,类似pytorch灵活配置)
4.2 onnx转tf,同时输出h5模型
onnx2tf -i yolox.onnx -oh5
其他:尝试openvino将onnx转tflite,也是一样有pad。理论上就不可能转成没有pad且计算一致结果。过程如下:
1.onnx->openvino,
直接用openvino工具,输出.bin和.xml
命令:mo –input_model model.onnx
2.openvino->tflite
用openvino2tensorflow工具,
命令:PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python openvino2tensorflow –model_path model.xml –output_no_quant_float32_tflite