一篇简单的工程化笔记。
数据
首先,我们跳过知识图谱构建这个过程,直接用开源的中文数据集,知识图谱的构建够写个三天三夜里了,这里推荐一个中文知识图谱数据集,这个数据集非常大,数据也很干净。
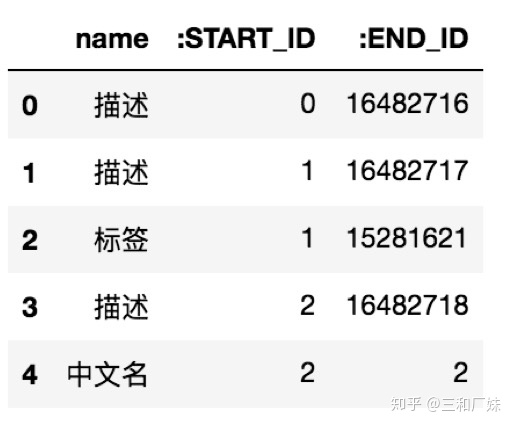
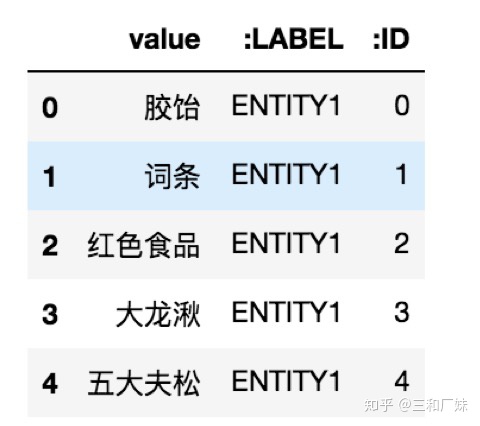
拿到这个大表后,从这个表里提取出实体和实体关系(一通。pandas操作),用于导入图数据库。表头有特殊含义,必须
按一定顺序,固定为一些字段
,参考Neo4j的文档。
图数据库
知识图谱一般是使用图数据库存储,虽然一般的关系型数据库也可以,但是图数据库的优点在于它是按节点Node存储,直接存储了关系,所以它在对于用于推断时,检索速度会比关系型数据库快很多。之前有人测过搜索Node(也就是如my sql中的一条记录)时,Neo4j和mysql的速
版权声明:本文为weixin_39848953原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。