图(有向图和无向图)的储存方法有邻接矩阵和邻接表两种储存方式。
其中
邻接表有两种实现方式:1.指针。2.数组
后者使用比较方便简洁,这里介绍一下用
数组实现邻接表储存图
输入数据
4 5
1 4 9
4 3 8
1 2 5
2 4 6
1 3 7
4表示顶点个数 5表示输入的边数
用邻接表储存这个图,代码如下
(我觉得有点乱,hh,理解不太清楚就不要用这个方法,直接
跳过
这个,看后面的)
#include<stdio.h>
int main(void)
{
int n,m;//n表示顶点个数,m表示输入的边数; 这里用n=4(点),m=5(边);举例
int i,k;
int u[6],v[6],w[6];//第一,二个数组是储存顶点的,第三个是储存该边的权值的;
//这三个数组的大小要根据m来定,比m大一就行了;
int first[5],next[6];
//这两个数组也要看实际,first数组比n(顶点)大一,next数组比m(边)大一
scanf("%d %d",&n,&m);
for(i=1;i<=n;i++)
first[i]=-1;//初始化first数组,表示1~n顶点暂时还没有连接的边;
for(i=1;i<=m;i++)
{
scanf("%d %d %d",&u[i],&v[i],&w[i]);//依次输入顶点和所连接的边权值
//下面两句是关键
next[i]=first[u[i]];
first[u[i]]=i;//为边编号,保证遍历时u[],v[],w[]输出的准确
}
printf("\n");
/*其实就是 最终储存依次 从一个顶点出发的所有边(i其实就是这些边的编号)
下面是邻接表的遍历输*/
for(i=1;i<=n;i++)
{
k=first[i];/*选出顶点 1 开始遍历 first可以理解为储存顶点编号,
其实 也储存了最后一次输入边的编号*/
while(k!=-1)//一直输出与该点连接的边直到没有(next【】==-1)
{
printf("%d %d %d\n",u[k],v[k],w[k]);//其实k就是边的编号
k=next[k]; //变为该顶点连接的下一条边 的编号
}
}
return 0;
}
输入输出如下
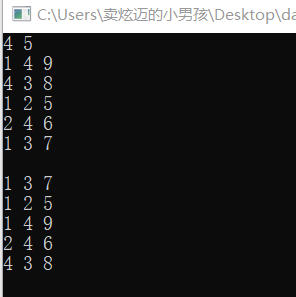
first[5]= {5,4,-1,2}这里的值都是最后一次输入边的编号
next[6]={-1,-1,1,-1,3}
可以发现使用邻接表来储存图的时间空间复杂度是O(M),遍历每一条边的时间复杂度也是O(M)。如果是稀疏图的话,M要远小于N
2
我们可以使用邻接表来代替邻接矩阵( Q(n
2
) )降低时间复杂度,邻接表最坏的情况下才和邻接矩阵一样,但是一般情况下并不会有那么多边。
上面是啊哈算法中实现用数组实现链表储存图的方法
不过我觉得使用时不是很方便,而且容易出错,所以不习惯用这个
,
现给出两种简便快捷的实现方法:
一、数组实现方法
:**
我们先定义一个结构体数组:
struct node{//u->v
int v;//记录当前顶点
int next;//与u相连的上一条出边
}a[maxx*2];//储存无向图
a就是实现链表的结构体数组:
下面先给出它的
输入
方法:
int c=0;//边的编号
int head[10000];//数组长度为顶点个数
void addage(int x,int y)
{
a[++c].v=y; a[c].next =head[x]/*顶点*/;head[x]=c/*第几条边*/;//x->y
a[++c].v =x;a[c].next =head[y];head[y]=c;//y->x;//如果是有向图的化省略这一行
return;//无向图
}
int main(void)
memset(head,-1,sizeof(head));//初始化为-1
for(int i=1;i<=m;i++){//m为边的总数
scanf("%d %d",&x,&y);//x->y
addage(x,y);
}
这里用数组实现链表,可以这样
理解
:
链表的储存可以想象成:储存编号为0~n-1的砖头
每个顶点可以看成一堆砖头,
在每一堆砖头中,
一层一层碟砖头,head记录该堆砖头最后一次出边的编号
遍历找某一顶点的出边的时候:用head找出顶点录入的最后一条出边,然后依次访问每一条边(因为C被记录在next里了)
还不太懂?那下面给出它的
遍历方法
,容易理解:
注意head的初值为-1,即遍历到顶点编号为-1停止
for(j=head[x];j!=-1;j=a[j].next )//x为你要的顶点,这一个循环就是遍历x的每一条出边
//a[j].v为x指向的顶点编号
你如果还想要储存每条边的权值的话可以直接在结构体里定义。
二、vector
看到这是不是觉得这个挺好用的,
下面再讲一个更有意思的
,学过C++ STL容器的都知道里面有个
vector
。
当我们初学图论的时候我们都会优先使用邻接矩阵,因为我们就会这个,也容易理解对于初学者来说,其实我们可以
用vector代替二维数组来实现邻接矩阵
。
我们储存图一般定义一个二维数组e[100][100],如果a,b之间有边,e[a][b]就设为1.
那我们用vector怎么
储存
和
遍历
呢?
1,定义
vector <int> e[100];
2,如果a,b之间有边,那么我们直接:
e[a].push_back(b);
3,遍历的时候我们,如果要遍历顶点a的所有出边,那么我们可以这样做:
for(int i=0;i<e[a].size();i++)
就好了,这样同样可以缩减遍历的时间,就和链表的速度差不多。我在做图论的题目都比较喜欢用这种方法而且我觉得比较好理解,通俗易懂吧,关键是和普通的邻接矩阵使用差不多,又省时。
【强推】
后面两种方法都挺好的,看自己了。