1、打开(缓冲)文件、读文件
1)文件模式
| 模式 | 意义 |
|---|---|
| r | 只读模式 |
| w | 写模式 |
| a | 追加模式 |
| + | 读写(更新)模式,可与其他模式结合使用。比如 r+ 代表读写模式,w+ 也代表读写模式(w 模式会清空文件,因此实际中不可读) |
| b | 二进制模式,可以其他模式结合使用。比如 rb 代表二进制只读模式,rb+ 代表二进制读写模式,ab 代表二进制追加模式 |
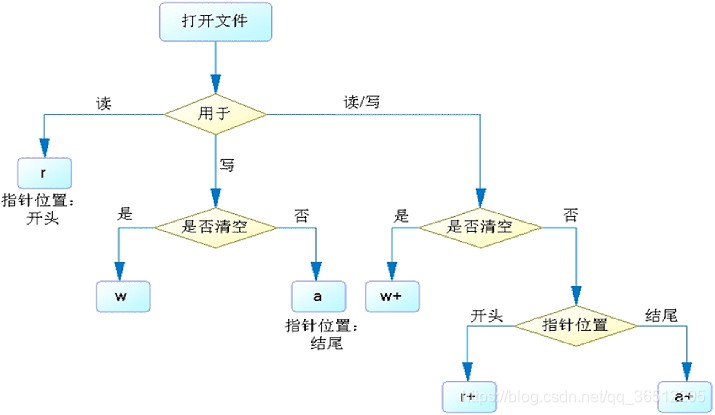
分析
:
- w 只是代表写模式,而 w+ 则代表读写模式,但实际使用中差别并不大,因为文件被清空了。
- r 或 r+ 模式打开文件,要求文件本身是存在的,它们都不能创建文件。
- 使用 w、w+、a、a+ 模式打开文件,该文件可以是不存在的,open() 函数会自动创建新文件。
- b 模式可被追加到其他模式上,用于代表二进制的方式读写文件内容(若没有指定 b 模式,以字符为单元读写文件;如果指定了 b 模式,以字节为单元来读写文件(计算机并不会以位为单元读取文件,一个字节有 8 位))
2)open()打开文件和read()读取文件
语法
:open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
说明
:open() 函数第三个参数
buffering
控制缓冲
-
值为负,缓冲大小为系统默认;
-
值为 0 或 False,不会缓冲;
-
值为 1 或 True,会缓冲(推荐,此时程序执行 I/O 具有更好的性能);
-
值大于 1 的整数,为缓冲大小。
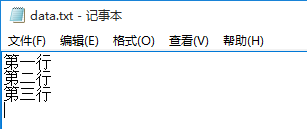
(1)创建一个 data.txt 文件:
(2)按字符读取
说明
:
- 不加 b 模式打开文件,那么文件被当成字符流处理,每次读取一个字符
-
open() 函数默认总按当前操作系统字符集来读取文件内容(
查看当前操作系统字符集
)
-
调用 read(n) 方法读取 n 个字符
f = open('data.txt', 'r', True) data1 = f.read(1) print(data1) print('-'*30) data2 = f.read(2) print(data2) f.close() # 关闭文件第 ------------------------------ 一行分析:
- data.txt 文件为 GBK 字符集编码(当前操作系统编码为 GBK)
- read(1) —> read(2) 文件指针移动
-
调用 read() 方法全部文件内容
f = open('data.txt', 'r', True) data = f.read() print(data) f.close()第一行 第二行 第三行
分析
:open() 函数默认按当前操作系统字符集来读取文件内容,容易引发异常,解决方式如下。
-
调用 open() 函数打开文件时指定字符集
f = open('data.txt', 'r', True, 'GBK') print(f.read()) f.close()第一行 第二行 第三行 -
open() 函数以二进制方式读取文件,然后以指定字符集来恢复字节数据(见下)
(3)按字节读取
说明
:以 b 模式打开文件,那么文件被当成二进制流处理,每次读取一个字节
-
调用 read(n) 方法读取 n 个字节
f = open('data.txt', 'rb', True) data1 = f.read(2) print(data1, data1.decode('GBK')) # 字节串,GBK 解码 print('-'*40) data2 = f.read(4) print(data2, data2.decode('GBK')) f.close()b'\xb5\xda' 第 ---------------------------------------- b'\xd2\xbb\xd0\xd0' 一行 -
调用 read() 方法全部文件内容
f = open('data.txt', 'rb', True) data = f.read() print(data) print('-'*50) print(data.decode('GBK')) f.close()b'\xb5\xda\xd2\xbb\xd0\xd0\r\n\xb5\xda\xb6\xfe\xd0\xd0\r\n\xb5\xda\xc8\xfd\xd0\xd0\r\n' -------------------------------------------------- 第一行 第二行 第三行
分析
:
- GBK 字符集编码中每个字符占 2 个字节
- rb 模式读取文件,可用于处理任意文件内容,如图片、音乐、视频等格式
3)按行读取文本文件
(1)readline([n])和readlines()
-
readline([n]):读取一行内容,若指定了参数 n,则只读取此行内的 n 个字符
try: f = open('data.txt', 'r', True, 'gbk') while True: line = f.readline() # 读取一行内容 if not line: break print(line, end='') except: print('出现异常') finally: if 'f' in globals(): f.close()第一行 第二行 第三行 -
readlines():读取文件内所有行
try: f = open('data.txt', 'r', True, 'gbk') line = f.readlines() # 读取所有行,返回所有行组成的列表 print(line) except: print('出现异常') finally: if 'f' in globals(): f.close()['第一行\n', '第二行\n', '第三行\n']
(2)使用文件迭代器读取
try:
f = open('data.txt', 'r', True, 'gbk')
for line in f: # 文件对象本身可迭代,直接用 for-in 循环即可
print(line, end='')
except:
print('出现异常')
finally:
if 'f' in globals():
f.close()
第一行
第二行
第三行
(3)使用linecache读取指定行
说明
:linecache 模块允许从 Python 源文件中读取指定行,并在内部使用缓存优化存储。由于该模块主要被设计成读取 Python 源文件(Python 源文件采用 UTF-8 字符集存储),因此该模块也可读取采用 UTF-8 字符集存储的其他文件。
# -*- coding:utf-8 -*-
# @Time : 2019/7/5 10:20
# @Author : wangkai
# @File : test.py
import linecache
import random
print(linecache.getline(random.__file__, 3), end='') # 读取random模块的源文件的第3行
print('-'*30)
print(linecache.getline('test.py', 2), end='') # 读取本程序的第2行
integers
------------------------------
# @Time : 2019/7/5 10:20