UnIVAL,这是第一个能够支持图像、视频和音频文本任务的统一模型!

进NLP群—>
加入NLP交流群
大型语言模型 (LLM) 使得对通才代理的雄心勃勃的追求不再是一个幻想。
构建此类通用模型的一个关键障碍是任务和模式的多样性和异质性。
一种有希望的解决方案是统一,允许在一个统一的框架内支持无数的任务和模式。
虽然在海量数据集上训练的大型模型(例如 Flamingo(Alayrac 等人,2022))可以支持两种以上的模态,但当前的中小型统一模型仍然仅限于 2 种模态,通常是图像文本或视频-文本。
我们提出的问题是:
是否有可能有效地构建一个可以支持所有模态的统一模型?
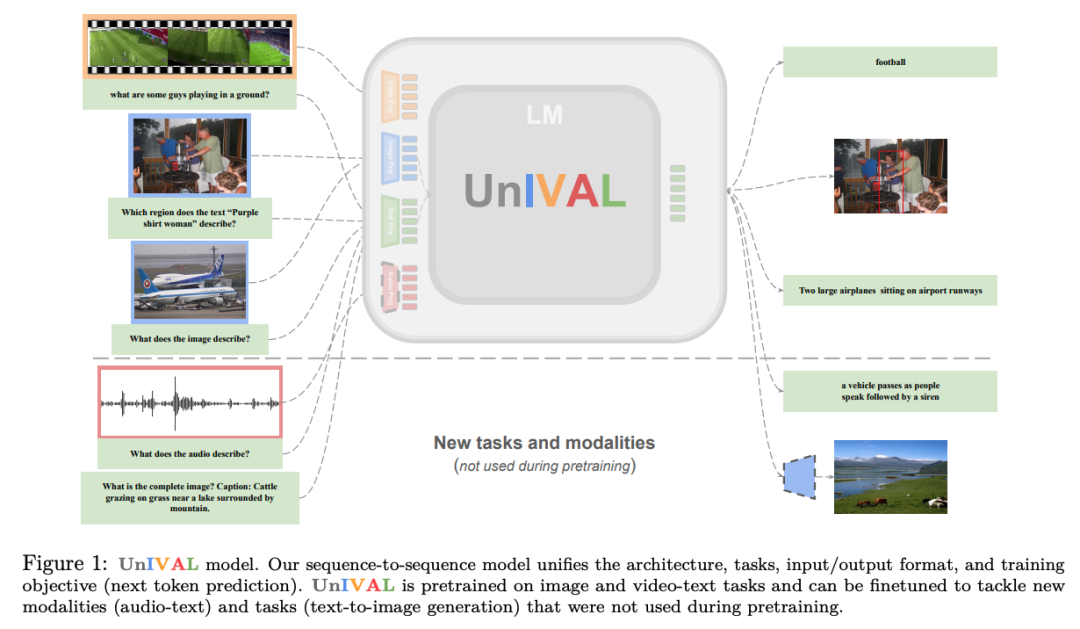
为了回答这个问题,我们提出了
UnIVAL
,朝着这个雄心勃勃的目标又迈进了一步。
不依赖于花哨的数据集大小或模型数十亿个参数,~ 0.25B 参数 UnIVAL 模型超越了两种模态,将文本、图像、视频和音频统一到一个模型中。

我们的模型基于任务平衡和多模态课程学习,在许多任务上进行了有效的预训练。
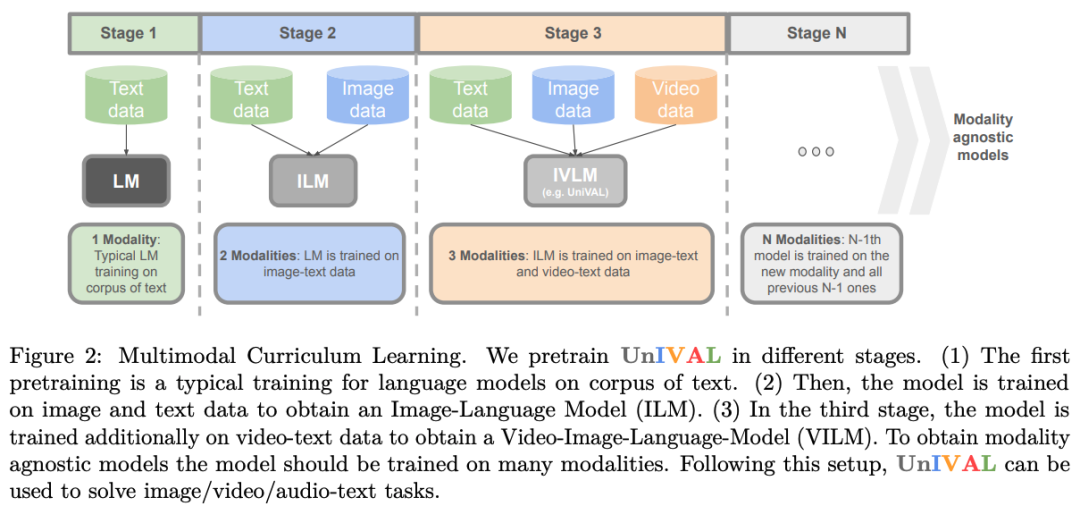

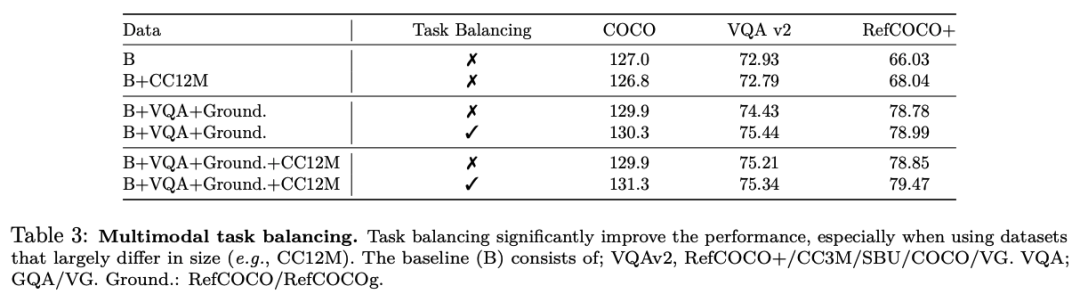
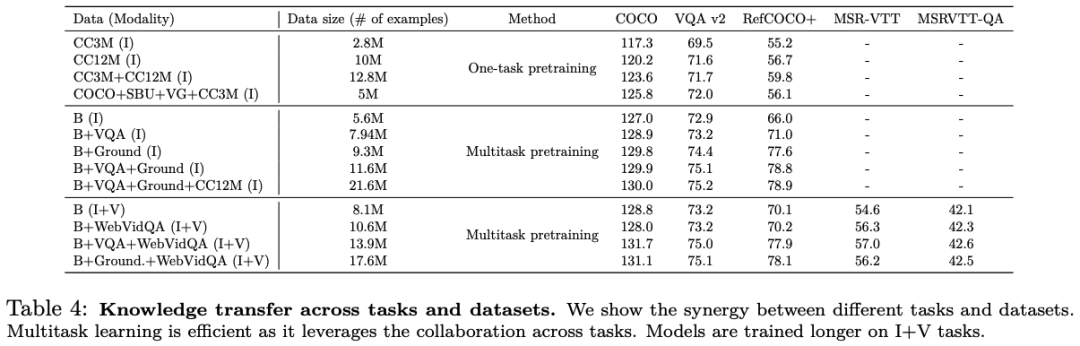
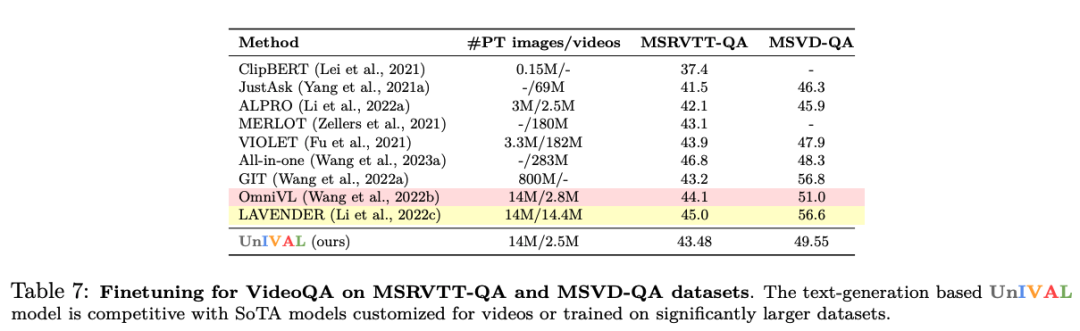
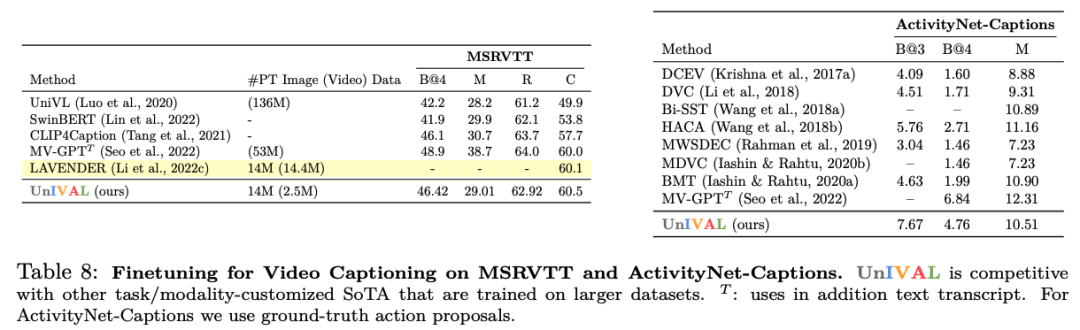
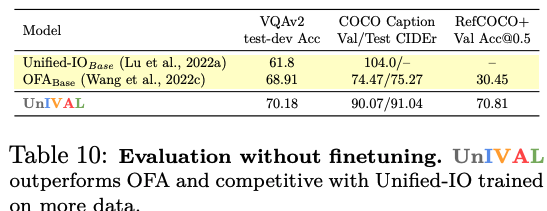
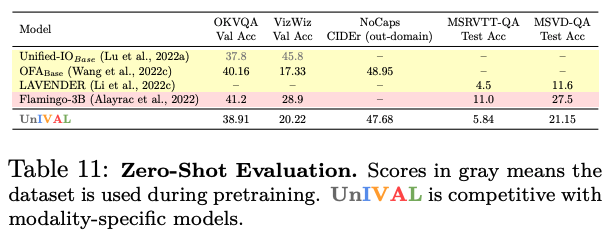
UnIVAL 显示跨图像和视频文本任务的现有最先进方法的竞争性能。
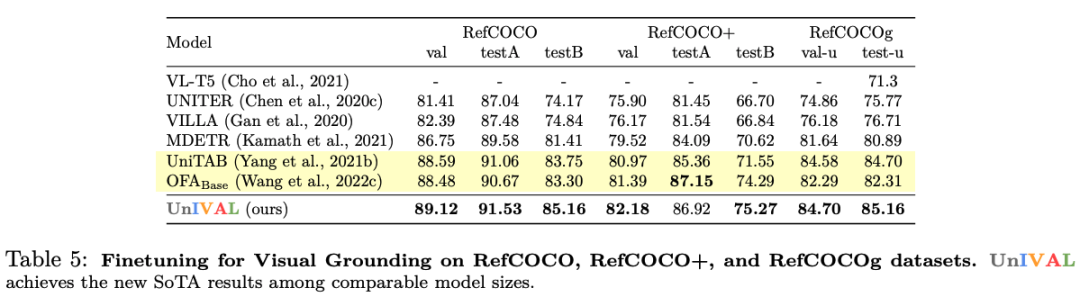
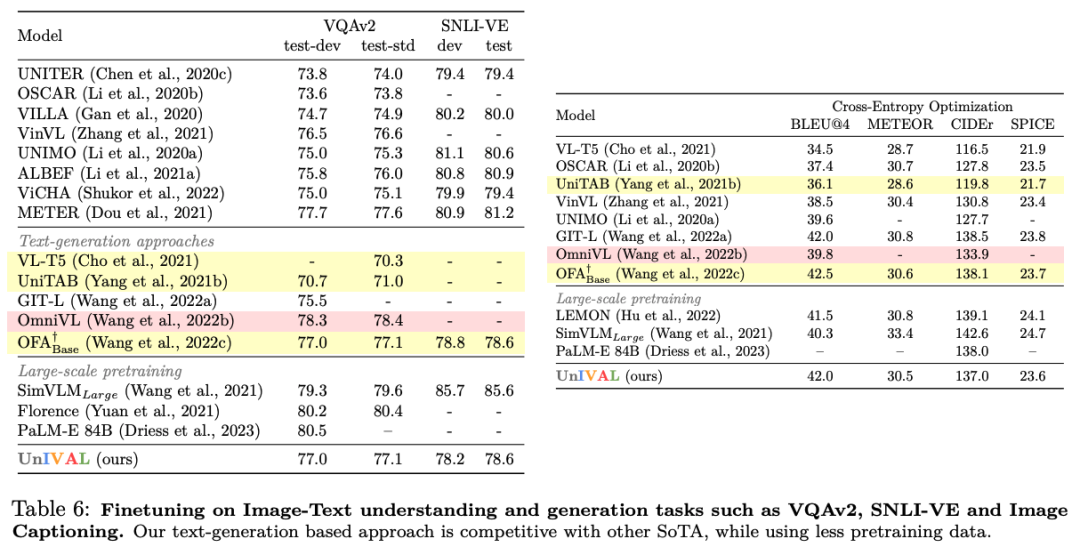
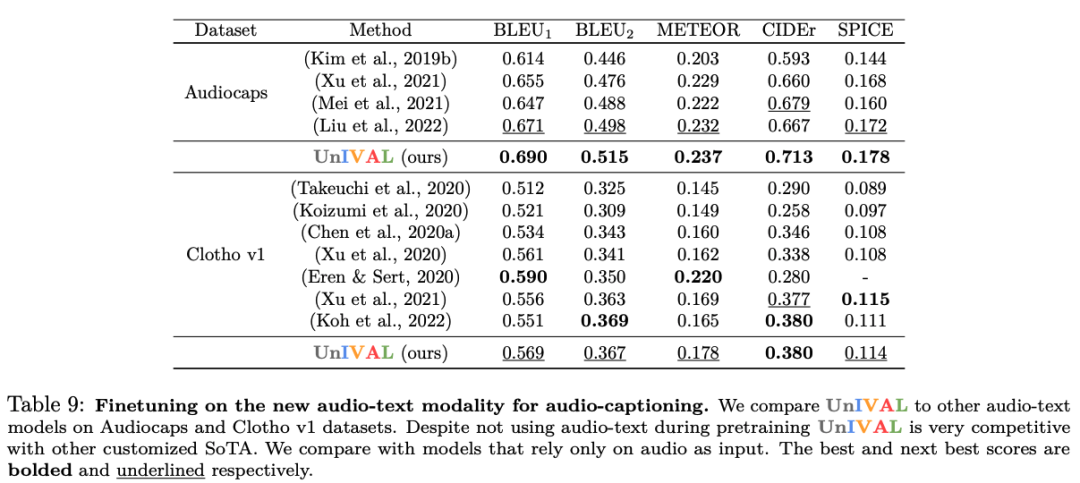
从图像和视频文本模式中学习的特征表示,允许模型在音频文本任务上进行微调时实现竞争性能,尽管没有正在对音频进行预训练。
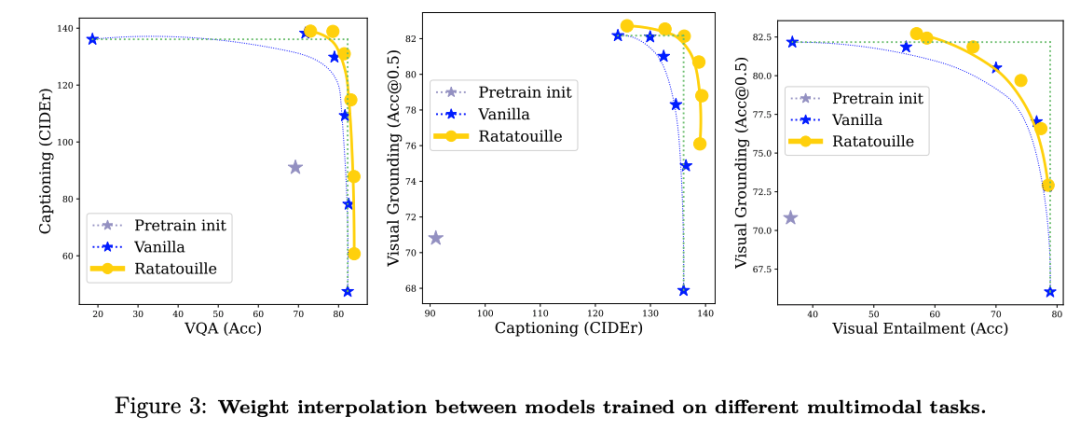
得益于统一模型,我们提出了一项通过对不同多模态任务训练的模型进行权重插值来进行多模态模型合并的新颖研究,显示了它们特别是对于分布外泛化的好处。
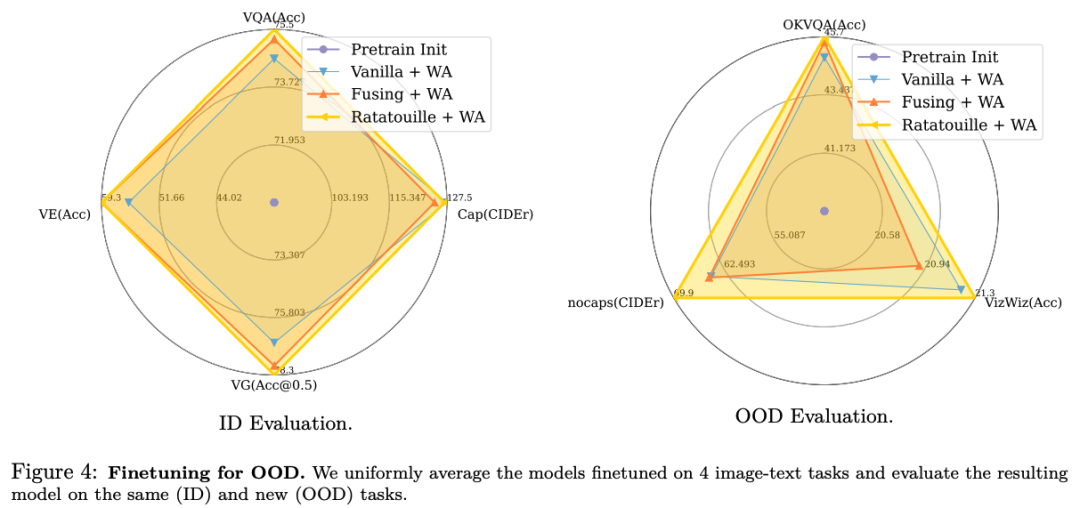
最后,我们通过展示任务之间的协同作用来激励统一。
总结
在本研究中,我们引入了 UnIVAL,这是第一个能够支持图像、视频和音频文本任务的统一模型。
我们通过一个相对较小的模型来实现这一点,该模型在相对较小的数据集上具有~ 0.25B 参数。
我们的统一系统经过多任务预训练,具有多种优势。它利用不同任务和模式之间的协同作用,实现更高效的数据训练,并对新颖的模式和任务表现出强大的泛化能力。
我们策略的统一方面为合并在不同多模态任务上微调的模型的有趣技术铺平了道路:我们证明,除了多任务预训练之外,通过权重插值合并可以进一步利用任务多样性。
最终,我们希望我们的工作能够激励研究界,并加速构建与模态无关的通才助理代理的进展。

进NLP群—>
加入NLP交流群