爬取ZOJ上的题目信息,并整理排序
为了加快自己的划水速度,我爬取了ZOJ上所有题目,然后根据AC的数量从多到少进行排序
代码:
# -*- coding:utf-8 -*-
__author__ = 'Administrator'
import requests
import csv
from lxml import etree
from urllib import request
f = open('test.csv', 'w', encoding='utf-8-sig', newline='') # 打开文件
write = csv.writer(f)
title = ['ID', 'Title', 'Ratio', 'AC', 'ALL', 'Link', 'Solved']# 头一行的内容
write.writerow(title)
l1 = [] # 用于保存每个题目的信息
# 题目类,包含ID, Title, Ratio, AC, ALL, Link, Solved属性
class Problem:
def __init__(self, ID, Title, Ratio, AC, ALL, Link, Solved):
self.ID = ID
self.Title = Title
self.Ratio = Ratio
self.AC = AC
self.ALL = ALL
self.Link = Link
self.Solved = Solved
# 排序函数
def personsort():
persons = [Problem(ID, Title, Ratio, AC, ALL, Link, Solved) for (ID, Title, Ratio, AC, ALL, Link, Solved) in l1] # 将列表中的数据写入类,再合成列表
persons.sort(key=lambda x: x.AC, reverse=True)#根据AC数从多到少排序
for element in persons:
element.AC = str(element.AC) # 将不是字符串类型的数据转换成字符串类型
# 将每组数据合成列表
data = [element.ID, element.Title, element.Ratio, element.AC, element.ALL, element.Link,element.Solved]
write.writerow(data) # 写入CSV文件
for i in range(1, 33): # 循环爬取第1-32页的网页
print("page:", i)
url = 'http://acm.zju.edu.cn/onlinejudge/showProblems.do?contestId=1&pageNumber=' + str(i)
# 爬取登录后的页面信息,需要设置header中的Cookie信息
headers = {
"Cookie": "X" # X就是你从网页上得到的Cookie
}
# res = requests.get(url).text
rep = request.Request(url=url,headers=headers)
rsp = request.urlopen(rep)
res = rsp.read().decode()
object = etree.HTML(res)
objects = object.xpath('//tr') # 从任意位置获取tr节点,如果是/tr,表示从根节点获取tr节点
for i in objects:
ID = i.xpath('td[@class="problemId"]/a/font/text()') # 题号
if len(ID) == 0:
continue
ID = str(ID) # 将列表转换成字符串类型
ID = ID[2:-2] # 去除不需要的多余字符
Title = i.xpath('td[@class="problemTitle"]/a/font/text()') # 题目名称
Title = str(Title)
Title = Title[2:-2]
Ratio = i.xpath('td[@class="problemStatus"]/text()') # 正确率
Solved = i.xpath('td[@class="problemSolved"]/font/text()')
if len(Solved) == 0:
Solved = "No"
else:
Solved = Solved[0]
if len(Ratio) != 0:
Ratio = Ratio[0][:-1]
else:
continue
AC = i.xpath('td[@class="problemStatus"]/a/text()') # 正确率
if len(AC) == 2:
ALL = AC[1]
AC = int(AC[0])#后期需要根据这个排序,所以转成int类型
else:
continue
Link = "http://acm.zju.edu.cn" + i.xpath('td[@class="problemTitle"]/a/@href')[0] # 题目链接
t1 = (ID, Title, Ratio, AC, ALL, Link, Solved) # 将信息合成元组
l1.append(t1) # 推入总列表
personsort() # 排序
f.close()
如何获取Cookie:
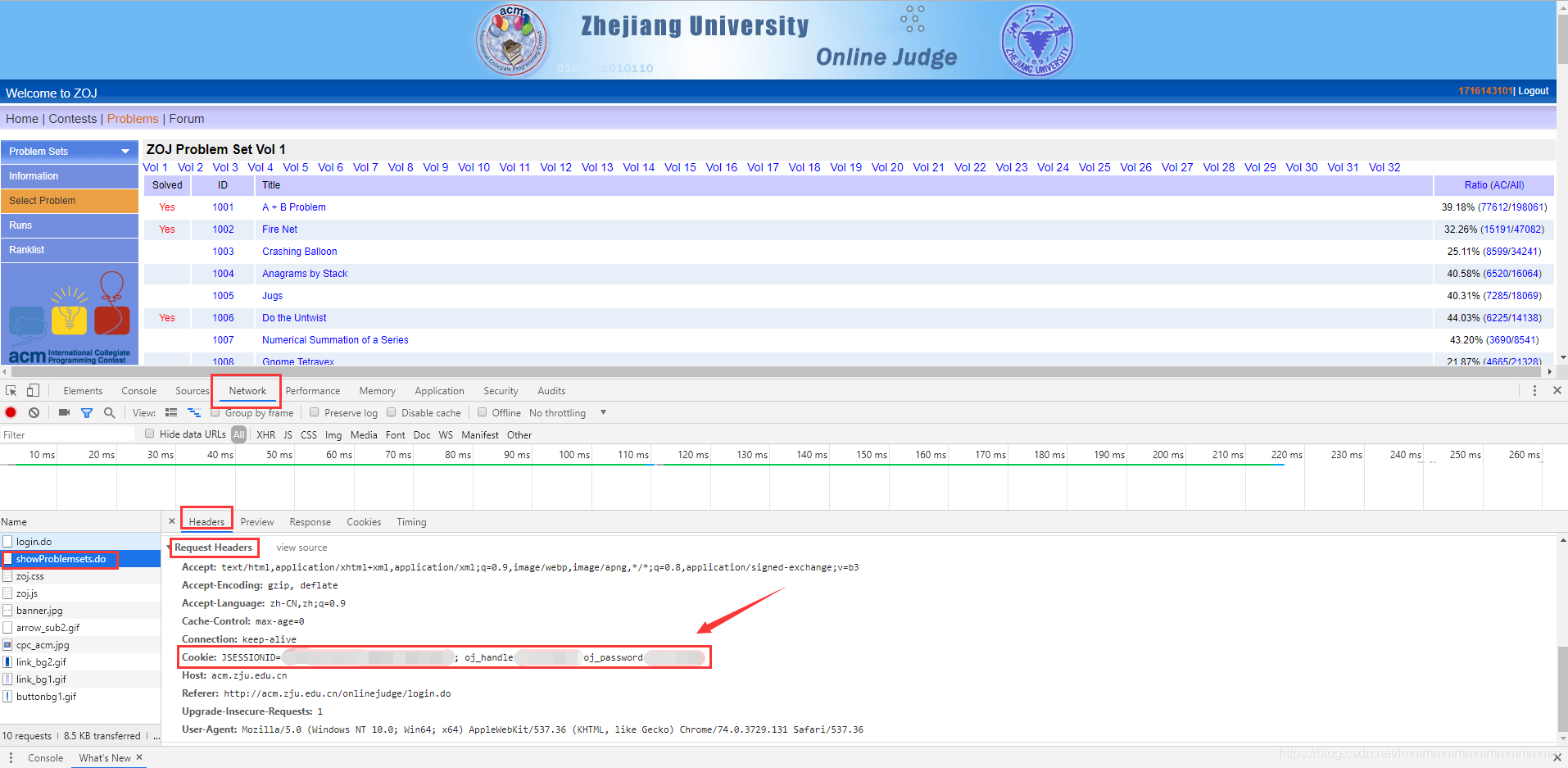
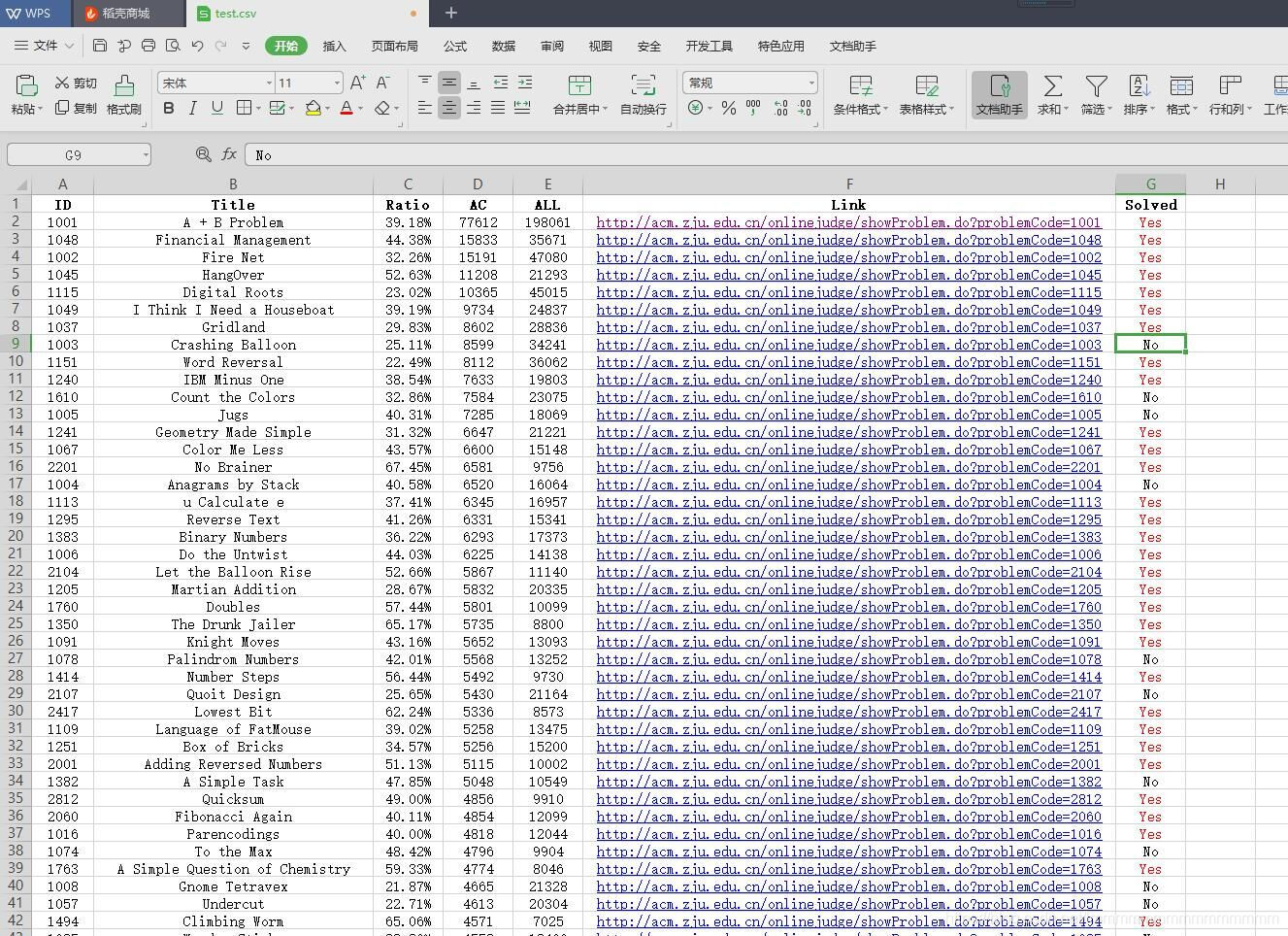
结果截图:
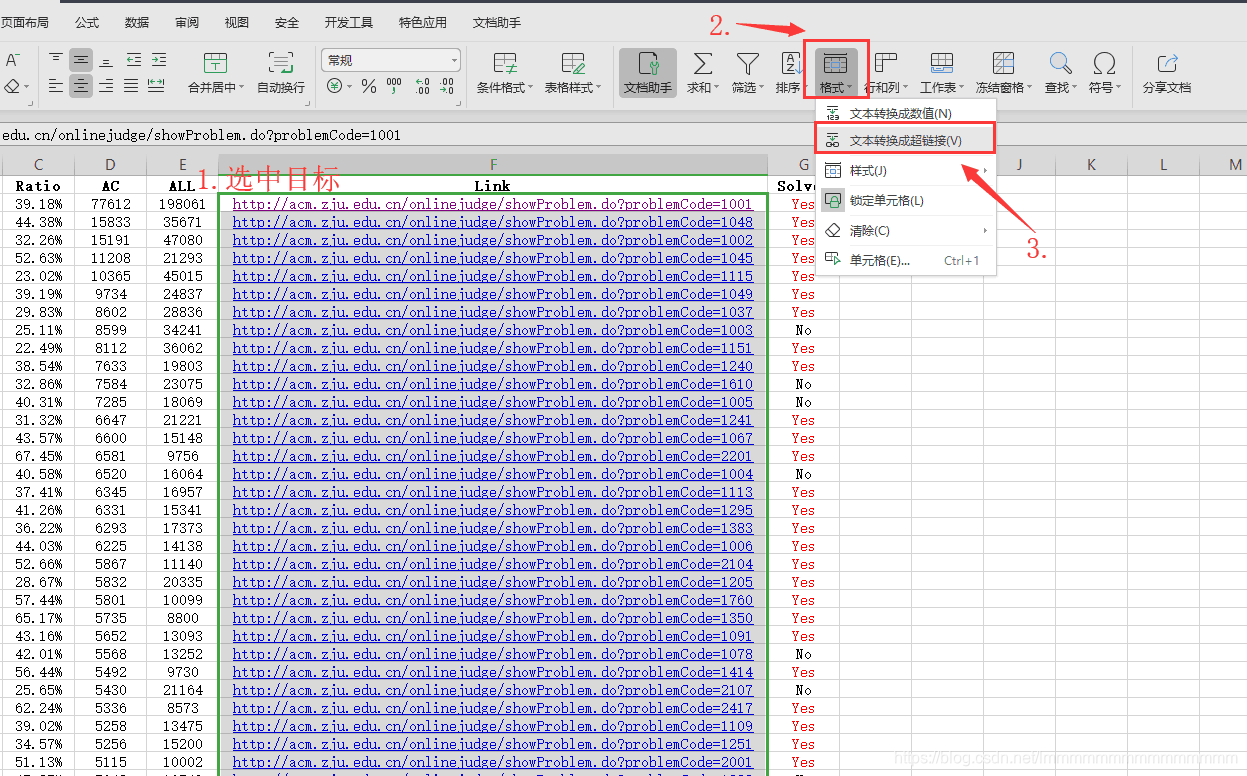
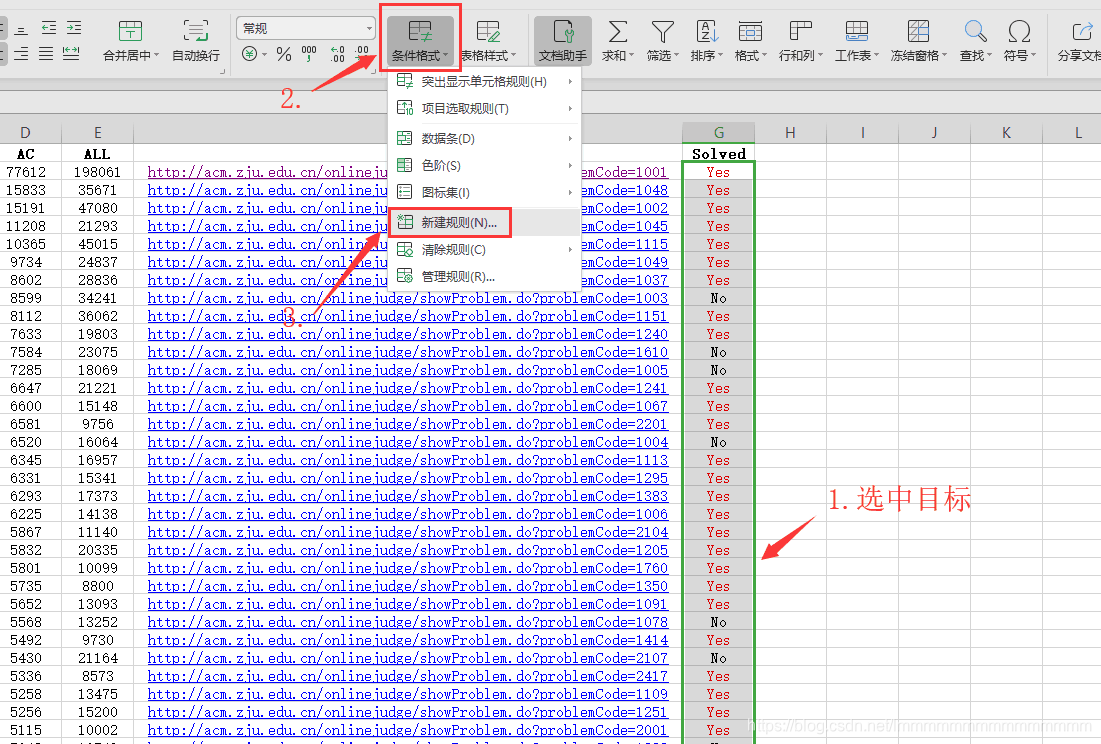
可以将“Yes”颜色设置成红色,还有超链接
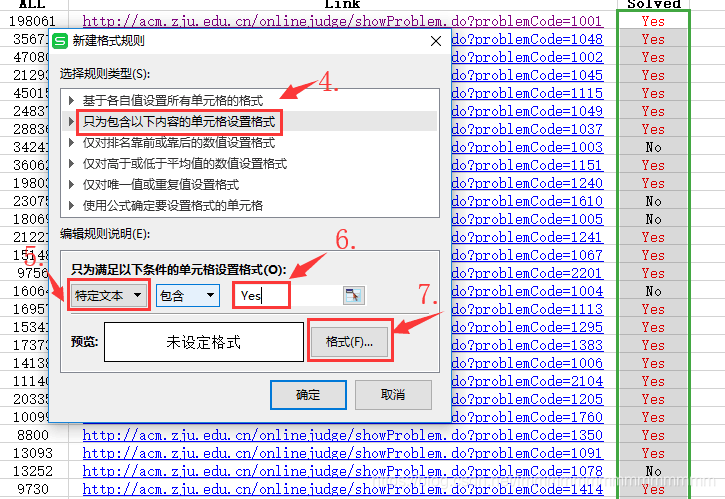
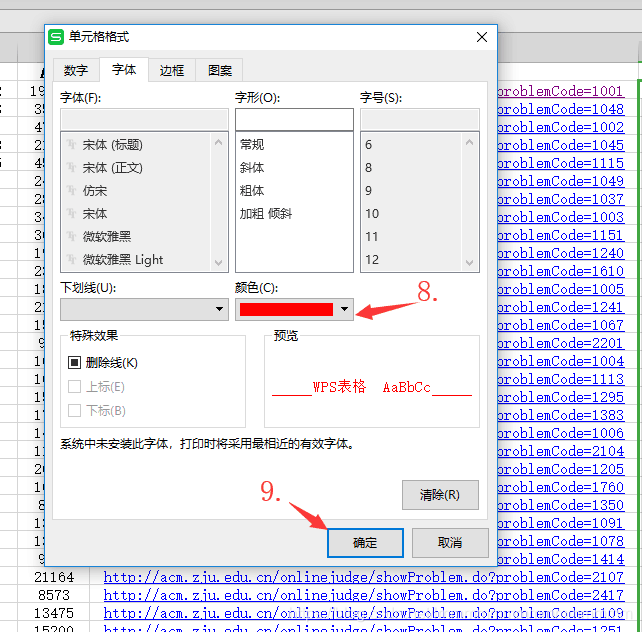
完成。
版权声明:本文为lmmmmmmmmmmmmmmm原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。