题目
:
交叉偏差的一对一缓解:扩展公平感知二元分类的一般方法
用以发现交叉偏差并消减交叉偏差。
研究背景:
如图1所示:
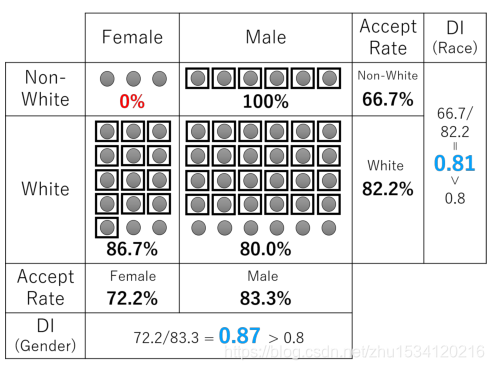
男性和女性,白人和非白人在大体上的接受率基本相同,但是可以明显看到非白人女性占有率0%,存在明显的歧视性,即一个受保护的群体在整体上似乎受到公平对待,受保护群体的一部分也可能受到不公平对待。
研究问题:
交叉偏差就是存在两个或多个敏感属性,这些敏感属性之间存在一定的关联,这种关联影响了系统的结果,导致结果存在不均衡问题,即出现歧视性。
创新点:1.
提出了One-vs.-One Mitigation方法
2.
提供了一个子组视差上限,可以控制精度和公平性之间的权衡。
研究方法:
为了解决上述交叉偏差问题,论文提出了One-vs.-One Mitigation方法。
一、公平指标


任何子组中的一个实例被归类到有利类的概率等于整个数据集中的概率 任意子组中的一个实例被正确地归类到有利类的概率(真正率,TPR)和错误分类为有利类(假Posi- tive Rate, FPR)的概率等于整个数据集中的概率

任意子组中的一个实例被正确地归类到有利类(TPR)的概率等于整个数据集中的实例的概率
二、方法
该方法利用从分类模型或缓解方法中获得的多数投票结果和预测概率来计算每个实例的得分。对每对的缓解结果进行汇总,并根据最喜欢的类别的投票率和预测概率的平均值计算T。最终缓解结果Z由投票率是否超过阈值s决定
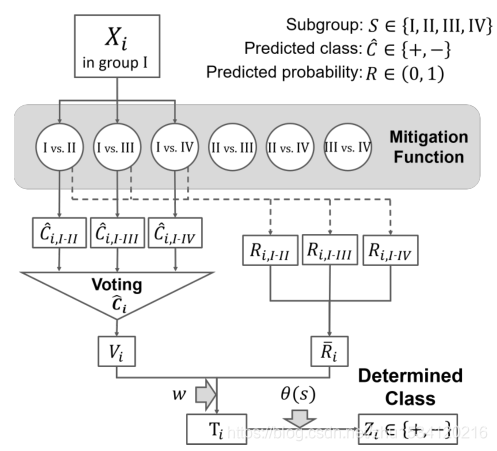

为什么要采取多数投票结果?
因为我们无法从重估和不同影响消除器等缓解方法中获得预测概率的信息
多数投票的结果意味着与Xi相关的每对子组之间的比较所得到的所有结果中,有利的类所占的比例.当只有少数子组时,如果我们只使用多数投票来确定分数,那么有很多实例具有相同的分数值。这导致很难根据分数值确定应该选择哪些实例来更改它们的类。然后我们还使用从分类方法中提取的预测概率来计算分数。为了平衡多数投票结果和预测概率,我们引入了一个权衡参数w
实验:
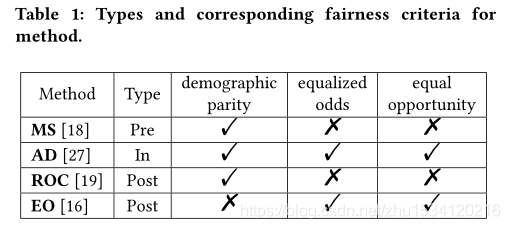
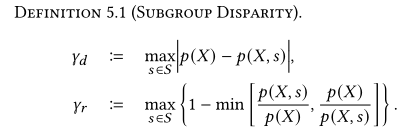
MS是按摩预处理技术。该方法根据分类器的预测得分,选择训练数据的升降级实例(将有利类标签修改为不利类标签,反之亦然)进行预处理。
AD是一种对抗性去偏处理,它的目的是最小化从预测类中预测敏感属性值的可能性。
ROC是基于拒绝选择的分类,作为后处理,在分类阈值附近修改类标签。此时,受保护组中的实例被修改为有利的类,而非受保护组中的实例被修改为不利的类。
EO是作为后处理开发的最优均等概率/机会预测器,确保各组间预测结果的真、假阳性率没有差异。
数据集:

实验结果:
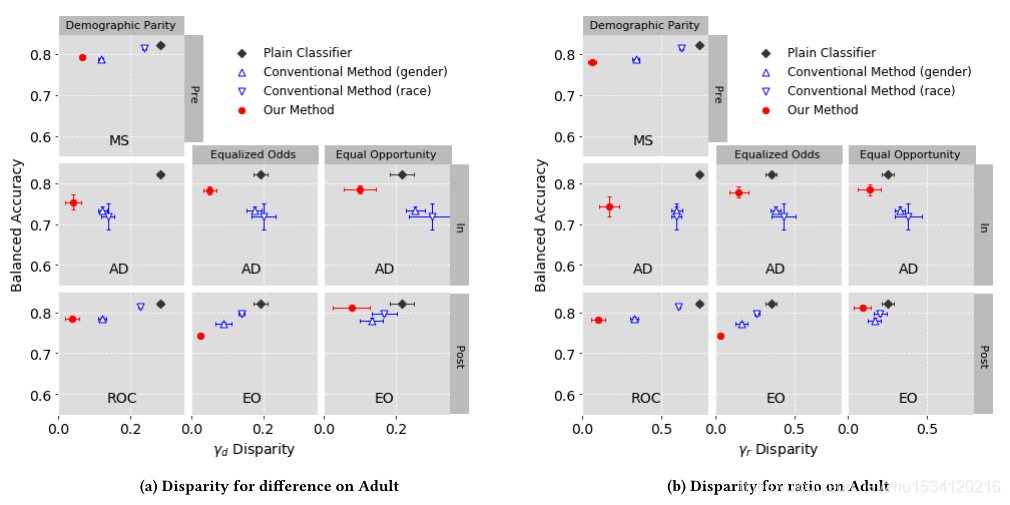
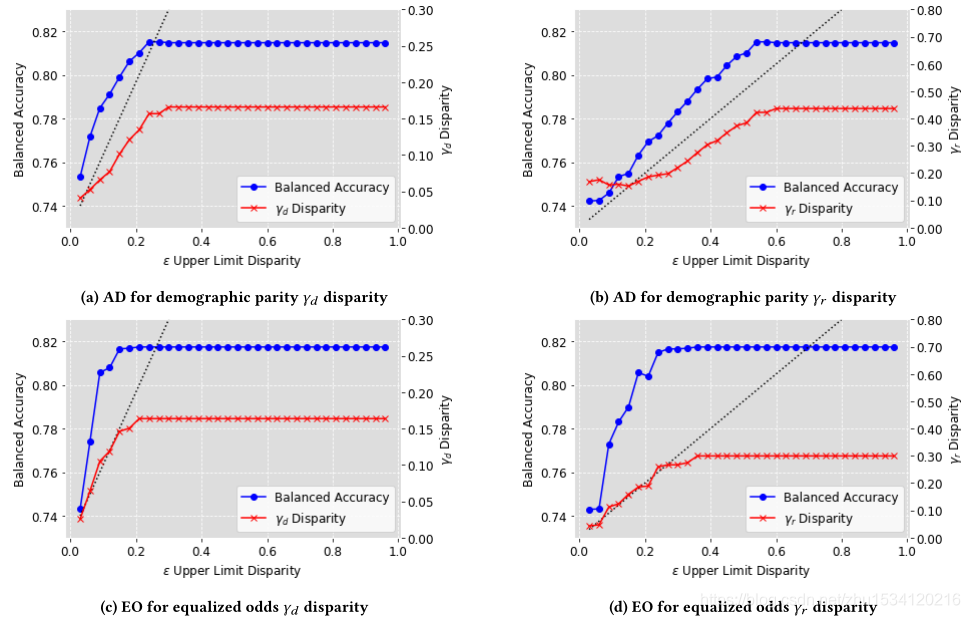
实验结果表明,与传统的分类器和普通分类器相比,我们的方法能更好地减轻交叉偏倚。我们还证实了该方法可以通过调整视差的上限来控制交流性和公平性之间的平衡。证明了我们的方法能够在满足广泛的公平性要求的同时,减轻不同现实情况下的交叉偏差。
展望:
我们期望在未来提出新的基于公平意识的二值分类方法和标准时,能够减少考虑交叉偏倚的负担。