YARN中资源调度器的那些事儿,接上次Yarn的那些事儿,来扯一下调度器…
YARN三种资源调度器
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
在Yarn中有三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,FairS cheduler。
FIFO Scheduler
把应用按提交的顺序排成一个先进先出队列,缺点是大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。
Capacity Scheduler-容量调度
把资源划分为多个队列,队列还可以有子队列。
弹性队列(queue elasticity): 支持占用其他空闲队列资源。
Fair Scheduler-公平调度
目的是为所有的应用分配公平的资源,右下角图图从第二个任务提交到获得资源会有一定的延迟,因为他需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占领的资源,大任务又获得了全部系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
Fair支持多队列,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。过程如下图所示。
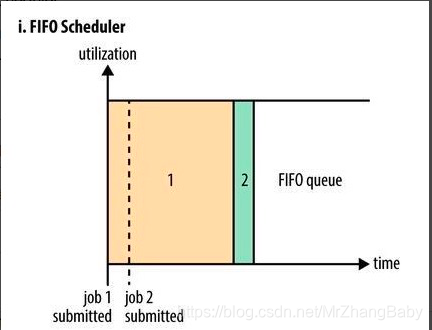
好多人都看不懂这些图,用通俗易懂的话,轻松的解释一下:FIFO调度,就是先进先出,一个一个的进行任务调度~
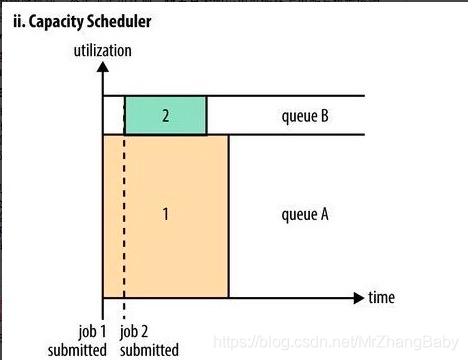
容量调度:划分多队列,保证队列中任务调度资源互不影响~
容量调度后面也支持了打标签调度YARN-Label Based sScheduling
注意:容量调度才能使用label便签,公平调度暂时不支持标签
从Hadoop 2.6.0起YARN引入了一种新的调度策略:基于标签的调度机制。该机制的主要引入动机是更好地让YARN运行在异构集群中,进而更好地管理和调度混合类型的应用程序。
基本思想是: 用户可以为每个nodemanager标注几个标签,比如highmem,highdisk等,以表明该nodemanager的特性;同时,用户可以为调度器中每个队列标注几个标签,这样,提交到某个队列中的作业,只会使用标注有对应标签的节点上的资源。
举个例子: 比如最初你们的hadoop集群共有20个节点,硬件资源是32GB内存,4TB磁盘;后来,随着spark地流行,公司希望引入spark计算框架,而为了更好地运行spark程序,公司特地买了10个大内存节点,比如内存是64GB,为了让spark程序与mapreduce等其他程序更加和谐地运行在一个集群中,你们希望spark程序只运行在后来的10个大内存节点上,而之前的mapreduce程序既可以运行在之前的20个节点上,也可以运行在后来的10个大内存节点上,怎么办?
有了label-based scheduling后,这是一件非常easy的事情。
你需要按以下步骤操作:
步骤1:为旧的20个节点打上normal标签,为新的10个节点打上highmem标签;
步骤2:在capacity scheduler中,创建两个队列,分别是hadoop和spark,其中hadoop队列可使用的标签是nornal和highmem,而spark则是highmem,并配置两个队列的capacity和maxcapacity。 最终提交作业时指定队列和labels。
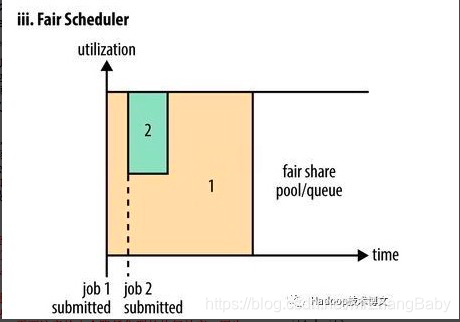
Fair Scheduler-公平调度体现在公平上,如果一个大任务占用全部资源,再提交任务,那么这个大任务会给新提交的任务省下来一些资源供起运行。公平调度还有另外一种基于队列的公平调度是支持资源抢占的,不建议生产上使用。如下图:
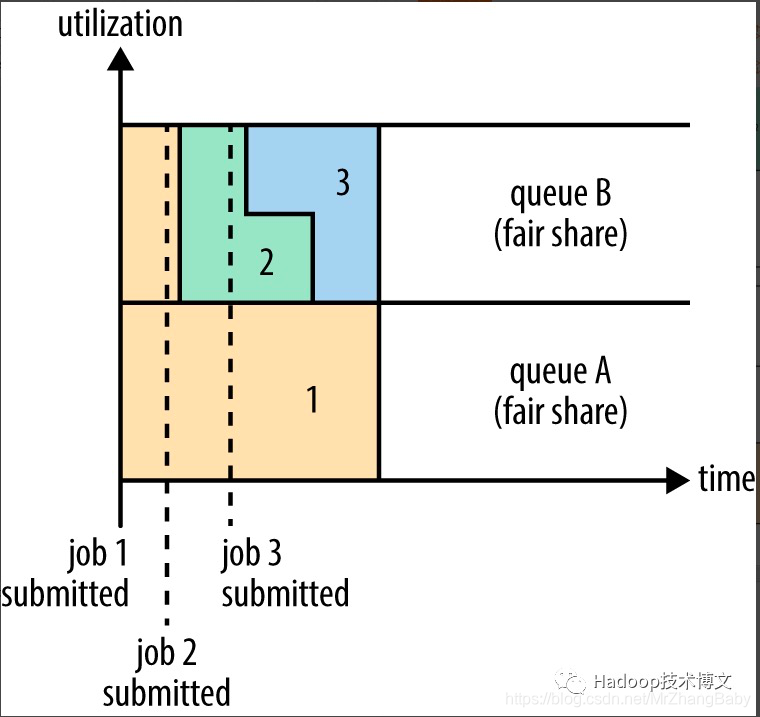
当一个job提交到一个繁忙集群中的空队列时,job并不会马上执行,而是阻塞直到正在运行的job释放系统资源。为了使提交job的执行时间更具预测性(可以设置等待的超时时间),Fair调度器支持抢占。
抢占就是允许调度器杀掉占用超过其应占份额资源队列的containers,这些containers资源便可被分配到应该享有这些份额资源的队列中。需要注意抢占会降低集群的执行效率,因为被终止的containers需要被重新执行。
生产环境建议使用容量调度,结合实际场景配置label便签进行合适的配置容量调度的使用~~