一、数据与数据管理的历史
1、数据、 数据库、 数据库 系统 和 数据库 管理 系统
为了 了解 世界, 交流 信息, 人们 需要 描述 事物。 在 计算 机中, 为了 存储 和 处理 这些 事物, 就要 抽出 对这 些 事物 感兴趣 的 特征 并 组成 一个 记录 来 描述。 例如: 在学 生的 档案 中, 如果 人们 最 感兴趣 的 是 学生 的 姓名、 性别、 年龄、 出生年月、 籍贯、 所在 系、 入学 时间, 就可以 这样 描述:( 王 兵, 男, 1987, 北京, 计算机 系, 2006)。 这里 的 学生 记录 就是 数据。
有了 数据 之后, 就 需要 把 数据 存储 起来, 方便 查询 使用 等, 把这 种 存储 数据 的“ 仓库” 称之为 数据库( Database, DB)。数据库 管理 系统( Database Management System, DBMS) 是 用于 创建、 管理 和 维护 数据库 时 所 使用 的 软件, 介于 用户 和 操作系统 之间, 可 对 数据库 进行 管理。
数据库 系统 包括 3 个 主要 的 组成部分。
⑴ 数据库: 用于 存储 数据 的 存储 空间。
⑵ 数据库 管理 系统: 用于 管理 数据库 的 软件。
⑶ 数据库 应用 程序: 为了 提高 数据库 系统 的 处理 能力 所 使用 的 管理 数据库 的 软件 补充。
2、数据管理 的 历史
(1) 简单 应用 (20 世纪 50 年代 以前)
这个 阶段 最 基本 的 特征 是 无 数据管理 及 完全 分散 的 手工 方式。
(2)文件 系统 (20 世纪 50 年代 后期 到 60 年代 中期)
这个 阶段 的 基本 特征 是有 了 面向 应用 的 数据管理 功能, 工作 方式 是 分散 的 非 手工 的。
(3)数据库 系统 (20 世纪 60 年代 后期 开始)
20 世纪 60 年代 后期, 计算机 在 管理 中的 应用 更加 广泛, 数据 量 急剧 增大, 对数 据 共享 的 要求 越来越 迫切; 同时, 大 容量 磁盘 已经 出现, 联机 实时 处理 业务 增多; 软件 费用 占 系统 总 费用 的 比例 日益 上升, 硬件 价格 大幅 下降, 编制 和 维护 应用 软件 所需 成本 相对 增加。 在 这种 情况下, 为了 解决 多用户、 多 应用 共享 数据 的 需求, 使 数据 为 尽可能 多 地 为 应用 程序 服务, 出现 了 数据库 系统。
3、MySQL 的 起源 与 版本
MySQL 是一 个 小型 关系 型 数据库 管理 系统, 开发者 为 瑞典 MySQL AB 公司, 在 2008 年 1 月 16 号 被 Sun 公司 收购。 MySQL 被 广泛 地 应用 在 Internet 上 的 中小型 网 站 中。
MySQL有如下几个版本:
⑴ MySQL Community Server, 社区 版本, 开源 免费, 但不 提供 官方 技术 支持。
⑵ MySQL Enterprise Edition, 企业 版本, 需 付费, 可以 试用 30 天。
⑶ MySQL Cluster, 集群 版, 开源 免费, 可将 几个 MySQL Server 封装 成 一个 Server。
⑷ MySQL Cluster CGE, 高级 集群 版, 需 付费。
⑸ MySQL Workbench( GUI TOOL), 一 款 专为 MySQL 设计 的 ER/ 数据库 建模 工具。 它是 著名 的 数据库 设计 工具 DBDesigner4 的 继任者。 MySQL Workbench 又 分为 两个 版本, 分别 是 社区 版( MySQL Workbench OSS)、 商用 版( MySQL Workbench SE)。
MySQL Community Server 是 开源 免费 的, 这也 是 我们 通常 用的 MySQL 的 版本。
4、MySQL 与 Oracle
数据库 软件 有很 多种, 常见 的 数据库 有 甲骨文 公司( Oracle 公司) 的 Oracle、 IBM 公司 的 DB2、 微软 公司 的Access 与 SQL Server 以及 MySQL。
MySQL 是最 受欢迎 的 开源 SQL 数据库 管理 系统, 它 由 MySQL AB 开发、 发布 和 支持。 MySQL AB 是一 家 基于 MySQL 开发 人员 的 商业 公司, 它是 一家 使用 了 一种 成功 的 商业 模式 来 结合 开源 价值 和 方法论 的 第二 代 开源 公司。 MySQL 是 MySQL AB 的 注册 商标。
MySQL 是一 个 快速、 多 线程、 多用户、 健壮 的 SQL 数据库 服务器。 MySQL 服务器 支持 关键 任务、 重负 载 生产 系统 的 使用, 也可以 将它 嵌入 到 一个 大 配置( Mass- Deployed) 的 软件 中去。
与其 他 数据库 管理 系统 相比, MySQL 具有 以下 优势。
(1) MySQL 是一 个 关系 数据库 管理 系统。
(2) MySQL 是 开源 的。
(3) MySQL 服务器 是一 个 快速、 可靠 和 易于 使用 的 数据库 服务器。
(4) MySQL 服务器 工作 在 客户/ 服务器 或 嵌入 系统 中。
(5) 有 大量 的 MySQL 软件 可以 使用。
Oracle 公司( 甲骨文 公司) 是 规模 较大 的 企业 软件 公司, 向 遍及 145 个 国家 的 用户 提供 数据库、 工具 和 应用 软件 以及 相关 的 咨询、 培训 和 支持 服务。 在 2008 年, Oracle 公司 是 继 Microsoft 及 IBM 后, 全球 收入 排名 第三 的 软件 公司。 但在 2013 年 年底, Oracle 公司 击败 IBM, 成为 全球 收入 排名 第二 的 软件 公司。
Oracle 数据库 产品 具有 以下 优良 特性。
Oracle 数据库 之所以 取得 如此 的 成就, 与 它 具有 的 很多 优点 是 分不开 的。
(1) 兼容性。 Oracle 产品 采用 标准 SQL, 并经 过 美国 国家 标准 技术 所( NIST) 测试。 与 IBM SQL/ DS、 DB2、 INGRES、 IDMS/ R 等 兼容。
(2) 可移植性。 Oracle 的 产品 可 运 行于 很 宽 范围 的 硬件 与 操作系统 平台 上。 可以 安装 在 70 种 以上 不同 的 大、 中、 小型 机上; 可在 VMS、 DOS、 UNIX、 Windows 等 多种 操作系统 下 工作。
(3) 可连接 性。 Oracle 能 与 多种 通信 网络 相连, 支持 各种 协议( TCP/ IP、 DECnet、 LU6. 2 等)。
(4) 高 生产率。
Oracle 产品 提供 了 多种 开发 工具, 能 极大 地方 便 用户 进行 进一步 的 开发。
(5) 开放 性。
Oracle 良好 的 兼容性、 可移植性、 可连接 性 和 高 生产率 使 Oracle RDBMS 具有 良好 的 开放 性。
二、关系型数据模型
1、关系型数据模型的结构
建立 数据库 系统 离不开 数据 模型。一种 是 独 立于 计算机 系统 的 数据 模型。其 典型 代表 就是 著名 的“ 实体- 关系 模型”。另一种 数据 模型 是 直接 面向 数据库 的 逻辑 结构。目前 理论 成熟、 使用 普及 的 模型 就是 关系 模型。 关系 模型 是由 若干个 关系 模式 组成 的 集合, 关系 模式 的 实例 称为 关系, 每个 关系 实际上 是一 张 二维 表格。 关系 模型 用 键 导航 数据。SQL 语言 是 关系 数据库 的 代表性 语言, 已经 得到 了 广泛 的 应用。 典型的 关系 数据库 产品 有 DB2、 Oracle、 Sybase、 SQL Server 等。
关系 模型 有 3 个 组成部分: 数据 结构、 数据 操作 和 完整性 规则。 关系 模型 建立 在 严格 的 数学 概念 的 基础上, 它 用 二维 表 来 描述 实体 与 实体 间的 联系。 下面 介绍 关系 模型 中的 一些 术语。
⑴ 关系( Relation): 对应 通常 所说 的 一张 表。
⑵ 元 组( Tuple): 表中 的 一行 即为 一个 元 组, 可以 用来 标识 实体 集中 的 一个 实体, 表中 任意 两行( 元 组) 不能 相同;
⑶ 属性( Attribute): 表中 的 一列 即为 一个 属性, 给 每个 属性 起 一个 名称 即 属性 名, 表中 的 属性 名 不能 相同。
⑷ 主 键( Key): 表中 的 某个 属性 组, 它可 以 唯一 确定 一个 元 组。
⑸ 域( Domain): 列 的 取值 范围 称为 域, 同 列 具有 相同 的 域, 不同 的 列 也可以 有 相同 的 域。
⑹ 分量: 元 组 中的 一个 属性 值。
⑺ 关系 模式: 对 关系 的 描述。 可表示 为: 关系 名( 属性 1, 属性 2,…, 属性 n)。
关系 是 一种 规范化 的 二维 表格, 具有 如下 性质。
⑴ 属性 值 具有 原子 性, 不可 分解。
⑵ 没有 重复 的 元 组。
⑶ 理论上 没 有行 序, 但是 使用 时有 时 可以 有行 序。 在 关系 数据库 中, 关 键码( 简称 键) 是 关系 模型 的 一个 重要 概念, 是 用来 标识 行( 元 组) 的 一个 或 几个 列( 属性)。如果 键 是 唯一 的 属性, 则 称为 唯一 键; 反之 由 多个 属性 组成, 则 称为 复合 键。
键 的 主要 类型 如下。
⑴ 超 键: 在 一个 关系 中, 能 唯一 标识 元 组 的 属性 或 属性 集 称为 关系 的 超 键。
⑵ 候选 键: 如果 一个 属性 集 能 唯一 标识 元 组, 且 又不 含有 多余 的 属性, 那么 这个 属性 集 称为 关系 的 候选 键。
⑶ 主 键: 如果 一个 关系 中有 多个 候选 键, 则 选择 其中 的 一个 键 为 关系 的 主 键。 用 主 键 可以 实现 关系 定义 中“ 表中 任意 两行( 元 组) 不能 相同” 的 约束。
⑷ 外 键: 如果 一个 关系 R 中 包含 另一个 关系 S 的 主 键 所 对应 的 属性 组 F, 则 称 此 属性 组 F 为 关系 R 的 外 键, 并称 关系S 为 参照 关系, 关系 R 是 依赖 关系。 为了 表示 关联, 可以 将 一个 关系 的 主 键 作为 属性 放入 另外 一个 关系 中, 第二个 关系 中的 那些 属性 就 称为 外 键。
2、关系型数据模型的操作与完整性
关系 数据库 的 数据 操作 语言( Data Manipulation Language, DML) 的 语句 分为 查询 语句 和 更新 语句 两 大类。 查询 语句 用于 描述 用户 的 各类 检索 要求; 更新 语句 用于 描述用户 的 插入、 修改 和 删除 等 操作。
关系 数据 操作 语言 建立 在 关系 代数 基础上, 具有 以下 特点。
⑴ 以 关系 为 单位 进行 数据 操作, 操作 的 结果 也是 关系。
⑵ 非 过程 性强。 很多 操作 只需 指出 做 什么, 而无 需 步步 引导 怎么 去做。
⑶ 以 关系 代数 为基础, 借助于 传统 的 集合 运算 和 专门 的 关系 运算, 使 关系 数据 语言 具有 很强 的 数据 操作 能力。
下面 介绍 在 数据 操作 语言 中 对 数据库 进行 查询 和 更新 等 操作 的 语句。
● SELECT 语句: 按指 定的 条件 在 一个 数据库 中 查询 的 结果, 返回 的 结果 被 看作 记录 的 集合。
● SELECT… INTO 语句: 用于 创建 一个 查询 表。
● INSERT INTO 语句: 用于 向 一个 表 添加 一个 或 多个 记录。
● UPDATE 语句: 用于 创建 一个 更新 查询, 根据 指定 的 条件 更改 指定 表中 的 字段 值。 该 语句 不生 成 结果 集, 而且 当 使用 更新 查询 更新 记录 之后, 不能 取消 这次 操作。
● DELETE 语句: 用于 创建 一个 删除 查询, 可从 列 在 FROM 子句 之中 的 一个 或 多个 表中 删除 记录, 且 该 子句 满足WHERE 子句 中的 条件, 可以 使用 DELETE 删除 多个 记录。
● INNER JOIN 操作: 用于 组合 两个 表中 的 记录, 只要 在 公共 字段 之中 有 相符 的 值。 可以 在 任何 FROM 子句 中 使用 INNER JOIN 运算, 这是 最 普通 的 连接 类型。 只要 在这 两个 表 的 公共 字段 之中 有 相符 的 值, 内部 连接 将 组合 两个 表中 的 记录。
● LEFT JOIN 操作: 用于 在 任何 FROM 子句 中 组合 来源 表 的 记录。 使用 LEFT JOIN 运算 来 创建 一个 左边 外部 连接。 左边 外部 连接 将 包含 从 第一个( 左边) 开始 的 两个 表中 的 全部 记录, 即使 在 第二个( 右边) 表中 并没有 相符 值 的 记录。
● RIGHT JOIN 操作: 用于 在 任何 FROM 子句 中 组合 来源 表 的 记录。 使用 RIGHT JOIN 运算 创建 一个 右边 外部 连接。 右边 外部 连接 将 包含 从 第二个( 右边) 表 开始 的 两个 表中 的 全部 记录, 即使 在 第一个( 左边) 表中 并没有 匹配 值 的 记录。
● PARAMETERS 声明: 用于 声明 在 参数 查询 中的 每一个 参数 的 名称 及 数据 类型。 该 声明 是 可选 的, 但是 当 使用 时, 须 置于 任何 其他 语句 之前, 包括 SELECT 语句。
● UNION 操作: 用于 创建 一个 联合 查询, 它 组合 了 两个 或 更多 的 独立 查询 或 表 的 结果。 所有 在 一个 联合 运算 中的 查询, 都 须 请求 相同 数目 的 字段, 但是 字段 不必 大小 相同 或 数据 类型 相同。
关系 模型 的 完整性 规则 是对 数据 的 约束。 关系 模型 提供 了 3 类 完整性 规则: 实体 完整性 规则、 参照 完整性 规则 和 用户 定义 的 完整性 规则。 其中 实体 完整性 规则 和 参照 完整性 规则 是 关系 模型 必须 满足 的 完整 性的 约束 条件, 称为 关系 完整性 规则。
● 实体 完整性: 指 关系 的 主 属性( 主 键 的 组成部分) 不能是 NULL。 NULL 就 是指 不知道 或是 不能 使 用的 值, 它与 数值 0 和 空 字符串 的 意义 都不 一样。
● 参照 完整性: 如果 关系 的 外 键 R1 与 关系 R2 中的 主 键 相符, 那么 外 键 的 每个 值 必须 在 关系 R2 中 主 键 的 值 中 找到 或者是 空 值。
● 用户 定义 完整性: 是 针对 某一 具体 的 实际 数据库 的 约束 条件。 它 由 应用 环境 所 决定, 反映 某一 具体 应用 所 涉及 的 数据 必须 满足 的 要求。 关系 模型 提供 定义 和 检验 这类 完整 性的 机制, 以便 用 统一、 系统 的 方法 处理, 而 不必 由 应用 程序 承担 这一 功能。
3、关系型数据模型的存储结构
一张 二维 表 就是 一个 关系, 它 由 表 名、 行 和 列 组成。表 的 每一行 代表 一个 元 组, 每一 列 称为 一个 属性。
三、关系型数据模型中的数据依赖与范式
在 关系 数据库 中的 每个 关系 都 需要 进行 规范化, 使之 达到 一定 的 规范化 程度。
1. 第一 范式
第一 范式 是 第二 范式 和 第三 范式 的 基础, 是最 基本 的 范式。 第一 范式 包括 下列 指导 原则。
⑴ 数据 组 的 每个 属性 只可 以 包含 一个 值。
⑵ 关系 中的 每个 数组 必须 包含 相同 数量 的 值。
⑶ 关系 中的 每个 数组 一定 不能 相同。
2. 第二 范式
第二 范式( 2NF) 规定 关系 必须 在 第一 范式 中, 并且 关系 中的 所有 属性 依赖于 整个 候选 键。 候选 键 是 一个 或 多个 唯一 标识 每个 数据 组 的 属性 集合。
3.第三范式
第三 范式( 3NF) 同 2NF 一样 依赖于 关系 的 候选 键。 为了 遵循 3NF 的 指导 原则, 关系 必须 在 2NF 中, 非 键 属性 相互 之间 必须 无关, 并且 必须 依赖于 键。
四、常见的关系型数据库管理系统
常见 的 关系 型 数据库 管理 系统 产品 有 Oracle、 SQL Server、 Sybase、 DB2、 Access 等。
1. Oracle
2.SQL Server
3.Sybase
4.DB2
5.Access
五、MySQL数据库系统的体系结构
了解 MySQL 必须 牢牢 记住 其 体系 结构图, MySQL 是由 SQL 接口、 解析 器、 优化 器、 缓存、 存储 引擎 组成 的, 如下 图 所示。
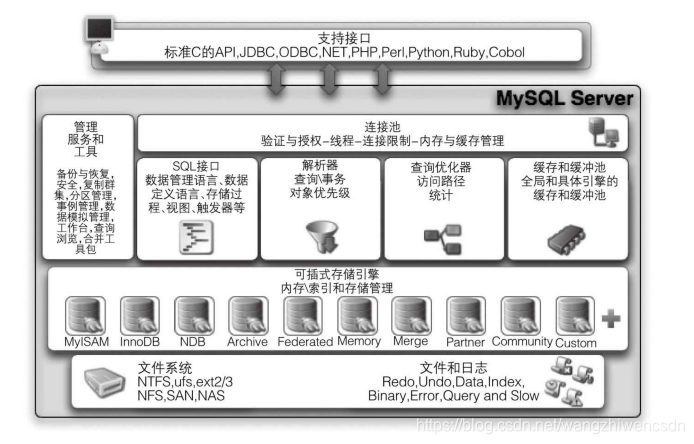
⑴ 支持 接口: 是指 不同 语 言中 与 SQL 的 交互。
⑵ 管理 服务 和 工具: 系统管理 和 控制 工具。
⑶ 连接 池: 管理 缓冲 用户 连接、 线程 处理 等 需要 缓存 的 需求。
⑷ SQL 接口: 接受 用户 的 SQL 命令, 并且 返回 用户 需要 查询 的 结果, 如 select from 就是 调用 SQL Interface。
⑸ 解析 器: SQL 命令 传递 到 解析 器 的 时候 会被 解析 器 验证 和 解析, 解析 器 是由 Lex 和 YACC 实现 的, 是一 个 很长 的 脚本, 其 主要 功能 如下。 ① 将 SQL 语句 分解 成数 据 结构, 并将 这个 结构 传递 到 后续 步骤, 以后 SQL 语句 的 传递 和 处理 就是 基于 这个 结构 的。 ② 如果 在 分解 构成 中 遇到 错误, 那么 就说 明 这个 SQL 语句 是 不合理 的。
⑹ 查询 优化 器: SQL 语句 在 查询 之前 会使 用 查询 优化 器 对 查询 进行 优化。 它 使用“ 选取 → 投影 → 连接” 策略 进行 查询。 用 一个 例子 就可以 理解: select uid, name from user where gender = 1; 这个 select 查询 先 根据 where 语句 进行 选取, 而 不是 先 将 表 全部 查询 出来 以后 再进 行 gender 过滤。
这个 select 查询 先 根据 uid 和 name 进行 属性 投影, 而 不是 将 属性 全部 取出 以后 再进 行 过滤。 将 这 两个 查询 条件 连接 起来 生成 最终 查询 结果。
⑺ 缓存 和 缓冲 池: 查询 缓存。 如果 查询 缓存 有 命中 的 查询 结果, 查询 语句 就可以 直接 去 查询 缓存 中 取 数据。 这个 缓存 机制 是由 一系列 小 缓存 组成 的。 比如 表 缓存、 记录 缓存、 Key 缓存、 权限 缓存 等。
⑻ 存储 引擎: 存储 引擎 是 MySQL 中 具体 的 与 文件 打交道 的 子系统。 也是 MySQL 最 具有 特色 的 一个 地方。 从 MySQL 5. 5 之后, InnoDB 就是 MySQL 的 默认 事务 引擎。
六、MySQL存储引擎
存储 引擎 是 MySQL 中 一个 重要的 组成部分。 MySQL 提供 了 多个 不同 的 存储 引擎, 包括 处理 事务 安全 表 的 引擎 和 处理 非 事务 安全 表 的 引擎。 在 MySQL 中, 不需 要在 整个 服务器 中 使用 同一 种 引擎, 应该 针对 具体 的 要求, 对 每一个 表 使用 不同 的 存储 引擎。
MySQL 5. 6 支持 的 存储 引擎 有 InnoDB、 MyISAM、 Memory、 Merge、 Archive、 Federated、 CSV、 BLACKHOLE 等。 其中 InnoDB 是 支持 事务 型 的 存储 引擎, 从 MySQL 5. 5 之后, InnoDB 就是 MySQL 的 默认 事务 引擎。 InnoDB 支持 事务 安全 表( ACID), 也 支持 行 锁定 和 外 键。 InnoDB 为 MySQL 提供 了 具有 事务( transaction)、 回 滚( rollback) 和 崩溃 修复 能力( crash recovery capabilities)、 多 版本 并发 控制( multi- versioned concurrency control) 的 事务 安全( transaction- safe (ACID compliant)) 型 表。